指令系统和寻址方式
文章目录
- 指令系统
-
- 指令的基本格式
- 扩展码指令格式
- 指令的操作类型
- 指令的寻址方式
-
- 指令寻址
- 数据寻址
-
- 隐含寻址
- 立即寻址
- 直接寻址
- 间接寻址
- 寄存器寻址
- 寄存器间接寻址
- 相对寻址
- 基址寻址
- 变址寻址
- 堆栈寻址
- 使用场景
- PSW
- 小结
- 程序的机器级代码表示
- CISC和RISC
- 刷题小结
指令系统
- 指令:计算机系统执行的命令
- 指令集:一台计算机的所有指令的集合
- ISA:抽象概念,定义了计算机体系结构的基本特征和行为,如指令字格式和指令类型、通用寄存器的个数和位数、数据类型及格式、存储空间的大小和编址方式、寻址方式等
ISA完整定义了软件和硬件的接口,是计算机软/硬件界面之一(操作系统、驱动等也是计算机软/硬件界面)
指令的基本格式

- 指令分为操作码和地址码,操作码指的是执行哪条指令,地址码是要操作的数据存放在哪。
指令的地址由程序计数器PC给出,注意地址码是找到要操作的数据,而下一条要执行的指令是要找到指令的的地址 ,而指令的地址由PC给出。
- 指令的长度,等于机器字长的叫单字长指令,等于半个机器字长的称为半字长指令,等于两个机器字长的称为双字长指令。计算机按字节编址,所以指令的位数是字节的整数倍(算出指令的长度23位足够也要取24位作为答案)
指令系统中如果所有指令的长度相同,就是定长指令字结构,指令的长度随着指令功能在变就称作变长指令字结构
- 指令根据地址码的数目可分为零地址指令、一地址指令、二地址指令,三地址指令、四地址指令
零地址指令:

空操作指令、停机指令、关中断指令。
零地址的运算指令常被用于堆栈寄存器,弹出栈顶和次栈顶的数据进行运算。
一地址指令:

只有目的数的一地址指令:一个数算完存回原地址(a++)。OP(A1)→A1,
隐含约定目的地址的双操作数指令:有一个操作数已经在ACC里面了,默认将结果就存在ACC里,所以只需要提供一个操作数放入ACC进行相加即可。(ACC)OP(A1)→ACC
二地址指令:

(A1)OP(A2)→A1
A1和A2其中有一个目的操作数,算完后结果依旧放在目的操作数中
三地址指令:

(A1)OP(A2)→A3
如果地址都是主存地址,需要四次访存,取指令一次,取两个操作数两次,存放结果一次。(王道教材是这么说的,查到的资料说和具体架构、实现等相关)
四地址指令:

(A1)OP(A2)→A3,A4=下一条要执行的指令的地址
扩展码指令格式
王道视频讲的很清楚

指令的操作类型
-
数据传送:MOV,LOAD,STORE
-
算术和逻辑运算:ADD,SUB,CMP,MUL,DIV,INC,DEC,AND,OR,NOT,XOR
-
转移操作:JMP,BRANCH,CALL,RET,TRAP
-
输入输出操作:完成CPU与外部设备的信息交互
王道书:

指令的寻址方式
指令寻址
指令寻址的目的是为了找到下一条指令在哪。
指令寻址分为顺序寻址和跳跃寻址
- 取指阶段后让PC+“1”,这个1就是让PC指向下一条指令,也就是一个指令字长
顺序寻址:PC+1个指令字长自动形成下一条指令的地址
跳跃寻址:PC在取指后依旧会加“1”,但是当前指令会修改PC的值,比如JMP 7,把PC的值修改为7,下一条就会执行编号为7的指令,实现跳转的结果。

数据寻址
数据寻址的目的是为了获取操作数的地址,然后可以正确的拿到操作数进行指令的执行。
具体的方式有隐含寻址、

形式地址前面会有一个标志来表示是哪种寻址方式,也就是寻址特征。
隐含寻址

比如要算A+B,这种寻址方式中指令里面只需要给出A,而默认B已经放在了ACC里,即不明显的给出第二个操作数的地址值。
| 优点 | 缩短指令字长,需要的存储空间更少,执行效率更高 |
|---|---|
| 缺点 | 增加存储隐含操作数的硬件 |
立即寻址
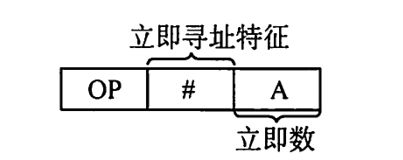
A就是要找的数据的值,比如我们要找的数据是011(B),也就是3,一般是要找到3所在的地址再去拿到3。这种寻址方式就直接把数据3放在了地址位上,就不用寻址了,直接用,寻址特征是#。
| 优点 | 执行时间最短,不用访存 |
|---|---|
| 缺点 | A的位数决定A的数据范围不会很大 |
直接寻址
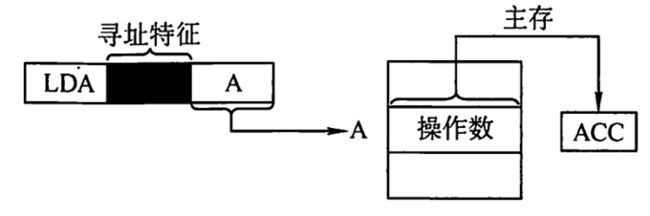
名字听上去和立即寻址很像,需要进行区分。
指令里的地址A就是有效地址EA,或者说数据的真实地址。有效地址我们也称为EA(Effective Address)。这里EA=A
根据A我们就能直接拿到操作数。
| 优点 | 执行速度较快,不需要计算地址,执行阶段只需一次访存 |
|---|---|
| 缺点 | A的位数决定A的寻址范围不会很大 |
比如A的位数为8,那就只能找256个存储单元
间接寻址

EA=(A),指令里的地址A是操作数的地址EA的地址(套娃),多级套娃就需要多次间接寻址。
这种方式一开始看起来很怪,但实际上扩大了寻址范围。因为实际地址EA是存在主存里的,假如有32位,而直接地址可能就只有16位甚至更短,所以这种办法可以扩大寻址范围。
| 优点 | 相对于直接寻址扩大了寻址范围 |
|---|---|
| 缺点 | 多次访存,速度较慢。 |
一次间接寻址需要两次访存,两次间接访存需要三次访存…
寄存器寻址
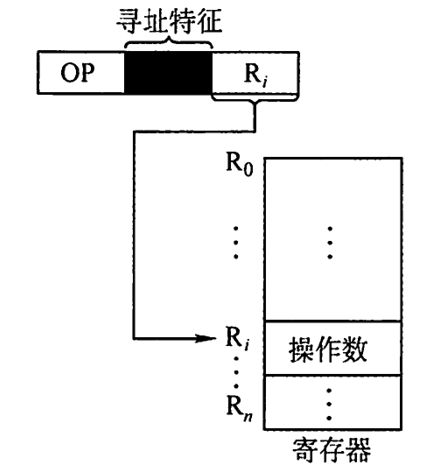
EA=Ri
这里的Ri是寄存器编号,不是主存。
| 优点 | 地址码短使得指令字短且不用访存,执行速度快 |
|---|---|
| 缺点 | 寄存器数量贵,所以数量少 |
寄存器间接寻址

EA=(Ri)
这里的Ri是寄存器编号,不是主存。
| 优点 | 比一般的间接寻址速度快 |
|---|---|
| 缺点 | 仍然需要访存 |
相对寻址

EA = (PC)+A
A是偏移量,PC是下一条指令的位置。
实现JUMP A时可以使用相对寻址,这样就能跳转到指定位置。将偏移量加上PC的值就能得到跳转目标的有效地址
| 优点 | 便于程序浮动,多到程序设计中最重要的寻址方式 |
|---|---|
| 缺点 | 寻址范围收到A的位数限制,比如A为8位,那跳转就局限于[PC-256,PC+256] |
为什么在多道程序设计中,最重要的寻址方式是相对地址寻址,而不是基址寻址?
在多道程序设计中,最重要的寻址方式是相对地址寻址。相对地址寻址是指在指令中使用相对于某个基址(通常是程序计数器或某个专用寄存器)的偏移量来表示操作数的地址。这种寻址方式适用于多道程序设计,因为它使得程序可以在内存的任何位置运行,而不需要修改指令中的地址值。
虽然基址寻址对于多道程序设计有一定的好处,但它并不是最重要的寻址方式。基址寻址是指使用专用寄存器(称为基地址寄存器)存储基址,然后在指令中使用偏移量来表示操作数的地址。这种方式确实可以改进程序的可重定位性,但它也有一些缺点:
- 基址寻址需要使用额外的寄存器来存储基址,这可能在寄存器有限的硬件环境中不是最优选择。
- 当程序需要访问不同的内存区域时,需要频繁地更新基址寄存器。这会增加程序的复杂性和执行时间。
相比之下,相对地址寻址不需要额外的寄存器,也不需要频繁地更新基址。因此,在多道程序设计中,相对地址寻址比基址寻址更为重要。
基址寻址

EA=(BR)+A或EA=(R0)+A
BR是一个基址寄存器,寄存器里的内容由操作系统确定,用户不能更改。
| 优点 | 扩大了A的寻址范围(BR的位数大于A的位数),利于多道程序设计 |
|---|---|
| 缺点 | 这块缺点没找到(找到的资料全是王道的书) |
变址寻址

EA=(IX)+A
IX是一个寄存器,编址寻址的IX可以由用户自己设置。
| 优点 | 利于编址循环程序和处理数组,比起基址寻址更具有灵活性和通用性 |
|---|---|
| 缺点 | 增加了指令的数量和和程序的复杂度(王道书上也没讲缺点,只讲了特点) |
堆栈寻址
硬堆栈:寄存器堆栈
软堆栈:从主存中划出一部分区域来做堆栈
硬堆栈不访存,软堆栈访存一次
堆栈寻址的特点是使用一个栈指针寄存器(通常称为SP寄存器)来管理堆栈中数据的存储和取出。SP寄存器里的内容是栈顶的地址。
使用场景
- 立即寻址:适用于需要访问常数或立即数的指令,例如赋值操作等。
- 直接寻址:适用于内存空间地址已知且固定的情况,例如静态数据的存储和读取。
- 寄存器寻址:适用于需要频繁访问寄存器中的数据的指令,因为寄存器的访问速度比内存快得多,例如循环中的计数器变量等。
- 寄存器间接寻址:适用于通过寄存器访问内存中的数据,例如数组中的元素。
- 基址寻址:适用于需要动态分配内存或需要访问偏移地址的情况,例如程序中动态分配内存的操作。
- 变址寻址:适用于数组和矩阵等数据结构的处理,因为数组和矩阵中的元素通常是按一定规律排列的,可以通过寄存器中的偏移量来访问数组和矩阵中的元素。
- 堆栈寻址:适用于程序中的函数调用和返回等操作,因为函数调用和返回时需要保存和恢复栈中的数据。
PSW
cmp指令比较a和b实际上是执行a-b
状态字寄存器PSW会记录a-b的结果,根据PSW的几个标志位进行判断来决定是否转移。
| 标志位 | 含义 |
|---|---|
| 进位标志CF | 进位则为1,否则为0 |
| 零标志ZF | 结果为0则ZF为1,否则为0 |
| 符号位标志SF | 结果为负则SF为1,否则为0 |
| 溢出标志OF | 结果溢出则OF为1,否则为0 |
小结
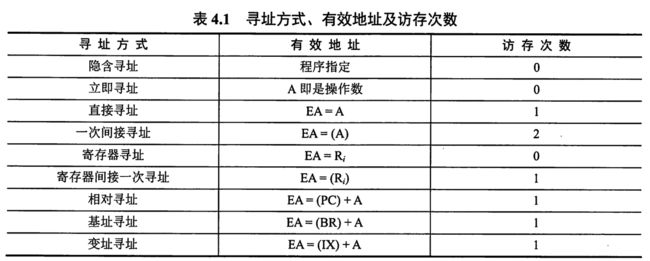
除了间接寻址外别的寻址方式最外层都没有括号,说明别的寻址方式通过加减之后可以直接得到EA,而不用再去取一次存储单元的值得到EA。
程序的机器级代码表示
常见的汇编指令和通用寄存器如下:
汇编指令:
- MOV:数据传送指令,用于将一个源操作数的值传送到目的操作数中。
- ADD:加法指令,将两个操作数相加,并将结果存放到目的操作数中。
- SUB:减法指令,将两个操作数相减,并将结果存放到目的操作数中。
- CMP:比较指令,将两个操作数进行比较,结果不存储,只修改标志寄存器。
- JMP:跳转指令,将程序执行的控制权转移到另一个指定的地址处。
- JZ:零标志位跳转指令,当零标志位为1时,将程序执行的控制权转移到指定的地址处。
- JE:等于标志位跳转指令,当等于标志位为1时,将程序执行的控制权转移到指定的地址处。
- JNE:不等于标志位跳转指令,当等于标志位为0时,将程序执行的控制权转移到指定的地址处。
- CALL:调用指令,将当前指令的下一条指令的地址压入栈中,并将控制权转移到指定的过程中。
通用寄存器:
- AX:累加器寄存器,用于存储运算结果和参与运算的数据。
- BX:基址寄存器,用于存放数据存储区的基地址。
- CX:计数器寄存器,用于循环和移位指令中的计数器。
- DX:数据寄存器,用于存放数据和进行数据传输操作。在乘法和除法指令中用于存放操作数或运算结果的高位。
- SI:源变址寄存器,用于存放源操作数的偏移地址。
- DI:目的变址寄存器,用于存放目的操作数的偏移地址。
- SP:栈指针寄存器,用于存放栈顶地址。
- BP:基址指针寄存器,用于存放数据存储区的基地址,通常与堆栈操作有关。
CISC和RISC
CISC和RISC是指令系统的两种设计方向
直接贴王道课件了


简单来说:CISC就像给了你C语言语法+库函数,RISC相当于只给了C语言语法。
CISC更难优化编译代码,RISC更容易。且CISC由于指令复杂导致电路也比较复杂,而RISC电路简单。
这些年都在向RISC靠,以前是CISC
RISC和CISC不具备直接的兼容性,两者都不能运行对方的机器码,在兼容性这块上基本扯不上关系。(实现上有一些技术可以将RISC指令翻译为CISC指令)
RISC的指令字长是定长,只用Load和Store指令,且按边界对齐存放,这些使得取指令、去操作数的操作简化且时间长度固定,可以有效地简化流水线的复杂度。
刷题小结
-
机器语言是指令系统的实现方式,且指令系统的出现避免了用户编写程序时直接与二进制打交道。
-
指令的地址由PC给出
-
中断隐指令是一种处理器指令,是为了能够让处理器执行当前任务时随时响应设备的中断请求,完成中断后返回原来的程序执行。他是由外部事件触发的,中断隐指令的执行和程序的正常流程是分离的,所以中断隐指令不是程序控制指令。
-
如果说一指令有254条,从0编址是编到253,所以写题时得注意别写成254。
-
指令系统中采用不同寻址方式的目的是可缩短指令字长,扩大寻址空间,提高编程的灵活性
-
直接寻址的无条件转移指令的功能是将指令的地址码送入PC中,而不是MAR.
-
操作数和操作数的有效地址需要进行区分,寄存器寻址的寄存器中存的就是操作数,寄存器间接寻址的寄存器中存的是EA,还要通过这个EA去主存里拿到操作数
-
有些寻址方式需要标识是哪个寄存器的得分配位数给寄存器编号
-
基址寻址的形式地址,即地址码里放的是补码,如果所给补码是4位,而主存地址是8位,这时需要进行符号扩展,不然基址加上偏移量的结果是错的。
-
PSW的各个标志位需要注意,比如SF表示的是符号位标志,但是是负数时为1,而结果为0时符号位标志也是0.
-
题目给了有多少种寻址方式的话得注意指令字长分配位数时要考虑指令特征。比如有4个指令的话指令特征要分配2位。
-
CISC会尽量去增强指令的功能,且需要用到微程序处理器。而RISC是不用或少用微程序处理器,以硬布线控制器为主(电路被设计为直接执行指令)。
-
基址寻址的基址寄存器面向操作系统,用户操作不了,而变址寻址的寄存器面向用户,用户可操作,所以数组操作时常常可以用上变址寻址。
-
大端模式下指令中给出的地址是MSB,小端模式下指令给出的地址是LSB(0x123456里的MSB是0x12,LSB是0x56)