机器学习入门(五):集成学习Bagging,Boosting,RandomForest和GridSearchCV参数调优
0)集成学习
集成学习(ensemble methods)的目的是结合不同的分类器,生成一个meta-classifier, 从而使其拥有比单个classifier有更好的泛化能力(The goal behind ensemble methods to combine different classifiers into a meta-classifier that has a better generalization performance than each individual classifier alone.)
简单举例说明一下其优点,一个人容易犯错,一群人通过少数服从多数能够减少犯错的概率,Bagging中的民主投票Majority Vote就是基于这样的特点。
比如一个分类器的错误率是epsilon = 0.35,那25个这样的分类器共同决策的错误率即为:

这显然大大减少了错误的产生,使分类器性能大幅提升,但需要注意的是,随着错误率的提升,共同决策的性能也会下降:
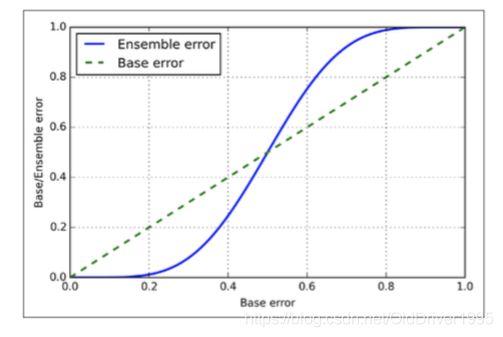
随着错误率提升,ensemble error也在上升,随着错误率超过50%,集体决策的效率也降低了,50%以下适合集成学习,反之则单个分类器效果更好。(这大概是变相吐槽皿煮投票吧hhh)。
首先简单介绍一下各种算法:
一)Bagging算法:

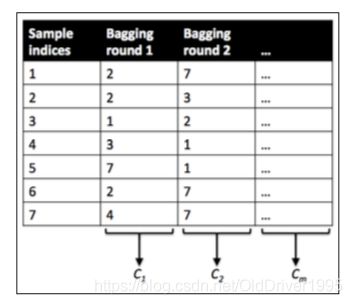
简称袋装法, 英文全称叫Bootstrap Aggregating,其实现过程是随机替换数据样本中的数据(random sample with replacement),生成一个train set,实现一个机器学习模型,重复操作,每次抽取互不干扰,由不同的train set生成k的模型,最后将k个模型采用投票的方式获得分类结果。
生成数据的过程:
二)Boosting算法:
Boosting的思想是通过关注那些错误分类的样本,使得弱分类器学习之后提升整体的性能。(The key concept behind boosting is to focus on training samples that are hard to classify, that is, to let the weak learners subsequently learn from misclassified training samples to improve the performance of the ensemble. )
Boosting选取数据的方式和Bagging不同,它随机选取样本子集,并且不替换。
原始的Boosting流程是这样,分为四步:
a)随机选取子集,训练出弱分类器C1
b)随机选取子集,然后加上50%上一次错误分类的样本,获得一个弱分类器C2
c)从样本中找出与C1,C2不一致的训练数据,获得弱分类器C3
d)通过Majority Vote的方式结合这三个分类器。
2.1)AdaBoost算法:
全称Adaptive Boosting。
和原始的Boost算法不同的是,这个算法使用所有的样本。给训练集Train set添加权重, 每次分类之后,分类正确的数据项会减少权重,分类错误的会增加权重(对的残差小,错的残差大),将修改权重后的数据集再次放入模型,重复迭代。从而实现一个强分类器。
2.2) GradientBoosting算法:
它的核心思想就是让损失函数沿着梯度下降的方向进行。
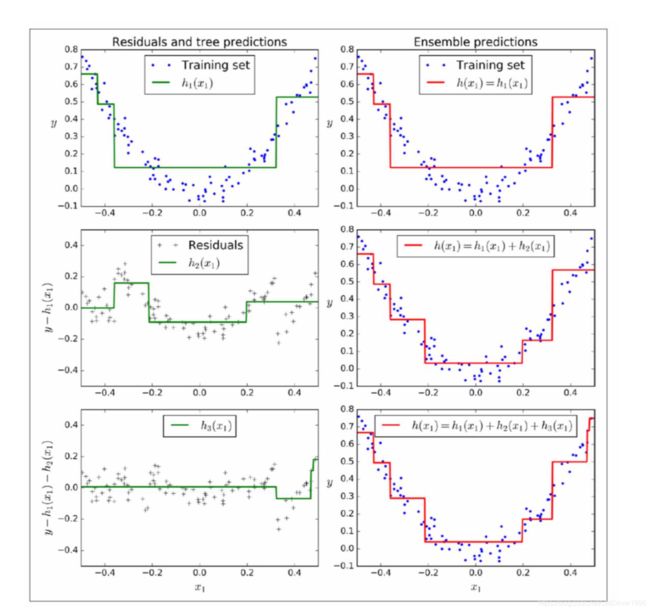
首先用决策树作为基础分类器,每一个模型都会试图去修正上一个模型的error, 而这个error就是y-F(x),或者更简单的说是y_test - y_predict (这样看着比什么最小化损失函数看着更加通俗易懂),即用每次得到的训练集减去上一个模型的预测值y_next = y - y^, 然后DecisionTree().fit(X, y_next)。而每次生成的预测值h = y-F(x),都作为一个修正项,加在上一次的预测中,使得预测越来越贴近真实情况。
来个图比较具体:
三)随机森林:
随机森林可以被看作一堆决策树的集合。
思想很简单,利用Bagging法抽取sample,然后随机抽取数据集的属性features, 生成树的时候,每次只在选择的这些属性中进行比较(通过信息增益或者其他的),然后选择一个属性进行分枝,从而生成整颗树, 故得名随机森林。它的思想是基于Bagging的,而不是Boosting。
四)代码实现:
这里就不一一演示每种模型的训练结果,只展示如何导入,以及如何获得结果,还有如何GridSearchCV调优。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
#导入iris数据
from sklearn.datasets import load_iris
iris = load_iris()
iris.data = iris.data[:,:2] #处理一下数据,方便绘图
X_train, X_test, y_train, y_test = train_test_split(
iris.data, iris.target, stratify=iris.target, random_state=42)
#导入模型
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import BaggingClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import AdaBoostClassifier
from sklearn.ensemble import GradientBoostingClassifier
#导入GridSearch
from sklearn.model_selection import GridSearchCV
#使用随机森林作为模型
RF=RandomForestClassifier(n_estimators=500, max_leaf_nodes=16,random_state=42)
RF.fit(X_train,y_train)
y_predict = RF.predict(X_test)
print(accuracy_score(y_test,y_predict))
测试一下准确率,不是很高
![]()
生成图像查看一下,代码如下:
def plot_boundary(clf, axes):
x1= np.linspace(axes[0], axes[1], 100)
x2= np.linspace(axes[2], axes[3], 100)
xx, yy = np.meshgrid(x1, x2)
x_new = np.c_[xx.ravel(), yy.ravel()]
y_pred = clf.predict(x_new).reshape(xx.shape)
plt.contourf(xx, yy, y_pred, alpha = 0.4, cmap=plt.cm.brg)
plt.plot(X[y==0,0], X[y==0,1],"bs")
plt.plot(X[y==1,0], X[y==1,1], "g^")
plt.plot(X[y==2,0], X[y==2,1],"r*")
plot_boundary(RF, [4, 8, 1.5, 4.5])
plt.show()

然后可以打印 RF.get_params 看一下他有哪些参数是可以调的:

然后就可以设置一下需要调试的参数及备选参数范围,比如分枝时不仅可以计算信息增益,也可以计算基尼系数, 然后n_estimators是指生成树的数量, 还可以设定每次划分时能考虑的最大的特征数,sqrt就是样本数N开方,或者还有log2:
param_g={
'n_estimators':[50,100,200,300,400,500,600],
'criterion':['gini','entropy'],
'max_features':['auto','sqrt']}
#然后调优
gs = GridSearchCV(RF,param_grid=param_g,cv=5)
gs.fit(X_train, y_train)
print(gs.best_score_)
print(gs.best_params_)
然后发现了适合的参数,准确率有所提升,n_estimators需要修改。
![]()
利用best_estimators_这个现有的模型生成调参后的图像:
plot_boundary(gs.best_estimator_, [4, 8, 1.5, 4.5])
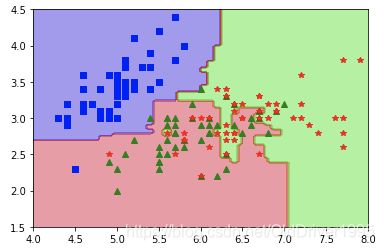
利用这个方法,再也不怕调参数了。
参考文献:Python Machine Learning(作者:Sebastian Raschka)