Linux中的中断管理机制
1、中断相关基础知识介绍
1.1、中断产生背景
假设现在CPU需要去获取一个键盘的时间,如果处理器发出一个请求信号之后一直在轮询键盘的响应,由于键盘响应速度比处理器慢得多并且需要等待用户输入,这对于CPU来说是非常浪费资源的。与其这样,还不如等到键盘有事件发生的时候再发送一个信号给处理器,让处理器暂停当前的工作来处理这个响应,这比处理器一直轮询等待效率要高,这就是中断管理机制产生的背景。
1.2、ARM中断管理器
不同的体系结构对中断控制器有着不同的设计理念, 例如ARM公司提供了一个通用中断控制器(Generic Interrupt Controller, GIC),x86体系架构则采用了高级可编程中断控制器(Advanced Programmable Interrupt Controller, APIC)。这篇文章我们主要是基于ARM平台来介绍中断管理的实现。
GIC规范支持下面中断类型:
软件触发中断(Software Generated Interrupt,SGI):通常用于多核之间通信。硬件中断号从ID0~ID15私有外设中断(Private Peripheral Interrupt,PPI):这是每个处理核心私有的中断。硬件中断号从ID16~ID31外设中断(Shared Peripheral Interrupt,SPI):共用的外设中断。硬件中断号从ID32~IDX(IDX的意思是不同的ARM中断控制器,拥有的中断号数目不一样)
RK3288 provides an general interrupt controller(GIC) for Cortex-A17 MPCore processor, which only has 112 SPI (shared peripheral interrupts) interrupt sources and 3 PPI(Private peripheral interrupt)——在RK3288平台上,使用的Cortex-A17 ARM架构,上面是有112个SPI中断,3个PPI中断
GIC中断控制器主要由两个部分组成,分别是 仲裁单元(distributor ,为每一个中断源维护一个状态机,支持inactive、pending、active和active and pending状态)和 CPI接口模块(CPU Interface)。
2、GIC检测中断流程
当发生一个外设中断后
a:一个中断M产生,发生了电平变化,被中断控制器中的仲裁单元检测到了(仲裁单元检测中断信号)b:然后仲裁单元会把这个中断M的状态设置为pending(等待状态)(仲裁单元将中断信号设置为pending状态)c:然后过了一段时间后,中断控制器中的CPU Interface模块会把nFIQCPU[n]信号拉低,目的是向CPU报告中断请求,然后将中断M的硬件中断号存放到GICC_IAR寄存器中(CPU Interface向CPU报告中断请求)d:如果这个时候有一个更高优先级的中断N来了,由于中断控制器支持优先级抢占功能,所以这个时候N会变成当前CPU所有pending状态下优先级最高的中断(意味着它会被优先分配)。(发生中断抢占)e:然后跟步骤c一样,过了一段时间后,CPU Interface模块会再次去把nFIQCPU[n]信号拉低,由于这个时候nFIQCPU[n]已经是低电平了,所以只需要更新GICC_IAR寄存器的值为中断N的硬件中断号(设置新的优先级较高的中断信号)f:然后CPU就会去读取GICC_IAR寄存器,把寄存器中的硬件中断号读出来,也就相当于是响应中断了。这个时候仲裁单元就会把中断N的状态从pending变成了activce and pending。(响应中断信号)g:然后后面就是Linux内核处理中断N的中断服务程序了(处理中断)h:在Linux中断处理中断N的过程中,CPU Interface模块会重新拉高nFIQCPU[n]信号,当中断N处理完成后,会将N的硬件中断号写入到GICC_EOIR寄存器中,表示完成中断N的全部处理过程。i:然后中断控制器的仲裁单元,会重新选择该CPU下pending状态的中断中优先级最高的一个,发送该中断请求给CPU Interface模块,继续前面的流程。

3、中断注册
先由两个问题来开启这个问题的讨论
1、用户是怎么使用中断的? 使用request_irq/request_threaded_irq向内核注册中断
2、request_irq/request_threaded_irq使用的irq中断号是软件中断号,它是怎么来的? 它又是如何映射到具体的硬件设备的?
(其实request_irq函数调用的也是request_threaded_irq函数,只是传参的时候线程处理函数thread_fn函数设置成NULL)
3.1、request_irq
request_irq函数原型如下:
static inline int __must_check request_irq(unsigned int irq, irq_handler_t handler, unsigned long flags, const char *name, void *dev)
{
return request_threaded_irq(irq, handler, NULL, flags, name, dev);
}
irq:IRQ中断号,这里使用的是软件中断号,不是硬件中断号handler:中断处理函数thread_fn:中断线程化的处理函数。如果这个参数不为NULL,就会创建一个内核线程irqflags:中断标志位devname:该中断名称dev_id:传递给中断处理程序的参数
request_irq函数的调用关系如下:
request_irq
request_threaded_irq 1--根据获取到的软件中断号, 向内核注册中断
irq_to_desc 2--根据传进来的软件中断号,获取中断描述符irq_desc
action = kzalloc(sizeof(struct irqaction), GFP_KERNEL); 3--填充一个irqaction结构体
action->handler = handler; 4--将设备驱动中的handler填充到action->handle中
action->thread_fn = thread_fn;
action->flags = irqflags;
action->name = devname;
action->dev_id = dev_id;
__setup_irq 5--对中断请求进行判断,是否线程化等....

3.2、request_threaded_irq
request_threaded_irq被称为 中断线程化,明明已经有了request_irq了,为什么还需要request_threaded_irq, 为什么需要将中断线程化??
中断线程化目的是为了降低中断处理对系统实时延迟的影响。 可以这么说会比较难理解,我们来看进一步的解释。在Linux内核中,中断具有最高的优先级,只要有中断发生,内核会暂停手头的工作去处理中断时间,只有所有挂起等待的中断和软中断都处理完毕后才会继续回去执行中断前的任务,因此这个过程会造成实时任务的不及时处理。中断线程化的目的就是把中断处理中的一些繁重的任务作为内核线程来运行,让实时进程能够有比中断线程更高的优先级,让实时进程可以得到优先处理。
稍微了解了中断的注册,这个时候又有一个问题:那刚才说的request_irq/request_threaded_irq中使用的irq参数是虚拟中断号,但是在DTS中配置的是硬件中断号,它们之间是怎么转换的呢? 这就涉及到中断号之间的映射了。
4、硬件中断号和Linux中断号的映射
接着上面的内容,我们都知道了Linux驱动中,注册中断的API函数request_irq()/request_threaded_irq()是使用了Linux内核软件中断号(俗称软件中断号或者IRQ中断号),而不是硬件中断号。
4.1、中断在DTS中的配置
我们先来看看中断在DTS中的配置是什么样的,对ARM平台来说,所有与硬件相关的信息都是采用DTS的方式进行配置,看下面例子:
pio: 1000b000.pinctrl {
compatible = "mediatek,mt6771-pinctrl";
reg_bases = <&gpio>,
<&iocfg_0>,
<&iocfg_1>,
<&iocfg_2>,
<&iocfg_3>,
<&iocfg_4>,
<&iocfg_5>,
<&iocfg_6>,
<&iocfg_7>;
reg_base_eint = <&eint>;
pins-are-numbered;
gpio-controller;
gpio-ranges = <&pio 0 0 191>;
#gpio-cells = <2>;
interrupt-controller;
#interrupt-cells = <4>;
interrupts = <GIC_SPI 177 IRQ_TYPE_LEVEL_HIGH>;
};
上面是一个名为pio的节点,我们看看这个节点中跟中断相关的信息都是什么意思:
interrupts
我们可以看到,对于这个节点来说,interrupt =这个代表的是什么意思呢?看过上面介绍的童鞋应该可以猜到,第一个参数, GIC_SPI指的是,这个中断属于外设中断(SPI),后面的177代表的是中断号,代表的是实际上的物理中断,但是由于该中断属于SPI中断,而SPI的中断号的范围是ID32~IDX,所以实际的中断号应该是177+32=209,第三个参数指的是中断的触发类型。interrupt-controller
拥有这个属性的设备表示是一个中断控制器interrupt-cells
用于指定编码一个中断源所需要的单元个数
4.2、硬件中断号和软件中断号的映射过程
我们先来了解一下大概的函数调用过程,然后后面再来一一解释用到的核心的结构体
在Linux内核驱动中,我们一般使用irq_of_parse_and_map这个函数作为入口,来实现硬件中断号到虚拟中断号的映射,我们看看它是如何一步一步调用其他函数,最终实现映射功能的。(在Linux内核中,也有其他函数同样可以实现中断号的映射功能,比如platform_get_irq_byname,不过最终调用到的函数都是一样的,所以在这里我们就以 irq_of_parse_and_map 为例来进行分析就可以了)
4.2.1、映射入口函数irq_of_parse_and_map
- 函数原型:
unsigned int irq_of_parse_and_map(struct device_node *dev, int index)
unsigned int irq_of_parse_and_map(struct device_node *dev, int index)
{
struct of_phandle_args oirq;
if (of_irq_parse_one(dev, index, &oirq))
return 0;
return irq_create_of_mapping(&oirq);
}
总的调用框图如下,可结合这张图看下下面的描述:
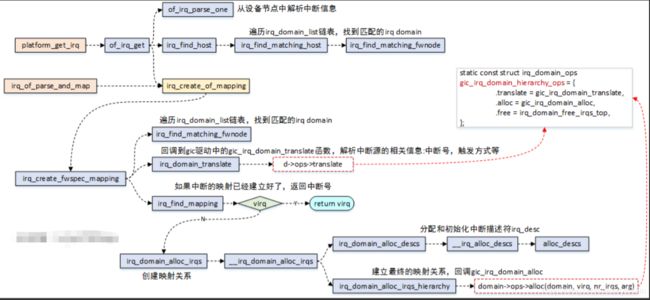

4.2.2、中断管理核心的数据结构
4.2.2.1、irq_desc
-
struct irq_desc:Linux中每一个产生的中断都会使用一个
irq_desc结构体来描述,我们来看看这个irq_desc结构体里面都有什么内容struct irq_desc { struct irq_common_data irq_common_data; struct irq_data irq_data; unsigned int __percpu *kstat_irqs; irq_flow_handler_t handle_irq; struct irqaction *action; /* IRQ action list * ......... }
4.2.2.2、irq_data
-
struct irq_data:可以看到,
irq_desc结构体中,有一个比较重要的结构体,irq_data,我们来看看它里面又有啥struct irq_data { u32 mask; unsigned int irq; unsigned long hwirq; struct irq_common_data *common; struct irq_chip *chip; struct irq_domain *domain; void *chip_data; };irq结构体里面的成员相信大家都不会陌生
- 1)
irq:软件中断号 - 2)
hwirq:硬件中断号 - 3)
irq_chip:代表的是对硬件中断器的操作 - 4)
irq_domain:是一个中断控制器的抽象描述,主要任务是完成硬件中断号到Linux软件中断号的映射
- 1)
4.2.2.3、irq_chip
-
struct irq_chip:如上所说,
irq_chip结构体就是包含了一系列对硬件中断器的操作函数struct irq_chip { struct device *parent_device; const char *name; unsigned int (*irq_startup)(struct irq_data *data); void (*irq_shutdown)(struct irq_data *data); void (*irq_enable)(struct irq_data *data); void (*irq_disable)(struct irq_data *data); ........ }
4.2.2.4、irq_domain
-
struct irq_domain一个中断控制器用一个
irq_domain数据结构来抽象描述,以前SoC内部的中断管理比较简单,通常有一个全局的中断状态寄存器,每个比特位管理一个外设中断,直接简单的映射硬件中断号到Linux IRQ中断号即可。但是,随着Soc的发展,SoC内部包含了多个中断控制器,比如传统的中断控制器GIC,GPIO类型的中断控制器等。面对如此复杂的硬件,导致之前的Linux内核管理机制无法较好得管理,这个时候就没办法沿用之前的一一对应的中断管理方式,因为多个中断控制器,可能存在相同的硬件中断号,当需要映射为Linux系统中的虚拟中断号时,不知道这个硬件中断号到底是哪个中断控制器发出的,所以在Linux 3.1内核就引入了IRQ domain这一个概念。简单点来说,IRQ domain结构体是一个包含一些将硬件中断号转换为虚拟中断号的函数的一个东东。struct irq_domain { struct list_head link; const char *name; const struct irq_domain_ops *ops; void *host_data; unsigned int flags; unsigned int mapcount; /* Optional data */ struct fwnode_handle *fwnode; enum irq_domain_bus_token bus_token; struct irq_domain_chip_generic *gc; /* reverse map data. The linear map gets appended to the irq_domain */ irq_hw_number_t hwirq_max; unsigned int revmap_direct_max_irq; unsigned int revmap_size; struct radix_tree_root revmap_tree; unsigned int linear_revmap[]; }; -
irq_domain_ops:我们前面说到,
irq_domain是一个中断控制器的抽象描述,它的作用就是实现硬件中断号到Linux软件中断号的映射,那么这个映射是由irq_domain中的哪个成员来实现的呢?答案就是irq_domain_ops,它里面包含了一系列的操作函数struct irq_domain_ops { int (*match)(struct irq_domain *d, struct device_node *node, enum irq_domain_bus_token bus_token); int (*select)(struct irq_domain *d, struct irq_fwspec *fwspec, enum irq_domain_bus_token bus_token); int (*map)(struct irq_domain *d, unsigned int virq, irq_hw_number_t hw); void (*unmap)(struct irq_domain *d, unsigned int virq); int (*xlate)(struct irq_domain *d, struct device_node *node, const u32 *intspec, unsigned int intsize, unsigned long *out_hwirq, unsigned int *out_type); }
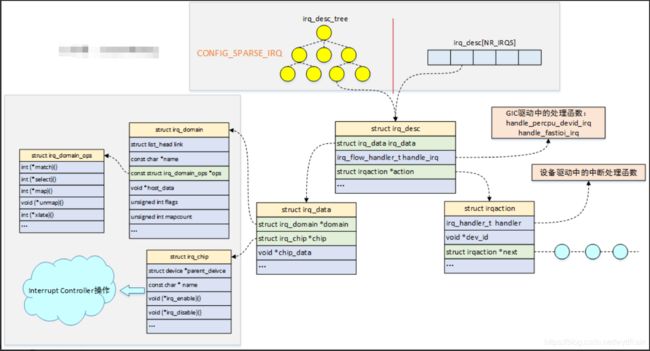
4.2.2.5、irq_desc结构体概览图
上面所描述的结构体之间的关系可以看下面的概览图:
4.2.3、中断映射过程中核心流程的具体实现
有兴趣的同学可以进一步看这一块内容,如果只是想了解大概框架的话,这一块内容可以跳过
既然要看硬件中断号是怎么映射成软件中断号的,而中断控制器又是负责这一项工作的,当然就得从中断控制器看起
5、中断控制器
5.1、中断控制器的DTS配置
在ARM平台上,中断控制器的硬件信息都是通过DTS来进行描述的,我们先来看看一个中断控制器在DTS中是怎么配置的,以联发科的MT8788平台为例,GIC的dts节点内容如下:
gic: interrupt-controller@0c000000 {
compatible = "arm,gic-v3";
#interrupt-cells = <3>;
#address-cells = <2>;
#size-cells = <2>;
#redistributor-regions = <1>;
interrupt-parent = <&gic>;
interrupt-controller;
reg = <0 0x0c000000 0 0x40000>, // distributor
<0 0x0c100000 0 0x200000>, // redistributor
<0 0x0c530a80 0 0x50>; // intpol
interrupts = <GIC_PPI 9 IRQ_TYPE_LEVEL_HIGH>;
};
5.2、查找对应驱动代码
通过compatible属性,我们可以找到这个gic的中断控制器对应的驱动代码是哪个——irq-gic-v3.c
-
代码入口:IRQCHIP_DECLARE(gic_v3, "arm,gic-v3", gicv3_of_init); #define IRQCHIP_DECLARE(name, compat, fn) OF_DECLARE_2(irqchip, name, compat, fn) #define OF_DECLARE_2(table, name, compat, fn) _OF_DECLARE(table, name, compat, fn, of_init_fn_2) #define _OF_DECLARE(table, name, compat, fn, fn_type) \ static const struct of_device_id __of_table_##name \ __used __section(__##table##_of_table) \ = { .compatible = compat, \ .data = (fn == (fn_type)NULL) ? fn : fn }所以
IRQCHIP_DECLARE这个函数已经定义了驱动的compatible是arm,gic-v3,和DTS中匹配上后, 就会调用gicv3_of_init函数
6、中断中的上下半部机制
6.1、上下半部机制产生的原因
什么是中断? 比如你现在肚子饿了,然后叫了个外卖,叫完外卖后你肯定不会傻傻坐在那里等电话响,而是会去干其他事情,比如看电视、看书等等,然后等外卖小哥打电话来,你再接听了电话后才会停止看电视或者看书,进而去拿外卖,这就是一个中断过程。你就相当于CPU,而外卖小哥的电话就相当于一个硬件中断。
什么是中断上下部? 继续参考上面的例子,比如你现在叫的是两份外卖,一份披萨一份奶茶,由两个不同的外卖小哥配送,当第一个送披萨的外卖小哥打电话来的时候(硬件中断来了),你接起电话,跟他聊起了恋爱心得,越聊越欢,但是在你跟披萨小哥煲电话粥的时候,奶茶外卖小哥打电话来了,发现怎么打也打不进来,干脆就把你的奶茶喝了,这样你就痛失了一杯奶茶,这个就叫做中断缺失。所以我们必须保证中断是快速执行快速结束的。 那有什么办法可以保护好你的奶茶呢?当你接到披萨小哥的电话后,你跟他说,我知道外卖来了,等我下楼的时候我们面对面吹水,电话先挂了,不然奶茶小哥打不进来,这个就叫做 中断上半部处理,然后等你下楼见到披萨小哥后,面对面吹水聊天,这个就叫做 中断下半部处理,这样在你和披萨小哥聊天的过程中,手机也不占线,奶茶小哥打电话过来你就可以接到了。所以我们一般在中断上半部处理比较紧急的时间(接披萨小哥的外卖),然后在中断下半部处理执行时间比较长的时间(和披萨小哥聊天),把中断分成上下半部,也可以保证后面的中断过来不会发生中断缺失
上半部通常是完成整个中断处理任务中的一小部分,比如硬件中断处理完成时发送EOI信号给中断控制器等,就是在上半部完成的,其他计算时间比较长的数据处理等,这些任务可以放到中断下半部来执行。Linux内核并没有严格的规则约束究竟什么样的任务应该放到下半部来执行,这是要驱动开发者来决定的。中断任务的划分对系统性能会有比较大的影响。
那下半部具体在什么时候执行呢? 这个没有确定的时间点,一般是从硬件中断返回后的某一个时间点内会被执行。下半部执行的关键点是允许响应所有的中断,是一个开中断的环境。 下半部的中断常见的包括软中断、tasklet、工作队列。
6.2、SoftIRQ 软中断
目前驱动中只有块设备和网络子系统使用了软中断,目前Linux内核开发者不希望用户再扩展新的软中断类型,如有需要,建议使用tasklet机制(后面会介绍)。
6.2.1、软中断类型
目前已经定义到的软中断类型如下:(可与看到定义的是枚举类型,索引号越小,软中断优先级越高)
enum
{
HI_SOFTIRQ=0, //优先级为0,是最高优先级的软中断类型
TIMER_SOFTIRQ, //优先级为1,用于定时器的软中断
NET_TX_SOFTIRQ, //优先就为2,用于发送网络数据包的软中断
NET_RX_SOFTIRQ, //优先级为3,用于接收网络数据包的软中断
BLOCK_SOFTIRQ, //优先级为4,用于块设备的软中断
IRQ_POLL_SOFTIRQ,
TASKLET_SOFTIRQ, //优先级为6,专门为tasklet机制准备的软中断
SCHED_SOFTIRQ, //优先级为7,进程调度以及负载均衡
HRTIMER_SOFTIRQ, //优先级为8,高精度定时器
RCU_SOFTIRQ, //优先级为9,专门为RCU服务的软中断
NR_SOFTIRQS
};
6.2.2、描述软中断的结构体
系统中定义了一个用来描述软中断的数据结构struct softirq_action,并且定义了软中断描述符数组softirq_desc[],每个软中断类型对应一个描述符,其中软中断的索引号就是该数组的索引
6.2.3、软中断的接口
open_softirq()函数:注册一个软中断
void open_softirq(int nr, void (*action)(struct softirq_action *))
nr:代表你希望注册的这个软中断是什么类型的(优先级是多少)
softirq_action:用来描述软中断的结构体
raise_softirq()函数:主动触发一个软中断的API接口函数
void raise_softirq(unsigned int nr)
6.3、tasklet
6.3.1、什么是tasklet?
tasklet是利用软中断实现的一种下半部机制,本质上是软中断的一个变种,运行在软中断上下文中。tasklet由tasklet_struct数据结构来描述
struct tasklet_struct
{
struct tasklet_struct *next;
unsigned long state;
atomic_t count;
void (*func)(unsigned long);
unsigned long data;
};
enum
{
TASKLET_STATE_SCHED, /* Tasklet is scheduled for execution */
TASKLET_STATE_RUN /* Tasklet is running (SMP only) */
};
next属性:多个tasklet串成一个链表state属性:有两个值。TASKLET_STATE_SCHER表示tasklet已经被调度,TASKLET_STATE_RUN表示tasklet正在运行中count属性:为0表示tasklet处于激活状态;不为0表示tasklet被禁止,不允许执行func:tasklet处理程序data:传递参数给tasklet处理函数
6.3.2、什么时候执行tasklet呢?是在驱动调用了tasklet_schedule()后马上执行吗?
由于tasklet是基于软中断机制的,一次tasklet_schedule()后不会马上执行,要等到软中断被执行时才有机会运行tasklet。 tasklet挂入到哪个CPU的tasklet_vet链表,那么就由该CPU的软中断来执行。(每个CPU会维护两个tasklet链表,一个普通优先级的tasklet_vec,另一个用于高优先级的tasklet_hi_vec)
6.3.3、tasklet的使用
要像在驱动中使用tasklet,首先需要定义一个tasklet,可以静态声明,可以动态初始化
6.3.3.1、静态定义tasklet
#define DECLARE_TASKLET(name, func, data) \
struct tasklet_struct name = { NULL, 0, ATOMIC_INIT(0), func, data }
#define DECLARE_TASKLET_DISABLED(name, func, data) \
struct tasklet_struct name = { NULL, 0, ATOMIC_INIT(1), func, data }
可以看到静态声明tasklet的方式有两个,DECLARE_TASKLET和DECLARE_TASKLET_DISABLED,它们的区别是DECLARE_TASKLET把count初始化为0,表示tasklet处于激活状态,而DECLARE_TASKLET_DISABLED相反,把count初始化为1,表示tasklet处于关闭状态。
6.3.3.2、动态定义tasklet
当然,除了上面说的静态声明tasklet外,也可以在驱动代码中调用tasklet_init()函数动态初始化tasklet
void tasklet_init(struct tasklet_struct *t,
void (*func)(unsigned long), unsigned long data)
{
t->next = NULL;
t->state = 0;
atomic_set(&t->count, 0);
t->func = func;
t->data = data;
}
EXPORT_SYMBOL(tasklet_init);
6.3.3.3、调度tasklet
在驱动程序中调度tasklet可以使用tasklet_schedule()函数
static inline void tasklet_schedule(struct tasklet_struct *t)
{
if (!test_and_set_bit(TASKLET_STATE_SCHED, &t->state))
__tasklet_schedule(t);
}
test_and_set_bit()原子地设置tasklet_struct->state成员为TASKLET_STATE_SCHED标志位,返回旧的state的值,如果返回true,那么说明这个tasklet已经在tasklet链表中,不需要再重新挂入,如果返回false,说明这个tasklet还没挂入到tasklet链表中,使用__tasklet_schedule函数把该tasklet挂入链表中。
6.3.3.4、tasklet使用例子讲解
假设我们在硬件中断处理函数中调用tasklet_schedule()函数去触发tasklet来处理一些数据,比如数据复制、数据转换等。以driver/char/snsc_event.c为例
- 首先用request_irq注册一个中断
//request_threaded_irq(irq, handler, NULL, flags, name, dev);
rv = request_irq(SGI_UART_VECTOR, scdrv_event_interrupt,
IRQF_SHARED, "system controller events", event_sd);
- 进入
scdrv_event_interrupt处理函数
static irqreturn_t scdrv_event_interrupt(int irq, void *subch_data)
{
struct subch_data_s *sd = subch_data;
unsigned long flags;
int status;
spin_lock_irqsave(&sd->sd_rlock, flags);
status = ia64_sn_irtr_intr(sd->sd_nasid, sd->sd_subch);
if ((status > 0) && (status & SAL_IROUTER_INTR_RECV)) {
tasklet_schedule(&sn_sysctl_event);
}
spin_unlock_irqrestore(&sd->sd_rlock, flags);
return IRQ_HANDLED;
}
DECLARE_TASKLET(sn_sysctl_event, scdrv_event, 0);
分析一下上面的驱动,首先系统里面已经注册了一个中断SGI_UART_VECTOR,当这个硬件中断发生时,就会调用到上半部的中断处理函数,scdrv_event_interrupt,在该上半部的处理函数中,会调用到tasklet_schedule函数来执行下半部的操作,这个tasklet最终回调到的函数是scdrv_event()函数。
6.3.4、tasklet的注意事项
tasklet是串行执行的。一个tasklet在tasklet_schedule()时会绑定某个CPU的tasklet_vec链表,它必须要在改CPU上执行完tasklet的回调函数才会和该CPU松绑。 为什么???
我们先来看看tasklet_action的实现,还记得这个函数是干什么的吗?? 往上看看,我们在注册软中断的时候,会用到open_softirq函数来注册软中断,而这个函数的其中一个参数就是tasklet_action的回调,也就是当软中断执行的时候,就会调用到tasklet_action,我们来看看它的具体实现
0 static __latent_entropy void tasklet_action(struct softirq_action *a)
1 {
2 struct tasklet_struct *list;
3 unsigned long long ts;
4
5 local_irq_disable();
6 list = __this_cpu_read(tasklet_vec.head);
7 __this_cpu_write(tasklet_vec.head, NULL);
8 __this_cpu_write(tasklet_vec.tail, this_cpu_ptr(&tasklet_vec.head));
9 local_irq_enable();
10
11 while (list) {
12 struct tasklet_struct *t = list;
13
14 list = list->next;
15
16 if (tasklet_trylock(t)) {
17 if (!atomic_read(&t->count)) {
18 if (!test_and_clear_bit(TASKLET_STATE_SCHED,
19 &t->state))
20 BUG();
21 check_start_time(ts);
22 t->func(t->data);
23 check_process_time("tasklet %ps", ts, t->func);
24 tasklet_unlock(t);
25 continue;
26 }
27 tasklet_unlock(t);
28 }
29
30 local_irq_disable();
31 t->next = NULL;
32 *__this_cpu_read(tasklet_vec.tail) = t;
33 __this_cpu_write(tasklet_vec.tail, &(t->next));
34 __raise_softirq_irqoff(TASKLET_SOFTIRQ);
35 local_irq_enable();
36 }
37 }
我需要再强调一个应用场景,就是当你去使用tasklet_schedule去调度一个tasklet的时候,就会进入到tasklet_action的处理函数。注意看16~28行,tasklet_trylock()函数是一个锁,如果目前访问的tasklet已经处于RUNNING状态,也就是它被设置了TASKLET_STATE_RUN的标志位,那么tasklet_trylock是会返回一个false,表示这个tasklet已经被其他CPU调度,正处于执行状态, 那么这一轮的tasklet就会跳过该tasklet。这样做的目的就是为了保证同一个tasklet只能在一个CPU上运行。
看到这里,你可能有点似懂非懂、朦朦胧胧的感觉,那我们趁热打铁,我直接给你们举一个 鲜活的例子。
首先,先回顾一下,我们前面举的一个tasklet使用的例子(driver/char/snsc_event.c),在前面说的那个例子中,我们正常注册一个中断,正常进入了硬件中断处理函数,在硬件中断处理函数中正常地调度了tasklet来进行下半部的软中断处理。它之所以正常,是因为没有发生额外的中断请求, 但是在实际繁忙的CPU工作中,各种各样的情况都有可能发生。
我们假设正常情况下,是(a)设备A首先触发了硬件中断,然后调用了snsc_event.c中的中断处理函数,然后它也(b)正常进入了tasklet的软中断处理中,在CPU0上处理,但是它还在处理下半部的时候,(c)突然设备B也产生了一个中断,那么(d)CPU0就会暂停tasklet的处理,转去执行设备B的硬件中断处理。如果这时候,(e)设备A又再次发生了中断,因为CPU0正忙着,所以中断控制器中的CPU Interface模块(f)把这个中断请求发送给了CPU1,假设CPU1很快处理完了硬件中断并开始处理该tasklet,发现tasklet_schedule()函数中发现并没有设置TASKLET_STATE_SCHED标志位(因为在CPU0执行tasklet回调函数的时候,就已经把这个标志位清楚了),所以CPU1会认为这个tasklet是一个新的tasklet,然后(g)CPU1把这个tasklet加入到自己的tasklet_vec链表中,然后等到它执行到上面16行代码的时候,发现(h)拿不到锁(因为CPU0中这个tasklet还没处理完,还没释放锁呢),所以CPU1就跳过了这次处理,得等到CPU0处理完第一个tasklet的时候,CPU1下一次软中断执行才会继续执行该tasklet。
6.4、工作队列(workqueue)
6.4.1、为什么需要工作队列
有了软中断和tasklet,为什么还需要工作队列?
软中断上下文的优先级高于进程上下文,因此软中断包括tasklet总是抢占进程的执行。当进程A在执行时发生中断,会优先处理中断函数,当中断返回时,应该先判断本地CPU上有没有pending状态的软中断,如果有,那么需要首先执行软中断包括tasklet。如果执行软中断或者tasklet的时间很长,那么进程A就长时间得不到运行,势必会影响系统的实时性,所以Linux专家一直要求工作队列机制来替代tasklet
相信大家到这里产生的第一个疑问肯定是:咦~工作队列怎么就不会影响到系统的实时性了呢?
6.4.2、工作队列的原理
- 软中断和tasklet:都是运行在中断上下文中,拥有比较高的优先级
- 工作队列机制:
把work交给一个内核线程来执行,它总是运行在进程上下文中
了解了工作队列的基本原理后,它的优点就一目了然了:它利用进程上下文来执行中断下半部操作,因此工作队列允许重新调度和睡眠。按我个人通俗点的理解,工作队列没有软中断和tasklet那么霸道,CPU不用每次都得先服务完它再去服务其他进程了。
工作队列在Linux内核中的使用是非常广泛的
6.4.3、工作队列基本概念
work item:表示一个工作任务worker/工作线程:执行工作任务的线程工作线程池(worker-pool):管理众多的工作线程,worker-pool分成两种,一种是BOUND类型,另一种是UNBOUND类型(不与具体CPU绑定),每个CPU都有工作线程池,不管是BOUND类型的工作线程池,还是UNBOUND类型的,都会定义两个线程池,一个给普通优先级的work使用,另一个给高优先级的work使用。
6.4.4、工作队列的使用
我们虽然可以自己创建新的工作队列,但是在Linux内核中,它推荐驱动开发者使用默认的workqueue,而不是新创建workqueue,要使用系统默认的workqueue,首先需要初始化一个work,内核提供了相应的宏 INIT_WORK()