ubuntu虚拟机下搭建zookeeper集群,安装jdk压缩包,搭建Hadoop集群与spark集群的搭建【下篇】
系列文章目录
Hadoop与主机连接以及20版本的Hadoop配置网络的问题_hadoop连不上网
Hadoop升级update命令被锁定的解决方法_hadoop重新初始化被锁住怎么办
虚拟机vmware下安装Ubuntu16.04修改屏幕尺寸与更新源,以及对应的安装vim和vim常见的操作命令
文章目录
前言
一、上篇文章链接
二、hadoop的配置
2.1、上传:scp hadoop-2.7.1.tar.gz [email protected]:/home/hadoop/
2.2、解压Hadoop文件:Tar -zxvf Hadoop-2.7.1.tar.gz
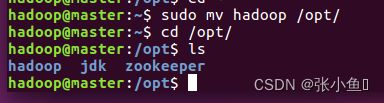
2.3、移动Hadoop到opt目录:sudo mv Hadoop-2.7.1 /opt/
2.4、分发环境变量
三、在集群上面配置Hadoop环境变量
3.1、配置Hadoop-env.sh文件
3.2、配置core-site.xml文件:vim core-site.xml
3.3、配置hdfs-site.xml文件:vim hdfs-site.xml
3.4、配置yarn-env.sh (yarn基本运行环境)
3.5、配置yarn-site.xml
3.7、配置mapred-site.xml文件:vim mapred-site.xml
3.8、分发环境变量配置文件,先删除已经存在的Hadoop
3.9、在master节点上面格式化namenode(不可在其他节点上面进行)启动hdfs和yarn
3.10、启动mr-jobhistory-daemon.sh
3.11、Web页面
3.12、集群关闭
四、配置spark集群环境
4.1、上传:scp spark-2.4.0-bin-without-hadoop.tgz [email protected]:/home/hadoop/
4.2、查看之后解压缩:tar zxvf spark-2.4.0-bin-without-hadoop.tgz
4.3、解压缩之后查看,然后修改名称:sudo mv spark-2.4.0-bin-without-hadoop/ spark
4.4、配置Vim.bashrc
4.5、修改名称:mv spark-env.sh.template spark-env.sh
4.6、修改spark-defaults.conf文件
4.7、修改spark-env.sh文件
4.8、修改slaves文件
4.9、分发spark环境
4.10、群起spark
4.11、修改原来的8080端口,避免与master端口重合,修改start-master.sh文件
4.12、修改原来的start-all.sh为start-spark-all.sh与stop-all.sh为stop-spark-all.sh
4.13、启动spark的节点
4.14、Web页面
4.15、停止spark节点
4.16、停止其他节点:
总结
前言
本篇主要介绍配置Hadoop集群和spark集群搭建,在ubuntu虚拟机下搭建zookeeper集群,安装jdk压缩包在上篇已经介绍了,此处不做赘述。
一、上篇文章链接
ubuntu虚拟机下搭建zookeeper集群,安装jdk压缩包,搭建Hadoop集群与spark集群的搭建
二、hadoop的配置
2.1、上传:scp hadoop-2.7.1.tar.gz [email protected]:/home/hadoop/
![]()
2.2、解压Hadoop文件:Tar -zxvf Hadoop-2.7.1.tar.gz

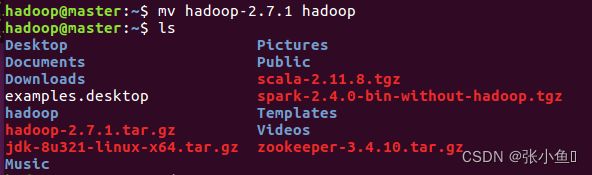
2.3、移动Hadoop到opt目录:sudo mv Hadoop-2.7.1 /opt/
重新命名:sudo mv Hadoop-2.7.1/ Hadoop
#配置Hadoop环境变量
export HADOOP_HOME=/opt/hadoop
export CLASSPATH=.:$HADOOP_HOME/lib
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
配置完成之后重启source .bashrc
2.4、分发环境变量

进入salve1里面,进入zkdata里面,删除下面的那些:salve2也是一样的操作
检查是否启动成功:zkserver.sh start
关闭zookeeper进程:另外两个也一样关闭的命令:zkServer.sh stop
三、在集群上面配置Hadoop环境变量
3.1、配置Hadoop-env.sh文件
vim.bashrc编写对应得Hadoop配置语句,三个虚拟机全部配置,保存,配置完成之后,source .bashrc使其生效,可以使用whereis java查看我们配置Java的地址
export JAVA_HOME=${JAVA_HOME}
export JAVA_HOME=/OPT/JAVA/jdk

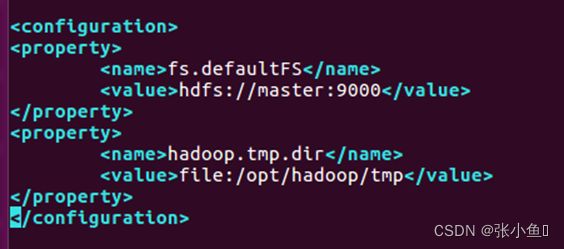
3.2、配置core-site.xml文件:vim core-site.xml
fs.defaultFS
hdfs://master:9000
hadoop.tmp.dir
file:/opt/hadoop/tmp
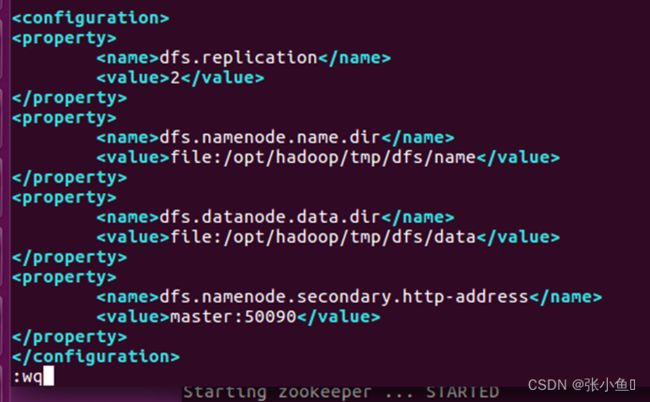
3.3、配置hdfs-site.xml文件:vim hdfs-site.xml
【修改的是第一个value的值为ip地址,第二个value为2】
dfs.replication
2
dfs.namenode.name.dir
file:/opt/hadoop/tmp/dfs/name
dfs.datanode.data.dir
file:/opt/hadoop/tmp/dfs/data
dfs.http.address
192.168.80.140:50070
-->
dfs.namenode.secondary.http-address
Master:50090
 3.4、配置yarn-env.sh (yarn基本运行环境)
3.4、配置yarn-env.sh (yarn基本运行环境)
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64

3.5、配置yarn-site.xml
yarn.resourcemanager.hostname
Master
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.resource.memory-mb
2048
yarn.nodemanager.resource.cpu-vcores
1
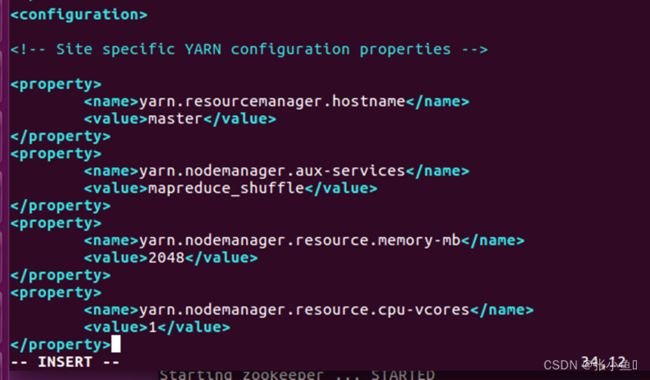
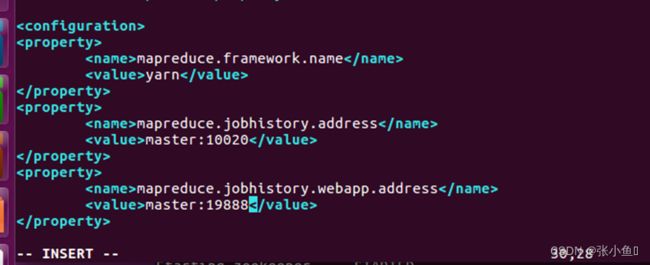
3.7、配置mapred-site.xml文件:vim mapred-site.xml
【此处先复制一份,再编辑】
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
master:10020
mapreduce.jobhistory.webapp.address
master:19888
<--19888是HTTP服务端口,10020是处于jobhistoryserver节点用于IPC的端口—>
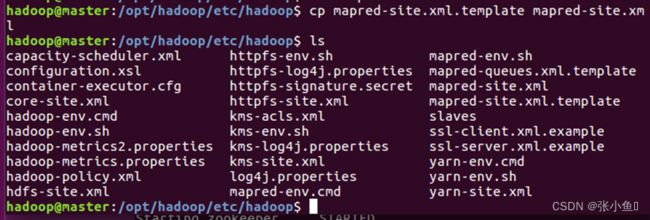
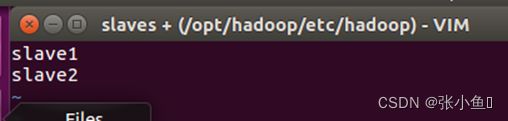
配置slaves文件,配置datanode节点,将datanode节点的主机名注册到salves文件里面配置的是salve1和salve2节点
3.8、分发环境变量配置文件,先删除已经存在的Hadoop
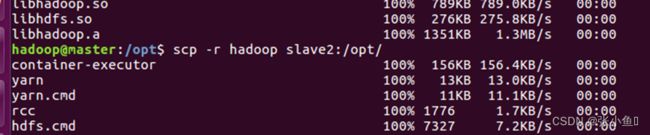
在master里面的opt目录之下,远程连接salve1的opt目录:scp -r Hadoop salve-1:/opt/
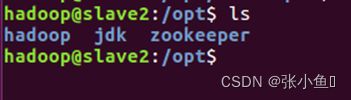
远程连接salve2的opt目录:scp -r Hadoop salve-2:/opt/,之后进入到另外两台虚拟机的opt目录下面查看是否配置Hadoop和Java成功,ls查看一下。


3.9、在master节点上面格式化namenode(不可在其他节点上面进行)启动hdfs和yarn

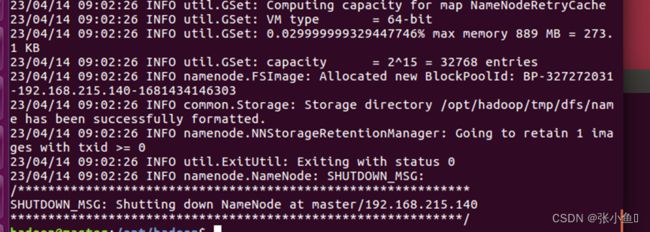
3.10、启动mr-jobhistory-daemon.sh
sbin/mr-jobhhistory-daemon.sh start historyserver
之后其他两台虚拟机上面jps查看
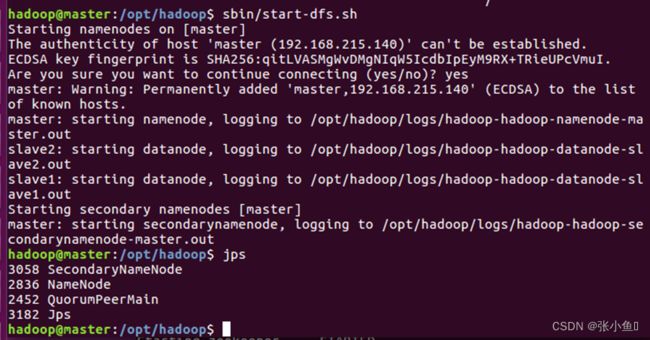
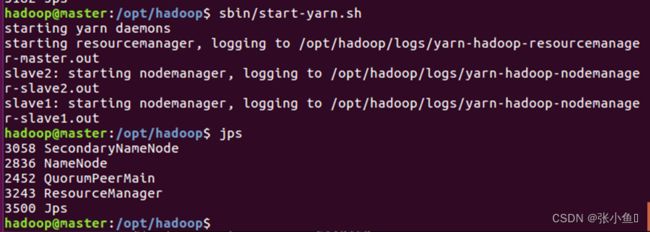
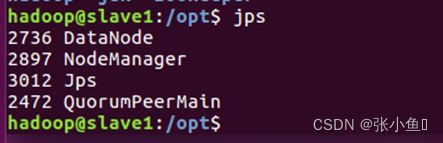
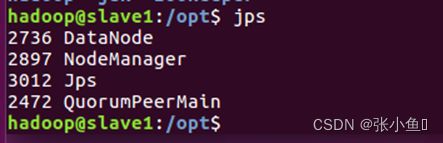
3.11、Web页面
http://master:8088
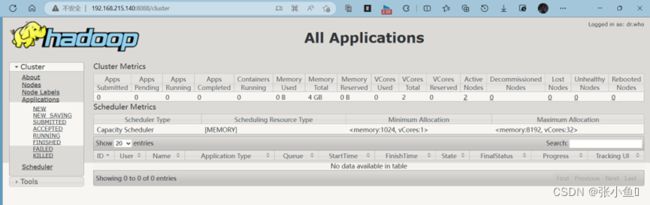
管理界面:http://localhost:8088
NameNode界面:http://localhost:50070
HDFS NameNode界面:http://localhost:8042
3.12、集群关闭
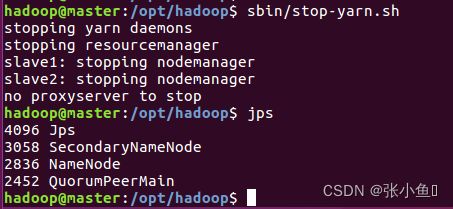
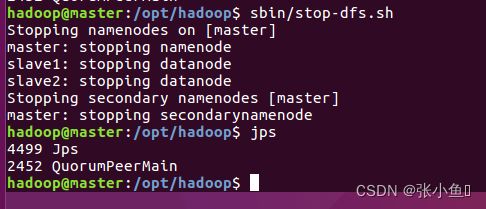
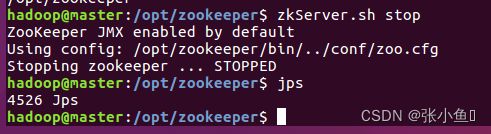
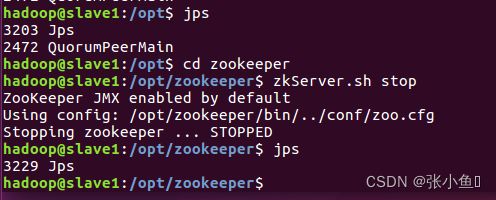
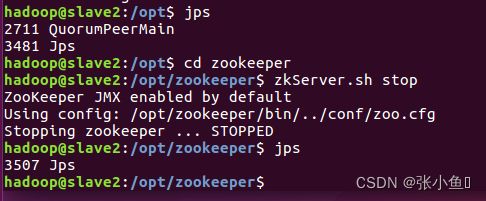
四、配置spark集群环境
4.1、上传:scp spark-2.4.0-bin-without-hadoop.tgz [email protected]:/home/hadoop/
![]()
4.2、查看之后解压缩:tar zxvf spark-2.4.0-bin-without-hadoop.tgz
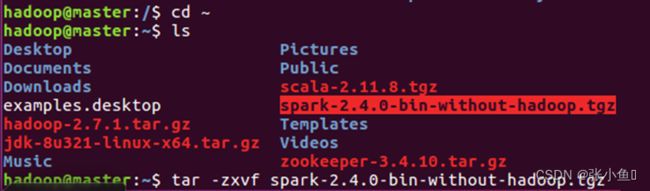
4.3、解压缩之后查看,然后修改名称:sudo mv spark-2.4.0-bin-without-hadoop/ spark
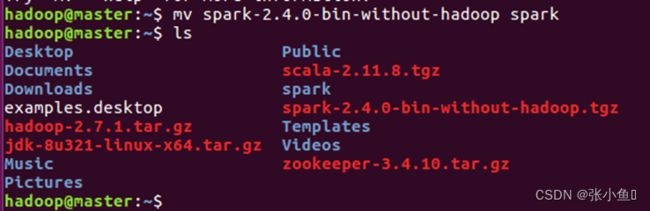
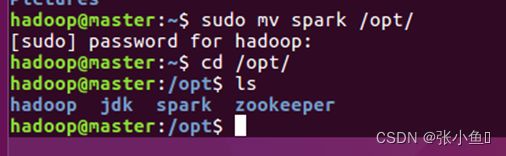
查看用户权限:此处就是在hadoop用户权限之下,不做修改
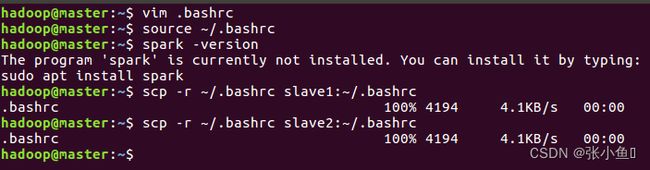
4.4、配置Vim.bashrc
编辑内容如下:


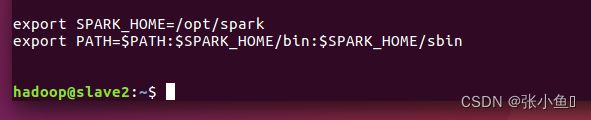
进入saprk,可以看到spark的配置文件在conf文件里面
4.5、修改名称:mv spark-env.sh.template spark-env.sh
复制一下:cp spark-env.sh spark-env.bak



4.6、修改spark-defaults.conf文件
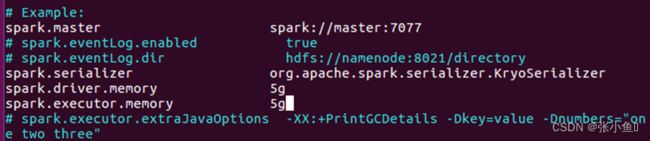
4.7、修改spark-env.sh文件
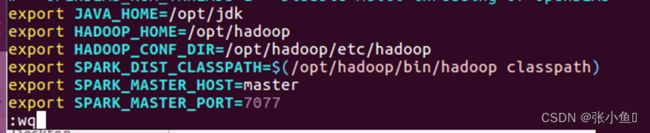
4.8、修改slaves文件
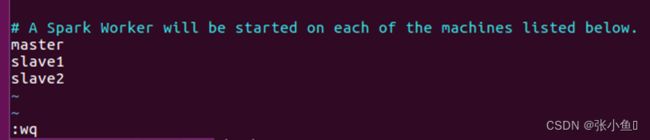
4.9、分发spark环境
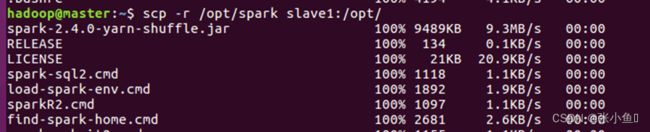

4.10、群起spark
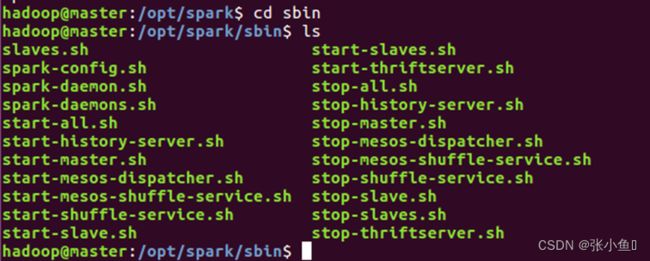
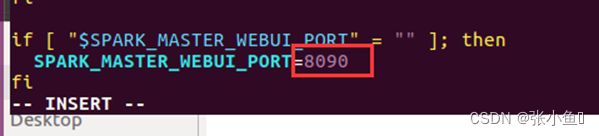
4.11、修改原来的8080端口,避免与master端口重合,修改start-master.sh文件
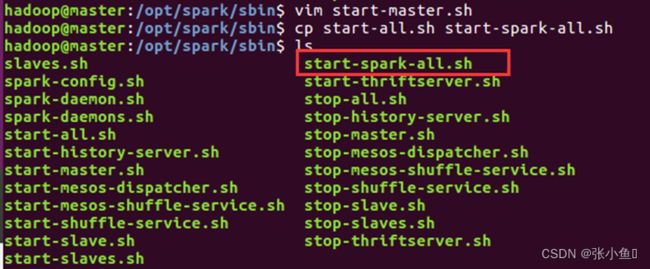
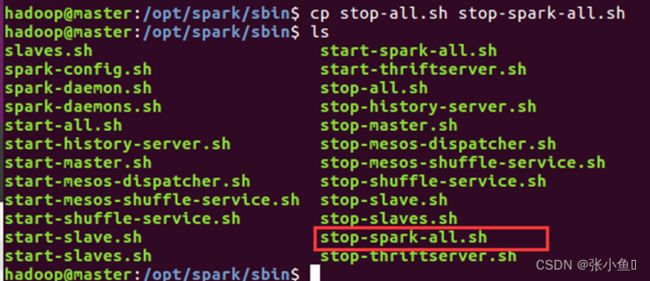
4.12、修改原来的start-all.sh为start-spark-all.sh与stop-all.sh为stop-spark-all.sh
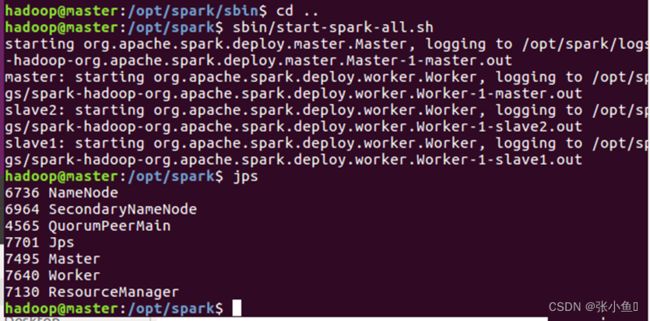
4.13、启动spark的节点
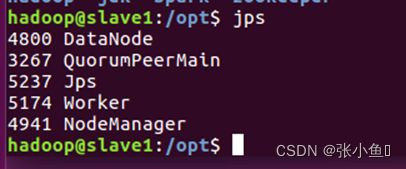
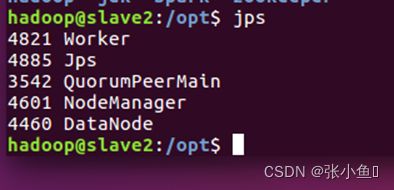
4.14、Web页面
http://master:8090
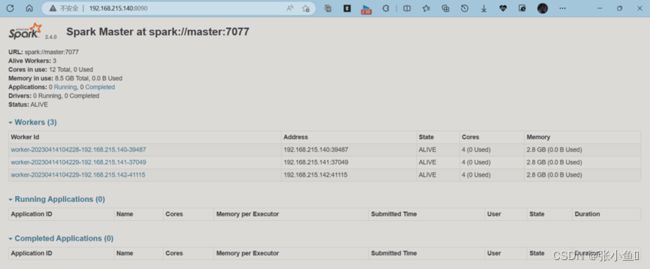
4.15、停止spark节点
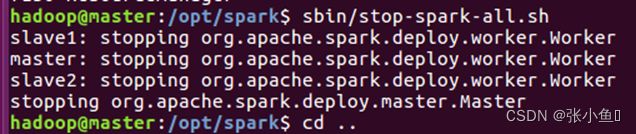
4.16、停止其他节点:
总结
大家在配置过程要书写正确的语句,要细心一点才不会出错奥~
以上就是今天的内容喽~
最后欢迎大家点赞,收藏⭐,转发,
如有问题、建议,请您在评论区留言哦。