Hadoop官网翻译(HDFS用户概览)
Hadoop架构
HDFS目标
- 容忍硬件故障
- 批处理数据访问
- 支持大文件
- 简单的读写一致性模型
- 数据本地性
- 支持异构平台
hdfs通过追加写来简化读写一致性模型。关注吞吐率。
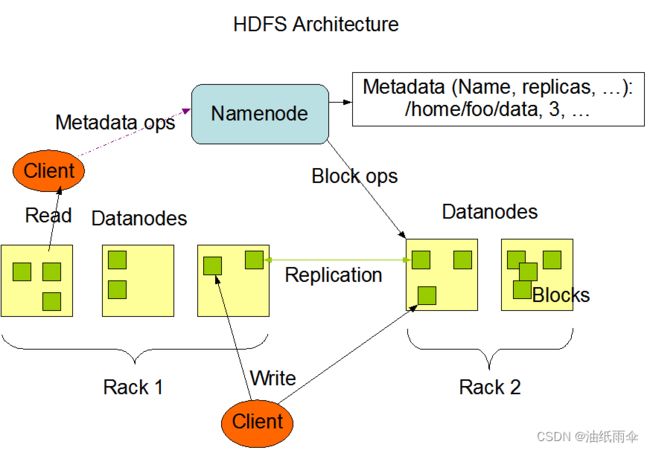
NameNode和DataNode
主从架构
NameNode两个功能:管理文件系统,管理DataNode
DataNode功能: 管理存储。
文件系统的操作有:打开关闭重命名文件和目录。
管理DataNode指的是:块操作到DataNode的映射,让DataNode处理请求。
管理存储:DateNode定时汇报块列表,处理NameNode下发的请求。
这里面涉及到三个角色,客户端,NameNode和DataNode
文件系统
- 支持文件系统的增删改操作
- 支持配额
- 支持权限
- NameNode维护属性信息(包含副本信息)
数据复制
文件是块组成的,每个文件的块大小副本数都是可以配置的。
TODO 配置一个文件块副本策略,块大小策略
查看副本数: hadoop fs -ls
修改副本数: hadoop fs -setrep 1
查看块信息: hadoop fsck-files -blocks -racks
上传文件设置块大小: hadoop fs -Ddfs.block.size=10 -Ddfs.replication=10 -put core-site.xml /tmp/ 不过默认是最小1G
除了最后一个块之外,所有的块都是大小相同的。
数据复制要关主的点:
- 副本数(不大于datanode个数)
- 机架感知
机架可以通过参数net.topology.node.switch.mapping.impl 指定类定制,决定哪个ip到哪个机架,如果没有配置,那么所有的ip到一个机架
- 复制策略
多个复制策略,默认是使用两个机架, 在虚拟化环境中,可以开启网络拓扑,也可以配置域,或者是尽可能多个机架。
- 存储策略
为了数据分层
设置了存储类型:ARCHIVE, DISK, SSD RAM_DISK
存储策略:Hot,Cold,Warm,(区分DISK,ARCHIVE) All_SSD,One_SSD(SSD),Lazy_persist等
查看路径策略: hdfs storagepolicies -getStoragePolicy -path
默认是开启的,需要dfs.datanode.data.dir前面有标识
./hdfs-site.xml-56- <property>
./hdfs-site.xml:57: <name>dfs.datanode.data.dir</name>
./hdfs-site.xml-58- <value>[DISK]/disks/hdd_data2,[DISK]/disks/hdd_data3,[DISK]/disks/hdd_data1</value>
./hdfs-site.xml-59- </property>
- 安全模式
NameNode启动时进入安全模式,关注副本数和全副本数百分比,达到要求自动退出。
元数据存储
- FSImage 文件属性映射
- EditLog 变更的记录
符合检查点要求时进行将内存中的FSImage刷成一个新的FSImage,dfs.namenode.checkpoint.txns和dfs.namenode.checkpoint.period两个值触发。
- DataNode汇报区块信息
datanode启动时会扫描本地文件系统文件列表,报告给NameNode,另外就是定时汇报,dfs.blockreport.intervalMse参数控制。
- DataNode部分日志
包含blockscanner,队列,数据块复制等日志信息
2023-02-15 15:39:41,046 INFO org.apache.hadoop.hdfs.server.datanode.BlockScanner: Initialized block scanner with targetBytesPerSec 1048576
2023-02-15 15:39:51,461 INFO org.apache.hadoop.ipc.CallQueueManager: Using callQueue: class java.util.concurrent.LinkedBlockingQueue, queueCapacity: 2000, scheduler: class org.apache.hadoop.ipc.DefaultRpcScheduler, ipcBackoff: false.
2023-02-15 15:39:51,739 INFO org.apache.hadoop.hdfs.server.common.Storage: Using 3 threads to upgrade data directories (dfs.datanode.parallel.volumes.load.threads.num=3, dataDirs=3)
2023-02-15 15:39:51,810 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Setting up storage: nsid=2104128967;bpid=BP-344496998-172.16.0.216-1665026133759;lv=-57;nsInfo=lv=-66;cid=cdp;nsid=2104128967;c=1665026133759;bpid=BP-344496998-172.16.0.216-1665026133759;dnuuid=1e3cd214-1fbf-4629-b718-8fe12d8ff800
2023-02-15 15:39:53,760 INFO org.apache.hadoop.hdfs.server.datanode.fsdataset.impl.FsDatasetImpl: Time to add replicas to map for block pool BP-344496998-172.16.0.216-1665026133759 on volume /disks/hdd_data3: 1816ms
鲁棒性
- DataNode节点没有心跳,NameNode检查副本数
默认10min
- 集群Rebalance
dfs.datanode.balance.max.concurrent.moves=100
dfs.balancer.max-size-to-move=21474836480
dfs.balancer.moverThreads=1300
dfs.balabcer.getBlocks.size=4294967296
dfs.datanode.balance.bandwidthPerSec=20971520
- 数据块校验
- 元数据损坏
多副本,或者NFS,或者distributed edit log (Journal)
数据组织
- 默认块大小是128M,可以包含多个块
- 写入时,根据副本策略向NameNode获取DataNode列表,然后使用Pipelined的方式写入。
pipelined方式就是部分写入就传到下一个,像一个管道。
访问方式
- FlieSystem
- HTTP访问
- NFS网关,挂载为本机的存储系统
- Shell
hadoop fs -ls /
- DFSAdmin
bin/hdfs dfsadmin -report
bin/hdfs dfsadmin -safemode enter
空间回收
- 删除时放到垃圾箱
- 减少副本数
减少副本数会在下一次心跳时删除
- 隔一段事件创建垃圾检查点,删除检查点之后一段时间内删除
hadoop fs -rm -r -skipTrash delete/test2
hadoop fs -expunge --immediate -fs s3a://landsat-pds/
用户指南
分布式,容错性,可伸缩,扩展简单
NameNode和DataNode内置在Web服务器中,可以简单的检查状态
一些有用的功能
- Balancer: 平衡集群工具
- fsck: 诊断工具,丢失块时使用
- Safemode: 进入维护模式
- Upgrade and rollback: 升级和回滚
- Recover Mode: 元数据损坏,恢复模式
bin/hdfs namenode -recover 从损坏的FSImage,EditLog恢复
- DfsAdmin命令: 管理HDFS
-report
-printTopology
- 平衡器
目的是为了数据平衡,可以通过tools主动调用,可以设置参数被动执行
hdfs balancer
threshold
source [-f hosts-file>]
dfs.balancer.service.interval
- 热修改datanode目录
首先修改配置
dfs.datanode.data.dir
然后dfsAdmin通知datanode重新加载配置项
去掉目录等
- 安全
- 大集群管理
主要目的是缩小namenode的内存瓶颈
一些概念
- Secondary NameNode
NameNode在启动时合并FSImage和EditLog,Secondary NameNode定时合并,如果需要Secondary NameNode的FSImage可以被读取
- Checkpoint Node
这个也是用来合并FSImage和EditLog,可以通过web接口查看。重要的是它会上传合并后的FSImage到NameNode。NN可以通过导入CheckPoint恢复
- Backup Node
和Checkpoint Node类似,但是它不需要下载FsImage创建检查点,时刻保持一致。
伪分布式安装
思路是使用Docker安装,配置文件暴露出来
dockerfile和docker compose附件给出,只需要一键命令就可以启动。可以通过百度网盘下载。