【译】Rust宏:教程与示例(一) - Rust声明式宏,看完本文就会写!
原文标题:Macros in Rust: A tutorial with examples
原文链接:https://blog.logrocket.com/macros-in-rust-a-tutorial-with-examples/
公众号: Rust 碎碎念
翻译 by: Praying
知乎:https://www.zhihu.com/column/c_1186237256184029184
感谢Praying大佬的翻译。读完此篇教程,你应该就明白如何编写Rust声明式宏了。
下一篇教程:【译】Rust宏:教程与示例(二) - Rust过程宏,看完本文就会写!
在本文中,我们将会涵盖你需要了解的关于 Rust 宏(macro)的一切,包括对 Rust 宏的介绍和如何使用 Rust 宏的示例。
我们会涵盖以下内容:
-
Rust 宏是什么?
-
Rust 宏的类型
-
Rust 宏的声明
-
创建声明式宏
-
Rust 中声明式宏的高级解析
-
从结构体中解析元数据
-
声明式宏的限制
-
Rust 中的过程宏
-
属性式风格宏
-
自定义继承宏
-
函数式风格宏
Rust 宏是什么?
Rust 对宏(macro)有着非常好的支持。宏能够使得你能够通过写代码的方式来生成代码,这通常被称为元编程(metaprogramming)。
宏提供了类似函数的功能,但是没有运行时开销。但是,因为宏会在编译期进行展开(expand),所以它会有一些编译期的开销。
Rust 宏非常不同于 C 里面的宏。Rust 宏会被应用于词法树(token tree),而 C 语言里的宏则是文本替换。
Rust 宏的类型
Rust 有两种类型的宏:
-
声明式宏(Declarative macros)使得你能够写出类似 match 表达式的东西,来操作你所提供的 Rust 代码。它使用你提供的代码来生成用于替换宏调用的代码。
-
过程宏(Procedural macros)允许你操作给定 Rust 代码的抽象语法树(abstract syntax tree, AST)。过程宏是从一个(或者两个)
TokenStream到另一个TokenStream的函数,用输出的结果来替换宏调用。
让我们来看一下声明式宏和过程宏的更多细节,并讨论一些关于如何在 Rust 中使用宏的例子。
Rust 中的声明式宏
宏通过使用macro_rules!来声明。声明式宏虽然功能上相对较弱,但提供了易于使用的接口来创建宏来移除重复性代码。最为常见的一个声明式宏就是println!。声明式宏提供了一个类似match的接口,在匹配时,宏会被匹配分支的代码替换。
创建声明式宏
macro_rules! add{
// macth like arm for macro
($a:expr,$b:expr)=>{
// macro expand to this code
{
// $a and $b will be templated using the value/variable provided to macro
$a+$b
}
}
}
fn main(){
// call to macro, $a=1 and $b=2
add!(1,2);
}
这段代码创建了一个宏来对两个数进行相加。[macro_rules!]与宏的名称,add,以及宏的主体一同使用。
这个宏没有对两个数执行相加操作,它只是把自己替换为把两个数相加的代码。宏的每个分支接收一个函数的参数,并且参数可以被指定多个类型。如果想要add函数也能仅接收一个参数,我们可以添加另一个分支:
macro_rules! add{
// first arm match add!(1,2), add!(2,3) etc
($a:expr,$b:expr)=>{
{
$a+$b
}
};
// Second arm macth add!(1), add!(2) etc
($a:expr)=>{
{
$a
}
}
}
fn main(){
// call the macro
let x=0;
add!(1,2);
add!(x);
}
在一个宏中,可以有多个分支,宏根据不同的参数展开到不同的代码。每个分支可以接收多个参数,这些参数使用$符号开头,然后跟着一个 token 类型:
-
item——一个项(item),像一个函数,结构体,模块等。 -
block——一个块 (block)(即一个语句块或一个表达式,由花括号所包围) -
stmt—— 一个语句(statement) -
pat——一个模式(pattern) -
expr—— 一个表达式(expression) -
ty——一个类型(type) -
ident—— 一个标识符(indentfier) -
path—— 一个路径(path)(例如,foo,::std::mem::replace,transmute::<_, int>,…) -
meta—— 一个元数据项;位于#[...]和#![...]属性 -
tt——一个词法树 -
vis——一个可能为空的Visibility限定词
在上面的例子中,我们使用$typ参数,它的 token 类型为ty,类似于u8,u16。这个宏在对数字进行相加之前转换为一个特定的类型。
macro_rules! add_as{
// using a ty token type for macthing datatypes passed to maccro
($a:expr,$b:expr,$typ:ty)=>{
$a as $typ + $b as $typ
}
}
fn main(){
println!("{}",add_as!(0,2,u8));
}
Rust 宏还支持接收可变数量的参数。这个操作非常类似于正则表达式。*被用于零个或更多的 token 类型,+被用于零个或者一个参数。
macro_rules! add_as{
(
// repeated block
$($a:expr)
// seperator
,
// zero or more
*
)=>{
{
// to handle the case without any arguments
0
// block to be repeated
$(+$a)*
}
}
}
fn main(){
println!("{}",add_as!(1,2,3,4)); // => println!("{}",{0+1+2+3+4})
}
重复的 token 类型被$()包裹,后面跟着一个分隔符和一个*或一个+,表示这个 token 将会重复的次数。分隔符用于多个 token 之间互相区分。$()后面跟着*和+用于表示重复的代码块。在上面的例子中,+$a是一段重复的代码。
如果你更仔细地观察,你会发现这段代码有一个额外的 0 使得语法有效。为了移除这个 0,让add表达式像参数一样,我们需要创建一个新的宏,被称为TT muncher。
macro_rules! add{
// first arm in case of single argument and last remaining variable/number
($a:expr)=>{
$a
};
// second arm in case of two arument are passed and stop recursion in case of odd number ofarguments
($a:expr,$b:expr)=>{
{
$a+$b
}
};
// add the number and the result of remaining arguments
($a:expr,$($b:tt)*)=>{
{
$a+add!($($b)*)
}
}
}
fn main(){
println!("{}",add!(1,2,3,4));
}
TT muncher 以递归方式分别处理每个 token,每次处理单个 token 也更为简单。这个宏有三个分支:
-
第一个分支处理是否单个参数通过的情况
-
第二个分支处理是否两个参数通过的情况
-
第三个分支使用剩下的参数再次调用
add宏
宏参数不需要用逗号分隔。多个 token 可以被用于不同的 token 类型。例如,圆括号可以结合identtoken 类型使用。Rust 编译器能够匹配对应的分支并且从参数字符串中导出变量。
macro_rules! ok_or_return{
// match something(q,r,t,6,7,8) etc
// compiler extracts function name and arguments. It injects the values in respective varibles.
($a:ident($($b:tt)*))=>{
{
match $a($($b)*) {
Ok(value)=>value,
Err(err)=>{
return Err(err);
}
}
}
};
}
fn some_work(i:i64,j:i64)->Result<(i64,i64),String>{
if i+j>2 {
Ok((i,j))
} else {
Err("error".to_owned())
}
}
fn main()->Result<(),String>{
ok_or_return!(some_work(1,4));
ok_or_return!(some_work(1,0));
Ok(())
}
ok_or_return这个宏实现了这样一个功能,如果它接收的函数操作返回Err,它也返回Err,或者如果操作返回Ok,就返回Ok里的值。它接收一个函数作为参数,并在一个 match 语句中执行该函数。对于传递给参数的函数,它会重复使用。
通常来讲,很少有宏会被组合到一个宏中。在这些少数情况中,内部的宏规则会被使用。它有助于操作这些宏输入并且写出整洁的 TT munchers。
要创建一个内部规则,需要添加以@开头的规则名作为参数。这个宏将不会匹配到一个内部的规则除非显式地被指定作为一个参数。
macro_rules! ok_or_return{
// internal rule.
(@error $a:ident,$($b:tt)* )=>{
{
match $a($($b)*) {
Ok(value)=>value,
Err(err)=>{
return Err(err);
}
}
}
};
// public rule can be called by the user.
($a:ident($($b:tt)*))=>{
ok_or_return!(@error $a,$($b)*)
};
}
fn some_work(i:i64,j:i64)->Result<(i64,i64),String>{
if i+j>2 {
Ok((i,j))
} else {
Err("error".to_owned())
}
}
fn main()->Result<(),String>{
// instead of round bracket curly brackets can also be used
ok_or_return!{some_work(1,4)};
ok_or_return!(some_work(1,0));
Ok(())
}
在 Rust 中使用声明式宏进行高级解析
宏有时候会执行需要解析 Rust 语言本身的任务。
让我们创建一个宏把我们到目前为止讲过的所有概念融合起来,通过pub关键字使其成为公开的。
首先,我们需要解析 Rust 结构体来获取结构体的名字,结构体的字段以及字段类型。
解析结构体的名字及其字段
一个struct(即结构体)声明在其开头有一个可见性关键字(比如pub ) ,后面跟着struct关键字,然后是struct的名字和struct的主体。
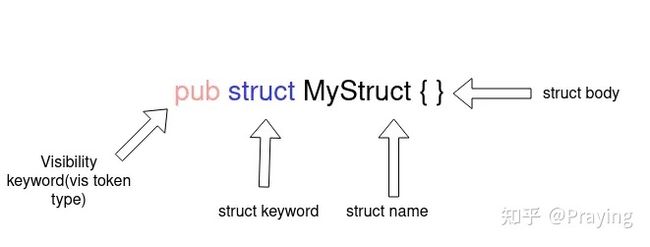
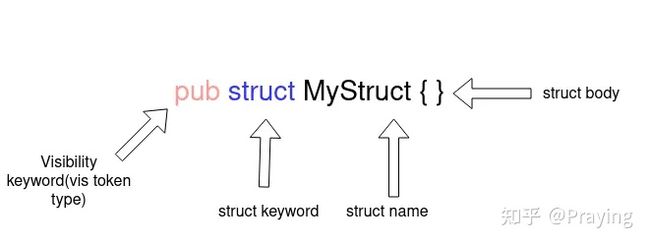
macro_rules! make_public{
(
// use vis type for visibility keyword and ident for struct name
$vis:vis struct $struct_name:ident { }
) => {
{
pub struct $struct_name{ }
}
}
}
$vis将会拥有可见性,$struct_name将会拥有一个结构体名。为了让一个结构体是公开的,我们只需要添加pub关键字并忽略$vis变量。
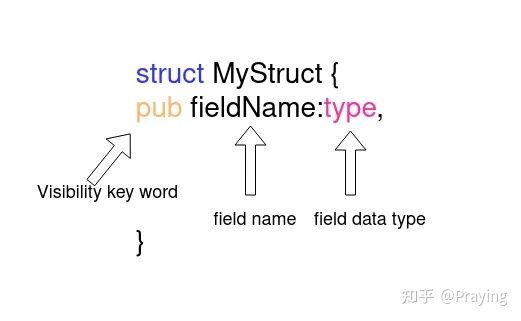
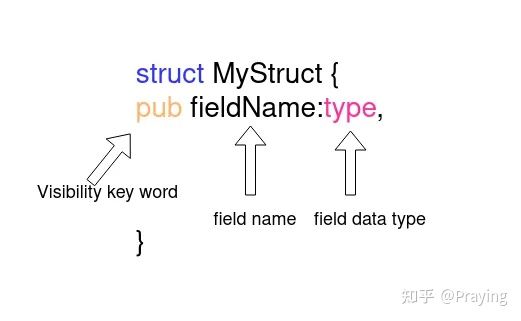
一个struct可能包含多个字段,这些字段具有相同或不同的数据类型和可见性。ty token 类型用于数据类型,vis用于可见性,ident用于字段名。我们将会使用*用于零个或更多字段。
macro_rules! make_public{
(
$vis:vis struct $struct_name:ident {
$(
// vis for field visibility, ident for field name and ty for field data type
$field_vis:vis $field_name:ident : $field_type:ty
),*
}
) => {
{
pub struct $struct_name{
$(
pub $field_name : $field_type,
)*
}
}
}
}
从struct中解析元数据
通常,struct有一些附加的元数据或者过程宏,比如#[derive(Debug)]。这个元数据需要保持完整。解析这类元数据是通过使用meta类型来完成的。
macro_rules! make_public{
(
// meta data about struct
$(#[$meta:meta])*
$vis:vis struct $struct_name:ident {
$(
// meta data about field
$(#[$field_meta:meta])*
$field_vis:vis $field_name:ident : $field_type:ty
),*$(,)+
}
) => {
{
$(#[$meta])*
pub struct $struct_name{
$(
$(#[$field_meta:meta])*
pub $field_name : $field_type,
)*
}
}
}
}
我们的make_public 宏现在准备就绪了。为了看一下make_public是如何工作的,让我们使用Rust Playground来把宏展开为真实编译的代码。
macro_rules! make_public{
(
$(#[$meta:meta])*
$vis:vis struct $struct_name:ident {
$(
$(#[$field_meta:meta])*
$field_vis:vis $field_name:ident : $field_type:ty
),*$(,)+
}
) => {
$(#[$meta])*
pub struct $struct_name{
$(
$(#[$field_meta:meta])*
pub $field_name : $field_type,
)*
}
}
}
fn main(){
make_public!{
#[derive(Debug)]
struct Name{
n:i64,
t:i64,
g:i64,
}
}
}
展开后的代码看起来像下面这样:
// some imports
macro_rules! make_public {
($ (#[$ meta : meta]) * $ vis : vis struct $ struct_name : ident
{
$
($ (#[$ field_meta : meta]) * $ field_vis : vis $ field_name : ident
: $ field_type : ty), * $ (,) +
}) =>
{
$ (#[$ meta]) * pub struct $ struct_name
{
$
($ (#[$ field_meta : meta]) * pub $ field_name : $
field_type,) *
}
}
}
fn main() {
pub struct name {
pub n: i64,
pub t: i64,
pub g: i64,
}
}
声明式宏的限制
声明式宏有一些限制。有些是与 Rust 宏本身有关,有些则是声明式宏所特有的:
-
缺少对宏的自动完成和展开的支持
-
声明式宏调式困难
-
修改能力有限
-
更大的二进制
-
更长的编译时间(这一条对于声明式宏和过程宏都存在)
下一篇文章:【译】Rust宏:教程与示例(二)将继续介绍更加复杂,也更加强大的:Rust过程宏