图像语义分割与目标检测概述
在计算机视觉领域,不仅有图像分类的任务,还有很多更复杂的任务,如对图像中的目标进行检测和识别,对图像进行实例分割和语义分割等。其中在基于卷积神经网络的深度学习算法出现后,图像的语义分割和目标检测的精度也有了质的提升。
一、常见的语义分割网络
语义分割是对图像在像素级别上进行分类的方法,在一张图像中,属于同一类的像素点都要被预测为相同的类,因此语义分割是从像素级别来理解图像。但是需要正确区分语义分割和实例分割,虽然它们在名称上很相似,但是它们属于不同的计算机视觉任务。例如,一张照片中有多个人,针对语义分割任务,只需将所有人的像素都归为一类即可,但是针对实例分割任务,则需要将不同人的像素归为不同的类。简单来说,实例分割会比语义分割所做的工作更进一步。
随着深度学习在计算机视觉领域的发展,提出了多种基于深度学习方法的图像语义分割网络,如FCN、U-Net、SegNet、DeepLab等。下面对FCN、U-Net、SegNet等网络结构进行一些简单的介绍,详细的内容读者可以阅读相关论文。
1.FCN
FCN语义分割网络是在图像语义分割文章Fully Convolutional Networks forSemantic Segmentation中提出的全卷积网络,该文章是基于深度网络进行图像语义分割的开山之作,而且是全卷积的网络,可以输入任意图像尺寸。其网络进行图像语义分割的示意图如下图所示。FCN的主要思想是:
(1)对于一般的CNN图像分类网络,如VGG和ResNet,在网络的最后是通过全连接层,并经过softmax后进行分类。但这只能标识整个图片的类别,不能标识每个像素点的类别,所以这种全连接方法不适用于图像分割。因此FCN提出把网络最后几个全连接层都换成卷积操作,以获得和输入图像尺寸相同的特征映射,然后通过softmax获得每个像素点的分类信息,即可实现基于像素点分类的图像分割。
(2)端到端像素级语义分割任务,需要输出分类结果尺寸和输入图像尺寸一致,而基于卷积+池化的网络结构,会缩小图片尺寸。因此FCN引入反卷积( deconvolution,和转置卷积的功能一致,也可称为转置卷积)操作,对缩小后的特征映射进行上采样,从而满足像素级的图像分割要求。
(3)为了更有效地利用特征映射的信息,FCN提出一种跨层连接结构,将低层和高层的目标位置信息的特征映射进行融合,即将低层目标位置信息强但语义信息弱的特征映射与高层目标位置信息弱但语义信息强的特征映射进行融合,以此来提升网络对图像进行语义分割的性能。
下图是图像语义分割文章Fully Convolutional Networks for Semantic Segmentation中提出的全卷积网络对图像进行语义分割的网络工作示意图。

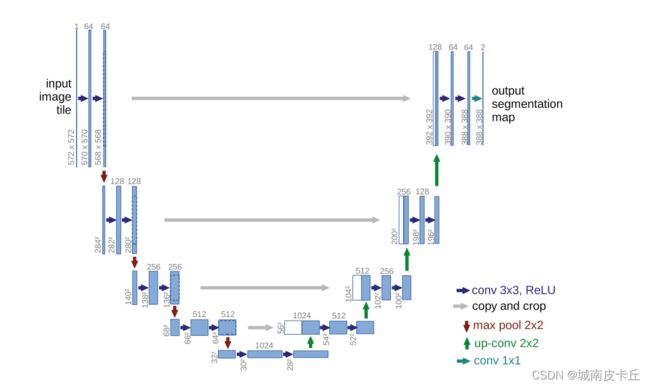
2.U-Net
U-Net是原作者参加ISBI Challenge提出的一种分割网络,能够适应较小的训练集(大约30张图片)。其设计思想是基于FCN网络,在整个网络中仅有卷积层,没有全连接层。因为训练数据较少,故采用大量弹性形变的方式增强数据,以让模型更好地学习形变不变性,这种增强方式对于医学图像来说很重要,并在不同的特征融合方式上,相较于FCN式的逐点相加,U-Net则采用在通道维度上进行拼接融合,其网络进行图像语义分割示意图如下所示:
3. Segment
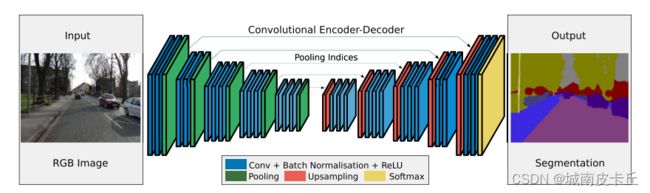
上图所示是图像语义分割文章SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation提出的网络结构工作示意图。网络在编码器处,执行卷积和最大值池化等操作,并且会在进行2x2最大值池化时,存储相应的最大值池化索引。在解码器部分,执行上采样和卷积,并且在上采样期间,会调用相应编码器层的最大值池化索引来帮助上采样操作,最后,每个像素通过softmax分类器进行预测类别。
二、常用的网络目标检测网络
目标检测是很多计算机视觉应用的基础,如实例分割、人体关键点提取、人脸识别等,目标检测任务可以认为是目标分类和定位两个任务的结合。目标检测主要关注特定的物体目标,要求同时获得这一目标的类别信息和位置信息。基于深度学习的目标检测方法主要有两类,一类是两阶段检测模型,如R-CNN、Fast R-CNN、Faster R-CNN等模型,它们将检测问题划分为两个阶段,首先产生候选区域,然后对候选区域分类并对目标位置进行精修;另一类是单阶段检测模型,如YOLO系列、SSD、Retina-Net等模型,它们不需要产生候选区域阶段,直接产生物体的类别概率和位置坐标值,经过单次检测即可直接得到最终的检测结果,因此它们的检测速度更快。
1、R-CNN
R-CNN是将CNN方法引入目标检测领域的开山之作,大大提高了目标检测效果,并且改变了目标检测领域的主要研究思路。R-CNN算法的工作流程如下图所示:

上图所示是图像目标检测文章 Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation的工作示意图,即R-CNN的工作流程主要有4个步骤。
(1)候选区域生成:每张图像会采用Selective Search方法,生成1000~2000个候选区域。
(2)特征提取:针对每个生成的候选区域,归一化为同一尺寸,使用深度卷积网络(CNN)提取候选区域的特征。
(3)类别判断:将CNN特征送入每一类SVM分类器,判别候选区域是否属于该类。
(4)位置精修:使用回归器精细修正候选框位置。
2、 Faster R-CNN
Faster R-CNN是两阶段方法的奠基性工作,提出的RPN ( Region ProposalNetworks)网络取代Selective Search算法使得检测任务可以由神经网络端到端地完成。其具体操作方法是将RPN放在最后一个卷积层之后,RPN直接训练得到候选区域。RPN网络的特点在于通过滑动窗口的方式实现候选框的提取,在特征映射上滑动窗口,每个滑动窗口位置生成9个不同尺度、不同宽高的候选窗口,提取对应9个候选窗口的特征,用于目标分类和边框回归。目标分类只需要区分候选框内特征为前景或者背景,与Fast R-CNN类似,边框回归确定更精确的目标位置。FasterR-CNN算法的工作流程如下图所示:

3、YOLO
YOLO ( You Only Look Once)是经典的单阶段目标检测算法,将目标区域预测和目标类别预测整合于单个神经网络模型中,实现在准确率较高的情况下快速检测与识别目标。YOLO的主要优点是检测速度快、全局处理使得背景错误相对较少、泛化性能好,但是YOLO由于其设计思想的局限,所以会在小目标检测时有些困难。
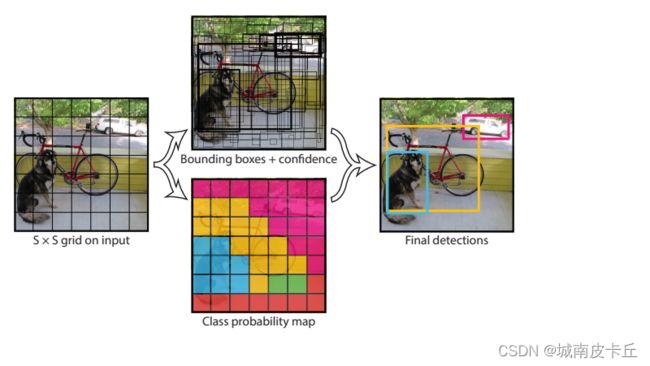
上图所示是图像目标检测文章You Only Look Once: Unified,Real-TimeObject Detection进行目标检测的工作示意图。其工作流程如下:首先将图像划分为S×S个网格,然后在每个网格上通过深度卷积网络给出其物体所属的类别判断(图像使用不同的颜色表示),并在网格基础上生成B个边框( box ),每个边框预测5个回归值,其中前4个值表示边框位置,第五个值表征这个边框含有物体的概率和位置的准确程度。最后经过NMS ( Non-Maximum Suppression,非极大抑制)过滤得到最后的预测框。