Redis入门——从单机到集群(搭建)

目录
redis概述
一、linux下安装
二、基本用法
1)基本数据类型
2)发布订阅
3)事务及锁
4)持久化操作
三、如何实现高可用
1)主从模式(master-slave)
2)哨兵模式(Sentinel)
3)集群模式(Cluster )
四、常见问题及解决
1)缓存击穿
2)缓存穿透
3)缓存雪崩
4)双写一致性
扩展
redis概述
此文档纯属个人在学习过程中的简单记录,大概介绍一下相关概念及操作。
Redis是一个高性能的非关系型数据库,写操作11w次/s,读操作8w次/s。
在我们项目开发中也经常用它来存储token、登录用户信息、字典数据、做分布式锁等等,以减轻我们数据库的压力,提高系统的可用性。接下来让我们学习它吧...
一、linux下安装
从官网http://www.redis.cn/download.htmlredis 6.0.6 下载 -- Redis中国用户组(CRUG)http://www.redis.cn/download.html下载相应版本的压缩包,安装操作在下载页面最下边,照着文档操作即可:

配置redis后台启动,打开redis.config文件:

# 启动redis
./src/redis-server ./redis.conf
# 连接命令
./src/redis-cli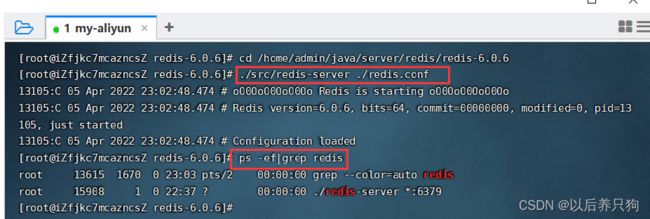
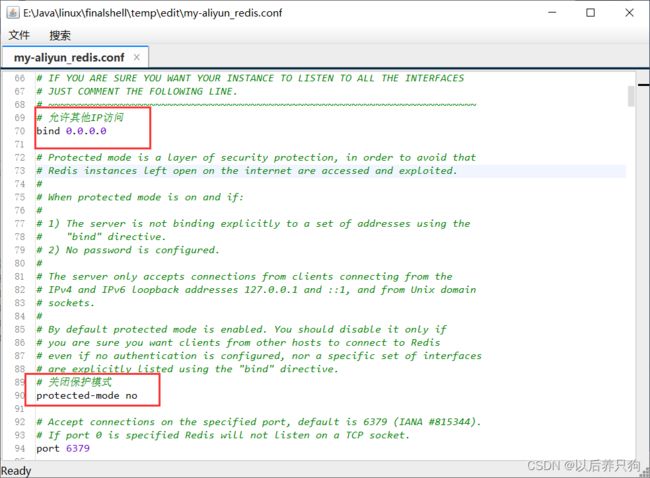
此时我们用本地工具是连接不上redis的,得先修改配置redis.config配置:
你可以通过官网学习他的基本命令
Redis文档中心 -- Redis中国用户组(CRUG)
可能遇到的问题:
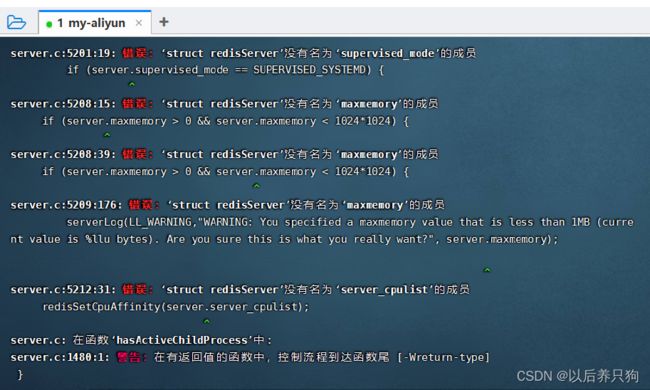
# 查看当前gcc版本:
gcc -v # 不是5.3以上,更新版本
yum -y install centos-release-scl
yum -y install devtoolset-9-gcc devtoolset-9-gcc-c++ devtoolset-9-binutils
scl enable devtoolset-9 bash二、基本用法
1)基本数据类型
redis常用的数据类型为前五个:
字符串(string)
哈希(hash)
列表(list)
集合(set)
有序集合(sorted set)
位图 ( Bitmaps )
基数统计 ( HyperLogLogs )
操作命令可以去网站学习redis命令手册,百度也可以就不多说了。
2)发布订阅
redis的发布订阅模式如下,分为发布者、消息频道、订阅者三个部分,发布者可在指定的消息频道发布消息,订阅了相应频道的消费者将接受到消息。感兴趣的可以去官网了解一下常用命令Redis Psubscribe 命令_订阅一个或多个符合给定模式的频道。:

命令演示:
创建消息频道,并订阅: subscribe channel1
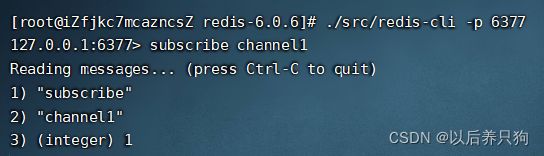
查看我们已创建的消息频道:pubsub channels
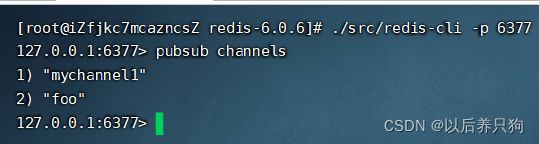
此时打开另一个客户端进行消息发布:subscribe channel1

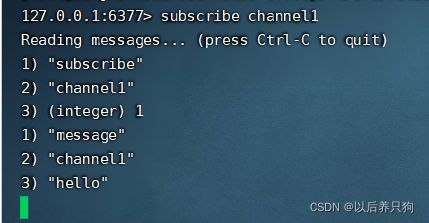
redis的发布订阅模式,实时性较高,但是消息不会保存,当没有订阅者订阅,消息发送出去将会丢失。此功能本人在实际开发过程中还没用过,但是也从网上搜索了下他的用途,可用于临时聊天、群聊等功能,下面和rabbitmq做个比较:
redis: 轻量级,低延迟,高并发,低可靠性;
rabbitmq:重量级,高可靠,异步,不保证实时,有可视化界面;
3)事务及锁
redis的事务不具有原子性,如果某一个命令报错了,会继续执行下边的命令,不会回滚数据。这点和mysql不同。redis事务中我们可以把多个命令看做一个队列,先用multi命令创建队列,然后把这些命令放入队列中等待,最后用命令exec执行这个队列。
下边是一个事务操作栗子:
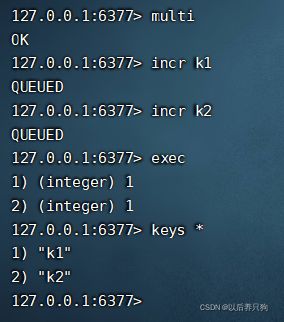
接下来演示一下报错不回滚的场景:
incr递增命令用在value是字符串的key上会报错,但是后边的命令依旧正常执行:


redis对于事务的支持性并不好,不支持原子性,虽然也可以用watch实现乐观锁,但是没有隔离级别,在java中操作redis事务也需要手动创建、执行、回滚,而MySQL事务配置注解方式更加简单。
另外reddisson实现的分布式锁,其实是用了lua脚本在rediss命令中具有原子性这一特点。java中我们可以用aop去实现一个自定义注解使用分布式锁,用起来更加简单。
lua脚本在redis为什么具有原子性,看看官方的说明:
“Atomicity of scripts
Redis uses the same Lua interpreter to run all the commands. Also Redis guarantees that a script is executed in an atomic way: no other script or Redis command will be executed while a script is being executed. This semantic is similar to the one of MULTI / EXEC. From the point of view of all the other clients the effects of a script are either still not visible or already completed.”
大致是说:脚本的原子性。
Redis使用(支持)相同的Lua解释器,来运行所有的命令。Redis还保证脚本以原子方式执行:在执行脚本时,不会执行其他脚本或Redis命令。这个语义类似于MULTI(开启事务)/EXEC(触发事务,一并执行事务中的所有命令)。从所有其他客户端的角度来看,脚本的效果要么仍然不可见,要么已经完成。
4)持久化操作
redis持久化方式有两种,AOF和RDB,我们一般默认使用RDB就可以:
这部分偷个懒,具体可以参考这篇文章,说的很详细:详解Redis中两种持久化机制RDB和AOF(面试常问,工作常用)
下面补充一下如何配置:
RDB一些参数配置

AOF如果开启了,redis会优先使用这种持久化方式,配置文件如下:
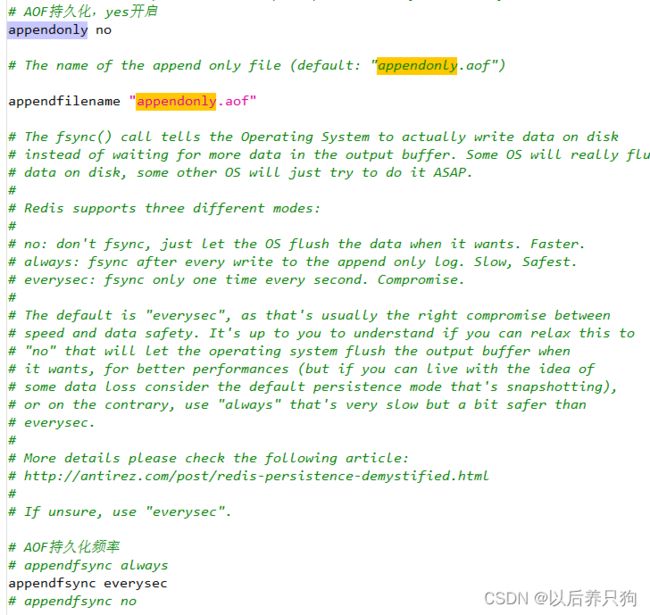
三、如何实现高可用
啥是高可用?打个比方,公司有程序员小王负责A业务,有一天小王跳槽了,公司的A业务就无人运转了,会给公司造成很大的损失,为了避免损失,公司又招了小李、小刘,和小王一起负责业务A,这个时候我们可以把他们三个看做一个集群,就算其中俩人跳槽,业务仍可继续运转,这就实现了服务的高可用。
下边学习一下高可用的实现,由于就一个机器,下边都是用一台机器做的试验。
1)主从模式(master-slave)
一台主机多台从机,主机master负责写入数据并同步数据到从机,从机slave负责读数据。
优点:读写分离提高性吞吐量,挂掉一个从机仍可使用。
缺点:主机挂掉则不能写入数据。

配置一主两从,先把用到的redis.conf文件引入进来,然后针对需要配置的项进行配置:



好滴,接下来我们可以启动三个redis集群,然后使用 info replication查看集群信息

查看从机信息,6382就不展示了
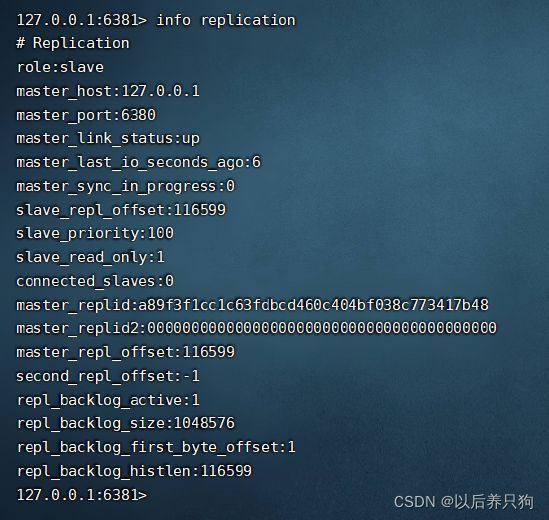
接下来我们向master写入数据
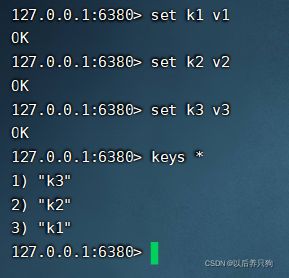
好的查看从机信息,也已经同步了数据了


有小伙伴说,从机可以写入数据吗

好的没错,你想多了
如果觉得每次都启动多个redis麻烦,可以写个脚本
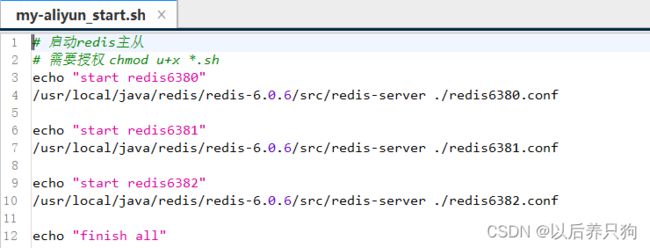
OK,主从同步我们就演示完了,是不是非常easy,接下来看哨兵
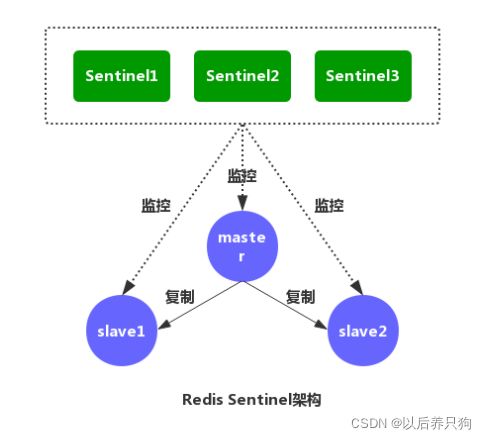
2)哨兵模式(Sentinel)
哨兵模式,即先启动redis的主从服务,然后再启动哨兵服务对redis进行监控,当redis的master服务挂掉后,哨兵会监测到并重新选举新的master。
首先我们要配置三个哨,配置文件都一样即可,此处端口配置的有区别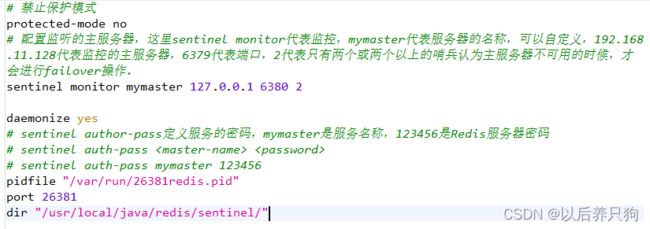
然后写个.sh的脚本文件启动哨兵,自己手敲命令启动也可以
 好的,我们首先启动redis主从服务,然后启动哨兵服务,下面以6381服务视角,查看哨兵选举的结果,当前信息是6380为master,6380为slave:
好的,我们首先启动redis主从服务,然后启动哨兵服务,下面以6381服务视角,查看哨兵选举的结果,当前信息是6380为master,6380为slave:

OK我们关掉6380master服务

30秒后,我们看一下6381服务状态(为什么30秒后呢,因为哨兵默认配置的扫描时间就是30秒)

是的6381被选举成了mater服务,下边是两个配置参数
# 监听6380master服务,有两个哨兵人为服务挂掉则进行选举 sentinel monitor mymaster 127.0.0.1 6380 2 # 指定多少毫秒之后 主节点没有应答哨兵sentinel 此时 哨兵主观上认为主节点下线 默认30秒 sentinel down-after-milliseconds mymaster 30000
3)集群模式(Cluster )
好的,既然上边已经有了哨兵模式,为什么还要集群模式呢?集群模式有什么优势吗?
首先我们要明白,哨兵模式他的主节点其实就一个,只有主节点负责写入操作,当我们的单机redis写入到了瓶颈8w/s,该如何提升性能呢?没错可以使用集群模式,多台主节点可以分别写入不同的数据。
原理描述:
Redis集群中内置了 16384【0-16383】 个哈希槽,当需要在 Redis 集群中放置一个 key-value 时,redis 先对key 使用 crc16 算法算出一个结果,然后把结果对 16384 求余数,这样每个 key 都会对应一个编号在 0-16383 之间的哈希槽,redis 会根据节点数量大致均等的将哈希槽映射到不同的节点.

关于集群节点插槽的分配,下面是楼主创建的集群,插槽的分配:

下面看redis集群模式搭建:
第一步、先配置redis集群模式,配置文件:

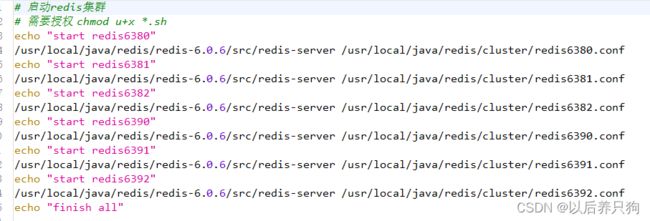
配置六个一样的文件,修改端口即可
一个个启动太麻烦,写个脚本命令一块启动
第二步、创建集群命令:./redis-cli --cluster create --cluster-replicas 1 127.0.0.1:6380 127.0.0.1:6381 127.0.0.1:6382 127.0.0.1:6390 127.0.0.1:6391 127.0.0.1:6392
输入yes,创三主三从服务结束
接下来演示一下集群的容灾:
集群模式连接需要加参数-c: ./redis-6.0.6/src/redis-cli -c -p 6380
查看集群状态,黄色标出主从关系的两个服务,mater:6381;slave:6390

关闭6381服务

再次查看集群状态,6381已经挂掉,6390上位成master:

然后我们再次启动6381服务
此时可以看到,6381彻底变成了6390的从机
好的演示结束,详细的配置文件及命令可以去官网或者百度。
四、常见问题及解决
首先要明白的是数据库(mysql、oracle等关系型数据库)是比较珍贵的资源,大量请求直接访问数据库可能会导致数据库宕机,从而我们的系统将崩溃。redis可以看做数据库的屏障,可以针对访问量大的数据做缓存,从而响应请求保护数据库。
1)缓存击穿
问题描述:如某个热点key失效的瞬间,大量的请求直接打在数据库上,导致数据库宕机。
解决方案:
1、设置热点key用不失效或者给key续活
2、代码加锁,请求只能排队访问数据库,
2)缓存穿透
问题描述:有黑客恶意发出大量请求访问缓存中不存在的key,导致数据库宕机。
解决方案:
1、当数据库没找到数据,在缓存中设置这个key且value为空
2、使用布隆过滤器过滤不符合的key
3、系统拦截器拦截请求并做token校验,或限制IP白名单
3)缓存雪崩
问题描述:某一时间缓存大量失效或者redis宕机,导致大量请求直接打在数据库。
解决方案:
1、做集群部署,实现高可用
2、key的失效时间不能设置在同一时间大量失效
3、用hystrix限流,超过请求数量,直接返回系统忙碌等提示
4、系统启动时,做数据预热
4)双写一致性
问题描述:多线程的情况下,数据库更新数据时,出现了缓存、数据库数据不一致。
情况1:先更新数据库,再更新缓存;
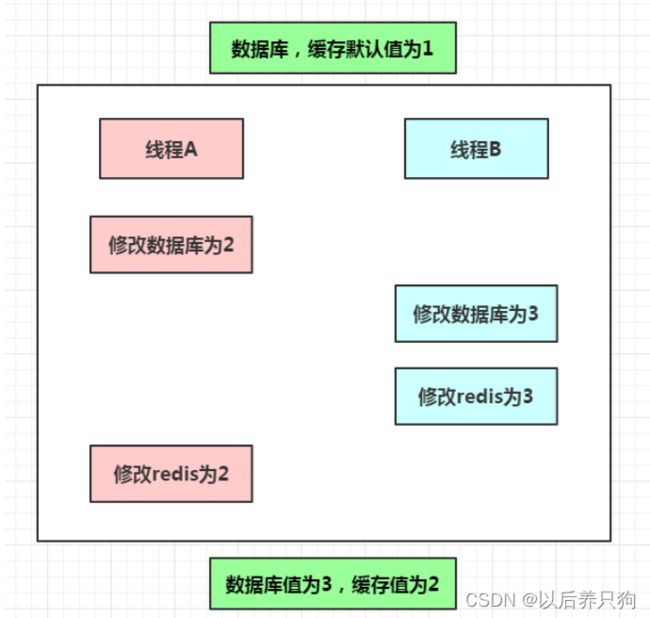
情况2:先更新缓存,再更新数据库;

情况3:先更新数据库,再删除缓存
这个问题可以使用延迟双删解决,延迟时间大于一次读取数据库、写入缓存的时间即可

情况4:先删除缓存。再更新数据库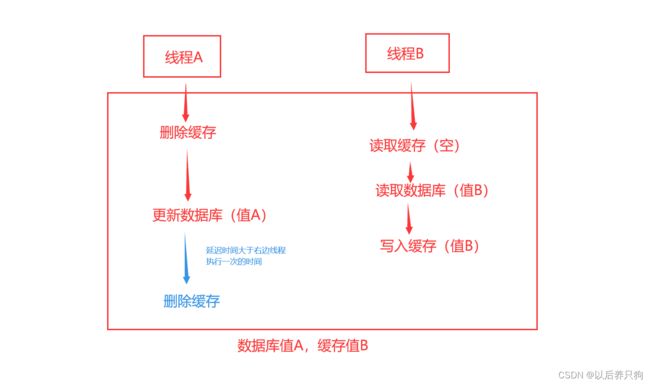
扩展
java中使用redis、redisson锁、@cacheable缓存及布隆过滤器的简单小栗子