x86汇编语言基础(AT&T语法)
0 背景
之前自学了王爽老师的《汇编语言》一书,作为初学者学习汇编语言,这是一本很好的入门书籍,对学习操作系统或者编译器的底层机制是有很大帮助的,但是不足是,这本书还停留在16位的8086汇编的阶段,而现在的操作系统都是跑在32位或64位的保护模式,所以想要实用些,还是要深入研究下。之前又学习了些x86的AT&T(常用的还有Intel格式)语法基础,也有在之前的博客中展示过,想着把这些分享下,也算自己复习下咯。
1 编译汇编文件
gcc -S xxx.c -o xxx.s
随便写个C代码:
#include gcc -S assembly.c -o assembly.s.打开来看,可能有点懵逼,没关系,跳过,后面一点点介绍,回头学习完再来看。
.file "assembly.c"
.text
.section .rodata
.LC0:
.string "%d\n"
.text
.globl main
.type main, @function
main:
.LFB0:
.cfi_startproc
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
subq $16, %rsp
movl $1, -4(%rbp)
movl $1, -8(%rbp)
movl -4(%rbp), %edx
movl -8(%rbp), %eax
addl %edx, %eax
movl %eax, -12(%rbp)
movl -12(%rbp), %eax
movl %eax, %esi
movl $.LC0, %edi
movl $0, %eax
call printf
movl -12(%rbp), %eax
leave
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE0:
.size main, .-main
.ident "GCC: (GNU) 8.3.1 20190507 (Red Hat 8.3.1-4)"
.section .note.GNU-stack,"",@progbits
另外,同样C++也可以g++指令实现。
2寄存器
在汇编世界里,主要通过汇编指令来操纵寄存器和内存地址,来实现程序的。
2.1寄存器的位数
在王爽的《汇编语言》见过ax、ah/al寄存器,这时16bit和高低8bit的寄存器,在目前的x86-64架构中会见到eax、和rax,分别对应32bit,64bit寄存器。
方便记忆:
a:accumulator 累加
h/l:high/low 高低
e:extend 扩展
r:register 寄存器?找个猜的不对
2.2 通用寄存器
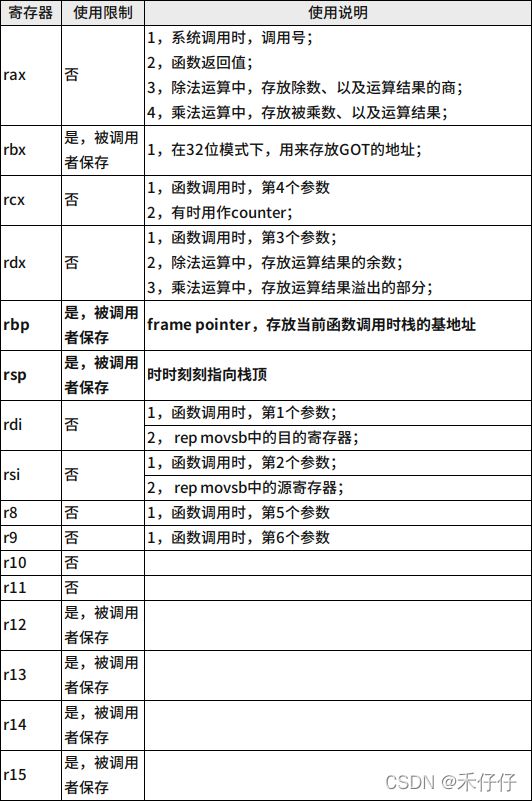
目前的CPU可能有上百个实际的物理寄存器。当然了,对软件开发人员来说,我们只需要关注逻辑上的通用寄存器。这里以64bit寄存器为例,其他同理。
如下所示:
3指令说明
3.1 基本说明
1、前缀
AT&T 汇编中:
- 寄存器前被冠以“%”
- 立即数前被冠以“$”
- 十六进制数前被冠以“0x”
2、后缀
操作码的后缀一般表示操作码的位数,l代表32位,w代表16位,b代表8位。
例如汇编中常见的
movl就是操作32位寄存器,movb是8bit。
3、操作数方向
操作数的方向和intel有点不一样,比如把立即数$0x13放到寄存器%ah中,用的是movb $0x42,%ah,即源操作数在前,目的操作数在后,这一点和intel汇编语法正好相反。
对于内存单元操作数来说,在AT&T 中是把寄存器用()括起来,而非[]。
举例说明
movl 0x13, %ebx
movl %ebx, 8(%si)
前后缀就不说了,这里将立即数0x13放入寄存器ebx,后面一句是将ebx寄存器里的值放到内存地址是8(%si)的内存单元上。
另外,AT&T间接寻址方式是有别于intel汇编的,上例中的8(%si)就相当于intel汇编中的[si+8]。
3.2 常用指令
1、运算指令
常见的指令如下:
addl %edx, %eax //edx+eax,结果放到eax l表示32位,后面指令位64位
add $5,%r10 // 5 + r10,结果放到r10
div %r10 //rax 除以r10,商放到rax,余数放到rdx
inc %r10 // r10 加1
mul %r10 // 将rax乘以 r10, 将结果放到rax中,溢出部分放到rdx
2、拷贝指令
拷贝有从寄存器到寄存器、从寄存器到内存
mov %r10,%r11 //将r10寄存器的值赋值给r11 ;
mov $99,%r10 //将立即数99赋值给r10寄存器;
mov %r10,(%r11) // 将r10的值拷贝到r11寄存器中的数值指向的内存地址上;
mov (%r10),%r11 // 将r10中数值指向的内存地址上的内容拷贝到r11;
push %r10 // 将r10的值放到栈上 ;
pop %r10 // 将栈顶的值pop到r10寄存器上。
3、流程控制指令
任何一种高级语言都有流程控制的关键词,同样对应汇编也有。这里主要介绍汇编的跳转指令和标签,我们这里看一段汇编代码:
cmpb $GRUB_INVALID_DRIVE,%al
je 1f
movb %al,%dl
1:
pushw %dx
首先这里就用到了标签,和跳转指令。其中:
- 1就是标签label
- comb,表示8bit的的比较操作,
cmpb $GRUB_INVALID_DRIVE,%al表示,比较立即数GRUB_INVALID_DRIVE和al(ax低8bit)存储的数字 - je 1f是跳转指令。
j:jump e:equal表示前面两数比较,如果相等,就跳转到label1的位置。 - 1f 1是标签,
f:forward这里表示向前寻找标签1,如果是b:backward表示向后寻找。当有重复存在时使用,一般自动编译不会重复,自己写汇编可以这么用。
下面列举几个常见的跳转指令:
cmp %r10,%r11 // 比较r10 和 r11,根据比较结果来设置CPU的状态寄存器,从而影响后面的jump语句;
cmp $99,%r11 // 比较99和r11,根据比较结果来设置CPU的状态寄存器,从而影响后面的jump语句;
jmp label //跳转到label
je label //如果相等,跳转到label
jne label // 如果不相等,跳转到label
jl label // 如果小于,跳转到label
jg label // 如果大于,跳转到label
call label // 调用函数
ret // 从函数调用返回
syscall //系统调用 (32位模式下, 使用"int $0x80" 软中断)
4、汇编指示符(assembler directive)
编译出的汇编文件的开始处,有一段由句号('.') 开头的指令,这些就是“AT&T 汇编指示符”了。这里命令名的其余是字母,通常使用小写。这些不会被翻译成机器指令,而是给汇编器一些特殊指示,称为汇编指示(Assembler Directive)或伪操作(Pseudo-operation)。
我们来看几个常见的:
- 1,.byte 表达式(expression_rs)
.byte可不带参数或者带多个表达式参数,表达式之间由逗点分隔。每个表达式参数都被汇编成下一个字节。在stage1.s中,有这么一段代码:
after_BPB:
CLI
.byte 0x80,0xca
那么编译器在编译时,就会在cli指令的下面接着放上0x80和0xca,因为每个表达式要占用1个字节,所以此处一共占用2个字节。
- 2,.word 表达式
这个表达式表示任意一节中的一个或多个表达式(同样用逗号分开),表达式占一个字(两个字节)。类似的还有.long。例:
.word 0x800
- 3,.file 字符(string)
.file 通告编译器我们准备开启一个新的逻辑文件。 string 是新文件名。总的来说,文件名是否使用引号‘"’都可以;但如果您希望规定一个空文件名时,必须使用引号""。本语句将来可能不再使用—允许使用它只是为了与旧版本的as编译器程序兼容。在as的一些配置中,已经删除了.file以避免与其它的汇编器冲突。例如stage1.s中:
.file ”stage1.s”
- 4,.text 小节(subsection)
通知as编译器把后续语句汇编到编号为subsection的正文子段的末尾,subsection是一个纯粹的表达式。如果省略了参数subsection,则使用编号为0的子段。例:
.text
- 5,.code16
告诉编译器生成16位的指令
- 6,.globl
.globl使得连接程序(ld)能够看到symbol,如果gemfield在局部程序中定义了symbol,那么与这个局部程序链接的局部程序也能存取symbol,例:
.globl SYMBOL_NAME(idt)
定义idt为全局符号。
- 7,.fill repeat , size , value
repeat, size 和value都必须是纯粹的表达式。本命令生成size个字节的repeat个副本。Repeat可以是0或更大的值。Size 可以是0或更大的值, 但即使size大于8,也被视作8,以兼容其它的汇编器。各个副本中的内容取自一个8字节长的数。最高4个字节为零,最低的4个字节是value,它以as正在汇编的目标计算机的整数字节顺序排列。每个副本中的size个字节都取值于这个数最低的size个字节。再次说明,这个古怪的动作只是为了兼容其他的汇编器。size参数和value参数是可选的。如果不存在第2个逗号和value参数,则假定value为零。如果不存在第1个逗号和其后的参数,则假定size为1。
例如,在linux初始化的过程中,对全局描述符表GDT进行设置的最后一句为:
.fill NR_CPUS*4,8,0
意思是.fill给每个cpu留有存放4个描述符的位置,并且每个描述符是8个字节。不过要注意的是,这种包含程序已初始化数据的节(.data)和包含程序程序还未初始化的数据的节(.bss),编译器会把它们在4字节上对齐,例如,.data是25字节,那么编译器会将它放在28个字节上。当这种以后缀名.s编写的A T&T格式的汇编代码完成后,就是编译和链接了。
也并不是所有汇编文件都包含这些指示符,这里的指示符也仅仅是常见的一部分。
现在回过头来看最开始的汇编是不是很清晰了呢?
4 栈操作
回到汇编代码,看到在每个汇编代码块的开始都有两句一样的汇编指令:(代码块没有汇编格式,用了C风格注释)
pushl %ebp //将调用者的栈底部地址保存起来
movl %esp, %ebp //将调用者的栈顶部地址,设置为本栈帧的底部
subq $16, %rsp //为变量申请内存空间, 开辟了16字节
其实这两句可以理解是保存上一个函数(这里是main函数)的栈底指针,然后从新开始一个新的栈。
另,栈操作可参考:
《计算机是如何工作的——汇编代码分析》
Debug一个C语言加法程序
这里只是将我所学的一些基础语法,分享出来,对于基本的阅读汇编语言应该问题不大,但是想要深入学习,特别是要写汇编语言或者优化代码的同学来说,是远不够的。
另外错误或不足,还请大家多多指出,共同学习进步。