Groovy从入门到精通
一、环境搭建
- 安装好JDK环境
- 到groovy官网下载groovySDK,解压到合适位置
groovy官网:http://www.groovy-lang.org/
安装后的文件如上图所示,我们需要关注的是bin和doc文件夹下的内容,其它文件夹下是一些配置和groovy自带的一些jar包 - 配置groovy环境变量
二、与Java的不同之处
1、默认 imports
所有这些包和类都是默认导入的,您不必使用显式import语句来使用它们:
java.io.*
java.lang.*
java.math.BigDecimal
java.math.BigInteger
java.net.*
java.util.*
groovy.lang.*
groovy.util.*
2、运行时分派
在Groovy中,将在运行时选择将被调用的方法。 这称为运行时分派或Multi-methods。 这意味着将基于运行时参数的类型来选择方法。 在Java中,则是根据声明的类型,在编译时选择方法。
下面的代码,以Java代码编写,可以在Java和Groovy中编译,但它的行为会有所不同:
int method(String arg) {
return 1;
}
int method(Object arg) {
return 2;
}
Object o = "Object";
int result = method(o);
在Java中, 您将得到:2
而在Groovy中:1
这是因为Java将使用静态信息类型,即o被声明为Object,而Groovy将在运行时选择该方法被实际调用时。 因为它是用String调用的,所以调用String版本。
3、数组初始化
在Groovy中,{...}块是为闭包而保留的。 这意味着您不能使用以下语法创建数组:
int [] array = {1,2,3}
你必须使用:
int [] array = [1,2,3]
4、自动资源管理块
roovy不支持Java 7中的ARM(自动资源管理)块。 相反,Groovy提供了依赖闭包的各种方法,它们具有相同的效果,同时更加方便。 例如:
Path file = Paths.get("/path/to/file");
Charset charset = Charset.forName("UTF-8");
try (BufferedReader reader = Files.newBufferedReader(file, charset)) {
String line;
while ((line = reader.readLine()) != null) {
System.out.println(line);
}
} catch (IOException e) {
e.printStackTrace();
}
可以这样写:
new File('/path/to/file').eachLine('UTF-8') {
println it
}
或者,如果你想要一个更接近Java的版本:
new File('/path/to/file').withReader('UTF-8') { reader ->
reader.eachLine {
println it
}
}
5、Lambdas
Java 8支持lambdas和方法引用:
Runnable run = () -> System.out.println("Run");
list.forEach(System.out::println);
Java 8 lambdas可以或多或少被认为是匿名内部类。 Groovy不支持该语法,但是可以使用闭包:
Runnable run = { println 'run' }
list.each { println it } // or list.each(this.&println)
6、GStrings
由于双引号字符串字面量被解释为GString,Groovy将在GString和String之间自动转换
Groovy中的单引号用于String,双引号结果是String或GString,取决于文字中是否有插值。
assert 'c'.getClass()==String
assert "c".getClass()==String
assert "c${1}".getClass() in GString
只有在赋给char类型的变量时,Groovy会自动将单字符String转换为char。 当调用类型为char的参数的方法时,我们需要显式转换或确保该值已预先转换。
char a='a'
assert Character.digit(a, 16)==10 : 'But Groovy does boxing'
assert Character.digit((char) 'a', 16)==10
try {
assert Character.digit('a', 16)==10
assert false: 'Need explicit cast'
} catch(MissingMethodException e) {
}
Groovy支持两种类型的转换,在转换为char的情况下,在转换multi-char 时存在微妙的差别。 Groovy风格的转换是更宽松的,将采取第一个字符,而C风格的转换将失败,异常。
// for single char strings, both are the same
assert ((char) "c").class==Character
assert ("c" as char).class==Character
// for multi char strings they are not
try {
((char) 'cx') == 'c'
assert false: 'will fail - not castable'
} catch(GroovyCastException e) {
}
assert ('cx' as char) == 'c'
assert 'cx'.asType(char) == 'c'
7、原始和封装
因为Groovy使用Objects来做每一件事,它对原始的引用自动包装。 因此,它不遵循Java的扩展优先于装箱。 这里有一个使用int的例子
int i
m(i)
//这是Java将调用的方法,因为扩展优先于装箱。
void m(long l) {
println "in m(long)"
}
//这是Groovy实际调用的方法,因为所有的基本引用都使用它们的包装类。
void m(Integer i) {
println "in m(Integer)"
}
8、==的行为
在Java中==表示对象的原始类型或标识的相等性。 在Groovy ==翻译为a.compareTo(b)== 0,如果他们是可比较的,否则a.equals(b)。 如果要检查身份,有is方法,例如a.is(b)
三、基础语法
1、动态类型
Groovy定义变量时:可以用Groovy风格的def声明,不指定类型;也可以兼容Java风格,指定变量类型;甚至还可以省略def或类型。
def t1 = 't1'
String t2 = 't2'
t3 = 't3'
Groovy风格定义的变量类型是动态的,编译成class时会自动转换成正确的Java类型。
def var = 'text'
println var
var = 5
println var + 1
可用Java实现类似效果如下。
Object o = "text";
System.out.println(String.valueOf(o));
o = 5;
System.out.println(String.valueOf(Integer.valueOf(o) + 1));
2、字符串
Groovy支持灵活的字符串语法,例如:
// 单引号字符串
def a = 'hello "world"'
// 双引号字符串
def b = "What's the weather like?"
// 用加号连接字符串,用等号对比字符串
assert 'ab' == 'a' + 'b'
// 三个单引号字符串,支持直接换行
def aMultilineString = '''line one
line two
line three'''
// 斜线字符串中,反斜线不需要转义,常用于正则表达式
def fooPattern = /.*foo.*/
// 双引号字符串支持用$嵌入变量
def name = 'Tom'
def greeting = "Hello ${name}"
// 如需函数调用,则$后表达式要加大括号
def pi = 3.14
def piString = "Pi = ${pi.toString()}"
3、闭包 (Closure)
闭包是一个变量,又是一个函数,类似C语言中的函数指针,或者Java中只有一个方法的接口(Runnable等)。
反编译class文件可以看出,Groovy闭包都会转化为继承groovy.lang.Closure的类。
闭包方法的参数用箭头定义,如果不特殊指定,则默认有一个it参数。
闭包方法的返回值可以用return显示指定,如果不指定则使用最后一条语句的值。
def c1 = {
println 'hello'
}
def c2 = { a, b ->
println a
println b
}
def c3 = { int a, String b ->
println a
println b
}
def c4 = { ->
println 'hello'
}
def c5 = {
println it
}
def c6 = {
return it + 1
}
def c7 = {
it + 1
}
闭包调用可以用call,也可以直接像Java方法一样加括号调用。
def c = {
println it
}
c.call('text1')
c('text2')
Java实现闭包效果:
abstract class MyClosure {
abstract void call(Object o);
}
MyClosure c = new MyClosure() {
@Override
void call(Object o) {
System.out.println(String.valueOf(o));
}
};
c.call("text");
4、方法/闭包的定义与调用
Groovy中定义方法既可以用Groovy闭包风格,也可以用Java风格,参数/返回值类型也是可选的。
def f1 = { text ->
println text
}
def f2(text) {
println text
}
void f3(String text) {
println text
}
注意函数定义不能这么写,会被视为函数调用。
f4(text) {
println text
}
调用带参数的闭包/函数,通常可以省略括号,如果最后一个参数是闭包,还可以单独写在括号后面,如下。
println('hello')
println 'hello'
def func = { text, Closure closure ->
println text
closure.call()
}
func('1', {
println '2'
})
func '3', {
println '4'
}
func('5') {
println '6'
}
5、delegate,owner,this
查看Closure类的源码,可以发现闭包中有delegate、owner、this三个成员变量,调用闭包没有的属性/方法时,会尝试在这三个变量上调用。一般情况下:
this指向闭包外部的Object,指定义闭包的类。owner指向闭包外部的Object/Closure,指直接包含闭包的类或闭包。delegate默认和owner一致,指用于处理闭包属性/方法调用的第三方对象,可以修改。
在闭包构造时this和owner就已经确定并传入,是只读的。如果需要修改,可以用Closure.rehydrate()方法克隆新的闭包,同时设置其this和owner。
Closure还有一个resolveStrategy属性,有多种值(OWNER_FIRST、DELEGATE_FIRST、OWNER_ONLY、DELEGATE_ONLY、TO_SELF),默认为OWNER_FIRST,表示调用闭包没有定义的属性/方法时,先尝试从owner取,再尝试从delegate取。
Groovy代码示例:
class MyDelegate {
def func = {
println('hello')
}
}
def c = {
func()
}
c.delegate = new MyDelegate()
c.call()
用Java实现类似效果如下。
static boolean callMethod(Object o, String method, Object... args) {
try {
Method func = o.getClass().getDeclaredMethod(method);
if (func != null) {
func.invoke(o, args);
return true;
}
} catch (Exception ignored) {
}
return false;
}
class MyDelegate {
void func() {
System.out.println("func");
}
}
abstract class MyClosure {
Object delegate;
abstract void call();
}
MyClosure c = new MyClosure() {
@Override
void call() {
if (!callMethod(this, "func")) {
callMethod(delegate, "func");
}
}
};
c.delegate = new MyDelegate();
c.call();
6、属性与Getter、Setter
Groovy中对象的属性(通常即成员变量)可以直接用名字访问,实际上会调用getter和setter
// File没有absolutePath的成员变量,但有getAbsolutePath方法,可以直接当属性访问
println new File('text').absolutePath
// File没有setAbsolutePath方法,这句会报ReadOnlyPropertyException
new File('text').absolutePath = '1'
四、集合操作
1、Lists
List 字面值
您可以按如下所示创建列表。 请注意,[]是空列表表达式。
def list = [5, 6, 7, 8]
assert list.get(2) == 7
assert list[2] == 7
assert list instanceof java.util.List
def emptyList = []
assert emptyList.size() == 0
emptyList.add(5)
assert emptyList.size() == 1
每个列表表达式都是创建[java.util.List],一个list可以用作构造另一个list的源:
def list1 = ['a', 'b', 'c']
//构造一个新的List,这个List和list1有相同的items
def list2 = new ArrayList(list1)
assert list2 == list1 // == 检测每一个对应的item,判断它们是否相同
// clone() 也是可以使用的
def list3 = list1.clone()
assert list3 == list1
list是objects的有序集合:
def list = [5, 6, 7, 8]
assert list.size() == 4
assert list.getClass() == ArrayList //所使用的列表的具体类型
assert list[2] == 7 // 索引是从0开始的
assert list.getAt(2) == 7 // 同[]运算符
assert list.get(2) == 7 // 替代方法
list[2] = 9
assert list == [5, 6, 9, 8,] //结果通过
list.putAt(2, 10) //等效于 list[2] = 10
assert list == [5, 6, 10, 8]
assert list.set(2, 11) == 10 // 赋值并返回原值
assert list == [5, 6, 11, 8]
assert ['a', 1, 'a', 'a', 2.5, 2.5f, 2.5d, 'hello', 7g, null, 9 as byte]
//元素可以是不同类型; 允许重复
assert [1, 2, 3, 4, 5][-1] == 5 // 允许负数index,从list尾部开始计数
assert [1, 2, 3, 4, 5][-2] == 4
assert [1, 2, 3, 4, 5].getAt(-2) == 4 // getAt() 可以使用负数index
try {
[1, 2, 3, 4, 5].get(-2) // 但是get()方法不允许使用负数index
assert false
} catch (e) {
assert e instanceof ArrayIndexOutOfBoundsException
}
List迭代
迭代列表的元素通常是通过调用each和eachWithIndex方法,它们对列表的每个项执行代码:
[1, 2, 3].each {
println "Item: $it"//it是对应于当前元素的隐式参数
}
['a', 'b', 'c'].eachWithIndex { it, i -> //it是当前元素, i是索引位置
println "$i: $it"
}
除了迭代之外,通过将每个元素转换为其他元素来创建新的List通常是很有用的。 这个操作,通常称为映射,在Groovy中通过collect方法完成:
assert [1, 2, 3].collect { it * 2 } == [2, 4, 6]
//简洁语法
assert [1, 2, 3]*.multiply(2) == [1, 2, 3].collect { it.multiply(2) }
def list = [0]
//可以给“collect”传入list参数,收集元素的列表
assert [1, 2, 3].collect(list) { it * 2 } == [0, 2, 4, 6]
assert list == [0, 2, 4, 6]
list操作
过滤和搜索
Groovy开发工具包包含许多集合的方法,通过这些方法增强标准集合的功能,其中一些如下所示:
assert [1, 2, 3].find { it > 1 } == 2 // 找出第一个符合条件的元素
assert [1, 2, 3].findAll { it > 1 } == [2, 3] //找出所有符合条件的元素
assert ['a', 'b', 'c', 'd', 'e'].findIndexOf { // 找出符合条件的第一个元素的index
it in ['c', 'e', 'g']
} == 2
assert ['a', 'b', 'c', 'd', 'c'].indexOf('c') == 2 // 返回index
assert ['a', 'b', 'c', 'd', 'c'].indexOf('z') == -1 // index返回-1意味着没有找到结果
assert ['a', 'b', 'c', 'd', 'c'].lastIndexOf('c') == 4
assert [1, 2, 3].every { it < 5 } // 如果每一个元素都符合条件则返回true
assert ![1, 2, 3].every { it < 3 }
assert [1, 2, 3].any { it > 2 } // 如果有一个元素符合条件就返回true
assert ![1, 2, 3].any { it > 3 }
assert [1, 2, 3, 4, 5, 6].sum() == 21 // 所有元素求和
assert ['a', 'b', 'c', 'd', 'e'].sum {
it == 'a' ? 1 : it == 'b' ? 2 : it == 'c' ? 3 : it == 'd' ? 4 : it == 'e' ? 5 : 0
// 求和的时候可以自定义元素的值
} == 15
assert ['a', 'b', 'c', 'd', 'e'].sum { ((char) it) - ((char) 'a') } == 10
assert ['a', 'b', 'c', 'd', 'e'].sum() == 'abcde'
assert [['a', 'b'], ['c', 'd']].sum() == ['a', 'b', 'c', 'd']
// 可以提供初始值
assert [].sum(1000) == 1000
assert [1, 2, 3].sum(1000) == 1006
assert [1, 2, 3].join('-') == '1-2-3' // 每个元素之间添加字符串
assert [1, 2, 3].inject('counting: ') { str, item ->
str + item // 减少操作
} == 'counting: 123'
assert [1, 2, 3].inject(0) { count, item ->
count + item
} == 6
这里是用于在集合中查找最大和最小值的惯用Groovy代码:
def list = [9, 4, 2, 10, 5]
assert list.max() == 10
assert list.min() == 2
// 单字符的list也可以查找最大值和最小值
assert ['x', 'y', 'a', 'z'].min() == 'a'
// 我们可以用Closure闭包来描述元素的大小
def list2 = ['abc', 'z', 'xyzuvw', 'Hello', '321']
assert list2.max { it.size() } == 'xyzuvw'
assert list2.min { it.size() } == 'z'
除了闭包之外,您还可以使用Comparator来定义比较条件:
Comparator mc = { a, b -> a == b ? 0 : (a < b ? -1 : 1) }
def list = [7, 4, 9, -6, -1, 11, 2, 3, -9, 5, -13]
assert list.max(mc) == 11
assert list.min(mc) == -13
Comparator mc2 = { a, b -> a == b ? 0 : (Math.abs(a) < Math.abs(b)) ? -1 : 1 }
assert list.max(mc2) == -13
assert list.min(mc2) == -1
assert list.max { a, b -> a.equals(b) ? 0 : Math.abs(a) < Math.abs(b) ? -1 : 1 } == -13
assert list.min { a, b -> a.equals(b) ? 0 : Math.abs(a) < Math.abs(b) ? -1 : 1 } == -1
添加或删除元素
我们可以使用[]分配一个新的空List,使用<<为List添加项目:
def list = []
assert list.empty
list << 5
assert list.size() == 1
list << 7 << 'i' << 11
assert list == [5, 7, 'i', 11]
list << ['m', 'o']
assert list == [5, 7, 'i', 11, ['m', 'o']]
//在<<表达式最前端的list是目标list
assert ([1, 2] << 3 << [4, 5] << 6) == [1, 2, 3, [4, 5], 6]
//使用leftShift方法等价于使用 <<
assert ([1, 2, 3] << 4) == ([1, 2, 3].leftShift(4))
我们可以通过多种方式添加到List中:
assert [1, 2] + 3 + [4, 5] + 6 == [1, 2, 3, 4, 5, 6]
// 等价于调用plus方法
assert [1, 2].plus(3).plus([4, 5]).plus(6) == [1, 2, 3, 4, 5, 6]
def a = [1, 2, 3]
a += 4 //创建了一个新的List
a += [5, 6]
assert a == [1, 2, 3, 4, 5, 6]
assert [1, *[222, 333], 456] == [1, 222, 333, 456]
assert [*[1, 2, 3]] == [1, 2, 3]
assert [1, [2, 3, [4, 5], 6], 7, [8, 9]].flatten() == [1, 2, 3, 4, 5, 6, 7, 8, 9]
def list = [1, 2]
list.add(3)
list.addAll([5, 4])
assert list == [1, 2, 3, 5, 4]
list = [1, 2]
list.add(1, 3) //在索引1前面插入元素3
assert list == [1, 3, 2]
list.addAll(2, [5, 4]) //在索引2前面插入元素[5,4]
assert list == [1, 3, 5, 4, 2]
list = ['a', 'b', 'z', 'e', 'u', 'v', 'g']
list[8] = 'x' // []运算符根据需要使列表增长
// 如果需要插入null
assert list == ['a', 'b', 'z', 'e', 'u', 'v', 'g', null, 'x']
然而,重要的是List上的+运算符不会改变List本身。 与<<相比,+运算符会创建一个新的列表,这通常不是你想要的,并可能导致性能问题。
Groovy开发包还包含一些方法,使您可以通过元素值轻松地从列表中删除元素:
assert ['a','b','c','b','b'] - 'c' == ['a','b','b','b']
assert ['a','b','c','b','b'] - 'b' == ['a','c']
assert ['a','b','c','b','b'] - ['b','c'] == ['a']
def list = [1,2,3,4,3,2,1]
list -= 3 //从原始list创建一个新的list,并删除元素3
assert list == [1,2,4,2,1]
assert ( list -= [2,4] ) == [1,1]
也可以通过引用其索引来删除元素,在这种情况下,列表会改变:
def list = [1,2,3,4,5,6,2,2,1]
assert list.remove(2) == 3 //删除第三个元素并返回第三个元素的值
assert list == [1,2,4,5,6,2,2,1]
如果你只想删除列表中具有相同值的第一个元素,而不是删除所有元素,则调用remove方法:
def list= ['a','b','c','b','b']
assert list.remove('c') // 删除元素'c'如果删除成功返回true
assert list.remove('b') // 删除第一个找到的元素'b',如果删除成功返回true
assert ! list.remove('z') // 返回false,因为没有任何元素删除
assert list == ['a','b','b']
删除列表中的所有元素可以通过调用clear方法来完成:
def list= ['a',2,'c',4]
list.clear()
assert list == []
设置操作
Groovy开发工具包还包括一些方法,使得它易于推理:
assert 'a' in ['a','b','c'] // 如果元素'a'在list中返回true
assert ['a','b','c'].contains('a') // 等价于java中的`contains`方法
assert [1,3,4].containsAll([1,4]) // `containsAll` 将检测每一个待查元素,如果都包含在list中,返回true
assert [1,2,3,3,3,3,4,5].count(3) == 4 // 返回元素3在列表中包含的数量
assert [1,2,3,3,3,3,4,5].count {
it%2==0 // 返回符合断言的元素在列表中包含的数量
} == 2
assert [1,2,4,6,8,10,12].intersect([1,3,6,9,12]) == [1,6,12]//返回两个列表的交集
assert [1,2,3].disjoint( [4,6,9] )//两个列表是互斥的,返回true
assert ![1,2,3].disjoint( [2,4,6] )
排序
使用List经常会遇到排序。 Groovy提供了各种选项来排序List,从使用闭包到comparators,如下例所示:
assert [6, 3, 9, 2, 7, 1, 5].sort() == [1, 2, 3, 5, 6, 7, 9]
def list = ['abc', 'z', 'xyzuvw', 'Hello', '321']
assert list.sort {
it.size()
} == ['z', 'abc', '321', 'Hello', 'xyzuvw']
def list2 = [7, 4, -6, -1, 11, 2, 3, -9, 5, -13]
assert list2.sort { a, b -> a == b ? 0 : Math.abs(a) < Math.abs(b) ? -1 : 1 } ==
[-1, 2, 3, 4, 5, -6, 7, -9, 11, -13]
Comparator mc = { a, b -> a == b ? 0 : Math.abs(a) < Math.abs(b) ? -1 : 1 }
// 仅限于JDK 8+
// list2.sort(mc)
// assert list2 == [-1, 2, 3, 4, 5, -6, 7, -9, 11, -13]
def list3 = [6, -3, 9, 2, -7, 1, 5]
Collections.sort(list3)
assert list3 == [-7, -3, 1, 2, 5, 6, 9]
Collections.sort(list3, mc)
assert list3 == [1, 2, -3, 5, 6, -7, 9]
复制元素
Groovy开发工具包还利用了操作符重载,以提供允许复制列表元素的方法:
assert [1, 2, 3] * 3 == [1, 2, 3, 1, 2, 3, 1, 2, 3]
assert [1, 2, 3].multiply(2) == [1, 2, 3, 1, 2, 3]
assert Collections.nCopies(3, 'b') == ['b', 'b', 'b']
// 来自JDK的nCopies具有与列表的乘法不同的语义
assert Collections.nCopies(2, [1, 2]) == [[1, 2], [1, 2]] //而不是[1,2,1,2]
2、Maps
Map 字面值
在Groovy中,可以使用map语法创建map(也称为关联数组):[:]:
def map = [name: 'Gromit', likes: 'cheese', id: 1234]
assert map.get('name') == 'Gromit'
assert map.get('id') == 1234
assert map['name'] == 'Gromit'
assert map['id'] == 1234
assert map instanceof java.util.Map
def emptyMap = [:]
assert emptyMap.size() == 0
emptyMap.put("foo", 5)
assert emptyMap.size() == 1
assert emptyMap.get("foo") == 5
默认情况下,map的key是字符串:[a:1]等价于['a':1]。 如果您定义一个名为a的变量,并且您希望a的值为您的map的key,这可能会令人困惑。 如果是这种情况,则必须通过添加括号来转义键,如以下示例所示:
def a = 'Bob'
def ages = [a: 43]
assert ages['Bob'] == null // 找不到`Bob`
assert ages['a'] == 43 // 因为 `a` 是字面值(文本)!
ages = [(a): 43] // 将`a`用()括起来
assert ages['Bob'] == 43 // 这时就能找到'Bob'的值了
除了map 字面值外, 也可以通过clone方法得到一个map的副本:
def map = [
simple : 123,
complex: [a: 1, b: 2]
]
def map2 = map.clone()
assert map2.get('simple') == map.get('simple')
assert map2.get('complex') == map.get('complex')
map2.get('complex').put('c', 3)
assert map.get('complex').get('c') == 3
如前面的示例所示,生成的map是原始map的浅拷贝
Map属性符号
Maps也像bean一样,所以你可以使用属性符号在Map中get/set项,只要键是有效的Groovy标识符的字符串即可:
def map = [name: 'Gromit', likes: 'cheese', id: 1234]
assert map.name == 'Gromit' // 同map.get('Gromit')
assert map.id == 1234
def emptyMap = [:]
assert emptyMap.size() == 0
emptyMap.foo = 5
assert emptyMap.size() == 1
assert emptyMap.foo == 5
注意:根据设计,map.foo会一直在map中查找这个key。这意味着foo.class将在不包含class键的map上返回null。如果你是想返回foo的类型,那么你必须使用foo.getClass()方法:
def map = [name: 'Gromit', likes: 'cheese', id: 1234]
assert map.class == null
assert map.get('class') == null
assert map.getClass() == LinkedHashMap // 这很可能是你想要的结果
map = [1 : 'a',
(true) : 'p',
(false): 'q',
(null) : 'x',
'null' : 'z']
assert map.containsKey(1) // 数字1不是一个标识符,所以得这样调用
assert map.true == null
assert map.false == null
assert map.get(true) == 'p'
assert map.get(false) == 'q'
assert map.null == 'z'
assert map.get(null) == 'x'
Map迭代
照例,在Groovy开发工具包中,Map上的惯用迭代使用each和eachWithIndex方法。 值得注意的是,使用Map字面值符号创建的Map是有序的,也就是说,如果对Map条目进行迭代,将保证条目将按照它们在Map中添加的顺序返回。
def map = [
Bob : 42,
Alice: 54,
Max : 33
]
// `entry` is a map entry
map.each { entry ->
println "Name: $entry.key Age: $entry.value"
}
// `entry` is a map entry, `i` the index in the map
map.eachWithIndex { entry, i ->
println "$i - Name: $entry.key Age: $entry.value"
}
// Alternatively you can use key and value directly
map.each { key, value ->
println "Name: $key Age: $value"
}
// Key, value and i as the index in the map
map.eachWithIndex { key, value, i ->
println "$i - Name: $key Age: $value"
}
Map操作
添加或删除元素
向Map中添加元素可以使用put方法,下标运算符或使用putAll:
def defaults = [1: 'a', 2: 'b', 3: 'c', 4: 'd']
def overrides = [2: 'z', 5: 'x', 13: 'x']
def result = new LinkedHashMap(defaults)
result.put(15, 't')
result[17] = 'u'
result.putAll(overrides)
assert result == [1: 'a', 2: 'z', 3: 'c', 4: 'd', 5: 'x', 13: 'x', 15: 't', 17: 'u']
删除Map的所有元素可以通过调用clear方法来完成:
def m = [1:'a', 2:'b']
assert m.get(1) == 'a'
m.clear()
assert m == [:]
使用Map字面值语法生成的Map使用object的equals和hashcode方法。 这意味着你不应该使用哈希码随时间变化的object,否则你将无法获得相关的值。
还值得注意的是,您不应该使用GString作为Map的键,因为GString的哈希码与等效String的哈希码不同:
def key = 'some key'
def map = [:]
def gstringKey = "${key.toUpperCase()}"
map.put(gstringKey,'value')
assert map.get('SOME KEY') == null
Keys, values and entries
我们可以检查视图中的keys, values, and entries:
def map = [1:'a', 2:'b', 3:'c']
def entries = map.entrySet()
entries.each { entry ->
assert entry.key in [1,2,3]
assert entry.value in ['a','b','c']
}
def keys = map.keySet()
assert keys == [1,2,3] as Set
由于操作的成功直接取决于正在操作的Map的类型,因此视图(不管是map的entry,key还是value)返回的变化值是非常不鼓励的。 特别地,Groovy依赖于来自JDK的集合,通常不能保证集合可以通过keySet,entrySet或values安全地操作。
过滤和搜索
Groovy开发包包含与List中类似的过滤,搜索和收集方法:
def people = [
1: [name:'Bob', age: 32, gender: 'M'],
2: [name:'Johnny', age: 36, gender: 'M'],
3: [name:'Claire', age: 21, gender: 'F'],
4: [name:'Amy', age: 54, gender:'F']
]
def bob = people.find { it.value.name == 'Bob' } // 查找单个entry
def females = people.findAll { it.value.gender == 'F' }
//两个都是返回entries,但是您可以使用collect来检索年龄例如
def ageOfBob = bob.value.age
def agesOfFemales = females.collect {
it.value.age
}
assert ageOfBob == 32
assert agesOfFemales == [21,54]
// 但您也可以使用键/对值作为闭包的参数but you could also use a key/pair value as the parameters of the closures
def agesOfMales = people.findAll { id, person ->
person.gender == 'M'
}.collect { id, person ->
person.age
}
assert agesOfMales == [32, 36]
// `every` 如果所有entries都匹配规则,则返回true
assert people.every { id, person ->
person.age > 18
}
// `any` 如果任何一个entry匹配规则,则返回true
assert people.any { id, person ->
person.age == 54
}
分组
我们可以使用一些标准将List分组到Map中:
assert ['a', 7, 'b', [2, 3]].groupBy {
it.class
} == [(String) : ['a', 'b'],
(Integer) : [7],
(ArrayList): [[2, 3]]
]
assert [
[name: 'Clark', city: 'London'], [name: 'Sharma', city: 'London'],
[name: 'Maradona', city: 'LA'], [name: 'Zhang', city: 'HK'],
[name: 'Ali', city: 'HK'], [name: 'Liu', city: 'HK'],
].groupBy { it.city } == [
London: [[name: 'Clark', city: 'London'],
[name: 'Sharma', city: 'London']],
LA : [[name: 'Maradona', city: 'LA']],
HK : [[name: 'Zhang', city: 'HK'],
[name: 'Ali', city: 'HK'],
[name: 'Liu', city: 'HK']],
]
3、Ranges
Ranges允许您创建顺序值List。 这些可以用作List,因为Range扩展了java.util.List。
使用..符号定义的范围是包含性的(即List包含from和to值)。
使用.. <符号定义的范围是半开的,它们包括第一个值,但不是最后一个值。
// 全包含的range
def range = 5..8
assert range.size() == 4
assert range.get(2) == 7
assert range[2] == 7
assert range instanceof java.util.List
assert range.contains(5)
assert range.contains(8)
// 半开的range
range = 5..<8
assert range.size() == 3
assert range.get(2) == 7
assert range[2] == 7
assert range instanceof java.util.List
assert range.contains(5)
assert !range.contains(8)
//获取range的端点而不使用索引
range = 1..10
assert range.from == 1
assert range.to == 10
请注意,int类型的Range实现了高效率,创建了一个包含from和to值的轻量级Java对象。
Ranges可以用于实现java.lang.Comparable以进行比较的任何Java对象,并且还有方法next()和previous()返回range中的下一个/上一个项目。 例如,您可以创建一系列String元素:
// 全包括range
def range = 'a'..'d'
assert range.size() == 4
assert range.get(2) == 'c'
assert range[2] == 'c'
assert range instanceof java.util.List
assert range.contains('a')
assert range.contains('d')
assert !range.contains('e')
您可以使用经典的for循环在一个range上进行迭代:
for (i in 1..10) {
println "Hello ${i}"
}
但是或者,您可以通过使用each方法迭代Range,在更加Groovy惯用的风格中实现相同的效果:
(1..10).each { i ->
println "Hello ${i}"
}
Range也可以用在switch语句中:
switch (years) {
case 1..10: interestRate = 0.076; break;
case 11..25: interestRate = 0.052; break;
default: interestRate = 0.037;
}
4、集合的语法增强
GPath支持
由于对List和Map的属性符号支持,Groovy提供了语法糖,使得处理嵌套集合变得非常容易,如下例所示:
def listOfMaps = [['a': 11, 'b': 12], ['a': 21, 'b': 22]]
assert listOfMaps.a == [11, 21] //GPath 标记
assert listOfMaps*.a == [11, 21] //扩展点符号
listOfMaps = [['a': 11, 'b': 12], ['a': 21, 'b': 22], null]
assert listOfMaps*.a == [11, 21, null] // 适用于空值
assert listOfMaps*.a == listOfMaps.collect { it?.a } //等价符号
// 但这只会收集非空值
assert listOfMaps.a == [11,21]
扩展运算符
扩展运算符可以用于将集合“内联”到另一个集合中。 它是语法糖,通常避免调用putAll并促进一行的实现:
assert [ 'z': 900,
*: ['a': 100, 'b': 200], 'a': 300] == ['a': 300, 'b': 200, 'z': 900]
//在map定义中的扩展map符号
assert [*: [3: 3, *: [5: 5]], 7: 7] == [3: 3, 5: 5, 7: 7]
def f = { [1: 'u', 2: 'v', 3: 'w'] }
assert [*: f(), 10: 'zz'] == [1: 'u', 10: 'zz', 2: 'v', 3: 'w']
//函数参数中的扩展map符号
f = { map -> map.c }
assert f(*: ['a': 10, 'b': 20, 'c': 30], 'e': 50) == 30
f = { m, i, j, k -> [m, i, j, k] }
//使用具有混合未命名和命名参数的展开map符号
assert f('e': 100, *[4, 5], *: ['a': 10, 'b': 20, 'c': 30], 6) ==
[["e": 100, "b": 20, "c": 30, "a": 10], 4, 5, 6]
星号“*”运算符
“星点”运算符是一个快捷运算符,允许您对集合的所有元素调用方法或属性:
assert [1, 3, 5] == ['a', 'few', 'words']*.size()
class Person {
String name
int age
}
def persons = [new Person(name:'Hugo', age:17), new Person(name:'Sandra',age:19)]
assert [17, 19] == persons*.age
使用下标运算符切片
您可以使用下标表达式将其索引到list,数组和map中。 有趣的是,字符串在这种情况下被视为特殊类型的集合:
def text = 'nice cheese gromit!'
def x = text[2]
assert x == 'c'
assert x.class == String
def sub = text[5..10]
assert sub == 'cheese'
def list = [10, 11, 12, 13]
def answer = list[2,3]
assert answer == [12,13]
请注意,您可以使用Range提取集合的一部分:
list = 100..200
sub = list[1, 3, 20..25, 33]
assert sub == [101, 103, 120, 121, 122, 123, 124, 125, 133]
下标运算符可用于更新现有集合(对于不可变的集合类型):
list = ['a','x','x','d']
list[1..2] = ['b','c']
assert list == ['a','b','c','d']
值得注意的是,允许使用负索引,从集合的末尾更容易提取:
您可以使用负指数从List,array,String等结尾计数。
text = "nice cheese gromit!"
x = text[-1]
assert x == "!"
def name = text[-7..-2]
assert name == "gromit"
最终,如果使用向后Range(开始索引大于结束索引),则答案将反过来。
text = "nice cheese gromit!"
name = text[3..1]
assert name == "eci"
五、IO操作
Groovy为I/O操作提供了许多帮助方法,虽然你可以在Groovy中用标准Java代码来实现I/O操作,不过Groovy提供了大量的方便的方式来操作File、Stream、Reader等等。
1、读取文件
读取文本文件并打印每一行文本
new File(baseDir, 'haiku.txt').eachLine{ line ->
println line
}
eachLine方法是Groovy为File类自动添加的方法,同时提供多个变体方法,比如你想知道读取的行数,你可以使用它的变体方法,如下
new File(baseDir, 'haiku.txt').eachLine{ line, nb ->
println "Line $nb: $line"
}
如果出于某种原因eachLine抛出异常,该方法能够确保资源正确地关闭,这适用于所有Groovy添加的I/O资源方法
例如在某些情况下,你更喜欢使用Reader访问I/O资源,但你仍然受益于Groovy的自动资源管理。在下一个示例中,即使发生了异常,Reader也将会被关闭。
def count = 0, MAXSIZE = 3
new File(baseDir,"haiku.txt").withReader { reader ->
while (reader.readLine()) {
if (++count > MAXSIZE) {
throw new RuntimeException('Haiku should only have 3 verses')
}
}
}
如果你需要收集文本文件的每一行到一个列表中,你可以这样做:
def list = new File(baseDir, 'haiku.txt').collect {it}
或者你甚至可以用as操作符来讲文件内容转为String数组
def array = new File(baseDir, 'haiku.txt') as String[]
多少次你不得不获得一个文件的内容到一个byte[],它需要多少代码?Groovy使得这件事非常的容易。
byte[] contents = file.bytes
处理I/O并不局限于处理文件。事实上,很多的操作依赖于输入/输出流,这就是为什么Groovy添加大量的支持方法,正如你所看到的文档。
例如,你可以很容易从一个文件获得一个InputStream
def is = new File(baseDir,'haiku.txt').newInputStream()
// do something ...
is.close()
但是你可以看到,这种方式需要你手动关闭流。会为你留意到,在Groovy中使用withInputStream通常是更好的方式。
new File(baseDir,'haiku.txt').withInputStream { stream ->
// do something ...
}
2、写文件
当然,一些时候你并不想读取文件,而是要写文件。其中一个方式就是使用Writer:
new File(baseDir,'haiku.txt').withWriter('utf-8') { writer ->
writer.writeLine 'Into the ancient pond'
writer.writeLine 'A frog jumps'
writer.writeLine 'Water’s sound!'
}
但是对于这样一个简单的示例中,使用<<操作符就足够了:
new File(baseDir,'haiku.txt') << '''Into the ancient pond
A frog jumps
Water’s sound!'''
当然我们并不总是处理文本内容,所以您可以使用Writer或者直接写入字节,例如:
file.bytes = [66,22,11]
当然你也可以直接处理输出流。例如,下面就是如何创建一个输出流写入一个文件:
def os = new File(baseDir,'data.bin').newOutputStream()
// do something ...
os.close()
但是你可以看到它需要你手动关闭输出流。会为你留意到,在Groovy中使用withOutputStream通常是更好的方式。
new File(baseDir,'data.bin').withOutputStream { stream ->
// do something ...
}
3、遍历文件树
在脚本中,在文件树种查找一些特定文件并处理这些文件是很常见的事情。Groovy提供了多种方法来做到这一点。例如你可以为一个文件夹中的每个文件直行一些操作:
//在目录的每一个文件直行闭包代码
dir.eachFile { file ->
println file.name
}
//在目录中符合匹配模式的文件直行闭包代码
dir.eachFileMatch(~/.*\.txt/) { file ->
println file.name
}
通常你需要处理一个更深的目录结构的文件,这种情况下你可以使用eachFileRecurse
//在指定目录递归查找,并在每一个文件和目录直行闭包代码
dir.eachFileRecurse { file ->
println file.name
}
//在指定目录递归查找,并在每一个文件直行闭包代码
dir.eachFileRecurse(FileType.FILES) { file ->
println file.name
}
对于更复杂的遍历技术可以使用traverse方法,它你需要设置一个特殊的标志指示这个遍历要做什么。
dir.traverse { file ->
if (file.directory && file.name=='bin') {
//如果当前file是一个目录或者它的名字是 bin ,则停止遍历
FileVisitResult.TERMINATE
} else {
//打印文件名并继续遍历
println file.name
FileVisitResult.CONTINUE
}
}
4、数据和对象
在Java中使用java.io.DataOutputStream和java.io.DataInputStream进行序列化和反序列化并不少见,Groovy将使它更容易处理。例如,您可以把数据序列化到一个文件中并反序列化它使用以下代码:
boolean b = true
String message = 'Hello from Groovy'
// Serialize data into a file
file.withDataOutputStream { out ->
out.writeBoolean(b)
out.writeUTF(message)
}
// ...
// Then read it back
file.withDataInputStream { input ->
assert input.readBoolean() == b
assert input.readUTF() == message
}
类似的,如果您想要序列化的数据实现了Serializable接口,你可以将它作为一个Object输出流处理,例如:
Person p = new Person(name:'Bob', age:76)
// Serialize data into a file
file.withObjectOutputStream { out ->
out.writeObject(p)
}
// ...
// Then read it back
file.withObjectInputStream { input ->
def p2 = input.readObject()
assert p2.name == p.name
assert p2.age == p.age
}
5、执行外部程序
前一节中描述的是使用Groovy处理文件多么容易。然而在系统管理等领域或devops通常需要与外部processes沟通。Groovy提供了一个简单的方法来执行命令行processes。仅仅需要些命令字符串再调用execute()方法即可。如。在 *nix机(安装了合适的 *nix命令工具的windows机),你这样执行:
//在外部process执行`ls`命令
def process = "ls -l".execute()
//读取文本并打印
println "Found text ${process.text}"
execute()方法返回一个java.lang.Process对象,并允许处理它的in/out/err流和退出值,从Process检查等。
如,这是和上面一样的命令
//执行`ls`命令
def process = "ls -l".execute()
//遍历命令进程的输入流
process.in.eachLine { line ->
//打印每一行输入流
println line
}
值得注意的是,in是一个输入流,对应于命令的标准输出。 out指的是可以向Process发送数据的流(标准输入)。
记住许多命令是shell内置函数,需要特殊处理。所以,如果你想要在一个Windows机器上列出一个目录下的所有文件:
def process = "dir".execute()
println "${process.text}"
你会收到一个IOException说无法运行程序“dir”:CreateProcess error = 2,系统找不到指定的文件。这是因为dir内置在Windows shell(cmd.exe)中,不能作为简单的可执行文件运行。 相反,你需要写:
def process = "cmd /c dir".execute()
println "${process.text}"
此外,由于此功能当前使用java.lang.Process底层,必须考虑该类的缺陷。尤其是,这个类的javadoc说:
由于一些本地平台仅为标准输入和输出流提供有限的缓冲区大小,因此无法及时写入输入流或读取子过程的输出流可能导致子过程阻塞甚至死锁
正因为如此,Groovy提供了一些额外的帮助方法,使得流处理更容易。
这里是如何从你的Process中gobble(未翻译)所有的输出(包括错误流输出):
def p = "rm -f foo.tmp".execute([], tmpDir)
p.consumeProcessOutput()
p.waitFor()
还有consumeProcessOutput的变体,使用StringBuffer,InputStream,OutputStream等...有关完整的列表,请阅读GDK API for java.lang.Process
此外,这些是一个pipeTo命令(映射到|以允许重载),它使一个进程的输出流被传送到另一个进程的输入流。
这里有一些使用的例子:
proc1 = 'ls'.execute()
proc2 = 'tr -d o'.execute()
proc3 = 'tr -d e'.execute()
proc4 = 'tr -d i'.execute()
proc1 | proc2 | proc3 | proc4
proc4.waitFor()
if (proc4.exitValue()) {
println proc4.err.text
} else {
println proc4.text
}
消耗错误
def sout = new StringBuilder()
def serr = new StringBuilder()
proc2 = 'tr -d o'.execute()
proc3 = 'tr -d e'.execute()
proc4 = 'tr -d i'.execute()
proc4.consumeProcessOutput(sout, serr)
proc2 | proc3 | proc4
[proc2, proc3].each { it.consumeProcessErrorStream(serr) }
proc2.withWriter { writer ->
writer << 'testfile.groovy'
}
proc4.waitForOrKill(1000)
println "Standard output: $sout"
println "Standard error: $serr"
六、运行时元编程
Groovy语言支持两种类型的元编程:运行时元编程和编译时元编程。 第一个允许在运行时改变类模型和程序的行为,而第二个只在编译时发生。 两者都有利弊,我们将在本节详细介绍。
使用运行时元编程,我们可以在运行时截取,注入,合成类和接口的方法。 为了更深入地理解Groovy MOP,我们需要了解Groovy对象和Groovy的方法处理。 在Groovy中,我们使用了三种对象:POJO,POGO和Groovy Interceptors。 Groovy允许对所有类型的对象进行元编程,但是是以不同的方式进行的。
- POJO - 一个常规的Java对象,它的类是用Java或任何其他运行在JVM上的编程语言编写的。
- POGO - 一个Groovy对象,它的类是用Groovy编写的。 它扩展了java.lang.Object并在默认情况下实现了groovy.lang.GroovyObject接口。
- Groovy Interceptor - 一个Groovy对象,它实现了groovy.lang.GroovyInterceptable接口并具有方法拦截功能,我们将在GroovyInterceptable部分讨论。
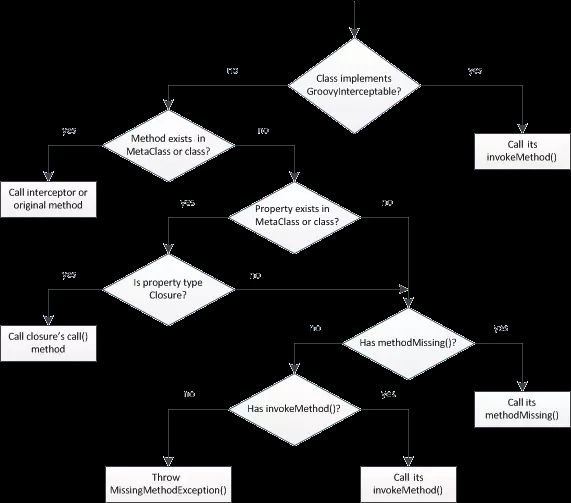
对于每个方法调用,Groovy检查对象是POJO还是POGO。 对于POJO,Groovy从groovy.lang.MetaClassRegistry获取它的MetaClass,并将方法调用委托给它。 对于POGO,Groovy需要更多步骤,如下图所示:
1、GroovyObject接口
groovy.lang.GroovyObject是Groovy中的主要接口,就像Object类是Java中的主要接口一样。GroovyObject在groovy.lang.GroovyObjectSupport类中有一个默认实现,它负责将调用传递给groovy.lang.MetaClass对象。 GroovyObject源代码如下:
public interface GroovyObject {
/**
* Invokes the given method.
*
* @param name the name of the method to call
* @param args the arguments to use for the method call
* @return the result of invoking the method
*/
Object invokeMethod(String name, Object args);
/**
* Retrieves a property value.
*
* @param propertyName the name of the property of interest
* @return the given property
*/
Object getProperty(String propertyName);
/**
* Sets the given property to the new value.
*
* @param propertyName the name of the property of interest
* @param newValue the new value for the property
*/
void setProperty(String propertyName, Object newValue);
/**
* Returns the metaclass for a given class.
*
* @return the metaClass of this instance
*/
MetaClass getMetaClass();
/**
* Allows the MetaClass to be replaced with a derived implementation.
*
* @param metaClass the new metaclass
*/
void setMetaClass(MetaClass metaClass);
}
invokeMethod
根据运行时元编程中的模式,当您调用的方法不存在于Groovy对象上时,将调用此方法。 下面是一个重写invokeMethod()方法的简单示例:
class SomeGroovyClass {
def invokeMethod(String name, Object args) {
return "called invokeMethod $name $args"
}
def test() {
return 'method exists'
}
}
def someGroovyClass = new SomeGroovyClass()
assert someGroovyClass.test() == 'method exists'
assert someGroovyClass.someMethod() == 'called invokeMethod someMethod []'
get/setProperty
对属性的每个读取访问都可以通过覆盖当前对象的getProperty()方法来拦截。 这里有一个简单的例子:
class SomeGroovyClass {
def property1 = 'ha'
def field2 = 'ho'
def field4 = 'hu'
def getField1() {
return 'getHa'
}
def getProperty(String name) {
if (name != 'field3')
return metaClass.getProperty(this, name) //将请求转发到getter以获取除field3之外的所有属性。
else
return 'field3'
}
}
def someGroovyClass = new SomeGroovyClass()
assert someGroovyClass.field1 == 'getHa'
assert someGroovyClass.field2 == 'ho'
assert someGroovyClass.field3 == 'field3'
assert someGroovyClass.field4 == 'hu'
您可以通过覆盖setProperty()方法来拦截对属性的写访问权限:
class POGO {
String property
void setProperty(String name, Object value) {
this.@"$name" = 'overridden'
}
}
def pogo = new POGO()
pogo.property = 'a'
assert pogo.property == 'overridden'
get/setMetaClass
您可以访问对象的metaClass或设置您自己的MetaClass实现以更改默认拦截机制。 例如,您可以编写自己的MetaClass接口实现,并将其分配给对象,从而更改拦截机制:
// getMetaclass
someObject.metaClass
// setMetaClass
someObject.metaClass = new OwnMetaClassImplementation()
2、get/setAttribute
此功能与MetaClass实现相关。 在默认实现中,您可以访问字段而不调用它们的getter和setter。 下面的示例演示了这种方法:
class SomeGroovyClass {
def field1 = 'ha'
def field2 = 'ho'
def getField1() {
return 'getHa'
}
}
def someGroovyClass = new SomeGroovyClass()
assert someGroovyClass.metaClass.getAttribute(someGroovyClass, 'field1') == 'ha'
assert someGroovyClass.metaClass.getAttribute(someGroovyClass, 'field2') == 'ho'
class POGO {
private String field
String property1
void setProperty1(String property1) {
this.property1 = "setProperty1"
}
}
def pogo = new POGO()
pogo.metaClass.setAttribute(pogo, 'field', 'ha')
pogo.metaClass.setAttribute(pogo, 'property1', 'ho')
assert pogo.field == 'ha'
assert pogo.property1 == 'ho'
3、methodMissing
Groovy支持methodMissing的概念。 此方法与invokeMethod的不同之处在于,它仅在失败的方法分派的情况下被调用,当没有找到给定名称和/或给定参数的方法时:
class Foo {
def methodMissing(String name, def args) {
return "this is me"
}
}
assert new Foo().someUnknownMethod(42l) == 'this is me'
通常当使用methodMissing时,可以缓存结果,以便下次调用相同的方法。
例如,考虑GORM中的动态查找器。 这些是根据methodMissing来实现的。 代码类似这样:
class GORM {
def dynamicMethods = [...] // an array of dynamic methods that use regex
def methodMissing(String name, args) {
def method = dynamicMethods.find { it.match(name) }
if(method) {
GORM.metaClass."$name" = { Object[] varArgs ->
method.invoke(delegate, name, varArgs)
}
return method.invoke(delegate,name, args)
}
else throw new MissingMethodException(name, delegate, args)
}
}
注意如果我们找到一个方法来调用,随后就会使用ExpandoMetaClass动态地注册一个新的方法。 这是为了下次更有效率的调用相同的方法。 这种使用methodMissing的方法不像invokeMethod一样,这种方式在第二次调用时并不产生昂贵开销。
4、propertyMissing
Groovy支持propertyMissing的概念,用于拦截那些失败的属性解析尝试。 在getter方法的情况下,propertyMissing接受一个包含属性名称的String参数:
class Foo {
def propertyMissing(String name) { name }
}
assert new Foo().boo == 'boo'
仅当Groovy运行时找不到给定属性的getter方法时才调用propertyMissing(String)方法。
对于setter方法,可以添加另一个propertyMissing定义,它接受一个附加的value参数:
class Foo {
def storage = [:]
def propertyMissing(String name, value) { storage[name] = value }
def propertyMissing(String name) { storage[name] }
}
def f = new Foo()
f.foo = "bar"
assert f.foo == "bar"
与methodMissing一样,最佳做法是在运行时动态注册新属性,以提高总体查找性能。
methodMissing和propertyMissing方法处理静态方法和属性可以通过ExpandoMetaClass
5、GroovyInterceptable
groovy.lang.GroovyInterceptable接口是用于通知Groovy运行时的扩展GroovyObject的标记接口,所有方法都应通过Groovy运行时的方法分派器机制拦截。
package groovy.lang;
public interface GroovyInterceptable extends GroovyObject {
}
当Groovy对象实现GroovyInterceptable接口时,对任何方法的调用都会调用invokeMethod()方法。 下面你可以看到一个这种类型的对象的简单例子:
class Interception implements GroovyInterceptable {
def definedMethod() { }
def invokeMethod(String name, Object args) {
'invokedMethod'
}
}
下一段代码是一个测试,显示对现有和不存在的方法的调用都将返回相同的值。
class InterceptableTest extends GroovyTestCase {
void testCheckInterception() {
def interception = new Interception()
assert interception.definedMethod() == 'invokedMethod'
assert interception.someMethod() == 'invokedMethod'
}
}
我们不能使用默认groovy方法,如println,因为这些方法被注入到所有groovy对象中,所以它们也会被拦截。
如果我们要拦截所有方法调用,但不想实现GroovyInterceptable接口,我们可以在对象的MetaClass上实现invokeMethod()。 此方法适用于POGO和POJO,如此示例所示:
class InterceptionThroughMetaClassTest extends GroovyTestCase {
void testPOJOMetaClassInterception() {
String invoking = 'ha'
invoking.metaClass.invokeMethod = { String name, Object args ->
'invoked'
}
assert invoking.length() == 'invoked'
assert invoking.someMethod() == 'invoked'
}
void testPOGOMetaClassInterception() {
Entity entity = new Entity('Hello')
entity.metaClass.invokeMethod = { String name, Object args ->
'invoked'
}
assert entity.build(new Object()) == 'invoked'
assert entity.someMethod() == 'invoked'
}
}
6、MateClass
Groovy带有一个特殊的MetaClass,它就是ExpandoMetaClass。 它是特别的,它允许通过使用一个整洁的闭包语法动态添加或更改方法,构造函数,属性,甚至静态方法。
应用这些修改在模拟(mock)或桩(stub)情况下特别有用,如测试指南中所示。
每个java.lang.Class由Groovy提供,并有一个特殊的metaClass属性,它将提供对ExpandoMetaClass实例的引用。 然后,此实例可用于添加方法或更改已有现有方法的行为。
默认情况下ExpandoMetaClass不执行继承。 要启用它,您必须在应用程序启动之前调用ExpandoMetaClass#enableGlobally(),例如在main方法或servlet引导中。
以下部分详细介绍了ExpandoMetaClass如何在各种情况下使用。
方法
一旦通过调用metaClass属性访问ExpandoMetaClass,可以使用左移<<或=运算符来添加方法。
注意,左移位运算符用于附加一个新方法。 如果类或接口声明了具有相同名称和参数类型的公共方法,包括继承自父类和父接口但不包括在运行时添加到metaClass的那些方法,那么将抛出异常。 如果要替换由类或接口声明的方法,可以使用=运算符。
运算符通过一个Closure代码块实例,将功能应用于metaClass的不存在的属性上。
class Book {
String title
}
Book.metaClass.titleInUpperCase << {-> title.toUpperCase() }
def b = new Book(title:"The Stand")
assert "THE STAND" == b.titleInUpperCase()
上面的例子显示了如何通过访问metaClass属性并使用<<或=运算符来分配一个Closure代码块来将新方法添加到类中。 Closure参数被解释为方法参数。 无参数方法可以使用{-> ...}语法添加。
属性
ExpandoMetaClass支持两种机制来添加或覆盖属性。
首先,它支持通过向metaClass的属性赋值来声明一个可变属性:
class Book {
String title
}
Book.metaClass.author = "Stephen King"
def b = new Book()
assert "Stephen King" == b.author
另一种方法是通过使用添加实例方法的标准机制来添加getter和/或setter方法。
class Book {
String title
}
Book.metaClass.getAuthor << {-> "Stephen King" }
def b = new Book()
assert "Stephen King" == b.author
在上面的源代码示例中,属性由闭包指定,并且是只读属性。 可以添加一个等效的setter方法,但是该属性值需要被存储以备将来使用。 这可以如下面的示例所示完成。
class Book {
String title
}
def properties = Collections.synchronizedMap([:])
Book.metaClass.setAuthor = { String value ->
properties[System.identityHashCode(delegate) + "author"] = value
}
Book.metaClass.getAuthor = {->
properties[System.identityHashCode(delegate) + "author"]
}
这不是唯一的方式。 例如,在servlet容器中,一种方式可能是将值作为请求属性存储在当前执行的请求中(如在Grails中的某些情况下所做的那样)。
构造函数
可以通过使用特殊的构造函数属性来添加构造函数。 可以使用<<或=运算符来分配Closure代码块。 当代码在运行时执行时,Closure参数将成为构造函数参数。
class Book {
String title
}
Book.metaClass.constructor << { String title -> new Book(title:title) }
def book = new Book('Groovy in Action - 2nd Edition')
assert book.title == 'Groovy in Action - 2nd Edition'
当添加构造函数时要小心,因为它很容易陷入堆栈溢出问题。
静态方法
可以使用与实例方法相同的技术添加静态方法,并在方法名称之前添加静态限定符。
class Book {
String title
}
Book.metaClass.static.create << { String title -> new Book(title:title) }
def b = Book.create("The Stand")
借用方法
使用ExpandoMetaClass,可以使用Groovy的方法指针语法从其他类中借用方法。
class Person {
String name
}
class MortgageLender {
def borrowMoney() {
"buy house"
}
}
def lender = new MortgageLender()
Person.metaClass.buyHouse = lender.&borrowMoney
def p = new Person()
assert "buy house" == p.buyHouse()
动态方法名称
由于Groovy允许使用Strings作为属性名,这反过来允许您在运行时动态创建方法和属性名。 要创建具有动态名称的方法,只需使用引用属性名称的语言特性作为字符串。
class Person {
String name = "Fred"
}
def methodName = "Bob"
Person.metaClass."changeNameTo${methodName}" = {-> delegate.name = "Bob" }
def p = new Person()
assert "Fred" == p.name
p.changeNameToBob()
assert "Bob" == p.name
相同的概念可以应用于静态方法和属性。
动态方法名称的一个应用程序可以在Grails Web应用程序框架中找到。 “动态编解码器”的概念通过使用动态方法名称来实现。
HTMLCodec 类
class HTMLCodec {
static encode = { theTarget ->
HtmlUtils.htmlEscape(theTarget.toString())
}
static decode = { theTarget ->
HtmlUtils.htmlUnescape(theTarget.toString())
}
}
上面的示例显示了编解码器实现。 Grails有各种编解码器实现,每个在一个类中定义。 在运行时,应用程序类路径中将有多个编解码器类。 在应用程序启动时,框架向某些元类添加encodeXXX和decodeXXX方法,其中XXX是编解码器类名称的第一部分(例如,encodeHTML)。 这种机制在下面显示的一些Groovy伪代码中:
def codecs = classes.findAll { it.name.endsWith('Codec') }
codecs.each { codec ->
Object.metaClass."encodeAs${codec.name-'Codec'}" = { codec.newInstance().encode(delegate) }
Object.metaClass."decodeFrom${codec.name-'Codec'}" = { codec.newInstance().decode(delegate) }
}
def html = 'hello'
assert 'hello' == html.encodeAsHTML()
运行时发现
在运行时,知道在执行该方法时存在什么其他方法或属性通常是有用的。 ExpandoMetaClass在撰写本文时提供了以下方法:
getMetaMethodhasMetaMethodgetMetaPropertyhasMetaProperty
你为什么不能使用反射? 因为Groovy是不同的,它有方法是“真正的”方法,同时方法只在运行时可用。 这些有时(但不总是)表示为MetaMethods。 MetaMethod告诉你在运行时可用的方法,因此你的代码可以适应。
当覆盖invokeMethod,getProperty和/或setProperty时,这是特别有用的。
GroovyObject 方法
ExpandoMetaClass的另一个特点是它允许重写方法invokeMethod,getProperty和setProperty,所有这些都可以在groovy.lang.GroovyObject类中找到。
以下示例显示如何覆盖invokeMethod:
class Stuff {
def invokeMe() { "foo" }
}
Stuff.metaClass.invokeMethod = { String name, args ->
def metaMethod = Stuff.metaClass.getMetaMethod(name, args)
def result
if(metaMethod) result = metaMethod.invoke(delegate,args)
else {
result = "bar"
}
result
}
def stf = new Stuff()
assert "foo" == stf.invokeMe()
assert "bar" == stf.doStuff()
Closure代码的第一步是查找给定名称和参数的MetaMethod。 如果方法可以找到一切都很好,它被委托。 如果不是,则返回一个虚拟值。
作者:小村医
链接:https://www.jianshu.com/p/5d30f1443aa6
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。