linux内存模型
转自:Linux内存管理(五)内存模型 - 知乎
本文基于以下软硬件假定:
架构:AARCH64
内核版本:5.14.0-rc5
1 平坦内存模型
linux内核采用页式内存管理,这种方式将整个物理地址空间划分成一系列以页帧为单位、大小相等的块。为了方便对这些块的引用,内核使用PFN对其进行编号,由于每个页都以页size为单位对齐,因此通过对物理地址移位就能得到PFN。如对于经典的4k页,可通过以下公式计算页帧号:
pfn = phys >> 12为了方便对物理内存的管理,内核又为每个页帧分配一个page结构体,用于维护与页帧相关的一些标志和属性信息。由于内核可能需要频繁地访问该结构体,因此就需要pfn和page结构体之间能比较方便且高效地相互转换。由于平坦内存的地址空间基本是连续的,因此对于平坦内存只需为其分配一块连续page地址空间,其就可以按下述方式转换:
page_addr = start_page + pfn – start_pfn此时若页size为4k,则pfn与page结构体之间的关系如下图:

但是对于像numa或其它一些内存架构,其物理地址空间可能并不连续,而是在中间存在一些空洞,若还采用上面的page结构体分配方式,则其关系如下图:
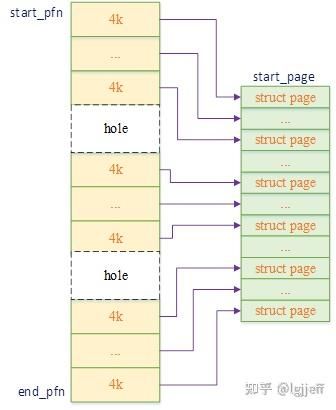
此时除内存空间外,还为那些空洞分配了page结构体,显然这是一种内存浪费。进一步看,每个page结构体需要占用64字节空间,假设内核配置的页大小为4k,则在没有空洞情况下该结构就需要占用约1.56%(64/4096)的总内存。若内存地址之间的空洞很大,则其浪费的内存将会非常惊人。
同时对于numa系统,cpu访问不同节点内存的速度不同,将page结构体分配到某一个特定节点,则不与该节点绑定的cpu访问这些数据的效率显然也会有问题。
因此作为内核对上述问题的解决方案,稀疏内存模型开始闪亮登场
2 稀疏内存模型
与平坦内存模型不同,稀疏内存模型将整个地址空间按section为单位进行分段,在armv8架构中,4k页size配置下section的size为128M,16k页size配置下section的size为512M。如对于128M section,则其分段形式如下:

这样如果某个section的地址都位于空洞中,我们就不需要为其分配page结构体,而且不同section对应的page结构体内存也不必是连续的。此时它们之间的组织关系可变为下图所示的形式:
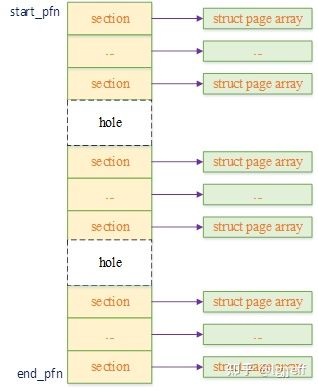
看起来前面的两个问题都被完美地解决了:
(1)由于不再为空洞建立page结构体,内存浪费处于可控状态。即每个空洞最多浪费128M * 1.56%的内存,由于一般系统内存的空洞数量并不会太多,且大部分的对齐边界都高于128M,因此这种内存消耗是可接受的
(2)每个section的page结构体内存可独立分配,这样就可以方便地将其放到最优的numa节点中,内存访问速度的问题也得到解决
但是细心的我们可能会发现,这两种模型的pfn和page结构体转换流程有些差异。其中平坦内存的转换方式如下:
#define __pfn_to_page(pfn) (mem_map + ((pfn) - ARCH_PFN_OFFSET))而稀疏的内存的转换关系如下:
#define __pfn_to_page(pfn) \
({ unsigned long __pfn = (pfn); \
struct mem_section *__sec = __pfn_to_section(__pfn); \
__section_mem_map_addr(__sec) + __pfn; \
})它要先通过pfn找到其对应的section,然后再在section中计算该pfn的实际page指针。前面我们提到过,内核对于pfn和page的转换操作是比较频繁的,因此这一操作就降低了转换性能
3 sparse vmemmap内存模型
我们继续分析,sparse内存模型下pfn和page转换之所以多出一步是因为它们之间不再具有线性的一一对应关系。那么我们能不能既解决前述问题的前提下,又使得它们重新具有这种关系呢?
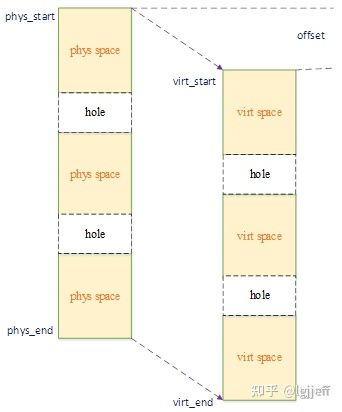
答案当然是可以的,我们知道内核会为所有非no-map的内存执行线性映射,这种映射方式的物理地址和虚拟地址之间只有一个offset偏移,而具有一一对应的关系。其原理如下图:
现在由于每个section的page结构体物理地址与其管理的内存地址之间不再具有一一对应关系,因此page结构体的线性映射虚拟地址与其所管理的内存地址之间也就不存在一一对应关系了。下图为其中的一个实例:
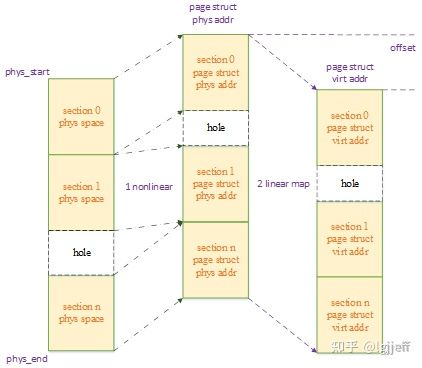
我们来回忆一下vmalloc的原理,通过非线性映射的方式,可以指定物理地址与虚拟地址之间的关系。因此像上图这种情况,我们可以将第二步linear map替换为非线性的vmemmap映射,并且将其映射关系调整为与第一步的关系相同,以将其重建为线性关系。以下为其重建原理图:
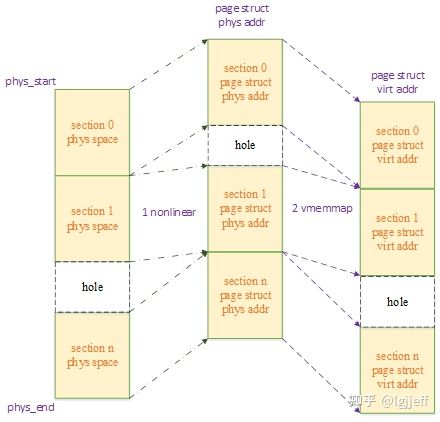
此时,page结构体的虚拟地址与其所管理的内存之间再次具有了线性关系,因此我们又可以愉快地使用与平坦模型类似的方式,执行pfn和page指针之间的转换了:
#define __pfn_to_page(pfn) (vmemmap + (pfn))为了实现这种映射关系,内核专门为page结构体预留了一段叫做vmemmap的虚拟地址空间。
最后,我们再看一下平坦内存模型实际上是稀疏内存模型的一个特例,因此稀疏内存模型可被用于所有内存布局的情况。故armv8会默认采用稀疏内存模型方式