〖Python网络爬虫实战⑪〗- 正则表达式实战(二)
- 订阅:新手可以订阅我的其他专栏。免费阶段订阅量1000+
python项目实战
Python编程基础教程系列(零基础小白搬砖逆袭)
- 说明:本专栏持续更新中,目前专栏免费订阅,在转为付费专栏前订阅本专栏的,可以免费订阅付费专栏,可报销(名额有限,先到先得)。
- 作者:爱吃饼干的小白鼠。Python领域优质创作者,2022年度博客新星top100入围,荣获多家平台专家称号。
最近更新
〖Python网络爬虫实战⑦〗- requests的使用(一)
〖Python网络爬虫实战⑧〗- requests的使用(二)
〖Python网络爬虫实战⑨〗- 正则表达式基本原理〖Python网络爬虫实战⑩〗- 正则表达式实战(一)
上节回顾
上一节我们先通过一个简单的小案例,来学习正则表达式是如何使用的。学会了如何使用正则表达式,本文,我们通过一个图片网站,我们来练习正则表达式的使用。
⭐️正则表达式实战(一)
环境使用
- python 3.9
- pycharm
模块使用
- requests
模块介绍
- requests
requests是一个很实用的Python HTTP客户端库,爬虫和测试服务器响应数据时经常会用到,requests是Python语言的第三方的库,专门用于发送HTTP请求,使用起来比urllib简洁很多。
- re
re模块是python独有的匹配字符串的模块,该模块中提供的很多功能是基于正则表达式实现的,而正则表达式是对字符串进行模糊匹配,提取自己需要的字符串部分,他对所有的语言都通用。
模块安装问题:
- 如果安装python第三方模块:
win + R 输入 cmd 点击确定, 输入安装命令 pip install 模块名 (pip install requests) 回车
在pycharm中点击Terminal(终端) 输入安装命令
- 安装失败原因:
- 失败一: pip 不是内部命令
解决方法: 设置环境变量
- 失败二: 出现大量报红 (read time out)
解决方法: 因为是网络链接超时, 需要切换镜像源
清华:https://pypi.tuna.tsinghua.edu.cn/simple 阿里云:https://mirrors.aliyun.com/pypi/simple/ 中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple/ 华中理工大学:https://pypi.hustunique.com/ 山东理工大学:https://pypi.sdutlinux.org/ 豆瓣:https://pypi.douban.com/simple/ 例如:pip3 install -i https://pypi.doubanio.com/simple/ 模块名
- 失败三: cmd里面显示已经安装过了, 或者安装成功了, 但是在pycharm里面还是无法导入
解决方法: 可能安装了多个python版本 (anaconda 或者 python 安装一个即可) 卸载一个就好,或者你pycharm里面python解释器没有设置好。
案例实战
我们前面通过一个简单的网站,学习了正则表达式。今天,我们来通过官方的网站,我们来获取其简单的数据,我们就用我们刚刚学习的正则表达式来获取,当然,我们也可以使用xpath和css获取,这个我们以后也会教学的。下面就按照爬虫的思路,一步一步的进行。
✨一、发送请求
进入主页后,我们随便点击一个标签,我们已这个为例,其他的思路一样,后面,你会发现网址差不多,只要改部分内容即可。
import requests
url = 'https://wallhaven.cc/toplist' #toplist是可以改动的
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}
response = requests.get(url=url,headers=headers)
print(response) 这段代码将使用 requests 模块来获取 https://wallhaven.cc/toplist 网站上的数据。首先,它定义了一个变量 url,它将用于构建 HTTP 请求的 URL。接下来,它定义了一个字典 headers,它将用于设置 HTTP 请求的头部。最后,它使用 requests.get() 函数来发送 HTTP 请求,并将 response 变量作为参数传递。最后,它打印出 response 变量的值。
运行之后,会返回
知识穿插
有的同学就好奇了,为什么加headers。为什么上一篇没有加,这里就加了。因为,绝大多数网站都有反爬措施,比如,对请求头的检查,看你是浏览器还是爬虫程序。这里,我们还是用上一篇的代码,不加请求头,访问另外一个网站,看看能不能得到我们想要的数据。
import requests
url = 'https://ssr2.scrape.center/'
res = requests.get(url)
print(res)我们运行之后就会报错。
requests.exceptions.SSLError: HTTPSConnectionPool(host='ssr2.scrape.center', port=443): Max retries exceeded with url: / (Caused by SSLError我们加上请求头,就可以正常获取数据,相信这个案例对比,可以加深大家的印象。
✨二、获取数据
我们用开发者工具,查找我们要的源代码。
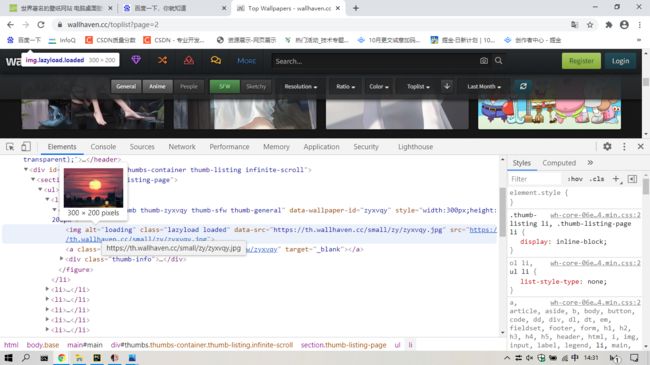
这样,我们就找到了源地址,一个是小图(分辨率比较低),一个是图片真实的网址(高分辨率),这里我们用正则表达式去匹配它。
html_url = re.findall('class="preview" href="(.*?)"',response.text,re.S) 这段代码将使用正则表达式 re.findall() 在 HTTP 响应中查找所有类名为 preview 的链接,并将其返回给变量 html_url。正则表达式的模式 'class="preview" href="(.*?)"' 其中,class="preview" 表示链接的类名为 preview,href="(.*?)" 表示链接的 URL 为任意字符串,.*? 表示匹配任意数量的任意字符,但是尽可能少地匹配。re.S 表示换行匹配。
通过观察我们发现,所有图片的源地址的位置都差不多。这样我们就获得了图片原网页的列表。
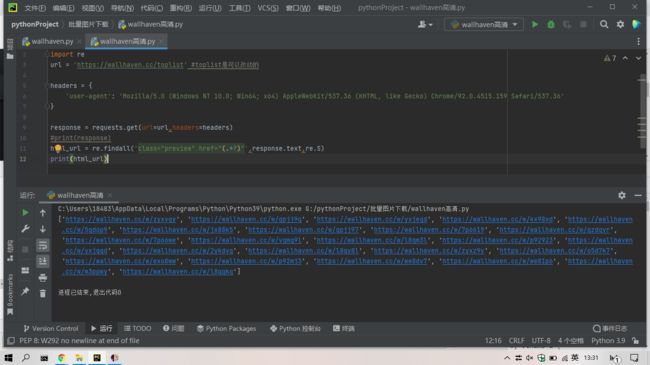
总结
大家就会发现我们就把每个链接地址获取了下来。正则表达式是不是很神奇。大家可以尝试获取其他的数据。我们获取到了图片地址,我们还可以保存下来,在后面的教学过程中,会教大家如何保存下来,这里重点是练习正则表达式。
