嵌入式C语言自我修养:从芯片、编译器到操作系统-习题、笔记
前沿
C语言测试(1):基本概念考查
- 什么是标识符、关键字和预定义标识符? 三者有何区别?
标识符(Identifier):由程序员定义,用来表示变量,包括了变量名、函数名、宏名、结构体名等。
标识符的命名规范:C语言规定,标识符只能由字母(A-Z,a-z)、数字(0-9)、和下划线(_)组成,并且第一个字符必须是字母或下划线,不能是数字。
预定义标识符:C语言中系统预先定义的标识符,如系统类库名、系统常量名、系统函数名
预定义标识符具有见字明义特点,如函数“格式输出”(英语全称加缩写:printf)、“格式输入”(英语全称加缩写:scanf)、sin、isalnum等等
关键字(Keywords):由C语言规定的具有特定意义的字符串,也称为保留字(有点像具有特殊含义的标识符,已经被系统所定义了)。如:int、char、long等。
人为定义的标识符不能与关键字相同,否则报错

- 在C程序编译过程中,什么是语法检查、语义检查? 两者有何区别?
语法检查:编写程序时候,要遵循特定语言的语法,比如C语言的每条语都要以分号";"结束。否则出现编译错误
#include[Error]expected ';' before 'return'
语义检查:语法上没有问题,但是出现了类似:数组越界等问题,这时候编译器可能不会报错
- 什么是表达式? 什么是语句? 什么是代码块?
表达式:用操作符连接起来的式子
1==flag
age>=50&&age<80
!0(0为假,非0为真)
语句:C语言中由一个分号":"隔开的就是一个语句
int a = 10;
printf("haha\n");
10;
'A';
; //空语句,啥都不执行,在语法层面不会报错
代码块:一个"{}“就是一个代码块
凡是在代码块中定义的变量叫做局部变量,函数也是代码块,因为函数也是被”{}"括起来的
凡是在代码中定义的变量都叫局部变量,值在本代码块内有效
局部变量与临时变量:返回局部变量会生成一个临时变量,即没有名字的变量
临时变量必须常引用。 const &b=func() 因为此时b地址绑定为此临时变量,编译器不允许临时变量值改变。此时临时变量生存期为b的生存期
int b=func()。临时变量给b赋值后释放
int main()
{
int flag = 6;
if (6 == flag)
{
int x = 10;//x在本代码块{}内定义,出了本代码块后x无效
}
printf("%d\n", x);//x在其他代码块中不可使用
return 0;
}
提示error

- 什么是数据对象、左值、右值、对象、副作用、未定义行为?
数据对象:用于存储值的数据存储区域统称为数据对象。
赋值表达式语句的目的是把值存储到内存位置上
左值:C语言中,用于标识特定数据对象的名称或表达式
对象指实际的数据存储,而左值用于标识或定位存储位置的标签
早期C语言左值:A.它指定一个对象,所有引用内存中的地址B.它可以在赋值运算符的左侧
后来,C语言标准中新增了const限定符,用const创建的变量不可修改,因此,const标识符满足A,但是不满足B
一方面C语言继续把标识对象的表达式定义为左值,一方面某些左值却不能放在赋值运算符的左侧
对于这个矛盾,C标准新增了一个术语,可修改的左值,用于标识可修改的1。所以,赋值运算符的左值应该是可修改的左值。当前标准建议,使用术语对象定位值
右值:能赋值给可修改的左值,且本身不是左值
例如 int bmw = 200; bmw是可修改的左值,200是右值
右值可以是常量、变量或其他可求值的表达式
当前标准在描述这一概念时使用的是表达式的值,而不是右值
例子
int ex;
int why;
int zee;
const int TWO = 2;
why = 42;
zee = why;
ex = TWO*(why+zee);
ex, why, zee都是可修改的左值( 或对象定位值 ), 它们可用于赋值运算符的左侧和右侧.
TWO是不可改变的左值, 它只能用于赋值运算符的右侧
( 在该例中, TWO被初始化为2,这里的=运算符表示初始化而不是赋值 ).
42 是右值, 它不能引用指定内存位置
(why+zee ) 是右值,该表达式不能不是特定内存位置, 而且也不能给它赋值
它是程序计算的一个临时值,在计算完毕后便会被丢弃
对象:
1.从硬件看:被存储的每个值都占用一定的物理内存,C语言把这样的一块内存称为对象
2.对象可以存储一个或多个值,一个对象可能并未存储实际的值,但它在存储适当的值时一定具有相应的大小
3.对象是指内存中的一段有意义的区域(key:在内存中、一段),如:const char*pc = “hello world”
程序根据声明把相应的字符串字面量存储在内存中,内含这些字符值的整个字符串字面量(hello world)就是一个对象,而且由于字符串字面量中的每个字符都能被单独访问,所有每个字符也是一个对象
4.访问对象可以通过声明变量来完成
5.标识符可以用于访问对象
6.可以用存储期描述对象
副作用:如果一个表达式不仅算出一个值,还修改了环境,就说明这个表达式有副作用(因为它多做了额外的事)。如a++;states = 50;
序列点:是程序执行的点,所有的副作用都在进入下一步之前发生;语句中的分号标记了序列点;当然不一定要分号才表示序列点,完整表达式的结束也是一个序列点
未定义行为:C语言标准未做规定的行为
编译器可能不报错,但这些行为编译器会自行处理,不同的编译器可能出现不同的结果,什么都可能发生,隐患极大
特征:包含多个不确定的副作用的代码的行为总是被认为未定义
例子:
- 同一表达式有多种运算符
在同一个表达式中多种运算符一起计算时,即使我们知道各符号都有自己的优先级或是人为加上括号限制计算顺序,但是我们却不知道编译器会先计算哪一段。计算顺序完全取决于编译器,所以结果不一定按照我们预想中的输出
int i=7;
printf(“%d”, i++*i++);
编译器可以选择使用变量的旧值相乘以后再对两者进行自增运算,没有任何保证自增或自减会在输出变量原值之后对表达式的其他部分进行计算之前立即进行
int a=5,b;
b=++a*–a;
int i = 5;
int j = (++i) + (++i) + (++i);
b的值不能确定
j的值不能确定
#include <stdio.h>
int main(){
int i = 0;
int a[] = {10,20,30};
int r = 1 * a[i++] + 2 * a[i++] + 3 * a[i++];
printf("%d\n", r);
return 0;
}
这段代码也并不是我们想象中的那样按照优先级来计算,编译器选择了他自己的一种套路
- 同一语句中各参数的求值顺序
在同一语句中,有多个表达式,我们不能确定编译器先调用哪一个表达式进行运算,运算之后又会对另一个表达式产生影响,因为他不一定是按照我们想象中自左向右进行调用的
printf("%d,%d\n",++n,power(2,n));
int f(int a, int b);
int i = 5;
f(++i, ++i);
- 通过指针修改const常量的值
编译器对应向常量所在内存赋值这件事的处理是未定义的。即在对常量的对象操作也许并不是我们想象的那样
int main()
{
const int a = 1;
int *b = (int*)&a;
*b = 21;
printf("%d, %d", a, *b);
return 0;
}
- 什么是结合性、左结合、右结合?
操作符的结合性:它是仲裁者,在几个操作符具有相同的优先级时决定先执行哪一个
每个操作符拥有某一级别的优先级,同时也拥有左结合性或右结合性
优先级决定一个不含括号的表达式中操作数之间的“紧密程度”。
如表达式a\*b+c中乘法的优先级高于加法运算符的优先级,所以先执行乘法a*b,而不是加法
但是许多操作符的优先级是相同的,这时操作符的结合性开始发挥作用,在表达式中,如果有
几个优先级相同的操作符,结合性就起仲裁者的作用,由它决定哪个操作符先执行。
int a,b=1,c=2;
a=b=c;
我们发现,这个表达式只有赋值符,这样优秀级就无法帮助我们决定哪个操作先执行,是先执行b=c呢?还是先执行a=b。如果按前者,a=结果为2,如果按后者,a的结果为1。
所有的赋值符都具有右结合性(在表达式中最右边的操作最先执行,然后从右到左依次执行)这样,c先赋值给b,然后b在赋值给a,最终a的值是2
类似的,具有左结合性的操作符(如位运算操作符"&“和”|")(在表达式中最左边的操作最先执行,然后从左到右依次执行)
结合性只用于表达式中出现两个以上相同优先级的操作符的情况,用于消除歧义
事实上,所有优先级相同的操作符,他们的结合性也是相同的,否则结合性依然无法消除歧义
如果在计算表达式的值时需要考虑结合性,那么最好把这个表达式一分为二或使用括号
a=b+c+d
=是右结合,所以先计算(b+c+d),然后再赋值给a
+是左结合,所以先计算(b+c)然后再计算(b+c)+d
C语言中具有右结合性的运算符包括所有单目运算符及赋值运算符(=)和条件运算符,其他都是左结合性
在C语言中,有少数运算符在C语言标准中是有规定表达式求值的顺序的:
1.&& 和 || 规定从左到右求值,并且在能确定整个表达式的值的时候就会停止,也就是常说的短路
2.条件表达式的求值顺序的规定
test?exp1:exp2;
条件测试部分test非零,则表达式exp1被执行,否则表达式exp2被执行,并且保证表exp1和exp2两者中只有一个被求值
3.逗号运算符的求值顺序是从左到右顺序求值,并且整个表达式的值等于最后一个表达式的值,注意","逗号还可以作为函数参数的分隔符、变量定义的分隔符等,这时候表达式的求值顺序是没有规定的
判断表达式计算顺序时,先按优先级高的先计算,优先级低的后计算,当优先级相同时再按结合性或从左至右顺序计算,或从右至左顺序计算
| 优先级 | 运算符 | 名称或含义 | 使用形式 | 结合方向 | 说明 |
|---|---|---|---|---|---|
| 1 | [] | 数组下标 | 数组名[常量表达式] | 左到右 | – |
| () | 圆括号 | (表达式)/函数名(形参比表) | – | ||
| . | 成员选择(对象) | 对象.成员名 | – | ||
| -> | 成员选择(指针) | 对象指针->成员名 | – | ||
| 2 | - | 负号运算符 | -表达式 | 右到左 |
单目运算符 |
| ~ | 按位取反运算符 | ~表达式 | 右到左 |
单目运算符 | |
| ++ | 自增运算符 | ++变量名/变量名++ | 右到左 |
单目运算符 | |
| – | 自减运算符 | –变量名/变量名– | 右到左 |
单目运算符 | |
| * | 取值运算符 | *指针变量 | 右到左 |
单目运算符 | |
| & | 取地址运算符 | &变量名 | 右到左 |
单目运算符 | |
| ! | 逻辑非运算符 | !表达式 | 右到左 |
单目运算符 | |
| (类型) | 强制类型转换 | (数据类型)表达式 | 右到左 |
– | |
| sizeof | 长度运算符 | sizeof(表达式) | 右到左 |
– | |
| 3 | / | 除 | 表达式/表达式 | 左到右 | 双目运算符 |
| * | 乘 | 表达式*表达式 | 左到右 | 双目运算符 | |
| % | 余数(取模) | 整型表达式%整型表达式 | 左到右 | 双目运算符 | |
| 4 | + | 加 | 表达式+表达式 | 左到右 | 双目运算符 |
| - | 减 | 表达式-表达式 | 左到右 | 双目运算符 | |
| 5 | << | 左移 | 变量<<表达式 | 左到右 | 双目运算符 |
| >> | 右移 | 变量>>表达式 | 左到右 | 双目运算符 | |
| 6 | > | 大于 | 表达式>表达式 | 左到右 | 双目运算符 |
| >= | 大于等于 | 表达式>=表达式 | |||
| < | 小于 | 表达式<表达式 | |||
| <= | 小于等于 | 表达式<=表达式 | |||
| 7 | == | 等于 | 表达式=表达式 | ||
| != | 不等于 | 表达式!=表达式 | |||
| 8 | & | 按位与 | 表达式&表达式 | ||
| 9 | ^ | 按位异或 | 表达式^表达式 | ||
| 10 | | | 按位或 | 表达式|表达式 | ||
| 11 | && | 逻辑与 | 表达式&&表达式 | ||
| 12 | || | 逻辑或 | 表达式||表达式 | ||
| 13 | ?: | 条件运算符 | 表达式1?表达式2:表达式3 | 右到左 |
三目运算符 |
| 14 | = | 赋值运算符 | 变量=表达式 | 右到左 |
– |
| /= | 除后赋值 | 变量/=表达式 | 右到左 |
– | |
| *= | 乘后赋值 | 变量*=表达式 | 右到左 |
– | |
| %= | 取模后赋值 | 变量%=表达式 | 右到左 |
– | |
| += | 加后赋值 | 变量+=表达式 | 右到左 |
– | |
| -= | 减后赋值 | 变量-=表达式 | 右到左 |
– | |
| <<= | 左移后赋值 | 变量<<=表达式 | 右到左 |
– | |
| >>= | 右移后赋值 | 变量>>=表达式 | 右到左 |
– | |
| &= | 按位与后赋值 | 变量&=表达式 | 右到左 |
– | |
| ^= | 按位异或后赋值 | 变量^=表达式 | 右到左 |
– | |
| |= | 按位或后赋值 | 变量|=表达式 | 右到左 |
– | |
| 15 | , | 逗号运算符 | 表达式,表达式,… | 左到右 | – |
说明:运算符一共分为15级,1级优先级最高,15级优先级最低
同一优先级运算符,运算顺序由结合方向所决定。结合性2 13 14 是从右自左,其他都是从左至右
简单记忆:!>算术运算符>关系原算法>&&>||>赋值运算符
口诀表
括号成员第一; //括号运算符 成员运算符. ->
全体单目第二; //所有的单目运算符比如++、 --、 +(正)、 -(负) 、指针运算*、&
乘除余三,加减四; //这个"余"是指取余运算即%
移位五,关系六; //移位运算符:<< >> ,关系:> < >= <= 等
等于(与)不等排第七; //即== 和!=
位与异或和位或; “三分天下"八九十; //这几个都是位运算: 位与(&)异或(^)位或(|)
逻辑或跟与; //逻辑运算符:|| 和 &&
十二和十一; //注意顺序:优先级(||) 底于 优先级(&&)
条件高于赋值, //三目运算符优先级排到13 位只比赋值运算符和”,"高
逗号运算级最低! //逗号运算符优先级最低
C语言测试(2):一个sizeof(int)引发的思考
sizeof是函数,是关键字,还是预定义标识符?
- sizeof是关键字
- A),sizeof(int); B),sizeof(i); C),sizeof int; D),sizeof i;
- A、B都是4. 用Visual C++6.0或者其他编译器来试下: C报错syntax error : ‘type’ 但是D输出结果也是4.
- sizeof后面没有括号也是可以的,但是函数后面是不能没有括号的,所以sizeof绝不是函数。
在32位和64位的Windows 7环境下运行,结果分别是多少? - 都是4
在32位和64位的X86 CPU平台下运行,结果分别是多少?
在8位、16位、32位的单片机环境下运行,结果分别是多少?
在32位ARM和64位ARM下运行,结果分别是多少?
分别在VC++6.0、Turbo C、Keil、32位/64位GCC编译器下编译、运行,结果一样吗?
使用32位GCC编译器编译生成32位可执行文件,运行在64位环境下,结果如何?
使用64位GCC编译器编译生成64位可执行文件,运行在32位环境下,结果如何?
C语言测试 (3):自增运算符
使用不同的编译器编译、运行下面的程序代码,结果分别是多少? 结果是否一定相同? 为什么?
#include <stdio.h>
int main(void)
{
int i=1;
int j=2;
printf("%d\n",i++*i++);
printf("%d\n",i+++j);
return 0;
}
C语言测试 (4):程序代码分析
#include <stdio.h>
{
int main(void)
int i;
int a[0];
printf("hello world!\n");
int j;
for(int k=0; k<10; k++);
return 0;
}
阅读上面的程序代码,然后进行如下操作,观察运行结果并分析。
分别使用C-Free、GCC、VC++6.0、Visual Studio编译、运行代码,运行结果一定相同吗? 会出现什么问题? 为什么?
在VC++6.0环境下,新建console工程,将上面的程序代码分别保存为.cpp和.c文件并编译、运行,运行结果会如何? 为什么?
C语言测试 (5):程序运行内存分析
在32位Linux下,编写一个数据复制函数,在实际运行中会出现什么问题?
int *data_copy(int *p)
{
int buffer[8192*1024];
memcpy(buffer,p,8192*1024);
return buffer;
}
C语言测试 (6):程序改错
在嵌入式ARM裸机平台上,实现一个MP3播放器,要求实现如下功能: 当不同的控制按键被按下时,播放器可以播放、暂停、播放上一首歌曲、播放下一首歌曲。为了实现这些功能,我们设计了一个按键中断处理函数:当有按键被按下时,会产生一个中断,我们在按键中断处理函数中读取按键的值,并根据按键的值执行不同的操作。下面设计的按键中断处理函数中有很多不合理之处,请找出6处以上。
int keyboard_isr(int irq_num)
{
char *buf =(char *)malloc(512);
int key_value = 0,
key_value = keyboard_scan();
if(key_value == 1)
{
mp3_decode(buf,"xx.mp3");
sleep(10);
mp3_play(buf); //播放
}
else if(key_value == 2)
mp3_pause(buf); //暂停
else if(key_value == 3)
mp3_next(buf); //播放下一首歌曲
else if(key_value == 4)
mp3_prev(buf);
else
{
printf("UND key !");return -1;
return -1;
}
return 0;
}
C语言测试 (7):linux内核代码分析
在Linux内核源码中存在着各种各样、稀奇古怪的C语言语法,试分析下面代码中宏定义、零长度数组、位运算、结构体变量初始化的作用。

C语言测试 (8):linux内核代码赏析
在Linux内核源码中,我们经常可以看到下面的代码风格,试分析它们的意义。

第1章 常用软件工具
1.1代码编辑 Vim
1.1.1安装Vim
sudo apt-get install vim
如果是fedora或mac
yum install vim
brew install vim
查看vim版本
vim-v
1.1.2Vim常用命令
vim的工作模式
- 普通模式:打开文件时候的默认模式,在其他模式下,按下esc键均可回到此模式
- 插入模式:普通模式下按下i/o/a键进入插入模式,可以进行文本编辑
- 命令行模式:普通模式下输入冒号(:)会进入命令行模式,此模式下,输入:set number 或 set nu可显示行号
- 可视化模式:普通模式下输入v会进入命令行模式,此模式下,移动光标可以选中一块文本,然后进行复制、剪切、删除、粘贴等文本操作
- 替换模式:普通模式下,通过光标选中一个字符,然后按下r键,在输入一个字符,这时新输入的字符替换了原本光标选中的字符(省去了先删除再插入的操作)
vim的不同粒度光标移动
- 1.单个字符移动
普通模式下
| k | 光标向上移动一个字符 |
|---|---|
| j | 光标向下移动一个字符 |
| h | 光标向左移动一个字符 |
| l | 光标向右移动一个字符 |
- 2.单词移动
| w | 光标移动到下一个单词开头 |
|---|---|
| b | 移动到上一个单词开头 |
| e | 下一个单词词尾 |
| E | 上一个单词词尾(忽略标点符号) |
| ge | 上一个单词词尾 |
| 2w | 指定移动光标2次移动到下下个单词开头 |
- 3.行移动
| $ | 将光标移动到当前行的行位 |
|---|---|
| O | 移动到当前行的行首 |
| ^ | 移动到行前的第一个非空字符 |
| 2| | 移动到当前行的第2列 |
| fx | 移动到当前行的第1个字符x上 |
| 3fx | 移动到当前行的第3个字符x上 |
| % | 符号间的移动,在()、[]、{}之间跳跃 |
- 4.屏幕移动
| nG | 光标跳转到指定的第n行 |
|---|---|
| gg/G | 光标跳转到文件的开头/末尾 |
| L | 光标移动到当前屏幕的末尾 |
| M | 光标移动到当前屏幕中间 |
| Ctrl+g | 光标查看当前的位置状态 |
| Ctrl+u/d | 光标向前/后半屏滚动 |
| Ctrl+f/b | 光标向前/后全屏滚动 |
- 5.文本的基本操作
| i/a | 在当前光标的前或后面插入字符 |
|---|---|
| I/A | 在当前光标所在行的行首或行尾插入字符 |
| o | 在当前光标所在行的下一行插入字符 |
| x | 删除当前光标所在处的字符 |
| X | 删除当前光标左边的字符 |
| dw | 删除一个单词 |
| dd | 删除所在行 |
| 2dd | 删除当前行和下一行 |
| yw | 复制一个单词 |
| yy | 复制当前行 |
| p | 粘贴,注意是粘贴到光标所在处的下一行 |
| J | 删除一个分行符,将当前行与下一行合并 |
- 6.文本的查找与替换
| /string | 在Vim的普通模式下输入/string即可正向往下查找字符串string |
|---|---|
| ?string | 反向查找字符串string |
| :set hls | 高亮显示光标处的单词,敲击n浏览下一个 |
| s/old/new | 将当前行的第一个字符串old替换为new |
| s/old/new/g | 将当前行的所有字符串old替换为new |
| %s/old/new/g | 将文本中所有字符串old替换为new |
| %s/^old/new/g | 将文本中所有以old开头的字符串替换为new |
- 7.文本的保存与退出
| u | 撤销上一步的操作 |
|---|---|
| q | 若文件没有修改,则直接退出 |
| q! | 若文件已经修改,则放弃修改,退出 |
| wq | 若文件已经修改,则保存修改,退出 |
| e! | 若文件已经修改,则放弃修改,恢复文件最初打开时的状态 |
| w! sudo tee% | 在Sheel的普通用户模式下保存root读写权限的文件 |
在ubuntu中,在Sheel的普通用户模式下一般只能修改/home/$(USER)/目录下的文件。若想使用Vim修改其他目录下的文件,则要使用sudo vim xx.c命令,或先切换到root用户,再使用Vim打开文件即可。若普通用户模式下忘记使用sudo,直接使用Vim修改了文件而无法保存退出时,可以使用下面命令来保存
w !sudo tee %
%表示当前的文件名,tee命令用来把缓冲区的数据保存到当前文件
保存root读写权限的文件

1.1.3Vim配置文件:vimrc
> Vim支持功能扩展和定制
显示行号:set nu命令
也可以将这个命令写入Vim配置文件,好处是使用Vim打开文件时,
不用每次都输入显示行号的命令,可以使用vim--version命令来查看Vim配置文件的路径
vim -version //查看vim版本
vim --version //查看vim扩展信息

system vimrc file: "$VIM/vimrc"
user vimrc file: "$HOME/.vimrc"
2nd user vimrc file: "~/.vim/vimrc"
user exrc file: "$HOME/.exrc"
defaults file: "$VIMRUNTIME/defaults.vim"
fall-back for $VIM: "/usr/local/share/vim"
f-b for $VIMRUNTIME: "/usr/local/share/vim/vim82"
Compilation: gcc -c -I. -Iproto -DHAVE_CONFIG_H -g -O2 -U_FORTIFY_SOURCE -D_FORTIFY_SOURCE=1
Linking:
gcc -L/usr/local/lib -Wl,--as-needed -o vim -lSM -lICE -lm -ltinfo -ldl
比如,在根目录下新建一个名为new的文本文件
vim new

Vim配置文件包含系统级配置文件和用户级配置文件
用户级配置文件:一般位于$HOME/.vimrc和~/.vim/vimrc这两个路径下
但是我的ubuntu下没找到,只找到了下图两个文档,打开后是乱码的

.vimrc要自己新建
vim ~/.vimrc
结果Found a swap file by the name "~/.vimrc.swp" 警告,也是就.vimrc.swp文件和我新建的有冲突

.swp 文件是使用vim编辑文本过程中产生的,如果直接关闭了terminal界面,没有通过(:wq)保存,就会包保留到文件夹中,这是可以删掉的
rm -f .vimrc.swp
然后在新建
vim ~/.vimrc
打开之后,按下i进入插入模式,然后输入set number,然后按下Esc进入普通模式,然后输入:wq保存退出

任意新建一个文件
vim new

系统级配置文件对所有用户都有效,一般位于/etc/vim路径下

当用户在Shell下输入vim命令打开一个文件时,Vim首先会设置内部变量SHELL和term,处理用户输入的命令行参数
- 打开的文件名和参数选项
- 然后加载系统级和用户级配置文件
- 然后加载插件并执行GUI的初始化工作
- 最后打开所有窗口并执行用户指定的启动时的命令
1.1.4Vim的按键映射
Vim可以通过map命令来实现像Windows下的Ctrl+c、Ctrl+v、Ctrl+x(剪切)的组合键
表1-1 不同工作模式下的按键映射命令
| 命令 | Normal | Visual | Operator Pending | Insert | Command Line |
|---|---|---|---|---|---|
| :map | Y | Y | Y | ||
| :map | Y | ||||
| :vmap | Y | ||||
| :omap | Y | ||||
| :map! | Y | Y | |||
| :imap | Y | ||||
| :cmap | Y |
常用的IDE支持自动补全(例如,写代码时遇到小括号、中括号、大括号等字符会自动补全,并将光标移动到括号中)
vim通过按键映射也可以实现自动补全
在根目录下
vim ~/.vimrc
添加
inoremap [ []<Esc>i
inoremap ] []<Esc>i
inoremap ( ()<Esc>i
inoremap ) ()<Esc>i
inoremap " ""<Esc>i
inoremap { {<CR>}<Esc>0
inoremap } {<CR>}<Esc>0
然后输入这些括号时候,只要打一部分就可以自动补全了
Vim在Normal模式下可以通过h、j、k、l来移动光标,但在插入模式下,这些按键不能作为方向键时候(可以用键盘上的方向键)
可以通过组合键映射,在插入模式下使用组合键Ctrl+h、Ctrl+j、Ctrl+k、Ctrl+l来移动光标
inoremap <C-L> <Esc>la
inoremap <C-H> <Esc>ha
inoremap <C-J> <Esc>lja
inoremap <C-K> <Esc>ka
在使用printf()函数打印字符串时,当我们在一对小括号和双引号内输入完字符串,想移动光标到该语句的行尾时,需要多次移动光标到该语句行尾,通过按键映射可以定义一组更加快捷的光标移动命令
imap ,, <ESC>la
imap .. <ESC>2la
在Vim插入模式下,快速敲击两次逗号,就可以快速跳出括号或引号
如果想快速移动两次光标,出入模式下,快速敲击两次句号就行
除了通过vimrc配置文件来定制功能外,Vim还支持通过插件来扩展功能
在Vim官网有很多xx.vim格式的插件供用户下载使用
如果你想通过插件来扩展vim的功能,方法是:
- 1.在当前用户下创建一个~/.vim/piugin目录
- 2.将这些xx.vim格式的插件复制到该目录
- 3.在$HOME/.virmrc配置文件中对这些插件进行配置,即可直接使用
1.2程序编译工具:make
1.2.1 使用IDE编译C程序
IDE(integrated development environment,集成开发环境)提供了程序的编辑、编译、链接、运行、调试、项目管理等功能
IDE将程序的编译、链接、运行等底层过程进行封装,留给用户的只有一个用户交互按钮:Run
点击Run后,IDE会自动调用相关的预处理器、编译器、汇编器、链接器等工具生成可执行文件,并将可执行文件加载到内存运行,通过打印窗口让用户直观地看到运行的结果
1.2.2 使用gcc编译C源程序
在Linux下,常在命令行下使用gcc或arm-linux-gcc交叉编译器来编译程序
他们的安装方式为:
sudo apt-get install gcc #自己的笔记本电脑只安装这个就行,arm的适合arm的CPU设备
sudo apt-get install gcc-arm-linux-gnueabi
安装完毕后可以查看编译器版本
gcc -v

gcc安装完成后,我们可以开始编译程序了
首先新建一个C程序
//main.c
#include
然后使用gcc命令来编译main.c源程序文件,将生成的可执行文件命名为hello,之后运行该文件
gcc -o hello main.c
./hello

gcc在编译main.c源文件时,会依次调用预处理、编译器、汇编器、链接器,最后生成可执行的二进制文件hello。根据需要,我们也可以通过gcc编译参数来控制程序的编译过程
-E:只对C源程序进行预处理,不变异
-S:只编译到汇编文件,不再汇编
-c:只编译生成目标文件,不进行链接
-o:指定输出的可执行文件名
-g:生成带有调试信息的debug文件
-O2:代码编译优化等级,一般选2
-W:在编译器中开启警告(warning)信息
-I:大写的I(is的首字母),在编译时指定头文件的路径
-l:小写的l(like的首字母),指定程序使用的函数库
-L:大写的L(like的首字母),指定函数库的路径
通过上面这些参数,我们可以根据实际需要来控制程序的编译过程,如上面的main.c源文件,如果我们只对其做编译操作,不链接
gcc -c main.c
通过下面命令,我们可以对C源文件main.c只做预处理操作,不再编译,并将预处理的结果重定向到main.i文件中
gcc -E main.c > main.i
打开main.i可以看到C程序经过预处理后发生了什么变化
1.2.3 使用make编译程序
当C源程序过多时候(Linux内核有3万多个源文件),如果还用gcc编译程序就非常不方便
gcc -o vmlinux main.c usb.c device.c hub.c driver.c ...
可以使用make
make是一个编译工具,make在编译程序时需要依赖Makefile的文件(生成一个可执行文件所依赖的所有C源文件都由Makefile文件指定)
在Makefile文件中,我们通过定义一个个规则,来描述各个要生成的目标文件所依赖的源文件及编译命令,最后链接器将这些文件组装在一起,生成可执行文件
当我们使用make编译一个工程时,make首先会解析Makefile,根据Makefile文件中定义的规则和依赖关系,分析出生成可执行文件和各个目标文件所依赖的源文件,并根据这些依赖关系构建出一个依赖关系树。然后根据这个依赖关系和Makefile定义的规则一步一步依次生成这些目标文件,最后将这些目标文件链接在一起,生成最终的可执行文件。
实例
新建两个文件
//main.c
#include //add.c
int add(int a,int b)
{
return a+b;
}
如果使用gcc编译:
gcc -o hello main.c add.c

如果使用make工具编译:
先写一个Makefile:
Makefile的构成单元是规则,一个规则由这些构成:目标、目标依赖和命令
目标:目标依赖
命令
- 目标:要生成的可执行文件或各个源文件对应的目标文件
- 一个目标后面一般要紧跟生成这个目标所依赖的源文件,以及生成这个目标的命令
- 命令可以是编译命令,可以是链接命令、可以是Shell命令,命令必须以Tab键开头
- 一个Makefile里可以有多个规则、多个目标,一般会选择第一个目标作为默认目标
Makefile文件中使用.PHONY声明的目标是一个伪目标,伪目标不是一个真正的文件名,可以看作一个标签。
伪目标比较特殊,一般无依赖,主要用于无条件执行一些命令,如清理编译结果和中间临时文件
一个规则可以像伪目标那样无目标依赖,无条件地执行一些命令操作,也可以没有命令,只表示单纯的依赖关系,如下面Makefile文件中的all伪目标
将Makefile文件放置在main.c和add.c的同一目录下,然后进入该目录,在命令行环境下输入make命令就可以直接编译项目
可以使用make clean命令清除程序的编译结果和生成的临时中间文件
为编译main.c和add.c写的Makefile文件
.PHONY:all clean
all:hello
hello:main.o add.o
gcc -o hello main.o add.o
main.o:main.c
gcc -c main.c
add.o:add.c
gcc -c add.c
.PHONY:clean
clean:
rm -rf main.o add.o
make

注意执行make后,系统会优先找Makefile、其次找makefile、GNUmakefile,三个都找不到会报错
1.2.3.1 Makefile详解
此处的教程仅仅是在main函数中调用fun1和fun2函数,而fun1和fun2独立写在fun1.c和fun2.c里,代码如下
//main.c
#include//fun1.c
#include//fun2.c
#include1.2.3.2 Makefile详解第一版
如果使用gcc对上述代码进行编译(下面指定编译后的可执行文件命令为app)
gcc main.c fun1.c fun2.c -o app

Makefile其实是按规则一条条执行的,我们完全可以把上面的这条命令写成Makefile的一个规则,目标是app,此写法依赖的是main.c fun1.c func2.c,
Makefile的规则:
目标:目标依赖
命令
最终的Makefile如下
app:main.c fun1.c fun2.c
gcc main.c fun1.c fun2.c -o app
但这个版本的Makefile有两大缺点
1.一旦代码过多(比如有fun1.c … func10000.c),仅用一行规则完全不够,即使能用一行,也可能需要写得很长
2.任何文件只要稍微做了修改,就需要整个项目完整的重新编译
使用make编译,然后运行可执行文件app
make
./app

1.2.3.3 Makefile详解第二版
第二版中,我们要避免改动任何代码就要重新编译整个项目的缺点,我们将主规则的各个依赖替换成各自的中间文件
main.c–>main.o,fun1.c–>fun1.o,fun2.c–>fun2.o,再对每个中间文件的生成各自写条规则,比如,对于main.o,规则为:
main.o :main.c
gcc -c main.c -o main.o
这样做的好处是,当有一个文件发生改动时,只需要重新编译此文件即可,而无需重新编译整个项目
完整的Makefile文件如下
app:main.o fun1.o fun2.o
gcc main.o fun1.o fun2.o -o app
main.o: main.c
gcc -c main.c -o main.o
fun1.o:fun1.c
gcc -c fun1.c -o fun1.o
fun2.o:fun2.c
gcc -c fun2.c -o fun2.o
第二版Makefile也有一些缺点
1.存在许多重复内容,可考虑用变量替换
2.后面的三条规则非常类似,可以用一条模式规则替换

1.2.3.4 Makefile详解第三版
第三版Makefile中,我们将使用变量及模式规则使Makefile更加简洁
使用的三个变量如下
obj = main.o fun1.o fun2.o
target =app
CC=gcc
使用的模式规则为
%.o:%.c
$(CC) -c $< -o $@
这条规则表示:所有的.o文件都由对于的.c文件生成
在规则里,我们看到两个自动变量$<和$@,自动变量有很多,常用的三个是
$<:第一个依赖文件
$@:目标
$^:所有不重复的依赖文件,以空格分开
完整的Makefile文件如下
obj = main.o fun1.o fun2.o
target = app
CC = gcc
$(target): $(obj)
$(CC) $(obj) -o $(target)
%.o: %.c
$(CC) -c $< -o $@
第三版的Makefile依然存在一些缺陷:
1.obj对应的文件需要一个个输入,工作量大
2.文件数目一旦很多的话,obj将很长
3.每增加/删除一个文件都需要修改Makefile

PS:注意在makefile中,命令行要以tab键开头,否则会报错!
Makefile:6: *** missing separator. Stop.

1.2.3.5 Makefile详解第四版
在第四版Makefile中,我们将使用wildcard和patsubst这两个函数
wildcard:
扩展通配符,搜索指定文件。这里我们使用src=$(wildcard./*.c),代表在当前目录下搜索所有.c文件,并赋值给src
函数执行结束后,src的值为:main.c fun1.c fun2.c
patsubst:
替换通配符,按指定规则做替换
这里,我们使用obj=$(patsubst %.c, %.o,$(src))
代表将src里的每个文件都由.c替换为.o
函数执行结束后,obj的值为main.o fun1.o fun2.o,其实和第三版Makefile的obj值一样,只不过这里它更加智能、灵活
除了使用patsubst函数外,我们也可以使用模式规则达到同样的效果,如:
obj = $(src:%.c=%.o)
也是代表将src里面的每个文件都由.c替换成.o
几乎每个Makefile里都会有一个伪目标clean,这样我们通过执行make clean命令就可以将中间文件(如.o文件)及目标文件全部删除,留下干净的空间
.PHONY:clean
clean:
rm -rf $(obj) $(target)
.PHONY代表声明的clean是一个伪目标,这样每次执行make clean时,下面的规则都会被执行
完整的Makefile文件如下
src = $(wildcard ./*.c)
obj = $(patsubst %.c,%.o,$(src))
#obj=$(src:%.c=%.o)
target = app
CC=gcc
$(target):$(obj)
$(CC) $(obj) -o $(target)
%.o:%.c
$(CC) -c $< -o $@
.PHONY:clean
clean:
rm -rf $(obj) $(target)

注意

1.2.3.6 Makefile详解
参考来源四步教你从零开始写Makefile
1.3代码管理工具:Git
使用版本控制系统记录每次对代码的修改
1.3.1版本控制系统
版本控制系统跟踪并记录每一个文件的变化:
谁创建了它
谁修改了它
谁删除了它
何时?修改了什么?
Git是分布式版本控制系统
1.3.2Git的安装与配置
sudo apt-get install git
使用Git之前要进行一些配置(提交人是谁?提交人怎么联系?)
git config --global user.email 762743502@qq.com
git config --global user.name Jiasheng
Git可以通过不同的参数,灵活设置这些配置的作用范围
–global:配置~/.gitconfig文件,对当前用户下的所有仓库有效
–system:配置/etc/gitconfig文件,对当前系统下的所有仓库有效
无参数:配置.git/config文件,只对当前仓库有效
1.3.3Git常用命令
配置好Git后,我们开始使用Git来管理软件代码
常用Git命令
- git init:创建一个本地版本仓库
- git add main.c:将main.c文件的修改变化保存到仓库的暂存区
- git commit:将保存到暂存区的修改提交到本地仓库
- git log:查看提交历史
- git show commit_id:根据提交的ID查看某一个提交的详细信息

Git重要的概念:工作区(working directory)、暂存区(staging area)和版本库(repository)
主要从两个角度:从库里取出之前的代码、将修改后的代码放进库里
版本库中保存的是我们提交的多个版本的代码快照
如果想查看某个版本的代码,可以通过git checkout命令将版本库里这个版本的代码拉取出来,释放到工作区
在工作区可浏览某一个版本的代码、修改代码
如果想把修改保存到版本库中,可以先将修改保存到暂存区,接着修改,再保存到暂存区,直到真正完成修改,再统一将暂存区里所有的修改提交到版本库中,如上图所示
使用演示
新建一个目录learngit,在learngit目录下新建一个C源文件main.c
mkdir ~/learngit
cd ~/learngit
touch main.c
然后在learngit目录下新建一个Git仓库并将main.c提交到仓库中
git init #创建一个仓库
git status #查看工作区状态
git add main.c #将工作区的修改main.c添加到暂存区
git status #查看工作区状态
git commit -m "init repo and add main" #将暂存区的修改提交到仓库


每执行一步,我们都可以使用git status命令来查看文件的状态,你会发现,每一步操作后,main.c文件的状态都会跟着改变
从untracked到changes to be commited,工作区的状态也会跟着改变。提交成功后,可以使用git log 来查看提交信息,包含提交的ID、提交作者、提交时间、提交说明等

如果提交后又修改了main.c文件,想把这个修改再次提交到仓库
git add main.c
git commit -m "modify main.c again :add add function"
这两个命令将main.c的第二次修改提交到本地仓库,然后使用git log 或git show 命令来查看我们新的提交信息和修改变化
git show后面的一串数字字符串是每一次提交commit ID

如果你想让你的提交不影响整个项目(同一个项目有多个开发者),为了不影响他人使用,可以创建一个自己的分支my_branch切换到my_branch上,然后在这个分支上修改代码。修改后提交到my_branch分支
这样操作,所有修改都提交到my_branch分支,不会影响master主分支上的代码,不会影响他人
git branch my_branch #创建一个新分支my_branch
git checkout my_branch #切换到新分支my_branch
git commit -m "on my_branch:modify main.c" #将修改提交到my_branch
git log #查看新的提交信息
git checkout master #切换到master分支,在该分支上看不到新的提交信息
git log
git merge my_branch #将my_branch分支上的修改合并到master分支
got log

以上的常用命令可以让我们使用Git进行代码的修改、提交
Git还有很多其他命令,如分支管理、分支的合并和衍合、标签管理等
实际使用场景比上面的复杂:如远程仓库的代码拉取和提交、合并提交时的代码冲突等
第4章 程序的编译、链接和运行
安装arm-linux-gcc交叉编译器
sudo apt-get install gcc-arm-linux-gnueabi gcc #ubuntu
yum install gcc-arm-linux-gnueabi gcc #fedora
4.1 从源程序到二进制文件
//sub.c
int sub(int a ,int b)
{
return a+b;
}
//add.c
int add(int a ,int b)
{
return a+b;
}
//calculate.h
int add(int a,int b);
int sub(int a,int b);
//main.c
#include
我们在文件夹中依次创建了3个C程序源文件:main.c、add.c和sub.c。在main.c中定义了项目的入口函数main(),在main()函数中我们调用了add()和sub()函数完成加减操作。add()和sub()函数分别在add()和sub()中定义,并包含在头文件calculate.h中(在main.c调用add()和sub()之前,要先把calculate.h头文件包括进来,完成函数原型声明,编译器在编译程序时会根据这些函数声明对我们的源程序进行语法检查:检查实参类型、返回结果类型和函数声明的类型是否匹配)
以上是一个C程序项目中对多文件的组织原则:可以将add.c和sub.c看做一个模块,定义了很多API函数供其他模块调用,并将这些API的声明封装在calculate.h头文件中。其他模块若想调用add.c或sub.c中的函数,则要先#include"calculate.h"这个头文件
若想让上面这个程序在ARM平台运行,我们需要使用ARM交叉编译器将C源程序编译成ARM格式的二进制可执行文件
arm-linux-gnueabi-gcc -o a.out main.c add.c sub.c
./a.out
因为我的电脑是X86架构,无法执行ARM代码,所以执行./a.out 会报错
bash: ./a.out: cannot execute binary file: Exec format error

ARM交叉编译器成功将C源程序翻译为可执行文件,将生成的二进制文件复制到ARM平台就可以直接运行了
查看a.out的内容:
readelf -h a.out

查看a.out的section header:
readelf -S a.out

readelf-h命令主要用来获取可执行文件的头部信息
包括:可执行文件运行的平台、软件版本、程序入口地址,以及program headers、section header等信息
从文件的头部信息,我们可以知道a.out可执行文件一共有多少个section headers
| ELF header |
|---|
| program header table |
| .init |
| .text |
| .rodata |
| .data |
| .bss |
| .systab |
| .debug |
| .line |
| .strtab |
| section header table |
图4-1 可执行文件的内部结构
section headers用于描述可执行文件的section信息
一个可执行文件通常由不同的段(section)构成
代码段、数据段、BBS段、只读数据段
每个section用一个section header来描述,包括:段名、段的类型、段的起始地址和段的大小
一个可执行文件中的每一个section都有一个section header,将这些section headers集中放在一起,就是一个section header table(节头表),可使用readelf -S查看
通过section header table信息,可以看到一个可执行文件的基本构成
一个可执行文件由一系列section组成,section header table自身也是以一个section的形式存储在可执行文件中
section header里各个section header用来描述各个section的名称、类型、起始地址、大小等信息
可执行文件的头文件EFL header 用来描述文件类型、要运行的处理器平台、入口地址等(程序运行时,加载器会根据此头文件来获取可执行文件的一些信息)
一个可执行文件,我们熟悉的section有:
.text、.data、.bss,是我们常说的代码段、数据段、BSS段
C程序中定义的函数、变量、未初始化的全局变量经编译后会放置在不同的段中:
函数翻译成二进制指令放在代码段中
初始化的全局变量和静态变量放在数据段中
BSS段比较特殊:一般,未初始化的全局变量和静态变量会放置在BSS段中,但是因为他们未初始化,默认值全是0,其实没有必要单独开辟空间存储,为了节省空间,可执行文件的BSS段是不占用空间的。但是BSS段的大小、起始地址和各个变量的地址信息会分别保存在节头表section header table和符号表.symtab里,当程序运行时,加载器会根据这些信息在内存中紧挨着数据段的后面为BSS段开辟一片存储空间,为各个变量分配存储单元
从可执行文件的构成可以大概看出编译的流程
如图4-2:
编译是将C程序定义的函数、变量挑挑拣拣、加以分类,分别放置在可执行文件的代码段、数据段和BSS段中
程序中定义的一些字符串、printf函数打印的字符串常量则放置在只读数据段.rodata中
若程序在编译时设置为debug模式,则可执行文件还会有一个专门的.debug section ,用来保存可执行文件中每一条二进制指令对应的源码位置信息,根据这个信息,GDB调试器就可以支持源码级的单步调试,否则单步执行的都是二进制指令,可读性不高,不方便调试
最后环节:编译器还会在可执行文件中添加一些其他的section,如.init section,这些代码来自C语言运行库的一些汇编代码,用来初始化C程序运行所依赖的环境,如内存堆栈的初始化等

图4-2 从C程序到可执行文件
程序的编译流程
预处理、编译、汇编、链接
每个阶段需要调用不同的工具去完成,上一阶段的输出作为下一阶段的输入
在一个多文件的C项目中,编译器是以C源文件为单位进行编译的。在编译的不同阶段,编译程序(如gcc、arm-linux-gcc)会调用不同的工具来完成不同阶段的任务
在编译器安装路径的bin目录下,可以看到各种各样的编译工具,gcc在程序编译过程中会调用他们
常见的工具
预处理器:将源文件main.c经过预处理变为main.i
编译器:将预处理后的main.i编译为汇编文件main.s
汇编器:将汇编文件main.s编译为目标文件main.o
链接器:将各个目标文件main.o、sub.o、add.o链接成可执行文件a.out

最后生成的可执行文件a.out其实也是目标文件(object file),唯一不同的是,a.out是一种可执行的目标文件
目标文件:
可重定位的目标文件(relocatable files)
可执行的目标文件(executable files)
可被共享的目标文件(shared object files)
汇编器生成的目标文件是可重定位的目标文件,是不可执行的,需要链接器经过链接、重定位之后才能运行
可被共享的目标文件一般以共享库的形式存在,在程序运行时需要动态加载到内存,跟应用程序一起运行
4.2 预处理过程
为方便编程,编译器一般为程序员提供一些预处理命令,使用#标识,常见的预处理命令如下
头文件包含(实现模块化编程):#include
定义一个宏(定义一个常量,提高代码可读性):#define
条件编译(让代码兼容不同的处理器架构和平台,最大限度得复用公用代码):#if、#else、#endif
编译控制(设定编译器状态,指示编译器完成一些特定动作):#paragma
#paragma pack([n]):指示结构体和联合成员的对齐方式
#paragma message(“string”):在编译信息输出窗口打印自己的文本信息
#paragma warning:有选择地改变编译器的警告信息行为
#paragma once:在头文件中添加这条指令,可以放置头文件多次编译
预处理过程是在编译源程序之前,先处理源文件中的各种预处理命令。编译器不认识预处理指令!在编译之前必须把这些预处理命令处理掉,否则编译器报错
预处理器的操作:
头文件展开:将#include包含的头文件内容展开到当前位置
宏展开:展开所有的宏定义,并删除#define
条件编译:根据宏定义条件,选择要参与编译的分支代码,其余的分支丢弃
删除注释
添加行号和文件名标识:编译过程中根据需要可以显示这些信息
保留#pragma命令:该命令会在程序编译时指示编译器执行一些特定的行为
一个源程序在预处理前后有什么变化?
下面是一个测试程序,分别使用预处理命令去定义一些宏和条件编译
//calculate.h
int add(int,int);
int sub(int,int);
//main.c
#include"calculate.h"
#define PI 3.14
void platform_init()
{
#ifdef ARM
printf("ARM platform init ..\n");
#else
printf("X86 platform init ..\n");
#endif
}
#pragma pack(2)
#pragma message("build main.c...");
float f= PI;
int main(void)
{
platform_init();
add(2,3);
sub(5,4);
return 0;
}
对上面的C程序只做预处理,不编译,将输出的信息重定向到main.i文件
arm-linux-gnueabi-gcc -E main.c >main.i
cat main.i

# 1 "main.c"
# 1 ""
# 1 ""
# 31 ""
# 1 "/usr/arm-linux-gnueabi/include/stdc-predef.h" 1 3
# 32 "" 2
# 1 "main.c"
# 1 "calculate.h" 1
int add(int a,int b);
int sub(int a,int b);
# 2 "main.c" 2
void platform_init()
{
printf("X86 platform init ..\n");
}
#pragma pack(2)
# 13 "main.c"
#pragma message("build main.c...");
# 13 "main.c"
float f= 3.14;
int main(void)
{
platform_init();
add(2,3);
sub(5,4);
return 0;
}
对比预处理前后源文件的变化,可以发现,当预处理器
遇到#include命令时,会直接将包含的头文件内容展开,并删除#include
遇到#define宏时,执行同样的操作
当遇到条件编译指令时,会根据开发者定义的宏标记。选择要参与编译的代码部分,其余部分删除
经过预处理后,#pragma保留,指示编译器在后续的编译阶段执行一些特殊的操作
继续编译预处理后的C程序,在编译信息提示窗口里,我们会看到自己添加的编译提示信息
arm-linux-gnueabi-gcc main.i

4.3 程序的编译
经过预处理后的源文件,退去一切包装,注释被删除,各种预处理命令也基本上被处理掉了,剩下的是原汁原味的C代码
接下来的第二步是进入编译阶段,编译阶段分两步
1.编译器调用一系列解析工具,去分析这些C代码,将C源文件编译为汇编文件
2.通过汇编器将汇编文件汇编成可重定位的目标文件
4.3.1 从C文件到汇编文件
从C文件到汇编文件,其实是从高级语言到低级语言的转换。通过前面的学习,我们知道,一个汇编文件是以段为单位来组织程序的:代码段、数据段、BSS段,各个段之间相互独立,可以使用AREA或.section伪操作来定义一个段
汇编程序的组织结构和二进制目标文件已经很接近(两者本质上等价):汇编指令是二进制指令的助记符
唯一的差异是汇编语言的程序结构需要使用各种伪操作来组织。汇编文件经过汇编器汇编后,处理掉各种伪操作命令就是二进制目标文件了
从C源文件到汇编文件的转换,是将C文件中的程序代码块、函数转换为汇编程序中的数据段、只读数据段。将C程序中的全局变量、静态变量、常量转换为汇编程序中的数据段、只读数据段(但真的实现起来是很复杂的,单单C语句解析就是一门大学问)
编译过程可以分为6步
1.词法分析
2.语法分析
3.语义分析
4.中间代码生成
5.汇编代码生成
6.目标代码生成
词法分析是编译过程的第一步,主要用来解析C程序语句。词法分析一般会通过词法扫描器从左到右,一个字符一个字符地读入源程序,通过有限状态机解析并识别这些字符流,将源程序分解为一些列不能再分解的记号单元–token
token是字符流解析过程中有意义的最小记号单元,常见的token如下
- C语言的各种关键字: int、float、for、while、break等
- 用户定义的各种标识符:函数名、变量名、标号等
- 字面量:数字、字符串等
- 运算符:C语言标准定义的40多个运算符
- 分隔符:程序结束符分号、for循环中的逗号
假如我们C源程序中有下面这句:
sum = a+b/c;
经过词法扫描器扫描分析后,就分解成了8个token:“sum”、“=”、“a”、“+”、“b”、“/”、“c”、“;”,新手写C程序时不小心输入了中文符号、圆角/半角字符导致编译出错,就发生在这个阶段
词法分析结束后,进入语法分析。语法分析主要是对前一阶段产生的token序列进行解析,看是否能构建一个语法上正确的语法短语(程序、语句、表达式等)。语法短语用语法树表示,是一种树型结构,不再是线性序列。如图4-4,上面的token序列,经过语法分析,就可以分解为一个语法上正确的语法树

图4-4语法树
语法分析工具在对token序列分析过程中,如果发现不能构建语法上正确的语句或表达式,就会报语法错误:syntax error。如果程序语句后面少加了一个语句结束符分号或在for循环中少了一个分号,报的错误都属于这种语法错误。在调试程序时,遇到syntax error就要检查一下
语法分析如果没有出现问题就会进入下一阶段:语义分析,语法分析仅仅对程序做语法检查,对程序、语句的真正意义并不了解,而语义分析主要对语法分析输出的各种表达式、语句进行检查,看看有没有错误,如果传递给函数的实参与函数声明的形参类型不匹配,或者使用了一个未声明的变量、除数为零、break出现在循环语句或switch语句之外、continue出现在循环语句之外,这些都会报语义上的错误或警告
语义分析通过后,接下来就会进入编译的第四阶段:生成中间代码。在语法分析阶段输出的表达式或程序语句,还是以语法树的形式储存,我们需要将其转换为中间代码。中间代码是编译过程中的一种临时代码,常见的有三地址吗、P-代码等。
中间代码和语法树相比,优点是:中间代码是一维线性序列结构,类似伪代码,编译器很容易将中间代码翻译成目标代码,如下面的表达式语句
int main(void)
{
int sum =0;
int a=2;
int b=1;
int c=1;
sum=a+b/c;
return 0;
}
使用下面的命令就可以生成对应的三地址码
arm-linux-gnueabi-gcc -fdump-tree-gimple main.c
main ()
{
int D.4205;
{
int sum;
int a;
int b;
int c;
sum = 0;
a = 2;
b = 1;
c = 1;
_1 = b / c;
sum = a + _1;
D.4205 = 0;
return D.4205;
}
D.4205 = 0;
return D.4205;
}

C程序语句sum=a+b/c;编译为三地址码后,就变成了上面所示的类似伪代码的语句。中间码一般和平台是无关的,如果想将C程序编译为X86平台下的可执行文件,那么最后一步就是根据X86指令集,将中间代码翻译为X86汇编程序;如果想编译成在ARM平台上运行的可执行文件,那么就要参考ARM指令集,根据ATPCS规则分配寄存器,将中间代码翻译成ARM汇编程序
根据上面的三地址码,我们尝试将sum=a+b/c使用ARM汇编指令实现:变量a、b、c分别放到寄存器R0、R1、R2中,临时变量D.4427使用R3代替,然后使用ADD命令完成累加
MOV R0,#2
MOV R1,#1
MOV R2,#1
DIV R3,R1,R2
ADD R0,R0,R3
当然,上面的例子只是为了演示三地址码到ARM汇编程序的转换。ARM交叉编译器到底是如何实现的,我们使用arm-linux-gnueabi-gcc -S命令或反汇编可执行文件,即可查看汇编代码的具体实现
rm-linux-gnueabi-gcc -S main.c

4.3.2 汇编过程
汇编过程是使用汇编器将前一阶段生成的汇编文件翻译成目标文件。编译器的主要工作是参考ISA指令集,将汇编代码翻译成对应的二进制指令,同时生成一些必要的信息,以section的形式组装到目标文件中,后面的链接过程会用到这些信息。如图4-5所示,汇编的流程主要包括词法分析、语法分析、指令生成等过程
编译器在编译一个项目时,是以C源文件为单位进行编译的,每一个源文件经过编译,生成一个对应的目标文件,如图4-6所示,本章开头创建的main.c、add.c和sub.c文件,经过编译阶段后,会生成对应的main.o、add.o和sub.o,但是这三个目标文件是不可执行的,属于可重定位的目标文件,它们要经过链接器重定位、链接之后,才能组装成一个可执行的目标文件a.out

通过编译生成的可重定位目标文件,都是以零地址为链接起始地址进行链接的,即编译器在将源文件翻译成可重定位目标文件的过程中,将不同的函数编译成二进制指令后,是从零地址开始依次将每一个函数的指令序列存放到代码段中,每个函数的入口地址也就从零地址开始依次往后偏移,使用readelf命令分析main.o、add.o和sub.o这三个目标文件
先生成main.o、add.o和sub.o
arm-linux-gnueabi-gcc -c main.c add.c sub.c

readelf -S main.o sub.o add.o
展示部分代码:
File: main.o
There are 12 section headers, starting at offset 0x358:
Section Headers:
[Nr] Name Type Addr Off Size ES Flg Lk Inf Al
[ 0] NULL 00000000 000000 000000 00 0 0 0
[ 1] .text PROGBITS 00000000 000034 00005c 00 AX 0 0 4
[ 2] .rel.text REL 00000000 0002c4 000030 08 I 9 1 4
[ 3] .data PROGBITS 00000000 000090 000008 00 WA 0 0 4
[ 4] .bss NOBITS 00000000 000098 000004 00 WA 0 0 4
[ 5] .rodata PROGBITS 00000000 000098 00000e 00 A 0 0 4
[ 6] .comment PROGBITS 00000000 0000a6 000031 01 MS 0 0 1
[ 7] .note.GNU-stack PROGBITS 00000000 0000d7 000000 00 0 0 1
[ 8] .ARM.attributes ARM_ATTRIBUTES 00000000 0000d7 00002a 00 0 0 1
[ 9] .symtab SYMTAB 00000000 000104 000160 10 10 16 4
[10] .strtab STRTAB 00000000 000264 00005d 00 0 0 1
[11] .shstrtab STRTAB 00000000 0002f4 000061 00 0 0 1
Key to Flags:
W (write), A (alloc), X (execute), M (merge), S (strings), I (info),
L (link order), O (extra OS processing required), G (group), T (TLS),
C (compressed), x (unknown), o (OS specific), E (exclude),
y (purecode), p (processor specific)

通过打印的信息可以看到,main.o、add.o和sub.o这三个目标文件在编译时,都是以零地址为基地址进行代码段的组装
在每个可重定位目标文件中,函数或变量的地址其实就是它们在文件中相对于零地址的偏移:每个目标文件都是这样
有一个问题:在后面的链接中,链接器在将各个目标文件组装在一起时,各个目标文件的参考起始地址就发生了变化,那么这个目标文件中的函数或变量的地址也要随之更新,否则我们就无法通过函数名去引用函数,无法通过变量名去引用变量
- 地址是如何变更的呢?
链接器将各个目标文件组装在一起后,我们需要重新修改各个目标文件中的变量或函数的地址,这个过程称为重定位。 - 一个项目中有那么多文件,链接器是如何知道哪些函数或变量需要重定位呢?
很简单,我们需要把重定位的符号收集起来,生成一个重定位表,以section的形式保存到每个可重定位目标文件中就可以了
除此之外,一个文件的所有符号,无论是函数名还是变量名,无论其是否需要重定位,我们一般也会收集起来,生成一个符号表,以section的形式添加到每一个可重定位目标文件中
在上面的例子中, main.o中的函数引用了add.o和sub.o中的add和sub函数。在链接器组装过程中,add和sub函数的地址发生了变化;在链接器组装之后,需要重新计算和更新add和sub函数的新地址,这个过程是重定位
arm-linux-gnueabi-gcc -o a.out main.c add.c sub.c
4.3.3 符号表与重定位表
符号表和重定位表是非常重要的,这两个表为链接过程提供各种必要信息
在汇编阶段,汇编器会分析汇编语言中各个section的信息,收集各种符号,生成符号表,将各个符号在section内的偏移地址也填充到符号表内。我们可以使用命令来查看目标文件的符号信息
readelf -s sub.o #小写的s
打印结果如下:
Symbol table '.symtab' contains 10 entries:
Num: Value Size Type Bind Vis Ndx Name
0: 00000000 0 NOTYPE LOCAL DEFAULT UND
1: 00000000 0 FILE LOCAL DEFAULT ABS sub.c
2: 00000000 0 SECTION LOCAL DEFAULT 1
3: 00000000 0 SECTION LOCAL DEFAULT 2
4: 00000000 0 SECTION LOCAL DEFAULT 3
5: 00000000 0 NOTYPE LOCAL DEFAULT 1 $a
6: 00000000 0 SECTION LOCAL DEFAULT 5
7: 00000000 0 SECTION LOCAL DEFAULT 4
8: 00000000 0 SECTION LOCAL DEFAULT 6
9: 00000000 48 FUNC GLOBAL DEFAULT 1 sub

在整个编译过程中,符号表主要用来保存源程序中何种符号的信息,包括符号的地址、类型、占用空间的大小等。这些信息一方面可以辅助编译器做语义检查,看源程序是否有语法错误;另一方面也可以辅助编译器编译代码的生成,包括地址与空间的分配、符号决议、重定位等
符号表本质上是一个结构体数组,在ARM平台下,定义在Linux内核源码的/arch/arm/include/asm/elf.h文件中
type struct elf32_sym
{
Elf32_Word st_name; //符号名,字符串表中的索引
Elf32_Addr st_value; //符号对应值
Elf32_Word st_size; //符号类型和绑定信息
unsigned char st_info; //符号类型和绑定信息
unsigned char st_other;
Elf32_Half st_shndx; //符号所在的段
} Elf32_Sym;
符号表中的每一个符号,都有符号值和类型。符号值本质上是一个地址,也可以是绝对地址,一般出现在可执行目标文件中;也可以是一个相对地址,一般出现在可重定位目标文件中,符号的类型主要有以下几种:
OBJECT:对象类型,一般用来表示我们在程序中定义的变量
FUNC:关联的是函数名或其他可引用的可执行代码
FILE:该符号关联的是当前目标文件的名称
SECTION:表明该符号关联的是一个section,主要用来重定位
COMMON:表明该符号是一个公用块数据对象,是一个全局弱符号,在当前文件中未分配空间
TLS:表明该符号对应的变量存储在线程局部存储中
NOTYPE:未指定类型,或者目前还不知道该符号类型
编译器是以C源文件为单位编译程序的,如果在一个C源文件中,我们引用了在其他文件中定义的函数或全局变量,那么编译器会不会报错?
其实编译器是不会报错的,只要在调用之前,声明一下编译器就会认为你引用的这个全局变量或函数可能在其他文件、库中定义,在编译阶段暂时不会报错。在后面的链接过程中,链接器会尝试在其他文件或库中查找你引用的这个符号的定义,如果真的找不到才会报错,此时的错误类型是链接错误
main.o: In function `main':
main.c:(.text+0x14): undefined reference to `add'
main.c:(.text+0x24): undefined reference to `sub'
collect2: error: ld returned 1 exit status
 编译器在给每个目标文件生成符表的过程中,如果在当前文件中没有找到符号的定义,也会将这些符号收集在一起并报错到一个单独的符号表中,以待后续填充,这个符号表就是重定位符号表,如
编译器在给每个目标文件生成符表的过程中,如果在当前文件中没有找到符号的定义,也会将这些符号收集在一起并报错到一个单独的符号表中,以待后续填充,这个符号表就是重定位符号表,如main.o中,引用了add和sub这两个在别的文件中定义的符号,我们查看main.o的符号表(.symtab)
打印如下
Symbol table '.symtab' contains 22 entries:
Num: Value Size Type Bind Vis Ndx Name
0: 00000000 0 NOTYPE LOCAL DEFAULT UND
1: 00000000 0 FILE LOCAL DEFAULT ABS main.c
2: 00000000 0 SECTION LOCAL DEFAULT 1
3: 00000000 0 SECTION LOCAL DEFAULT 3
4: 00000000 0 SECTION LOCAL DEFAULT 4
5: 00000000 0 NOTYPE LOCAL DEFAULT 3 $d
6: 00000000 0 SECTION LOCAL DEFAULT 5
7: 00000000 0 NOTYPE LOCAL DEFAULT 5 $d
8: 00000000 0 NOTYPE LOCAL DEFAULT 1 $a
9: 00000054 0 NOTYPE LOCAL DEFAULT 1 $d
10: 00000000 4 OBJECT LOCAL DEFAULT 4 uninit_local_val.4621
11: 00000000 0 NOTYPE LOCAL DEFAULT 4 $d
12: 00000004 4 OBJECT LOCAL DEFAULT 3 local_val.4620
13: 00000000 0 SECTION LOCAL DEFAULT 7
14: 00000000 0 SECTION LOCAL DEFAULT 6
15: 00000000 0 SECTION LOCAL DEFAULT 8
16: 00000000 4 OBJECT GLOBAL DEFAULT 3 global_val
17: 00000004 4 OBJECT GLOBAL DEFAULT COM uninit_val
18: 00000000 92 FUNC GLOBAL DEFAULT 1 main
19: 00000000 0 NOTYPE GLOBAL DEFAULT UND add
20: 00000000 0 NOTYPE GLOBAL DEFAULT UND sub
21: 00000000 0 NOTYPE GLOBAL DEFAULT UND printf

在main.o的符号表中,可以看到,add和sub这两个符号的信息处于未定义状态(NOTYPE),需要后续填充。同时,在main.o中会使用一个重定位表.rel.text来记录这些需要重定位的符号
我们使用readelf命令分别去查看main.o的重定位表和section header table信息
readelf -S main.o #大写的S
打印信息如下:
There are 12 section headers, starting at offset 0x358:
Section Headers:
[Nr] Name Type Addr Off Size ES Flg Lk Inf Al
[ 0] NULL 00000000 000000 000000 00 0 0 0
[ 1] .text PROGBITS 00000000 000034 00005c 00 AX 0 0 4
[ 2] .rel.text REL 00000000 0002c4 000030 08 I 9 1 4
[ 3] .data PROGBITS 00000000 000090 000008 00 WA 0 0 4
[ 4] .bss NOBITS 00000000 000098 000004 00 WA 0 0 4
[ 5] .rodata PROGBITS 00000000 000098 00000e 00 A 0 0 4
[ 6] .comment PROGBITS 00000000 0000a6 000031 01 MS 0 0 1
[ 7] .note.GNU-stack PROGBITS 00000000 0000d7 000000 00 0 0 1
[ 8] .ARM.attributes ARM_ATTRIBUTES 00000000 0000d7 00002a 00 0 0 1
[ 9] .symtab SYMTAB 00000000 000104 000160 10 10 16 4
[10] .strtab STRTAB 00000000 000264 00005d 00 0 0 1
[11] .shstrtab STRTAB 00000000 0002f4 000061 00 0 0 1
Key to Flags:
W (write), A (alloc), X (execute), M (merge), S (strings), I (info),
L (link order), O (extra OS processing required), G (group), T (TLS),
C (compressed), x (unknown), o (OS specific), E (exclude),
y (purecode), p (processor specific)
readelf -r main.o
打印信息如下:
Relocation section '.rel.text' at offset 0x2c4 contains 6 entries:
Offset Info Type Sym.Value Sym. Name
00000014 0000131c R_ARM_CALL 00000000 add
00000024 0000141c R_ARM_CALL 00000000 sub
00000034 0000151c R_ARM_CALL 00000000 printf
00000040 0000151c R_ARM_CALL 00000000 printf
00000054 00000602 R_ARM_ABS32 00000000 .rodata
00000058 00000602 R_ARM_ABS32 00000000 .rodata

readelf -S main.o
readelf -S sub.o

通过对比,我们可以看到,main.o目标文件比sub.o多了一个section:重定位表.rel.text中,我们可以看到需要重定位的符号add、sub及库函数printf。重定位表中的这些符号所关联的地址,在后面的链接过程中经过重定位,会更新为新的实际地址

4.4 链接过程
复习一下前面的内容:
在一个C项目的编译中,编译器以C源文件为单位,将一个个C文件翻译成对应的目标文件
生成的每一个目标文件都由代码段、数据段、BSS段、符号表等section组成
这些section从目标文件的零偏移地址开始按照顺序依次排放,每个段中的符号相对于零地址的偏移,其实就是每个符号的地址
这样程序中定义的变量、函数名等都有了一个暂时的地址
暂时:在后续的链接过程中,这些目标文件中的各个section会重新拆分组装,每个section的起始参考地址都会发生变化,导致每个section中定义的函数、全局变量等符号的地址也要随之发生变化,需要重新修改,即重定位
这些函数、全局变量等符号同时被放置在目标文件中,这些目标文件是不可执行的,他们需要经过链接器链接、重定位后才能运行
本部分将接着上一节继续分析编译之后的链接过程,链接主要分为三个过程:分段组装、符号决议和重定位
4.4.1 分段组装

图4-7 程序的链接过程
链接过程第一步:将各个目标文件分段组装
链接器将编译器生成的各个可重定位目标文件重新分解组装:将各个目标文件的代码段放在一起,作为最终生成的可执行文件的代码段
将各个目标文件的数据段放在一起,作为可执行文件的数据段
其他section也会按照同样的方法进行组装,最终就生成了一个如图4-7所示的可执行文件的雏形
除了代码段、数据段的分解组装需要关注,还有一个重要的section需要我们了解一下
符号表:
链接器会在可执行文件中创建一个全局的符号表,收集各个目标文件符号表中的符号,然后将其统一放到全局符号表中
通过这步操作,一个可执行文件中的所有符号都有了自己的地址,并保存在全局符号表中,但此时全局符号表中的地址还都是原来在各个目标文件中的地址,即相对于原地址的偏移
在生成链接过程中,不同的代码如何组装?
链接生成的可执行文件最终是要被加载到内存中执行的,那么要加载到内存中的什么地方?
一般而言,程序在链接程序时需要指定一个链接起始地址,链接开始地址一般也就是程序要加载到内存中的地址
在链接过程中,各个段在可执行文件的先后组装顺序也是一个需要考虑的问题
一个可执行程序肯定会有入口地址,一般执行的代码要放到前面
那么如何指定程序的链接地址和各个段的组装顺序?
通过链接脚本:
链接脚本本质上是一个脚本文件,在这个脚本文件中,不仅规定了各个段的组装顺序、起始地址、位置对齐等信息,同时对输出的可执行文件格式、运行平台、入口地址等信息做了详细的描述
链接器就是根据链接脚本定义的规则来组装可执行文件的,并最终将这些信息以section的形式报错到可执行文件的ELF Header中,一个简单的链接脚本如下
OUTPU_FORMAT("elf32-littlearm") ;输出ELF文件格式
OUT_ARCH("arm") ;输出可执行文件的运行平台为arm
ENTY(_start) ;程序入口地址
SECTIONS ;各段描述
{ .=0X60000000; ;代码段的起始地址
.text:{*(.text)} ;代码段描述:所有.o文件中的.text段
.=0x60200000; ;数据段的起始地址
.data:{*(.data)} ;数据段描述:所有.o文件中的.data段
.bss :{*(.bss)} ;BSS段描述
}
假如在一个嵌入式系统中,内存RAM的起始地址是0x60000000,我们在链接程序时,可以在链接脚本中指定内存中的一个合法地址作为链接起始地址
程序运行时,加载器首先会解析可执行文件中的ELF Header头部信息,验证程序的运行平台和加载地址信息,然后将可执行文件加载到内存中对应的地址,程序就可以正常运行了
在Windows或Linux环境下编译程序,一般会使用编译器提供的默认链接脚本,程序员只需要关注功能和业务逻辑的实现就可以了,不需要关心这些底层是如何编译和链接的
程序写好后,点击图形界面上的RUN按钮,或使用gcc/make命令编译后即可运行
如果对链接脚本感兴趣,可以使用下面的命令来查看链接器使用的默认链接脚本
arm-linux-gnueabi-ld --verbose

在嵌入式裸机环境下编译程序,尤其是编译ARM底层代码,很多时候我们要根据开发部的不同硬件配置、内存大小和地址,灵活指定链接地址,或显示指定链接脚本,有时候甚至要自己编写脚本
U-boot源码编译的脚本U-boot.lds一般放在U-boot源码的顶层目录下
Linux内核编译的链接脚本vmlinux.lds一般放在arch/arm/boot/compressed/目录下面,而对于ARM裸机程序开发,大多数IDE都会提供一些接口,如ADS1.2集成开发环境。如图4-8所示,在simple模式下,我们可以直接通过Debug Setting界面设置代码段、数据段的起始地址
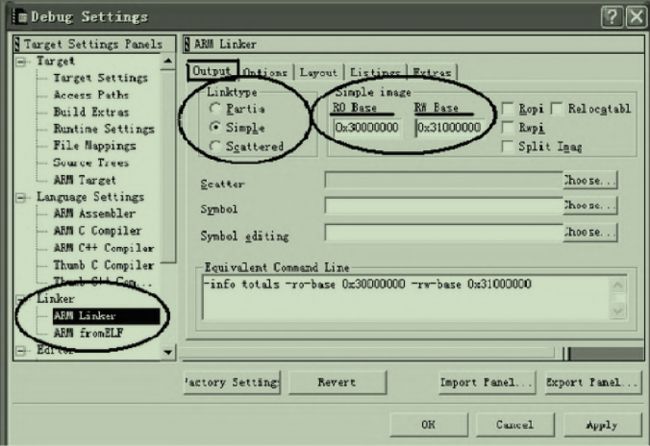
图4-8 代码段、数据段的起始地址配置
如图4-9所示,通过链接器的Layout选项我们还可以设置程序的入口地址
当一个嵌入式系统有多种存储配置(Flash、ROM、SDRAM、片内SRAM等),存在各种复杂的地址映射,程序需要加载到不同的RAM中运行时,通过上面的界面简单配置已经不能满足我们的需求。ADS1.2集成开发环境提供了另一种模式:Scattered模式,即采用分散加载,通过显示指定scatter.scf脚本来指示链接器完成链接过程。分散加载脚本的格式事例如下

图4-9 程序的入口地址设置
LOAD_ROM 0X00000000 ;程序入口地址
{
EXEC_ROM ;代码放在ROM中
{
*(+Ro)
}
RAM OX30008000
{
*(+RW,+ZI);数据段、BSS段放在RAM中
}
}
不同的编译器、不同的操作系统,链接脚本的文件名后缀一般也不一样。GCC编译器的默认链接脚本在/usr/lib/scripts目录下,而C-Free集成开发环境默认链接脚本则在安装路径下的mingw/mingw32/lib/ldscripts下
不同的编译器默认的链接地址是不一样的,如ubuntu16.04环境下安装的32位GCC编译器,默认链接的起始地址为0x08048000,32位ARM交叉编译器的默认链接起始地址为0x10000。在一个带有MMU(Memory Management Unit内存管理单元)的CPU搭建的嵌入式系统中,程序的链接起始地址往往都是一个虚拟地址,程序运行过程还需要地址转换,通过MMU将虚拟地址转换为物理地址,然后才能访问内存,这部分内容属于CPU硬件底层要关心的内容,和编译原理是不冲突的
4.4.2 符号决议
公司中的项目常由多人组成的软件团队共同开发
一个项目
产品经理定义功能需求
架构师进行系统分析和模块划分
将各个模块的具体实现分配给不同的人员
开发者在实现各自模块的编程中,可能会产生一个问题:
位于不同模块或不同文件中的全局变量、函数可能存在重名冲突
int i,j;
int count;
int add(int a,int b);
当这些全局变量在多个文件中定义时,链接器在链接过程中会发现:各个文件中定义了相同的全局变量或函数名,发生了符号冲突
编译器有专门的符号决议规则来解决这种符号冲突。规则很简单:
- 一山不容二虎
- 强弱可以共存
- 体积大者胜出
一山不容二虎:
"虎"指强符号,编译器为了解决这种符号冲突,引入了强符号和弱符号的概念
强符号:函数名、初始化的全局变量
弱符号:未初始化的全局变量
在一个多文件的工程中,强符号不允许多次定义,否则就会发生重定义错误
强符号和弱符号可以在一个项目中共存,当强弱符号共存时,强符号会覆盖掉弱符号,链接器会现在强符号作为可执行文件中的最终符号
//sub.c
int i =20;
//main.c
int i;
int main(void)
{
printf("i=%d\n",i);
return 0;
}
使用gcc 或arm-linux-gcc编译上面的两个源文件并运行
gcc main.c sub.c -o a.out
./a.out

通过程序运行结果可以看到,i变量的最终值为20,而不是0。链接器在进行符号决议时,选择了强符号(sub.c源文件中定义的i符号),丢弃了弱符号(main.c源文件中定义的未初始化的全局符号i)。如果修改程序,将main.c文件中的i也附一个初值,再去重新编译这两个源文件,就会发现链接器会报重定义错误,因为此时一个项目中出现了两个同名的强符号,一山不容二虎
链接器也允许一个项目中出现多个弱符号共存,在编译期间,编译器在分析每个文件中未初始化的全局变量时,并不知道该符号在链接阶段是被采用还是被丢弃,因此在程序编译期间,未初始化的全局变量并没有被直接放在BSS段中,而是将这些弱符号放在一个叫做COMMON的临时块中,在符号表中使用一个未定义的COMMON来标记,在目标文件中也没有给它们分配存储空间
在链接期间,链接器会比较多个文件中的弱符号,选择占用空间最大的那个,作为可执行文件中的最终符号,此时弱符号的大小已经确定,并被直接放到了可执行文件的BSS段中
//sub.c
int i ;
//main.c
char i;
int main(void)
{
return 0;
}
编译和分析上面的sub.c和main.c
arm-linux-gnueabi-gcc main.c sub.c
arm-linux-gnueabi-gcc -c main.c sub.c
readelf -s main.o|grep i
readelf -s sub.o|grep i
readelf -s a.out|grep i

打印如下:
readelf -s main.o|grep i
9: 00000001 1 OBJECT GLOBAL DEFAULT COM i
readelf -s sub.o|grep i
8: 00000004 4 OBJECT GLOBAL DEFAULT COM i
readelf -s a.out|grep i
94: 00021028 4 OBJECT GLOBAL DEFAULT 23 i

通过readelf命令分别查看目标文件main.o和sub.o中的符号i,可以发现它们都被放置在了COMMON块中,大小分别标记为1和4,而最终生成的可执行文件a.out中,变量i被放置在.bss段中,大小标记为4字节
正常情况下,初始化的全局变量、函数名默认都是强符号,未初始化的全局变量默认是弱符号。如果在项目中有特殊需求,我们也可以将一些强符号显示转换为弱符号
GNU C编译器在ANSI C语法标准的基础上扩展了一系列C语言语法,如提供了一个__attribute__关键字用来声明符号的属性。通过下面的命令,可以将一个强符号转换为弱符号
__attribute__((weak)) int n = 100;
__attribute__((weak)) void fun();
为了验证上面的命令是否成功地将强符号转换为了弱符号,我们写一个简单的程序来测试
//sub.c
int i = 20 ;
//main.c
__attribute__((weak)) int i = 10;
int main(void)
{
printf("i=%d\n",i);
return 0;
}
编译上面的两个源文件并运行
gcc -o out main.c sub.c
./out

变量i的打印值为20,在main.c中虽然定义了一个初始化的全局变量,但是通过__atrribute__属性声明将其显示弱化后,就避免了“一山不容二虎”的符号冲突,编译器不会报链接错误
和强符号、弱符号对应的,还有强引用、弱引用的概念。在一个程序中,我们可以定义多个函数和变量,变量名和函数名都是符号,这些符号的本质,或者说这些符号值,其实就是地址。在另一个文件中,我们可以通过函数名去调用该函数,通过变量名去访问该变量。我们通过符号去调用一个函数或访问一个变量,通常称之为引用*(reference),强符号对应强引用,弱符号对应弱引用
在程序链接过程中,若对一个符号的引用为强引用,链接时找不到其定义,链接器将会报未定义错误;若对一个符号的引用为弱引用,链接时找不到其定义,则链接器不会报错,不会影响最终可执行文件的生成。可执行文件在运行时没有找到该符号的定义才会报错
利用链接器对弱引用的处理规则,我们在引用一个符号之前可以先判断该符号是否存在(定义),这样做的好处是:当我们引用一个未定义符号时,在链接阶段不会报错,在运行阶段通过判断运行,也可以避免运行错误
例子:想实现一个视频解码模块,并最终封装成库的形式提供给应用开发者
在模块实现的过程中,我们可以将提供给用户的一系列API函数声明为弱符号,这样做的两个好处:
1.当我们对库中的某些API函数实现不满意时,或者这些API存在bug,我们有更好的实现时,可以自定义与库函数同名的函数,直接调用他们而不会发生冲突
2.在库的实现过程中,我们可以将某些扩展功能模块还未完成的一些API定义为弱引用。应用程序在调用这些API之前,要先判断该函数是否实现,然后才调用运行,这样做的好处是未来发布新版本库时,无论这些接口是否已经实现,或已经删除,都不会影响应用程序的正常链接和运行
//decode.h
__attribute__((weak)) void decode();
//decode.c
#include//main.c
#include在上面的程序中,我们实现了一个解码库,并将解码库的函数接口声明为弱引用。在main.c中,main()函数调用了解码库中的decode()函数,在调用之前,我们先对弱引用做了一个判断,这样做的好处是:无论在decode.c中decode()函数是否有定义,都不会影响程序的正常运行
ARM电脑
arm-linux-gnueabi-gcc main.c decode.c
./a.out
rm a.out
arm-linux-gnueabi-gcc main.c
./a.out
X86电脑
gcc main.c
./a.out
rm a.out
gcc main.c decode.c
./a.out

4.4.3 重定位
经过符号决议,我们解决了链接过程中多文件符号冲突的问题,经过处理之后,可执行文件的符号表中的每个符号虽然都确定下来了,但是还存在一个问题:符号表中的每个符号值,也就是每个函数、全局变量的地址,还是原来各个目标文件中的值(基于零地址的偏移)。链接器将各个目标重新分解组装后,各个段的起始地址都发生了变化
 图4-10 链接过程中的各符号地址变化
图4-10 链接过程中的各符号地址变化
在可执行文件中,各个段的起始地址都发生了变化,那么各个段的符号地址也要跟着发生变化。编译器生成的各个目标文件,以零地址为起始地址放置各个函数的指令代码,各个函数相对零地址的偏移就是各个函数的入口地址。如图4-10中的main()函数和sub()函数,它们在原来各自的目标文件中,相对于零地址的偏移分别是0x10和0x30,main.o文件中代码段的大小为len,经过链接器分解后,所有目标文件的代码段组装在一起,原来目标文件的各个代码段的起始地址发生了变化:此时main()函数和sub()函数相对于a.out文件头地址也就变成了0x10和len+0x30。链接器在链接程序时一般会基于某个链接地址link_addr进行链接,所以最后main()函数和sub()函数的真实地址也就变成了link_addr+0x10、link_addr+len+0x30。
程序经过重新分解组装后,无论是代码段还是数据段,各个符号的真实地址都发生了变化,而此时可执行文件的全局符号表中,各个符号的值还是原来的地址,所以接下来还要修改全局符号表中这些符号的值,将他们的真实地址更新到符号表中。修改完毕后,当我们想通过符号引用去调用一个函数或访问一个变量时,就能找到它们在内存中的真实地址了
链接器怎么知道哪些符号需要重定位呢?
在各个目标文件中还有一个重定位表,专门记录各个文件中需要重定位的符号
重定位的核心工作就是修正指令中的符号地址,是链接过程中的最后一步,也是最核心、最重要的一步,前面两步的操作,都是为这一步服务
在编译阶段,编译器在将各个C源文件生成目标文件的过程中,遇到未定义的符号一般不会报错,编译器会认为这些符号可能会在其他地方定义。在链接阶段,链接器在其他地方找不到该符号的定义,才会报链接错误。编译器在链接阶段(之前?)会搜集这些未定义的符号,生成一个重定位表,用来告诉链接器,这些符号在文件中被引用,但是在本文件中没有找到定义,有可能在其他文件或库中定义,“我先不报错,你链接的时候找找看”
无论是代码段,还是数据段,只要这个段中有需要重定位的符号,编译器都会生成一个重定位表与其对应:.rel.text或.rel.data。这些重定位表记录各个段中需要重定位的各种符号,并以section的形式保存在各个目标文件中,我们可以通过readelf或objump命令来查看一个目标文件中的重定位表信息
arm-linux-gnueabi-gcc -c main.c
arm-linux-gnueabi-objdump -r main.o
arm-linux-gnueabi-readelf -r main.o
打印内容如下:
smile@smile-X3-S:~/Documents/code/C/4.4.2.4$ arm-linux-gnueabi-objdump -r main.o
main.o: file format elf32-littlearm
RELOCATION RECORDS FOR [.text]:
OFFSET TYPE VALUE
00000014 R_ARM_CALL decode
0000001c R_ARM_CALL puts
0000002c R_ARM_ABS32 decode
00000030 R_ARM_ABS32 .rodata
smile@smile-X3-S:~/Documents/code/C/4.4.2.4$ arm-linux-gnueabi-readelf -r main.o
Relocation section '.rel.text' at offset 0x1e0 contains 4 entries:
Offset Info Type Sym.Value Sym. Name
00000014 00000d1c R_ARM_CALL 00000000 decode
0000001c 00000e1c R_ARM_CALL 00000000 puts
0000002c 00000d02 R_ARM_ABS32 00000000 decode
00000030 00000502 R_ARM_ABS32 00000000 .rodata
重定位表有一个重要的信息:需要重定位表的符号在指令代码中的偏移地址offset,链接器修正指令代码中各个符号的值时要根据这个地址信息才能从茫茫的二进制代码中找到他们。链接器读取各个目标文件中的重定位表,根据这些符号在可执行文件中的新地址,进行符号重定位,修改指令代码中引用这些符号的地址,并生成新的符号表。重定位过程中的地址修正其实很简单,如下
重定位新地址=新的段基地址+段内偏移
至此,整个链接过程就结束了,我们跟踪的整个编译流畅也就是结束了,最终生成的文件就是一个可执行目标文件

4.5 程序的安装
程序的运行过程,其实就是处理器根据PC寄存器中的地址,从内存中不断取指令、翻译指令和执行指令的过程。内存RAM的优点是支持随机读写,因此可以支持CPU随机读取指令;内存的缺点是RAM属于易失性存储器,一旦断电,内存中原先保存的数据都会消失。现代计算机的存储系统一般采用ROM+RAM的组合形式;ROM中存储的数据断电后不会消失,常用来报错程序的指令和数据,但ROM不支持随机存取,因此程序运行时,会首先将指令和数据从ROM加载到RAM,然后CPU到RAM中取指令
4.5.1 程序安装的本质
- 以Windows电脑安装一个软件为例子,我们在网上下载一个软件的安装包,接着把这个软件安装到我们的D盘,安装成功后在桌面会留下一个快捷方式,双击打开就可以使用这个软件了
- 软件的安装过程其实就是将一个可执行文件安装到ROM的过程,我们下载的软件安装包里包含了可以在计算机上运行的可执行文件,软件开发者为了方便用户使用,将可执行文件、程序运行时需要的动态共享库、安装使用文档等打包压缩,生成可运行的自解压安装包格式
- 使用安装包安装软件就是将包中的可执行文件解压出来,然后将可执行文件和动态共享库复制到指定的安装目录,并把这些安装信息告诉操作系统。当用户要运行这个软件时,操作系统就会从安装目录找到这个可执行文件,把它加载到内存执行。无论是在Linux环境还是在Windows环境,基本上都是遵循这个套路,只不过实现的方式不同而已
- 在Linux环境中,我们一般将可执行文件直接复制到系统的官方路径/bin、/sbin、/usr/bin下,程序运行时直接才能够这些系统默认的路径下去查找可执行文件,将其加载到内存运行
接下来我们做一个实验,分别在Linux和Windows下制作一个软件安装包,分别安装运行,这个软件很简单,是一个helloworld程序