Kotlin 学习笔记(六)—— Flow 数据流学习实践指北(二)StateFlow 与 SharedFlow
要说最近圈内大事件,那就非 chatGPT 莫属了!人工智能领域最新的大突破了吧?很可能引发下一场的技术革命,因为大家都懂的原因现在还不能在中国大陆使用,不过国内的度厂正在积极跟进了,预计3月份能面世,且期待一下吧~
上节主要讲述了 Flow 的组成、Flow 常用操作符以及冷流的具体使用。这节自然就要介绍热流了。先来温习下:
冷流(Cold Flow):在数据被消费者订阅后,即调用
collect方法之后,生产者才开始执行发送数据流的代码,通常是调用emit方法。即不消费,不生产,多次消费才会多次生产。消费者和生产者是一对一的关系。
上次说的例子不太直观,所以这次换了个更直观的对比例子,先来看第一个:
//code 1
val coldFlow = flow {
println("coldFlow begin emitting")
emit(40)
println("coldFlow 40 is emitted")
emit(50)
println("coldFlow 50 is emitted")
}
binding.btn2.setOnClickListener {
lifecycleScope.launch {
coldFlow.collect {
println("coldFlow = $it")
}
}
}
只有当点击按钮时,才会如图打印出信息,即冷流只有调用了 collect 方法收集流后,emit 才会开始执行。

热流(Hot Flow)就不一样了,无论有无消费者,生产者都会生产数据。它不像冷流,Flow 必须在调用末端操作符之后才会去执行;而是可以自己控制是否发送或者生产数据流。并且热流可以有多个订阅者;而冷流只有一个。再来看看热流的例子:
//code 2
val hotFlow = MutableStateFlow(0)
lifecycleScope.launch {
println("hotFlow begin emitting")
hotFlow.emit(40)
println("hotFlow 40 is emitted")
hotFlow.emit(50)
println("hotFlow 50 is emitted")
}
binding.btn2.setOnClickListener {
lifecycleScope.launch {
hotFlow.collect {
println("hotFlow collects $it")
}
}
}
MutableStateFlow 就是热流中的一种,当没有点击按钮时,便会输出下图中的前三行信息。
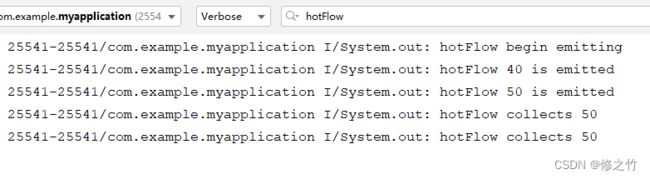
当点击两下按钮后,就会依次输出如图第 4,5 行的信息,至于为什么只会接收到 50,这跟 MutableStateFlow 的特性有关,后面再说。
通过这两个例子就可清楚地知道冷热流之间的区别。热流有两种对象,分别是 StateFlow 和 SharedFlow。
1. SharedFlow
先来看看 SharedFlow,它是一个 subscriber 订阅者的角色,当一个 SharedFlow 调用了 collect 方法后,它就不会正常地结束完成;但可以 cancel 掉 collect 所在的协程,这样就可以取消掉订阅了。SharedFlow 在每次 emit 时都会去 check 一下所在协程是否已经取消。绝大多数的终端操作符,例如 Flow.toList() 都不会使得 SharedFlow 结束完成,但 Flow.take() 之类的截断操作符是例外,它们是可以强制完成一个 SharedFlow 的。
SharedFlow 的简单使用样例:
//code 3
class EventBus {
private val _events = MutableSharedFlow<Event>() // private mutable shared flow
val events = _events.asSharedFlow() // publicly exposed as read-only shared flow
suspend fun produceEvent(event: Event) {
_events.emit(event) // suspends until all subscribers receive it
}
}
与 LiveData 相似的使用方式。但 SharedFlow 的功能更为强大,它有 replay cache 和 buffer 机制。
1.1 Replay cache
可以理解为是一个粘性事件的缓存。每个新的订阅者会首先收到 replay cache 中之前发出并接收到的事件,再才会收到新的发射出的值。可以在 MutableSharedFlow 的构造函数中设置 cache 的大小,不能为负数,默认为 0.
//code 4
public fun <T> MutableSharedFlow(
replay: Int = 0,
extraBufferCapacity: Int = 0,
onBufferOverflow: BufferOverflow = BufferOverflow.SUSPEND
)
replay 重播之前最新的 n 个事件,见字知义。下面是例子:
//code 5
private fun testSharedFlow() {
val sharedFlow = MutableSharedFlow<Int>(replay = 2)
lifecycleScope.launch {
launch {
sharedFlow.collect {
println("++++ sharedFlow1 collected $it")
}
}
launch {
(1..3).forEach{
sharedFlow.emit(it)
}
}
delay(200)
launch {
sharedFlow.collect {
println("++++ sharedFlow2 collected $it")
}
}
}
}
结果为:
com.example.myapplication I/System.out: ++++ sharedFlow1 collected 1
com.example.myapplication I/System.out: ++++ sharedFlow1 collected 2
com.example.myapplication I/System.out: ++++ sharedFlow1 collected 3
com.example.myapplication I/System.out: ++++ sharedFlow2 collected 2
com.example.myapplication I/System.out: ++++ sharedFlow2 collected 3
在 emit 发射数据前后分别设置了一个订阅者,后面还延时了 200ms 才进行订阅。第一个订阅者 1、2、3都收到了;而第二个订阅者却只收到了 2 和 3. 这是因为在第二个订阅者开始订阅时,数据已经都发射完了,而 SharedFlow 的重播 replay 为 2,就可将最近发射的两个数据再依次发送一遍,这就可以收到 2 和 3 了。
1.2 extraBufferCapacity
SharedFlow 构造函数的第二个参数 extraBufferCapacity 的作用是,在 replay cache 之外还能额外设置的缓存。常用于当生产者生产数据的速度 > 消费者消费数据的速度时的情况,可以有效提升吞吐量。
所以,若 replay = m,extraBufferCapacity = n,那么这个 SharedFlow 总共的 BufferSize = m + n. replay 会存储最近发射的数据,如果满了就会往 extraBuffer 中存。接下来看一个例子:
//code 6
private fun coroutineStudy() {
val sharedFlow = MutableSharedFlow<Int>(replay = 1, extraBufferCapacity = 1)
lifecycleScope.launch {
launch {
sharedFlow.collect {
println("++++ sharedFlow1 collected $it")
delay(6000)
}
}
launch {
(1..4).forEach{
sharedFlow.emit(it)
println("+++emit $it")
delay(1000)
}
}
delay(4000)
launch {
sharedFlow.collect {
println("++++ sharedFlow2 collected $it")
delay(20000)
}
}
}
}
运行结果为:
17:32:09.283 28184-28184 System.out com.wen.testdemo I +++emit 1
17:32:09.284 28184-28184 System.out com.wen.testdemo I ++++ sharedFlow1 collected 1
17:32:10.285 28184-28184 System.out com.wen.testdemo I +++emit 2
17:32:11.289 28184-28184 System.out com.wen.testdemo I +++emit 3
17:32:13.286 28184-28184 System.out com.wen.testdemo I ++++ sharedFlow2 collected 3
17:32:15.292 28184-28184 System.out com.wen.testdemo I +++emit 4
17:32:15.293 28184-28184 System.out com.wen.testdemo I ++++ sharedFlow1 collected 2
17:32:21.301 28184-28184 System.out com.wen.testdemo I ++++ sharedFlow1 collected 3
17:32:27.311 28184-28184 System.out com.wen.testdemo I ++++ sharedFlow1 collected 4
17:32:33.292 28184-28184 System.out com.wen.testdemo I ++++ sharedFlow2 collected 4
打印结果可能会有点懵,对照着时序图更容易理解(此图来自于参考文献3,感谢 fundroid 大佬的输出~):
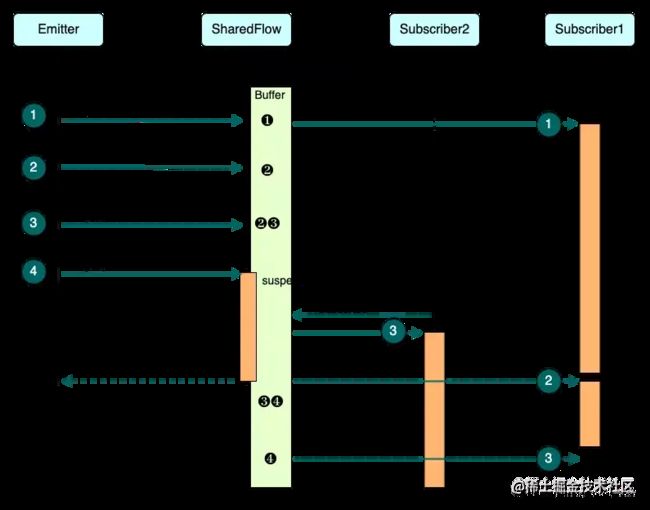
1)Emitter 发送 1,因为 Subscriber1 在 Emitter 发送数据前就已开始订阅,所以 Subscriber1 可马上接收;此时 replay 存储 1;
2)Emitter 发送 2,Subscriber1 还在处理中处于挂起态,此时 replay 存储 2;
3)Emitter 发送 3,此时还没有任何消费者能消费,则 replay 存储 3,将 2 放入 extra 中;
4)Emitter 想要发送 4,但发现 SharedFlow 的 Buffer 已满,则按照默认的策略进行挂起等待(默认策略就是 onBufferOverflow: BufferOverflow = BufferOverflow.SUSPEND);
5)Subscriber2 开始订阅,接收到 replay 中的 3,此时 Subscriber1 还是挂起态,Buffer 中数据没变化,即 replay 存储 3,extra 存储 2;
6)Subscriber1 处理完 1 后,依次处理 Buffer 中 的下一个数据,即消费 extra 中的 2,这时 Buffer 终于有空间了,Emitter 结束挂起,发送 4,replay 存储 4,将 3 放入 extra 中;
7)Subscriber1 消费完 2 后接着再消费 extra 中的 3,此时 Buffer 中就只有 4 了。后面的就不用多说了
比较绕,需要多看几次思考一下。需要注意的是,代码运行结果中下面两行输出到底谁先谁后的问题:
17:32:15.292 28184-28184 System.out com.wen.testdemo I +++emit 4
17:32:15.293 28184-28184 System.out com.wen.testdemo I ++++ sharedFlow1 collected 2
打印出的时间戳几乎是一样的,若严格按照 log 打印的时间戳顺序,应该是 Emitter 先发送的 4,Subscriber1 再才接收到的 2,但根据反复实践的结果来看,实际上是 Subscriber1 先接收缓冲区中的 2,等缓冲区有剩余空间后,Emitter 才结束挂起继续发送 4. 把上面的例子简化一下,再改改数据:
//code 7
private fun coroutineStudy() {
val sharedFlow = MutableSharedFlow<Int>(replay = 1, extraBufferCapacity = 1)
lifecycleScope.launch {
launch {
sharedFlow.collect {
println("++++ sharedFlow1 collected $it")
delay(10000)
}
}
launch {
(1..4).forEach{
sharedFlow.emit(it)
println("+++emit $it")
delay(1000)
}
}
}
}
打印结果如下所示,因为把 sharedFlow delay 的时长设置为 10s,所以很明显地看到 Emitter 在发送 1、2、3 时时间间隔均是 1s,发送 4 时足足过了 8s,这段时间就是 Emitter 被挂起了,一直等到 sharedFlow1 接收到 2 之后,4 才被 Emitter 发送,而 sharedFlow1 的每次接收都是间隔 10s,所以是先接收的 2,再结束挂起发送的 4.
00:25:52.481 29483-29483/com.example.myapplication I/System.out: +++emit 1
00:25:52.482 29483-29483/com.example.myapplication I/System.out: ++++ sharedFlow1 collected 1
00:25:53.483 29483-29483/com.example.myapplication I/System.out: +++emit 2
00:25:54.486 29483-29483/com.example.myapplication I/System.out: +++emit 3
00:26:02.487 29483-29483/com.example.myapplication I/System.out: +++emit 4
00:26:02.488 29483-29483/com.example.myapplication I/System.out: ++++ sharedFlow1 collected 2
00:26:12.497 29483-29483/com.example.myapplication I/System.out: ++++ sharedFlow1 collected 3
00:26:22.516 29483-29483/com.example.myapplication I/System.out: ++++ sharedFlow1 collected 4
通过源码也可看出这个结论,从 collect 方法进入,最终可以找到实际上是调用了 SharedFlowImpl 中的 collect 方法:
//code 8
override suspend fun collect(collector: FlowCollector<T>) {
val slot = allocateSlot()
try {
if (collector is SubscribedFlowCollector) collector.onSubscription()
val collectorJob = currentCoroutineContext()[Job]
while (true) {
var newValue: Any?
while (true) {
newValue = tryTakeValue(slot) //首先尝试直接获取值
if (newValue !== NO_VALUE) break
awaitValue(slot) //没获取到则只能挂起等待新值到来
}
collectorJob?.ensureActive()
collector.emit(newValue as T)
}
} finally {
freeSlot(slot)
}
}
在内层 while 循环中,首先是通过 tryTakeValue 方法直接取值,如果没取到则通过 awaitValue 方法挂起等待新值,awaitValue 是个挂起函数。取到新值之后,才会跳出内层 while 循环,并执行 collector.emit(newValue as T),而这一段代码,实际上就是调用的 code 7 中的 sharedFlow.emit(it) 代码。
此处源代码还可以看出,SharedFlow 每次在 emit 之前,确实都会查看所在协程是否还在运行;且它确实是不会停止的,哪怕没有接收到新值,也会一直处于挂起等待的状态,想要结束则得使用截断类型的操作符。
1.3 onBufferOverflow
SharedFlow 构造函数的第三个参数就是设置超过 Buffer 之后的策略,默认是将生产者挂起暂时不再发送数据,即 BufferOverflow.SUSPEND。
还有另外两个数据丢弃策略:
1)BufferOverflow.DROP_LATEST 丢弃最新数据;
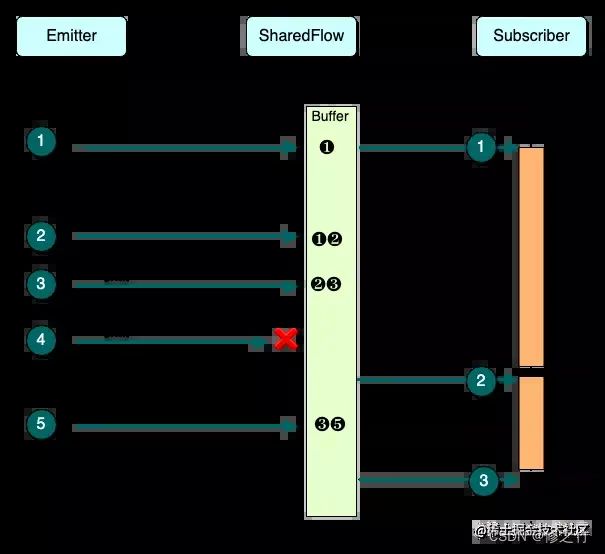
Emitter 在发送 4 时,因为 Buffer 已满,所以只能按照策略将最新的数据 4 丢弃。而在发送 3 时,由于 1 已经被消费过,所以可以从 Buffer 中移除,从而腾出存储空间缓存 3。
2)BufferOverflow.DROP_OLDEST 丢弃最老数据:
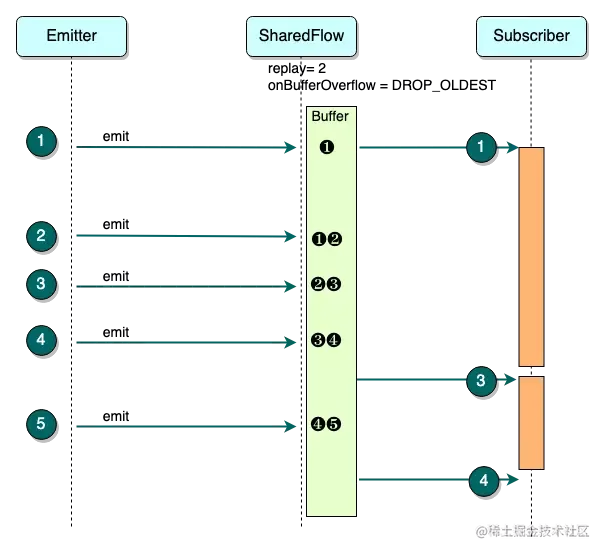
这个策略就比较简单,Buffer 中只会存储最新的数据。不管较老的数据是否被消费,当 Buffer 已满而又有新的数据到达时,老数据都会从 Buffer 中移除,腾出空间让给新数据。
注意点:当 replay、extra 都为 0,即没有 Buffer 的时候,那么 onBufferOverflow 只能是 BufferOverflow.SUSPEND。丢弃策略启动的前提是 SharedFlow 至少有 Buffer 且 Buffer 已满。
1.4 emit 与 tryEmit
由前一节可知,当 SharedFlow 的 Buffer 已满且 onBufferOverflow 为 BufferOverflow.SUSPEND 的时候,emit 会被挂起(emit 是个挂起函数),但这会影响到 Emitter 的速度。如果不想在发送数据的时候被挂起,除了设置 onBufferOverflow 丢弃策略外,还可以使用 tryEmit 方法。
//code 9
override fun tryEmit(value: T): Boolean {
var resumes: Array<Continuation<Unit>?> = EMPTY_RESUMES
val emitted = synchronized(this) {
if (tryEmitLocked(value)) {
resumes = findSlotsToResumeLocked(resumes)
true
} else {
false
}
}
for (cont in resumes) cont?.resume(Unit)
return emitted
}
@Suppress("UNCHECKED_CAST")
private fun tryEmitLocked(value: T): Boolean {
// Fast path without collectors -> no buffering
// 1.没有订阅者时,直接返回 true,因为没有人接收,发了也没用,也不用缓存
if (nCollectors == 0) return tryEmitNoCollectorsLocked(value) // always returns true
// With collectors we'll have to buffer
// 2.有订阅者,就得考虑缓存发送的值了
// cannot emit now if buffer is full & blocked by slow collectors
// 3.如果缓存空间已满,且订阅者还在挂起处理上次的数据,则不能 emit
if (bufferSize >= bufferCapacity && minCollectorIndex <= replayIndex) {
when (onBufferOverflow) {
BufferOverflow.SUSPEND -> return false // will suspend
BufferOverflow.DROP_LATEST -> return true // just drop incoming
BufferOverflow.DROP_OLDEST -> {} // force enqueue & drop oldest instead
}
}
// 4.代码能走到这里,说明缓存还有空间或丢弃策略为DROP_OLDEST
enqueueLocked(value)
bufferSize++ // value was added to buffer
// drop oldest from the buffer if it became more than bufferCapacity
if (bufferSize > bufferCapacity) dropOldestLocked()
// keep replaySize not larger that needed
if (replaySize > replay) { // increment replayIndex by one
updateBufferLocked(replayIndex + 1, minCollectorIndex, bufferEndIndex, queueEndIndex)
}
return true
}
由代码可见 tryEmit 不是一个挂起函数,它有返回值,如果返回 true 则说明发送数据成功了;如果返回 false,则说明这时发送数据需要被挂起等待。其中最主要的就是 tryEmitLocked 方法。
tryEmitLocked 方法主要逻辑已在注释中说明,需要额外说明的是,bufferCapacity 就是 replay + extraBufferCapacity 的大小;replayIndex 指的是最近开始订阅的订阅者在 replay cache 缓存数组中需要重播的最小 index。所以当使用默认构造的 SharedFlow 时,replay 和 extraBufferCapacity 都为 0,如果这时再使用 tryEmit 方法进行发送,则会使得 if (bufferSize >= bufferCapacity && minCollectorIndex <= replayIndex) 判断为 true,默认的丢弃策略又是 BufferOverflow.SUSPEND,就会导致这里会直接返回 false,永远都不会发送出值。所以,在使用默认构造的 SharedFlow 时,不能使用 tryEmit 发送值,否则无法发送。 一般使用 emit 即可。
在 SharedFlow 具体实现中,emit 方法就是先尝试使用 tryEmit 来发送值,如果不能马上发送再使用挂起函数 emitSuspend 方法:
//code 10 class SharedFlowImpl
override suspend fun emit(value: T) {
if (tryEmit(value)) return // fast-path
emitSuspend(value)
}
2. StateFlow
看完 SharedFlow 再来看 StateFlow 的话就比较简单了。因为 StateFlow 就是 SharedFlow 的一种特殊子类,特点有三:
1)它的 replay cache 容量为 1;即可缓存最近的一次粘性事件;
2)初始化时必须给它设置一个初始值;
3)每次发送数据都会与上次缓存的数据作比较,如果不一样才会发送,自动过滤掉没有发生变化的数据。
它还可直接访问它自己的 value 参数获取当前结果值,总体来说,在使用上与 LiveData 相似,下面是它俩的异同点对比。
2.1 与 LiveData 比较的相同点
- 均提供了 可读可写 和 仅可读 两个版本:MutableStateFlow、StateFlow 与 MutableLiveData、LiveData;
- 允许被多个观察者观察,即生产者对消费者可以为一对多的关系;
- 都只会把最新的值给到观察者,即使没有观察者,也会更新自己的值;
- 都会产生粘性事件问题;
- 都可能产生丢失值的问题;
粘性事件问题:因为 StateFlow 初始化时必须给定初始值,且 replay 为 1,所以每个观察者进行观察时,都会收到最近一次的回播数据。如果想避免粘性事件问题,换用 SharedFlow 即可,replay 使用默认值 0 。
值丢失问题:出现在消费者处理数据比生产者生产数据慢的情况,消费者来不及处理数据,就会把之前生产者发送的旧数据丢弃掉,看个例子:
//code 11
private fun stateFlowDemo1() {
val stateFlow = MutableStateFlow(0)
CoroutineScope(Dispatchers.Default).launch {
var count = 1
while (true) {
val tmp = count++
delay(1000)
println("+++++ tmp = $tmp")
stateFlow.value = tmp
}
}
CoroutineScope(Dispatchers.Default).launch {
stateFlow.collect{
println("++++ count = $it")
delay(5000) //模拟耗时操作
}
}
}

可以从打印结果看出,StateFlow 会丢弃掉生产者之前发送的值,其实 MutableStateFlow 的丢弃策略就是设置的 BufferOverflow.DROP_OLDEST。
2.2 与 LiveData 比较的不同点
- StateFlow 必须在构建的时候传入初始值,LiveData 不需要;
- StateFlow 默认是防抖的,LiveData 默认不防抖;
- 对于 Android 来说 StateFlow 默认没有和生命周期绑定,直接使用会有问题;
StateFlow 默认防抖:即如果发送的值与上次相同,则生产者并不会真正发送。在源码中也有说明,具体在 StateFlow.kt -> class StateFlowImpl -> private fun updateState -> if (oldState == newState) return true
感兴趣的可以自行查阅,我看的版本是 1.5.0.
与 LiveData 相比,没有和 Activity 的生命周期绑定恐怕是使用 StateFlow 最不方便的地方了。当 View 进入 STOPPED 状态时,LiveData.observe() 会自动取消注册使用方,这样就不会再接收到数据了,也符合常理。因为用户此时已经离开页面,再接收数据已没有意义,如果继续处理后续逻辑可能还会出 bug。
而如果使用的是 StateFlow 或其他数据流,在 View 进入 STOPPED 状态时,收集数据的操作并不会自动停止。如需实现相同的行为,则需要从 Lifecycle.repeatOnLifecycle 块收集数据流。如下是来自官方文档的例子:
//code 12
class LatestNewsActivity : AppCompatActivity() {
private val latestNewsViewModel = // getViewModel()
override fun onCreate(savedInstanceState: Bundle?) {
...
// Start a coroutine in the lifecycle scope
lifecycleScope.launch {
// repeatOnLifecycle launches the block in a new coroutine every time the
// lifecycle is in the STARTED state (or above) and cancels it when it's STOPPED.
repeatOnLifecycle(Lifecycle.State.STARTED) {
// Trigger the flow and start listening for values.
// Note that this happens when lifecycle is STARTED and stops
// collecting when the lifecycle is STOPPED
latestNewsViewModel.uiState.collect { uiState ->
// New value received
when (uiState) {
is LatestNewsUiState.Success -> showFavoriteNews(uiState.news)
is LatestNewsUiState.Error -> showError(uiState.exception)
}
}
}
}
}
}
//注意:repeatOnLifecycle API 仅在 androidx.lifecycle:lifecycle-runtime-ktx:2.4.0 库及更高版本中提供。
英文部分注释说的比较明确了,repeatOnLifecycle(Lifecycle.State.STARTED) 的作用就是每次进入 STARTED 可见状态时都会重新观察并收集数据;而在 STOPPED 状态时就会 cancel 掉 StateFlow 收集流所在的协程从而停止收集。
总结
最后总结一下 Flow 第二小节的内容吧:
1)热流有无消费者都可发送数据,生产者和消费者的关系可以是一对多;
2)SharedFlow 可构建热流,可设置 replay 重播数据量及 extraBufferCapacity 缓冲区大小,以及 onBufferOverflow 缓冲区满的策略;
3)emit 与 tryEmit 发送方法的异同,前者是挂起函数,注意在使用默认构造的 SharedFlow 时不要使用 tryEmit;
4)StateFlow 是 SharedFlow 的一个子类,replay = 1,必须给定初始值,自带防抖;
5)使用 StateFlow 或 SharedFlow 收集值时,记得在 repeatOnLifecycle(Lifecycle.State.STARTED) 方法中,防止出现崩溃等问题。
更多内容,欢迎关注公众号:修之竹
赞人玫瑰,手留余香!欢迎点赞、转发~ 转发请注明出处~
参考文献
- Reactive Streams on Kotlin: SharedFlow and StateFlow; Ricardo Costeira; https://www.raywenderlich.com/22030171-reactive-streams-on-kotlin-sharedflow-and-stateflow
- Kotlin中 Flow、SharedFlow与StateFlow区别;五问;https://juejin.cn/post/7142038525997744141
- 一看就懂!图解 Kotlin SharedFlow 缓存系统;fundroid;https://juejin.cn/post/7156408785886511111
- Kotlin:深入理解StateFlow与SharedFlow,StateFlow和LiveData使用差异区分,SharedFlow实现源码解析; pumpkin的玄学; https://blog.csdn.net/weixin_44235109/article/details/121594988?spm=1001.2014.3001.5502
- StateFlow 和 SharedFlow 官方文档 https://developer.android.google.cn/kotlin/flow/stateflow-and-sharedflow?hl=zh-cn