一、前述
一直以来都想用很简介或者很普通的方式聊下各个算法的前龙后脉,让更多的人都能看懂算法的过程。查看了网上很多博客,不是写的太笼统就是抄来抄去,根本没有阅读的欲望,很是让人浪费时间,也学不到真正的东西,一直半解。因为年前一直在忙着公司上线加班的事情,所以根本没抽出来时间。加班的日子暂时告一段落,打算从今天开始,出一个专辑序列专门打造一个所有人都能阅读懂的算法系列,以白话清晰的方式告诉你一个算法的魅力,同时也结合更多的贴切生活的例子,让你越来越爱上算法。这就是本系列的初衷,也希望大家都能多多投稿,一起走进DT&AI的时代。赠人玫瑰,手有余香,让我们开始我们的算法之旅吧。
第一节:多元线性回归
所以我们先聊下线性回归,其实线性回归是最简单的解决预测问题的手段,是用一条直线(平面、超平面)来拟合真实世界中的一些规律,比如三维空间用“平面”去拟合,更高维度的空间用“超平面”去拟合。那什么是更高维的空间呢?举一个例子:假设我们的数据集收集一个人的信息只有两个属性和特征,一个是身高 ,一个是性别,那么是不是可以在平面上画成一个点呢?比如身高是180,性别是1,那么它的横坐标是180,纵坐标是1,实际上就是一个点,假如有好多个人名和姓名,那么在二维空间里面就有好多个点。假设现在有三个项,体重,120,那么这个二维空间的点就会跑到三维空间了,无论怎么样,只要数据表示出来了都是空间的一个点。假如又扩充了一个维度比如收入,就不能在三维度空间里画出这个点,我们都知道在二维空间里面有直线,在三维空间有平面,在高维空间中是不是也有类似直线或者平面这种直的东西?因为四维空间我们没有办法想象是什么样的,但是我们可以知道它是直的或者平的一种物质 ,我们称这种物质叫做线性空间,而高维空间中的这种线性平面叫做超平面,在高纬度空间中,不能用平面来表示了,所以给起了个抽象的名字叫做超平面,不用去想他是什么样的,我们只要知道他是直的,是平的就行。好,至此我们知道了什么是高维空间,什么是超平面,什么是平面,说了这么多是不是很好奇,为什么还不介绍多元线性回归呢,别着急,一切的铺垫都是为了你更好地理解后面的知识,我们还铺垫一个东西,或者说回顾一些东西。
函数:记号f(x) ,扔进给f一个数经过一系列运算得到的一个结果,函数代表着一种映射(你给我一个值,我给你唯一的指到另一个值上的一个机器),这就是函数。当然官方定义如下:给定任何一个自变量x都有一个唯一的y与之对应的这么一种映射关系,这就叫做函数。
函数的根:是某一个x的取值,x取什么的时候就称作这个函数的根呢?就是x丢到这个机器里面之后结果是0,就叫函数的根,也就是与x轴的交点,也就是x取这个交点的时候y是0,那么我们称这两个x为函数的两个根。
导数:导数就是该点的切线的斜率,描述的函数的变化趋势,导数就是跟着某个点来,也就是给一个x就能给一个导数,x变导数也跟着变。
导函数:就是另一个机器,扔给我一个x ,我就告诉你什么结果,无穷无尽的表,你给我一个x,我就能查到这个x的点在原函数的位置上的导数等于几,由这个导数构成的这个函数叫做导函数。在计算的时候通常现有导数,函数是处处可导,也就是函数可以求出一个导函数来,什么导数在导函数里面算出来。
Log: 幂函数的逆运算。比如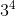 是81 那么
是81 那么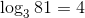 。这就是log.
。这就是log.
Ln:以e为底的对数运算.
好,至此为止本节所需要的内容和基础知识你已经掌握了,是不是很有成就感,学了这么多东西。接下来我们开始慢慢的引入多元函数问题,先抛出来几个问题:
假如你观测到了已知两个数据点 (x,y) 分别是(1,3)(2,5),此时非要让你预测x=3时y=? 如何预测?
假如你观测到了好多个数据点(x,y) 分别是 (1,3),(2,5),(3,7),(4,9)。。。所有数据点都满足同一个否有可能从中学得一些规律用来预测未来呢?
如果是多元的情况呢?(X1,X2,Y)(1,1,4)(2,1,5) (2,2,7) (1,2,6)。(3,1,?)
对于第一个例子我们可以找到规律,随着x每增大1,y增大2 所以x=3时 y是7.总结出一个规律就是y=2x+1
那什么是多元?多元就是上面的数据点从(x,y)变为了(x1,x2…xn,y),也就是从一个x,影响一个y变成多个x影响一个y,这其实就是多元线性回归的本质,即:先假设x,y中间的关系满足多元一次函数 y=w0+w1*X1+w2*X2+w3*X3+…+wn*Xn。(实际满足不满足不用管),做好假设以后,我们就可以拿到一系列的x与y,代到函数里面找到最好的一组w,通常w0是偏置项。上面的例子可以完美的写出来w0,w1..刚好符合这个规律。那假如我们的数据点不是完全符合呢,
比如下面的例子,


上面是一个特征,一个预测值,特征就是房价平米值,平米越大预测的费用越高,我们收集的数据是这样的一些点,其实本质就是画出一条线,然后根据x轴上一个点,y轴得出来一个值。虽然不是特别准,但是前后相差不多,那么这条线怎么画呢,有无数种画法,怎么量化的找到一条最好的线呢?其实就是预测的值与真实的值尽可能的小。好,到此为止,我们知道了多元的含义。为了说清楚怎么量化的找到一条最好的线?我们引入有监督学习的套路:
第一步引入判别函数:
提前假设出来y和x的关系,蛮不讲理。实际上是提供一种形式。比如我们上面的假设y=w0+w1*X1+w2*X2+w3*X3+…+wn*Xn。我们称y是inference function 判别函数,最后预测的时候拍板的,来得到最后的结果是多少的。
第二步引入学习概念:从数据中计算计算,然后生成一个模型,模型就是我们说的要求的w0,w1,w2.。。求解的过程叫做学习。
假如我们手里有一组数据集,还有一个判别函数,我要用多元线性回归来做回归任务,此时判别函数的形式也就有了,那么你需要的所谓的学习或者最好的w。其实所谓学习就是如何通过已知训练集得到一组最好的w。
第三步引入损失函数:
那么如何评价w好不与好呢,需要一个标准,我们称评估w到底好不好的标准的函数叫做损失函数(loss function)。损失函数的功能是评估这组w好还是不好,也就是你给我一个w,我给你一个评分,最后找一个评分最高的w,就是这么一个逻辑。所以损失函数是关于w的一个函数。。不同的算法有不同的损失函数,通常损失的值越低代表这个w越好,因此称之为损失函数。
那么损失函数怎么定义呢?实际上就是我们预测的每一个点和真实之间数据的差距,然后把这些差距累加起来,就能表示当前预测的结果与真实之间的差距,也就是我们的损失函数。
所以我们引入几个小概念:
误差:定义为预测值-真实值=误差。这个值有可能为正,有可能为负。
学习: 能够使当前数据最小的w就是最好的w,不用管给一个什么样的w,只要带进去一算,只要值最小就是最好的,如果训练集变了,那么原来的w 就不是现在的w ,也不是最好的,也就是我的w就是这个训练集上的经验好,这个就是学习。
那具体什么样的参数是好参数呢?
所以我们又引出一个概念:
目标函数:找到一个函数,使这个函数越小的时候模型(也就是W)越好,这个函数就叫做目标函数。
所以我们的目标:使模型在样本上表现最好(总体看起来误差最小),那么自然而然,我们的目标函数就是使误差函数最小,用数学公式表达就是
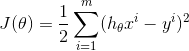
解释: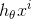 函数就是我们上面所说的判别函数 其中
函数就是我们上面所说的判别函数 其中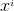 是我们收集上来的,是固定不变的,那么影响这个函数的因素就是
是我们收集上来的,是固定不变的,那么影响这个函数的因素就是 ,这里的是所有w的统称,单个的是w,在一起的就是;
,这里的是所有w的统称,单个的是w,在一起的就是;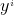 就是我们的真实值。我们把m个样本累加起来,就代表所有预测值与真实值之间的误差的累加。这里的1/2 是因为后面要对损失函数求导,所以有个1/2,有时候也会写成1/m 目的是为了相对公平,比如两万条样本的误差和两条样本的误差去直接比较,肯定是不公平的,所以除以各自的样本个数,是为了相对公平些。这个函数就是我们所说的MSE,最小二乘目标函数。
就是我们的真实值。我们把m个样本累加起来,就代表所有预测值与真实值之间的误差的累加。这里的1/2 是因为后面要对损失函数求导,所以有个1/2,有时候也会写成1/m 目的是为了相对公平,比如两万条样本的误差和两条样本的误差去直接比较,肯定是不公平的,所以除以各自的样本个数,是为了相对公平些。这个函数就是我们所说的MSE,最小二乘目标函数。
所以根据以上介绍,我们可以建立一个算法框架,由2个函数的框架,第一个叫判别函数,他是算法的核心,是如何认识世界的眼睛;另外一个叫做损失函数,他是用来做判定这组参数好与不好,想得到一组最好的参数我们就得有评分标准,我们想取得评分最高的那组参数,通常是这两个函数共同协作得到的那么一个结果。
说到这里,你已经了解了多元线性回归,乃至机器学习的套路。给自己鼓个掌吧!!然后继续。。
目标函数引入出来后,进一步思考,会自然而然想到,为什么是最小二乘,为什么是平方,而不是三次方,四次方。。?带着问题,我们来引入数学,用数学的角度来证明。先回顾一下概率论的基础:
什么是概率?
经过足够多的随机实验之后,每个结果发生的次数占总次数的比值。
频率学派的一种说法,就是说当你试验次数足够多的时候,概率是永远不可知的,频率是可以观测统计的,当你统计的随机试验足够多,那么你统计出来的频率(发生次数除以总次数)频率就会越来越接近于概率,最终可以用频率求的概率。
随机试验:有确定结果的但是每次的结果不一样,那么每做一次,就是随机试验。比如摇骰子,每次结果都不一样,每一次摇都是一次随机试验。
随机变量:描述随机试验结果的变量就是随机变量。
包含两个要素,
1. 随机实验取值的结果范围(可以使离散的,可以是连续的)
2. 随机实验取每个值的概率是多少:随机变量的分布(概率密度函数)
离散型、连续型随机变量
1. 离散型:一批电子元件的次品数目
2. 连续型:一批电子元件的寿命情况
3. 一种解释: 如果随机变量的所有取值可以罗列出来,那么其为离散型随机变量,如果不能(无穷多个可能性)我们称之为连续型随机变量。
随机变量的概率分布
1.概率分布: 随机实验的每种结果的概率的集合
2.概率分布函数: 给定一种结果,返回一个概率的函数
3.对于离散型随机变量:概率分布函数实质上是个列表,对于连续型随机变量:概率分布函数是一个连续函数。
上面比较抽象,我们举例解释:
比如x是一个变量,X
 (1,2,3).那么X 的取值只能是1,2或者3 这种能数的过来的取值对应的变量,我们称之为离散变量。比如X[0,9]之间任意一个数,我们称这种变量为连续变量,取值数不尽。那么随机怎么解释:在于除了需要告诉变量取值外还要告知,成为1的概率是多少,成为2的概率是多少,相当于在这个变量的取值的背后有一张概率表。我们称这个概率表为概率分布。所以离散的概率分布是一张表,那么连续的概率分布这么多点,不可能是一张表,而是对应一个函数,叫做概率分布函数,它是评估连续性随机变量落到某一点上的可能性的大小。比如比如f(x),扔进去一个x就给一个结果,对于连续性的随机变量,比如身高,从1.2m-2m都有可能,那么当身高等于1.84m的时候,带入f(x)函数后,得到一个小数,这个小数就代表1.84m的可能性有多大。这个函数f(x)就是概率密度函数。
(1,2,3).那么X 的取值只能是1,2或者3 这种能数的过来的取值对应的变量,我们称之为离散变量。比如X[0,9]之间任意一个数,我们称这种变量为连续变量,取值数不尽。那么随机怎么解释:在于除了需要告诉变量取值外还要告知,成为1的概率是多少,成为2的概率是多少,相当于在这个变量的取值的背后有一张概率表。我们称这个概率表为概率分布。所以离散的概率分布是一张表,那么连续的概率分布这么多点,不可能是一张表,而是对应一个函数,叫做概率分布函数,它是评估连续性随机变量落到某一点上的可能性的大小。比如比如f(x),扔进去一个x就给一个结果,对于连续性的随机变量,比如身高,从1.2m-2m都有可能,那么当身高等于1.84m的时候,带入f(x)函数后,得到一个小数,这个小数就代表1.84m的可能性有多大。这个函数f(x)就是概率密度函数。
接下来我们聊一个特殊的连续分布函数,高斯分布。请继续阅读第二节。
https://www.cnblogs.com/LHWorldBlog/p/10576619.html