多数据源,多租户,执行多线程代码的解决方案
我们的产品是用医疗数据做回顾性科研的,数据库 Schema 是基于国际公认的 OMOP 模型,所以核心的表结构都是固定的,而且我们经过几年的打磨,表也有上百个了,功能上也能支持复杂的查询和分析。我们自己也是对功能模块做了拆分,目前有 4 个应用,之间有少量的 REST 调用。
本来我们的目标客户是医院,实施人员抽取医院的 HIS 系统数据进入到我们的产品依赖的数据库,运行我们的软件,医生的科研都是基于全院数据的。所以大多数情况下,我们只需要启动 4 个 docker 甚至一个 docker 都行,能让 4 个应用跑起来就好。
但是今年的两家客户,要求做的科研不是基于全院数据,而是专病库,也就是胃肠科的,只希望整个系统跑的都只是胃肠的数据,心内科的只希望看心内的数据。如果一开始做项目的话,我们也许会在表中加一个字段,标识数据是属于哪个科室的。但是目前在产品比较成熟的情况下,我们的实施人员采用的部署方案是,每个科室一个数据库,然后每个数据库上面跑一套系统,也就是 4 个应用。可想而知,即便一个 docker 跑一套系统,多个科室就要跑多个 docker,如果我们接了十多个科室专病库,那么光是部署麻烦不说,还容易出错。
所以,我们的想法是,能不能系统只部署一套,数据库多个,用户使用时,系统运行时动态从对应的数据库连接池得到连接,执行 CURD 逻辑。具体实现上:
1. 用户登录时,需要其选择一个具体的(科室)专病库,我们将其会话 Session 和该数据源进行关联,此为第一步
2. 第二步,对每一次 HTTP 请求,都通过会话找到关联的数据源(从而获取数据库连接)
3. 第三步,针对系统大量使用了 java 多线程,需要保证子,孙线程都能继承已知的数据源为了证明可行性,我就简化了实现。首先,要实现多数据源,就需要通过一个名称去切换数据源:
/**
* Abstract javax.sql.DataSource implementation that routes getConnection() calls to
* one of various target DataSources based on a lookup key. The latter is usually
* (but not necessarily) determined through some thread-bound transaction context.
*/
public class CustomDataSource extends AbstractRoutingDataSource {
@Override
protected Object determineCurrentLookupKey() {
return DataSourceKeeper.getDataSourceName();
}
}方法体里的 DataSourceKeeper.java 就是帮助我们绑定会话 Session 和数据源的一个接口:
public class DataSourceKeeper {
public static WeakHashMap sessionDSMap = new WeakHashMap<>();
private static final InheritableThreadLocal dsInstanceHolder = new InheritableThreadLocal<>();
public static void setDataSourceName(String name){
dsInstanceHolder.set(name);
}
public static String getDataSourceName(){
return dsInstanceHolder.get();
}
} 变量 sessionDSMap 就是用户登录时选定数据源后,我们将 sessionId 和数据源的 lookup key 作为一个 Entry 放入。而 dsInstanceHolder 则是让子,孙线程继承这个 lookup key。因为代码里有不少多线程调用:

为了演示简单化,我就写了个 controller 来模拟用户登录时上报的 lookup key:
/**
* 模拟登录后,绑定用户会话Session和 target datasource
*/
@RestController
@RequestMapping("datasource")
@Slf4j
public class DataSourceBindController {
@GetMapping("{name}")
public void setDataSource(HttpServletRequest request, @PathVariable String name){
String sessionId = request.getSession().getId();
log.info("当前用户的 sessionId :: {}, 选择的数据源名称是 ::{}", sessionId, name);
DataSourceKeeper.sessionDSMap.put(sessionId, name);
}
}现在不同的用户登录(上报 lookup key)后,系统就知道了当前的每个用户绑定的数据源了,那么怎么使用呢?我定义了一个切面,拦截所有 controller 的调用(当然除了上面的 DataSourceBindController),将 lookup key 注入到线程上下文,保证线程在 getConnection() 时能正确路由到目标数据源。
/**
* 实现逻辑:每当controller 方法调用时,通过 sessionId 拿到绑定的 datasource
* 名称,并作为当前线程获取 datasource 实例的 lookup key.
*/
@Aspect
@Component
@Slf4j
public class DataSourceAspect {
@Autowired
private HttpServletRequest request;
@Before("execution(* com.hebta.vinci.code.controller..*(..))")
public void beforeMethod(JoinPoint jp){
String sessionId = request.getSession().getId();
log.info("当前用户的 sessionId :: {}", sessionId);
DataSourceKeeper.setDataSourceName(DataSourceKeeper.sessionDSMap.get(sessionId));
}
}PS: 没想到获取 HttpServletRequest 还可以使用 @Autowired 方式,真是方便!
至此,多租户多数据源,并行运行多线程代码的方案算是实现完成了,但是还有遗留问题:
1. 日志无法分离,没办法通过 lookup key 或者别的对不同专病库的日志进行定向输出
2. 应用启动时的一些(包含数据库查询)任务无法执行,因为那时还没有 lookup key
3. 用户统一登录需要专门处理,而不是基于各个专病库。这个相对来说不是什么问题第一点我不知道是不是有办法做到,有个变通的方式就是使用 log4j MDC 将 sessionId 加到日志语句中,通过 ELK 这样的工具可以选择具体的会话日志进行错误诊断。第二三两点都比较好处理,需要我们再梳理下相关代码。但是总体上,如果此方案被采用,可以大大减轻实施人员的部署成本。
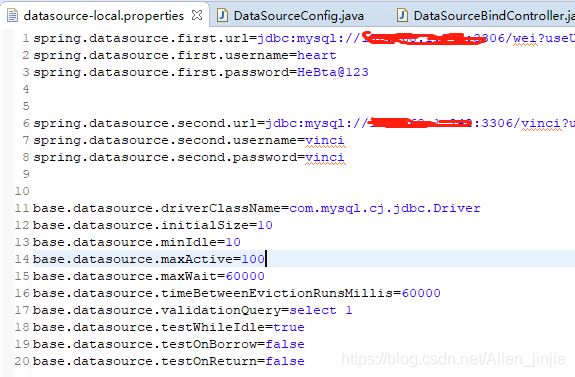
数据源配置代码:
@Configuration
//扫描 Mapper 接口并容器管理
@PropertySource("classpath:datasource-${spring.profiles.active}.properties")
@MapperScan(basePackages = {"com.hebta.vinci.code.mapper"}, sqlSessionFactoryRef = "baseSqlSessionFactory")
public class DataSourceConfig {
// 精确到 base 目录,以便跟其他数据源隔离
private static final String MAPPER_LOCATION = "classpath:mybatis/mapper/*Mapper.xml";
@Value("${spring.datasource.first.url}")
private String url;
@Value("${spring.datasource.first.username}")
private String user;
@Value("${spring.datasource.first.password}")
private String password;
@Value("${spring.datasource.second.url}")
private String second_url;
@Value("${spring.datasource.second.username}")
private String second_user;
@Value("${spring.datasource.second.password}")
private String second_password;
@Value("${base.datasource.driverClassName}")
private String driverClass;
@Value("${base.datasource.initialSize}")
private int initialSize;
@Value("${base.datasource.minIdle}")
private int minIdle;
@Value("${base.datasource.maxActive}")
private int maxActive;
@Value("${base.datasource.maxWait}")
private int maxWait;
@Value("${base.datasource.timeBetweenEvictionRunsMillis}")
private int timeBetweenEvictionRunsMillis;
@Value("${base.datasource.validationQuery}")
private String validationQuery;
@Value("${base.datasource.testWhileIdle}")
private boolean testWhileIdle;
@Value("${base.datasource.testOnBorrow}")
private boolean testOnBorrow;
@Value("${base.datasource.testOnReturn}")
private boolean testOnReturn;
public DataSource firstDataSource() {
DruidDataSource dataSource = new DruidDataSource();
dataSource.setUrl(url);
dataSource.setUsername(user);
dataSource.setPassword(password);
initParams(dataSource);
return dataSource;
}
public DataSource secondDataSource() {
DruidDataSource dataSource = new DruidDataSource();
dataSource.setUrl(second_url);
dataSource.setUsername(second_user);
dataSource.setPassword(second_password);
initParams(dataSource);
return dataSource;
}
private void initParams(DruidDataSource dataSource) {
dataSource.setDriverClassName(driverClass);
dataSource.setInitialSize(initialSize);
dataSource.setMinIdle(minIdle);
dataSource.setMaxActive(maxActive);
dataSource.setMaxWait(maxWait);
dataSource.setTimeBetweenEvictionRunsMillis(timeBetweenEvictionRunsMillis);
dataSource.setValidationQuery(validationQuery);
dataSource.setTestWhileIdle(testWhileIdle);
dataSource.setTestOnBorrow(testOnBorrow);
dataSource.setTestOnReturn(testOnReturn);
}
@Bean("customDS")
public DataSource customDS() {
CustomDataSource dataSource = new CustomDataSource();
Map targetDataSources = new HashMap<>();
targetDataSources.put("first", firstDataSource());
targetDataSources.put("second", secondDataSource());
dataSource.setTargetDataSources(targetDataSources);
return dataSource;
}
@Bean(name = "baseTransactionManager")
public DataSourceTransactionManager baseTransactionManager() {
return new DataSourceTransactionManager(customDS());
}
@Bean
@ConfigurationProperties(prefix = "mybatis.configuration")
public org.apache.ibatis.session.Configuration globalConfiguration() {
return new org.apache.ibatis.session.Configuration();
}
@Bean(name = "baseSqlSessionFactory")
public SqlSessionFactory baseSqlSessionFactory(@Qualifier("customDS") DataSource customDS,
org.apache.ibatis.session.Configuration configuration) throws Exception {
final SqlSessionFactoryBean sessionFactory = new SqlSessionFactoryBean();
sessionFactory.setDataSource(customDS);
PathMatchingResourcePatternResolver resolver = new PathMatchingResourcePatternResolver();
Resource[] apiRes = resolver.getResources(DataSourceConfig.MAPPER_LOCATION);
List res = new ArrayList<>(Arrays.asList(apiRes));
sessionFactory.setMapperLocations(res.toArray(new Resource[apiRes.length]));
sessionFactory.setConfiguration(configuration);
return sessionFactory.getObject();
}
}