### 论文精读——An Attention Enhanced Graph Convolutional LSTM Network for Skeleton-Based Action Recogniti
论文精读——IIP-Transformer: Intra-Inter-Part Transformer for Skeleton-Based Action Recognition
近期在做基于关键点的人体动作识别研究,调研了几篇基于transformer架构的 skeleton based action recognition 方面的文章,并且进行一个精读。
其中选取的一篇论文题为:IIP-Transformer: Intra-Inter-Part Transformer for Skeleton-Based Action Recognition,来自AIbee 一个AI公司,学生作者分别为北交大和南大的同学。最近刚刚发布在Arxiv上,应该还是在投状态。
个人认为这篇文章的质量还是比较高的, 起码对于我来说不仅具有创新性,还有很大的启发性(文章设计的具体步骤,方式思路,以及一些消融实验真的都非常有趣)
#############################################################################
文章来源
题目:IIP-Transformer: Intra-Inter-Part Transformer for Skeleton-Based Action Recognition
链接&下载地址:
论文地址: https://arxiv.org/abs/2110.13385
一些相关连接:
开源代码:
目前该算法暂无开源代码
paper with code :https://paperswithcode.com/paper/iip-transformer-intra-inter-part-transformer
#############################################################################
1. 简单说背景
目前基于骨骼关键点的动作识别问题(skeleton based action recognition)经过了3DCNN、 2stream 、LSTM的baseline模型阶段, 在过去的两年左右时间内,基本上是以GCN(图卷积网络)为baseline 进行解决的。标志性的文章就是 19年的ST-GCN(这个应该不用多讲,网络上随便搜一下就有很多解析)。
ST-GCN 可以视为 GCN 结构解决关键点识别问题的“开创者”,这点是毋庸置疑的,因为它不仅仅贡献了一个网络,而是构建了关键点序列拓扑图的一种架构范式,将其转化成CNN 从而直接进行卷积等特征提取操作,从而使得很多CNN的trick以及模块 得以复制和使用到关键点动作识别中。自此之后,大量的基于GCN 的工作得以展开,非常多网络得以提出,也极大的提升了数据集的指标。
基于GCN 的总体思路是将骨骼时序点理解成拓扑学中的图(graph)的概念, 利用构建关系矩阵,将没有空间关系的关键点转化为矩阵的形式,从而将每个点的坐标以参数信息的形式表现出来, 可以直接转化成“图片” (图片是:C x H x W,关键点是C x T x V )这种形式,也霸占了主流公开数据集中的SOTA 文章。这点要说明一下,SOTA中还有一个比较特殊的:港中文提出的PoseC3D 是使用了基于heatmap 的3DCNN结构,结构相当简洁,实验相当多,性能相当好,也是比较bug 的存在。。
随着attention 注意力机制的提出,transformer 的提出以及不断发展,目前已经在NLP界达到了统治地位,目前也已经进军CV 界,大有一统CV 和Transformer 的趋势。2020年 ViT 被提出,创建了CV任务的新范式。 既然骨骼点序列跟图片的形式比较像,自然也有利用transformer解决骨骼点序列的任务。 最早提出的概念的是 ST-TR网络 ,事实上这个还是一个利用了Attention 机制的 GCN 。 随后很快便有很多基于transformer 的文章被提出,并且取得了不错的效果。
2. 摘要
近期,基于transformer 的网络在基于骨架的动作识别任务上展现出了巨大的潜力。捕获全区和局部的依赖关系的能力是transformer优势的所在,但是同时也带来了二次计算与额外的参数以及内存消耗。此外,以往的研究主要集中在单个关节点的关系上,这通常会受到采样质量的或者位姿估计精度以及噪声带来的影响。
为了解决上述问题,本文提出了一种基于transformer的网络——IIP-Transformer。 该网络在利用关键点信息的基础上,还将关键点进行组合成为part,并且在joint 和part 的尺度上都进行了关系的特征提取,从而得到了关节级别(intra-part) 和 part级别(inter-part) 的依赖关系,使得动作是别的任务更加具有效率。
在数据方面,本文提出了一种part-level 的骨架编码方式,这种方式显著的降低了计算的复杂度,并且对joint 的噪声更具鲁棒性。
此外,本文提出了一种新的数据增强方式,用于提升模型性能。
在两个大规模数据集NTU-RGB+D 60和NTU RGB+D 120上,所提出的IIP-Transformer实现了最先进的性能,其计算复杂度比基于SOTA transformer网络的DSTA网络低8倍以上。
3. 关键点总结(亮点&有价值点&问题点)
首先放一下作者自己的总结:
文章的主要贡献:
- 本文将body parts 的概念引入了基于transformer 的 skeleton action recognition 问题中。基于part 而不是 joint 的思想不仅减少了self-attention 的计算复杂度,而且提升了对于关键点的噪声鲁棒性。
- 本文提出了一个基于transformer 的关键点识别网络:IIP-Transformer ,可以分别从时间空间维度提取joint 和part 尺度下的特征关系。
- 本文基于NTU RGB+D 系列下的两个大型公开数据集上达到了 SOTA 级别性能的同时,节省了大量的计算量(2-36倍),取得非常好的综合效果。
记录一些我关注的点
-
在我看来,本篇文章一个关键贡献点之一就是证明了transformer 在骨骼关键点数据上的有效性。事实上如果了解ViT相关知识的人就可以看出,本文跟ViT 的结构是非常像的,里面有很多思想是借鉴ViT 领域的,包括文中也提到了参考的BRIT 。可以进一步提供思路:关键点序列类型的数据从维度上和分布上来说跟图片格式是很相似的,如果GCN 证明了通过某种编码可以让CNN 网络在skeleton based action recognition这个问题上行之有效,那么以本文为代表的 Transformer for skeleton based action recognition 则是证明了transformer(尤其是ViT)的网络结构在解决该问题上也是有效的,而这又表示在前沿的ViT 有很多新提出的工具以及方法可以借鉴,有很多未知领域等待探索(
有很多文章可以水) -
本文除了网络模型以外最让我觉得觉的有趣(惊喜)的是消融实验中的关于截取长度的实验。以NTU RGB-D 数据集为例,如果对skeleton based action recognition比较熟悉的小伙伴们可能会知道,这个系列的数据集(分为60 和 120) 近些年基本是最常见且最base 的公开数据集。这个数据集的动作输入时长是不定的,最长的一个动作有300帧的输入(30帧每秒的话,大概有10 秒?) 所以其他很多模型的输入基本上是取最大值作为输入的。 即 Input shape 是 (batchsize ,channels = 3 ,T = 300 ,V =25 ) 。但是事实上一大部分的动作的长度是根本达不到300 帧的,甚至连一半 的150帧也达不到,这就造成了大量的空数据被填充。 作者做的这个实验中,尝试了改变输入不同时长,并且比较了此因素对于网络的差异。(如下图)

最狗血的是,当输入的帧数为 32时,本文取得了最佳性能。 而超过了更长帧数的性能。
事实证明,并不是帧数越长动作是被的更加准确,相反,在本文所提出的方法中,32帧就已经足够用
(注: 在这里需要说明的一点就是,使用主动的时长删减并不是本文最早提出的。可以注意到上图中的DSTA 就已经有过这方面的尝试并且将关键帧的数量缩小到128。)还有一点想吐槽一下: 本文重点在打的一个点是在网络规模相当的前提下达到了持平甚至更好的精度。 但是我想说的是,模型参数的规模和计算量是和输入的数据有关系的。。 你用32帧的输入去跟别人上百帧的模型去比肯定是参数要更少啊。。 所以在对这一块的描写方面多少有一点避重就轻的嫌疑(
学到了) -
想谈一谈作者本文另一个创新点:Part-based Methods ,即将各关键点进行分区的策略。 事实上也比较有意思。 ViT中的patch embedding本身就是在做reshape 的事情,而作者巧妙的利用了这个环节设计了一种reshape的策略,称为“part ” ,从本质上来说就是进行了一个指定的分组,并没有其他额外的计算操作。但是作者找到了理由并且赋予了其实际的意义,实验结果也证明这个策略的优越性,在我看来是一个比较有趣的设计。
-
另一个比较吸引我的点是作者在本文中提到的 Data Augmentation 部分。作者认为对于先前已经提出的
Rotation, GaussianNoise, GaussianBlur, JointMask 等数据增强的策略,并非完全适用于本文的 part-level ,因此,作者在本文使用的数据增强策略有:1. rotation 2. partmask ,并且希望通过这两个方法提升模型鲁棒性。原理都比较简单易懂,但是的确能起到效果。
4. 网络构建
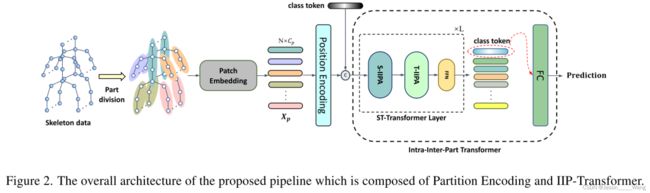
首先看一下网络的结构图:(如上图所示)
网络基于 part 的思想,首先将人体的关键点拆分成了几个part (我可以理解成 躯干 和 肢体),然后根据拆分的情况进行patchembedding,即将三维的数据flatten成2维的patch。 随后在进行一个 position encoding 模块。随后再进行一个class token 的过程(这一步暂时还没有看懂,不知道具体是怎么操作的,如果是模仿ViT添加一个class token 的话应该是在postion embedding 之前),pat数据处理以及patchembedding部分完成,得到了n个代码块。
针对上述的具体流程,作者补充了一个流程图用于说明:

ViT 在解决图像分类问题的时候通常会抛弃掉decoder,因此在我理解通常情况下可以划分成三个步骤:
patch embedding ——》encoder ——》 分类器(classifier)
本文思路相似,在patchembedding 过程结束之后,接下来是encoder 部分:

1111111111111111111111111111111
在编码部分,作者采用了将class token 和 其他token 分开处理的策略(但是从实际具体讲述上来看应该是合并处理的)

经典的self-attention机制:分成qkv 然后有一个res 模块,这部分和 vit 就非常像了,如果想深入了解可以去看ViT。
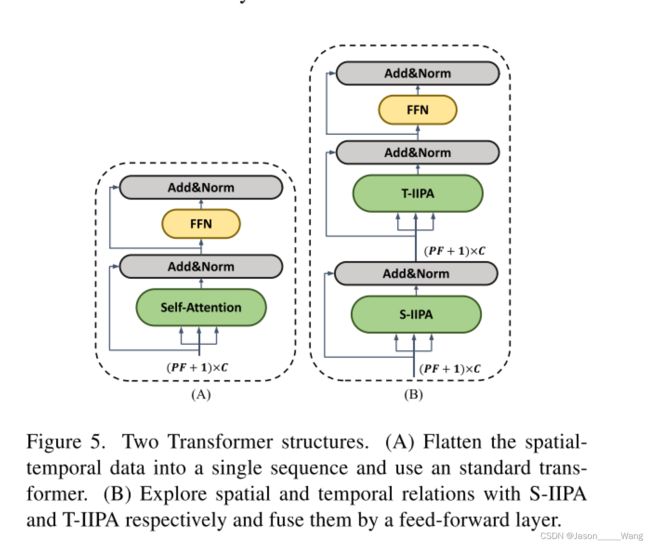
为数不多的区别是: 作者将两个encoder layer 中的一个 FFN 模块删掉然后合并成了一个,在实验中证明这样好像更useful。
在完成了上面两部分的操作之后,接下来就是一个简单的分类器:应该是FC层加上softmax,最后输出动作分类的预测结果。网络部分完事。
5. 实验

- IIPA 的设计实验: 上文中有讲到,IIPA是对标准的vit 做了一个改进,可以简单理解成从 ATTENTION—FFN 作为一个repeat layer,升级为:ATTENTION-S —ATTENTION-T —FFN 作为一个repeat layer ,可以看出,这个改动还是能够提升性能的,我认为这同时也可以理解成减少参数的一种。

- class token 的对比实验,在此证明了class-head 对于分类任务的有效性。

- positin emcoding 同上,也是证明了有效性。但是让我不明白的一点是为什么加了position 的比不加position 的要计算量反而更低了??

-
数据增强的有效性。 比较出乎意料的joint musk 和 part musk 相差的其实比较多。

-
数据输入帧序列长度的对比实验,这个在我看来是很有意思的。
6. 性能比较

直接看图, 在性能方面,无论是GCN系列的方法还是 Transformer系列的方法,作者都有对比,较为综合且全面(少了CTR-GCN和 Pose-C3D 这两个巨头,无疑是一个小小的黑点 哈哈)
同时本文的另一个优势是轻量级的模型,因此作者也毫不避讳的将其列出(毕竟只用32帧做输入,肯定小啊) 可以肯定的是,本网络还是取得了非常不错的效果,再加上transformer这个新兴的议题,希望能够冲击一篇不错的顶会吧。