springboot整合sharding-jdbc实现按年分库按月分表
springboot整合sharding-jdbc实现按年分库按月分表(实现、简析篇)
1.前言:
此方案为适用对时间依赖度较高的数据进行水平切分,如果你正好符合,那么你可以看看此篇,不符合也可以看看,毕竟sharding-jdbc对分库分表的方案实现度很高,可根据自身实际情况进行数据切分,如果你对以下概念已经有共了解,可直接跳到代码环节
2.分库分表概念
在做实现之前,我们需要了解到何为分库分表,为何要这样做,这样做有何利弊?
由于关系型数据库的先天特性,在单表数据量达到一定体量的时候,就会出现性能瓶颈,至于具体是多少,此篇不做研究,说法众多,后期有时间的话可以进行测试,为了解决性能瓶颈问题,行业内的先驱们则提出了对数据进行分而治之的思想,对数据以贴合实际情况进行切分,达到对数据库性能的优化,主要的切分方式有行业先驱总结了一下几种,也可参考https://www.cnblogs.com/buddy-yuan/p/12089178.html:
1.垂直拆分
1)垂直分库:垂直分库其实是一种简单逻辑分割,把单一数据库按照业务进行划分,达到一个专库专表的效果,例如可将系统拆分为配置库、历史数据库、用户库…
2)垂直分表:比较适用于那种字段比较多的表,且有些字段并非所有的需求都要使用到,操作数据库中的某张表,将表中一部分字段信息存储至一张新表中,原表中不在存储被拆分出去的字段信息,例如机组信息表可拆分为机组基础信息表、机组详细信息表
垂直拆分有以下优点:
- 跟随业务进行分割,和最近流行的微服务概念相似,方便解耦之后的管理及扩展。
- 高并发的场景下,垂直拆分使用多台服务器的CPU、I/O、内存能提升性能,同时对单机数据库连接数、一些资源限制也得到了提升。
- 能实现冷热数据的分离。
垂直拆分的缺点:
- 部分业务表无法join,应用层需要很大的改造,只能通过聚合的方式来实现。增加了开发的难度。
- 当单库中的表数据量增大的时候依然没有得到有效的解决。
- 分布式事务也是一个难题。
2.水平拆分
当某张表数据量达到一定的程度的时候,例如MySQL单表出现2000万以上数据就会出现性能上的分水岭。此时发现没有办法根据业务规则再进行拆分了,就会导致单库上的读写性能出现瓶颈。此时就只能进行水平拆分了。
1)库内分表:假设当我们的c_vib_point表达到了5000万行记录的时候,非常影响数据库的读写效率,怎么办呢?我们可以考虑按照订单编号的id进行rang分区,就是把订单编号在1-1000万的放在order1表中,将编号在1000万-2000万的放在order2中,以此类推,每个表中存放1000万数据,或者根据插入时间进行分表,一年一个表,也可控制单表数量,但是表的数据仍然存放在一个库内,使用的是该主机的CPU、IO、内存。单库的连接数也有限制。并不能完全的降低系统的压力
2)分库分表:分库分表在库内分表的基础上,将分的表挪动到不同的主机和数据库上。可以充分的使用其他主机的CPU、内存和IO资源。并且分库之后,单库的连接数限制也不在成为瓶颈。但是“成也萧何败也萧何”,如果你执行一个扫描不带分片键,则需要在每个库上查一遍。刚刚我们按照id分成了5个库,但是我们查询是name='AAA’的条件并且不带id字段时,它并不知道在哪个分片上查,则会创建5个连接,然后每个库都检索一遍。这种广播查询则会造成连接数增多。因为它需要在每个库上都创立连接。如果是高并发的系统,执行这种广播查询,系统的thread很快就会告警,所以对于开发者的数据库操作会更加严格。
水平拆分的优点:
- 水平扩展能无线扩展。不存在某个库某个表过大的情况。
- 能够较好的应对高并发,同时可以将热点数据打散。
- 应用侧的改动较小,不需要根据业务来拆分。
水平拆分的缺点:
- 路由是个问题,需要增加一层路由的计算,而且像前面说的一样,不带分片键查询会产生广播SQL。
- 跨库join的性能比较差。
- 需要处理分布式事务的一致性问题。
个人觉得,分库分表有利有弊,在使用分库分表之前,应优先考虑缓存技术、读写分离、优化SQL、使用索引等方式,分库分表作为最后的方案,且最好是在项目初期就应该做好前瞻性考虑,如果你确定项目在未来的一定时间内,数据量确确实实会达到一个非常影响性能的体量,那么就可以考虑做分库分表,当然,你可以暂时先不做分库分表,等数据量上来了再做
3.sharding-jdbc概念
一个技术的出现必然是被需求所驱动,sharding-jdbc就是分库分表的产物,当然它并非唯一实现,只是此篇以sharding-jdbc作为技术支持来实现分库分表,下面可了解一下其相关概念,最好做到知其然知其所以然
1.简介
sharding-jdbc定位为轻量级Java框架,在Java的JDBC层提供的额外服务。 它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架。
-
适用于任何基于JDBC的ORM框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template或直接使用JDBC。
-
支持任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP等。
-
支持任意实现JDBC规范的数据库。目前支持MySQL,Oracle,SQLServer,PostgreSQL以及任何遵循SQL92标准的数据库。
2.SQL
1)逻辑表
水平拆分的数据库(表)的相同逻辑和数据结构表的总称。例如根据时间将order一年表拆分为12个表,分别是order_01到order_12,则他们的逻辑表名为order
2)真实表
在分片的数据库中真实存在的物理表。即上个示例中order_01到order_12
3)数据节点
数据分片的最小单元。由数据源名称和数据表组成,例:dataSource.order_01
4)绑定表
指分片规则一致的主表和子表。例如:t_order表和t_order_item表,均按照order_id分片,则此两张表互为绑定表关系。绑定表之间的多表关联查询不会出现笛卡尔积关联,关联查询效率将大大提升。举例说明,如果SQL为:
SELECT i.* FROM t_order o JOIN t_order_item i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
在不配置绑定表关系时,假设分片键order_id将数值10路由至第0片,将数值11路由至第1片,那么路由后的SQL应该为4条,它们呈现为笛卡尔积:
SELECT i.* FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_0 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_1 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
在配置绑定表关系后,路由的SQL应该为2条:
SELECT i.* FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
其中t_order在FROM的最左侧,ShardingSphere将会以它作为整个绑定表的主表。 所有路由计算将会只使用主表的策略,那么t_order_item表的分片计算将会使用t_order的条件。故绑定表之间的分区键要完全相同。
5)广播表
指所有的分片数据源中都存在的表,表结构和表中的数据在每个数据库中均完全一致。适用于数据量不大且需要与海量数据的表进行关联查询的场景,例如:字典表。
2.分片
1)分片键
用于分片的数据库字段,是将数据库(表)水平拆分的关键字段。例:将订单表中的主键的尾数取模分片,则订单表主键为分片字段。 SQL中如果无分片字段,将执行全路由,性能较差。 除了对单分片字段的支持,ShardingSphere也支持根据多个字段进行分片。
2)分片算法
通过分片算法将数据分片,支持通过=、>=、<=、>、<、BETWEEN和IN分片。分片算法需要应用方开发者自行实现,可实现的灵活度非常高。
目前提供4种分片算法。由于分片算法和业务实现紧密相关,因此并未提供内置分片算法,而是通过分片策略将各种场景提炼出来,提供更高层级的抽象,并提供接口让应用开发者自行实现分片算法。
-
精确分片算法
对应PreciseShardingAlgorithm,用于处理使用单一键作为分片键的=与IN进行分片的场景。需要配合StandardShardingStrategy使用。
-
范围分片算法
对应RangeShardingAlgorithm,用于处理使用单一键作为分片键的BETWEEN AND、>、<、>=、<=进行分片的场景。需要配合StandardShardingStrategy使用。
-
复合分片算法
对应ComplexKeysShardingAlgorithm,用于处理使用多键作为分片键进行分片的场景,包含多个分片键的逻辑较复杂,需要应用开发者自行处理其中的复杂度。需要配合ComplexShardingStrategy使用。
-
Hint分片算法
对应HintShardingAlgorithm,用于处理使用Hint行分片的场景。需要配合HintShardingStrategy使用。
3)分片策略
包含分片键和分片算法,由于分片算法的独立性,将其独立抽离。真正可用于分片操作的是分片键 + 分片算法,也就是分片策略。目前提供5种分片策略。
-
标准分片策略
对应StandardShardingStrategy。提供对SQL语句中的=, >, <, >=, <=, IN和BETWEEN AND的分片操作支持。StandardShardingStrategy只支持单分片键,提供PreciseShardingAlgorithm和RangeShardingAlgorithm两个分片算法。PreciseShardingAlgorithm是必选的,用于处理=和IN的分片。RangeShardingAlgorithm是可选的,用于处理BETWEEN AND, >, <, >=, <=分片,如果不配置RangeShardingAlgorithm,SQL中的BETWEEN AND将按照全库路由处理。
-
复合分片策略
对应ComplexShardingStrategy。复合分片策略。提供对SQL语句中的=, >, <, >=, <=, IN和BETWEEN AND的分片操作支持。ComplexShardingStrategy支持多分片键,由于多分片键之间的关系复杂,因此并未进行过多的封装,而是直接将分片键值组合以及分片操作符透传至分片算法,完全由应用开发者实现,最大的灵活度。
-
行表达式分片策略
对应InlineShardingStrategy。使用Groovy的表达式,提供对SQL语句中的=和IN的分片操作支持,只支持单分片键。对于简单的分片算法,可以通过简单的配置使用,从而避免繁琐的Java代码开发,如:
t_user_$->{u_id % 8}表示t_user表根据u_id模8,而分成8张表,表名称为t_user_0到t_user_7。 -
Hint分片策略
对应HintShardingStrategy。通过Hint指定分片值而非从SQL中提取分片值的方式进行分片的策略。
-
不分片策略
对应NoneShardingStrategy。不分片的策略。
-
4.上代码,开干
此案例为springboot整合mybatis+sharding-jdbc+druid,项目中可根据实际情况替换,sharding都支持
1)引入依赖
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<groupId>com.dashuaigroupId>
<artifactId>sharding-demoartifactId>
<version>0.0.1-SNAPSHOTversion>
<parent>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-parentartifactId>
<version>2.1.3.RELEASEversion>
<relativePath/>
parent>
<properties>
<java.version>1.8java.version>
properties>
<dependencies>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-webartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-testartifactId>
<scope>testscope>
dependency>
<dependency>
<groupId>org.projectlombokgroupId>
<artifactId>lombokartifactId>
<optional>trueoptional>
dependency>
<dependency>
<groupId>org.mybatis.spring.bootgroupId>
<artifactId>mybatis-spring-boot-starterartifactId>
<version>2.1.4version>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
dependency>
<dependency>
<groupId>com.alibabagroupId>
<artifactId>druid-spring-boot-starterartifactId>
<version>1.1.10version>
<exclusions>
<exclusion>
<groupId>org.slf4jgroupId>
<artifactId>slf4j-apiartifactId>
exclusion>
exclusions>
dependency>
<dependency>
<groupId>io.shardingspheregroupId>
<artifactId>sharding-jdbc-spring-boot-starterartifactId>
<version>3.1.0.M1version>
dependency>
<dependency>
<groupId>org.apache.shardingspheregroupId>
<artifactId>sharding-jdbc-coreartifactId>
<version>4.1.0version>
dependency>
dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-maven-pluginartifactId>
plugin>
plugins>
build>
project>
2)配置文件
server:
port: 9090
servlet:
context-path: /sharding
spring:
application:
name: sharding-demo
mybatis:
mapper-locations: classpath:mapper/*.xml
type-aliases-package: com.dashuai.pojo
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
3)启动类
package com.dashuai;
import io.shardingsphere.shardingjdbc.spring.boot.SpringBootConfiguration;
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication(exclude = {SpringBootConfiguration.class})
@MapperScan("com.dashuai.mapper")
public class ShardingApplication {
public static void main(String[] args) {
SpringApplication.run(ShardingApplication.class, args);
}
}
此处有坑:如果你使用java进行sharding配置,那么这里需要排除sharding的自动配置,注意引包为io.shardingsphere.shardingjdbc.spring.boot.SpringBootConfiguration,否则会报数据源为空或者sqlSessionFactory为空,原因主要是 springboot与shardingjdbc整合的时候,默认会使用SpringbootConfiguration这个类(在sharding-jdbc包下)自动的从配置文件中读取配置,如果读取不到,那么数据源就配置不成功,因为这里我们使用配置类进行配置,不使用配置文件,所以他就读不到配置,那么就会报错,使用java配置有一定优点,请往下看
4)配置类
package com.dashuai.config;
import com.dashuai.utils.datasource.DataSourceUtil;
import com.dashuai.utils.shardingarithmetic.PreciseDatabaseShardingAlgorithm;
import com.dashuai.utils.shardingarithmetic.PreciseTableShardingAlgorithm;
import com.dashuai.utils.shardingarithmetic.RangeDatabaseShardingAlgorithm;
import com.dashuai.utils.shardingarithmetic.RangeTableShardingAlgorithm;
import org.apache.shardingsphere.api.config.sharding.KeyGeneratorConfiguration;
import org.apache.shardingsphere.api.config.sharding.ShardingRuleConfiguration;
import org.apache.shardingsphere.api.config.sharding.TableRuleConfiguration;
import org.apache.shardingsphere.api.config.sharding.strategy.StandardShardingStrategyConfiguration;
import org.apache.shardingsphere.shardingjdbc.api.ShardingDataSourceFactory;
import org.springframework.boot.SpringBootConfiguration;
import org.springframework.context.annotation.Bean;
import javax.sql.DataSource;
import java.sql.SQLException;
import java.util.HashMap;
import java.util.Map;
import java.util.Properties;
@SpringBootConfiguration
public class ShardingConfig {
/**
* 逻辑表名称
*/
private final String LOGICAL_TABLE = "t_order";
/**
* 分片键
*/
private final String DATABASE_SHARDING_COLUMN = "save_time_com";
@Bean
DataSource getShardingDataSource() throws SQLException {
// 分片规则配置对象
ShardingRuleConfiguration shardingRuleConfig = new ShardingRuleConfiguration();
// 规则配置
shardingRuleConfig.getTableRuleConfigs().add(getOrderTableRuleConfiguration());
// 数据库分片算法(精确、范围),按年分库
shardingRuleConfig.setDefaultDatabaseShardingStrategyConfig(new StandardShardingStrategyConfiguration(DATABASE_SHARDING_COLUMN, new PreciseDatabaseShardingAlgorithm(), new RangeDatabaseShardingAlgorithm()));
// 表分片算法(精确、范围),按月分表
shardingRuleConfig.setDefaultTableShardingStrategyConfig(new StandardShardingStrategyConfiguration(DATABASE_SHARDING_COLUMN, new PreciseTableShardingAlgorithm(), new RangeTableShardingAlgorithm()));
// 默认库,如果存在广播表和绑定表也可在此配置
shardingRuleConfig.setDefaultDataSourceName("default_dataSource");
// 开启日志打印
final Properties properties = new Properties();
properties.setProperty("sql.show", "true");
return ShardingDataSourceFactory.createDataSource(createDataSourceMap(), shardingRuleConfig, properties);
}
TableRuleConfiguration getOrderTableRuleConfiguration() {
// 暂定为两年,关于此表达式,可查看官方文档 https://shardingsphere.apache.org/document/legacy/4.x/document/cn/features/sharding/other-features/inline-expression/
String inLineExpressionStr = "dataSource_2020." + LOGICAL_TABLE + "_20200${1..9}" + "," + "dataSource_2021." + LOGICAL_TABLE + "_20210${1..9}" + "," +
"dataSource_2020." + LOGICAL_TABLE + "_20201${0..2}" + "," + "dataSource_2021." + LOGICAL_TABLE + "_20211${0..2}";
final TableRuleConfiguration ruleConfiguration = new TableRuleConfiguration("t_order", inLineExpressionStr);
// 设置主键生成策略
ruleConfiguration.setKeyGeneratorConfig(getKeyGeneratorConfiguration());
return ruleConfiguration;
}
private KeyGeneratorConfiguration getKeyGeneratorConfiguration() {
return new KeyGeneratorConfiguration("SNOWFLAKE", "id");
}
private Map<String, DataSource> createDataSourceMap() {
// key为数据源名称,后面分片算法取得就是这个,value为具体的数据源
final HashMap<String, DataSource> shardingDataSourceMap = new HashMap<>();
shardingDataSourceMap.put("default_dataSource", DataSourceUtil.createDataSource("com.mysql.cj.jdbc.Driver",
"jdbc:mysql://localhost:3306/sharding?userUnicode=ture&characterEncoding=utf8&serverTimezone=GMT%2B8",
"root",
"xhtest"));
shardingDataSourceMap.put("dataSource_2020", DataSourceUtil.createDataSource("com.mysql.cj.jdbc.Driver",
"jdbc:mysql://localhost:3306/order_2020?userUnicode=ture&characterEncoding=utf8&serverTimezone=GMT%2B8",
"root",
"xhtest"));
shardingDataSourceMap.put("dataSource_2021", DataSourceUtil.createDataSource("com.mysql.cj.jdbc.Driver",
"jdbc:mysql://localhost:3306/order_2021?userUnicode=ture&characterEncoding=utf8&serverTimezone=GMT%2B8",
"root",
"xhtest"));
return shardingDataSourceMap;
}
}
5)工具类
- 创建数据源工具类
package com.dashuai.utils.datasource;
import com.alibaba.druid.pool.DruidDataSource;
import javax.sql.DataSource;
public class DataSourceUtil {
public static DataSource createDataSource(final String driverClass, final String url, String userName, String passWord) {
final DruidDataSource result = new DruidDataSource();
result.setDriverClassName(driverClass);
result.setUrl(url);
result.setUsername(userName);
result.setPassword(passWord);
result.setInitialSize(5);
result.setMinIdle(5);
result.setMaxActive(20);
result.setMaxWait(60000);
result.setTimeBetweenEvictionRunsMillis(60000);
result.setMinEvictableIdleTimeMillis(30000);
return result;
}
}
- 时间格式化工具类
package com.dashuai.utils.date;
import java.text.SimpleDateFormat;
import java.util.Date;
public class DateUtil {
private static final SimpleDateFormat yearFormat = new SimpleDateFormat("yyyy");
private static final SimpleDateFormat monthFormat = new SimpleDateFormat("MM");
private static final SimpleDateFormat yearJoinMonthFormat = new SimpleDateFormat("yyyyMM");
public static String getYearByMillisecond(long millisecond) {
return yearFormat.format(new Date(millisecond));
}
public static String getMonthByMillisecond(long millisecond) {
return monthFormat.format(new Date(millisecond));
}
public static String getYearJoinMonthByMillisecond(long millisecond) {
return yearJoinMonthFormat.format(new Date(millisecond));
}
}
6)分片算法
分片算法有多种,此案例只使用了标准分片算法
- 数据库精确分片算法
package com.dashuai.utils.shardingarithmetic;
import com.dashuai.utils.date.DateUtil;
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingValue;
import java.util.Collection;
public class PreciseDatabaseShardingAlgorithm implements PreciseShardingAlgorithm<Long> {
/**
* 精确分片算法
*
* @param availableTargetNames 所有配置的库列表
* @param shardingValue 分片值,也就是save_time_com的值
* @return 所匹配库的结果
*/
@Override
public String doSharding(Collection<String> availableTargetNames, PreciseShardingValue<Long> shardingValue) {
Long value = shardingValue.getValue();
// 库后缀
String yearStr = DateUtil.getYearByMillisecond(value);
if (value <= 0) throw new UnsupportedOperationException("preciseShardingValue is null");
for (String availableTargetName : availableTargetNames) {
if (availableTargetName.endsWith(yearStr)) {
return availableTargetName;
}
}
throw new UnsupportedOperationException();
}
}
- 数据库范围分片算法
package com.dashuai.utils.shardingarithmetic;
import com.dashuai.utils.date.DateUtil;
import com.google.common.collect.Range;
import org.apache.shardingsphere.api.sharding.standard.RangeShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.standard.RangeShardingValue;
import java.util.ArrayList;
import java.util.Collection;
public class RangeDatabaseShardingAlgorithm implements RangeShardingAlgorithm<Long> {
/**
* 范围分片算法
*
* @param availableTargetNames 所有配置的库列表
* @param rangeShardingValue 分片值,也就是save_time_com的值,范围分片算法必须提供开始时间和结束时间
* @return 所匹配库的结果
*/
@Override
public Collection<String> doSharding(Collection<String> availableTargetNames, RangeShardingValue<Long> rangeShardingValue) {
final ArrayList<String> result = new ArrayList<>();
Range<Long> range = rangeShardingValue.getValueRange();
long startMillisecond = range.lowerEndpoint();
long endMillisecond = range.upperEndpoint();
// 起始年和结束年
int startYear = Integer.parseInt(DateUtil.getYearByMillisecond(startMillisecond));
int endYear = Integer.parseInt(DateUtil.getYearByMillisecond(endMillisecond));
return startYear == endYear ? theSameYear(String.valueOf(startYear), availableTargetNames, result) : differentYear(startYear, endYear, availableTargetNames, result);
}
// 同一年,说明只需要一个库
private Collection<String> theSameYear(String startTime, Collection<String> availableTargetNames, ArrayList<String> result) {
for (String availableTargetName : availableTargetNames) {
if (availableTargetName.endsWith(startTime)) result.add(availableTargetName);
}
return result;
}
// 跨年
private Collection<String> differentYear(int startYear, int endYear, Collection<String> availableTargetNames, ArrayList<String> result) {
for (String availableTargetName : availableTargetNames) {
for (int i = startYear; i <= endYear; i++) {
if (availableTargetName.endsWith(String.valueOf(i))) result.add(availableTargetName);
}
}
return result;
}
}
- 表精确分片算法
package com.dashuai.utils.shardingarithmetic;
import com.dashuai.utils.date.DateUtil;
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingValue;
import java.util.Collection;
public class PreciseTableShardingAlgorithm implements PreciseShardingAlgorithm<Long> {
/**
* 精确分片算法
*
* @param availableTargetNames 所有配置的表列表,这里代表所匹配到库的所有表
* @param shardingValue 分片值,也就是dau_id的值
* @return 所匹配表的结果
*/
@Override
public String doSharding(Collection<String> availableTargetNames, PreciseShardingValue<Long> shardingValue) {
long value = shardingValue.getValue();
if (value <= 0) throw new UnsupportedOperationException("preciseShardingValue is null");
final String yearJoinMonthStr = DateUtil.getYearJoinMonthByMillisecond(value);
for (String availableTargetName : availableTargetNames) {
if (availableTargetName.endsWith(yearJoinMonthStr)) {
return availableTargetName;
}
}
throw new UnsupportedOperationException();
}
}
- 表范围分片算法
package com.dashuai.utils.shardingarithmetic;
import com.dashuai.utils.date.DateUtil;
import com.google.common.collect.Range;
import org.apache.shardingsphere.api.sharding.standard.RangeShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.standard.RangeShardingValue;
import java.util.ArrayList;
import java.util.Collection;
public class RangeTableShardingAlgorithm implements RangeShardingAlgorithm<Long> {
@Override
public Collection<String> doSharding(Collection<String> availableTargetNames, RangeShardingValue<Long> rangeShardingValue) {
final ArrayList<String> result = new ArrayList<>();
final Range<Long> range = rangeShardingValue.getValueRange();
long startMillisecond = range.lowerEndpoint();
long endMillisecond = range.upperEndpoint();
// 起始年和结束年
int startYear = Integer.parseInt(DateUtil.getYearByMillisecond(startMillisecond));
int endYear = Integer.parseInt(DateUtil.getYearByMillisecond(endMillisecond));
// 起始月和结束月
int startMonth = Integer.parseInt(DateUtil.getMonthByMillisecond(startMillisecond));
int endMonth = Integer.parseInt(DateUtil.getMonthByMillisecond(endMillisecond));
int startYearJoinMonth = Integer.parseInt(DateUtil.getYearJoinMonthByMillisecond(startMillisecond));
int endYearJoinMonth = Integer.parseInt(DateUtil.getYearJoinMonthByMillisecond(endMillisecond));
return startYear == endYear ? theSameYear(startMonth, endMonth, availableTargetNames, result)
: differentYear(startYear, endYear, startMonth, endMonth, startYearJoinMonth, endYearJoinMonth, availableTargetNames, result);
}
// 同年,但可能不同月
private Collection<String> theSameYear(int startMonth, int endMonth, Collection<String> availableTargetNames, ArrayList<String> result) {
return startMonth == endMonth ? theSameMonth(startMonth, availableTargetNames, result) : differentMonth(startMonth, endMonth, availableTargetNames, result);
}
// 同年同月
private Collection<String> theSameMonth(int startMonth, Collection<String> availableTargetNames, ArrayList<String> result) {
String startMonthStr = String.valueOf(startMonth);
if (startMonthStr.length() == 1) startMonthStr = "0" + startMonthStr;
for (String availableTargetName : availableTargetNames) {
if (availableTargetName.endsWith(startMonthStr)) result.add(availableTargetName);
}
return result;
}
// 同年不同月
private Collection<String> differentMonth(int startMonth, int endMonth, Collection<String> availableTargetNames, ArrayList<String> result) {
for (String availableTargetName : availableTargetNames) {
for (int i = startMonth; i <= endMonth; i++) {
String monthStr = String.valueOf(i);
if (monthStr.length() == 1) monthStr = "0" + monthStr;
if (availableTargetName.endsWith(monthStr)) result.add(availableTargetName);
}
}
return result;
}
// 不同年,跨年,最少两个月,需要考虑跨两年以上的情况
private Collection<String> differentYear(int startYear, int endYear, int startMonth, int endMonth, int startYearJoinMonth, int endYearJoinMonth, Collection<String> availableTargetNames, ArrayList<String> result) {
return endYear - startYear == 1 ? twoYears(startYear, endYear, startMonth, endMonth, startYearJoinMonth, endYearJoinMonth, availableTargetNames, result) : moreThanTwoYears(startYear, endYear, startMonth, endMonth, availableTargetNames, result);
}
// 两年
private Collection<String> twoYears(int startYear, int endYear, int startMonth, int endMonth, int startYearJoinMonth, int endYearJoinMonth, Collection<String> availableTargetNames, ArrayList<String> result) {
int endCondition;
endCondition = Integer.parseInt(startYear + "12");
for (int i = startYearJoinMonth; i <= endCondition; i++) {
for (String availableTargetName : availableTargetNames) {
// 如果多库此算法sharding会匹配两次,需要年份加月份来判断,只使用月份的话有问题
if (availableTargetName.endsWith(String.valueOf(i))) result.add(availableTargetName);
}
}
endCondition = Integer.parseInt(endYear + "01");
for (int i = endYearJoinMonth; i >= endCondition; i--) {
for (String availableTargetName : availableTargetNames) {
if (availableTargetName.endsWith(String.valueOf(i))) result.add(availableTargetName);
}
}
return result;
}
// 两年以上,如果数据量大的话不建议跨太多库
private Collection<String> moreThanTwoYears(int startYear, int endYear, int startMonth, int endMonth, Collection<String> availableTargetNames, ArrayList<String> result) {
return null;
}
}
7)实体
package com.dashuai.pojo;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.util.Date;
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Order {
private long id;
private Integer aId;
private Integer bId;
private Integer cId;
private Integer dId;
private Integer eId;
private Date saveTime;
private Long saveTimeCom;
private Integer param1;
private Integer param2;
private Integer param3;
private Integer param4;
private Integer param5;
private Integer param6;
private Float param7;
private Float param8;
private Float param9;
private Float param10;
private Float param11;
private Float param12;
private Float param13;
private Float param14;
private Float param15;
private Float param16;
private Float param17;
private Float param18;
private Float param19;
public Order(int aId, int bId, int cId, int dId, int eId, Date saveTime, long saveTimeCom, int param1, int param2, int param3, int param4, int param5, int param6, float param7, float param8, float param9, float param10, float param11, float param12, float param13, float param14, float param15, float param16, float param17, float param18, float param19) {
this.aId = aId;
this.bId = bId;
this.cId = cId;
this.dId = dId;
this.eId = eId;
this.saveTime = saveTime;
this.saveTimeCom = saveTimeCom;
this.param1 = param1;
this.param2 = param2;
this.param3 = param3;
this.param4 = param4;
this.param5 = param6;
this.param6 = param6;
this.param7 = param7;
this.param8 = param8;
this.param9 = param9;
this.param10 = param10;
this.param11 = param11;
this.param12 = param12;
this.param13 = param13;
this.param14 = param14;
this.param15 = param15;
this.param16 = param16;
this.param17 = param17;
this.param18 = param18;
this.param19 = param19;
}
}
7)controller
如果只是为了测试,controller和service其实可以不用,但是一开始我写了,那就贴上来吧
package com.dashuai.controller;
import com.dashuai.pojo.Order;
import com.dashuai.service.OrderService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;
@RestController
@RequestMapping("/order")
public class OrderController {
@Autowired
private OrderService orderService;
@GetMapping("/{id}")
public Order fingById(@PathVariable("id") Long orderId) {
Order order = orderService.findById(orderId);
return order;
}
@GetMapping("/fingBySaveTimeCom/{saveTimeCom}")
public Order fingBySaveTimeCom(@PathVariable("saveTimeCom") Long saveTimeCom) {
Order order = orderService.findBySaveTimeCom(saveTimeCom);
return order;
}
@GetMapping("/createTable")
public String createTable() {
try {
orderService.createTable();
} catch (Exception e) {
e.printStackTrace();
return "建表失败";
}
return "建表成功";
}
}
8)service
package com.dashuai.service;
import com.dashuai.pojo.Order;
public interface OrderService {
Order findById(Long orderId);
Order findBySaveTimeCom(Long saveTimeCom);
void createTable();
}
package com.dashuai.service.impl;
import com.dashuai.mapper.OrderMapper;
import com.dashuai.pojo.Order;
import com.dashuai.service.OrderService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
@Service
public class OrderServiceImpl implements OrderService {
@Autowired
private OrderMapper orderMapper;
@Override
public Order findById(Long orderId) {
return orderMapper.findById(orderId);
}
@Override
public Order findBySaveTimeCom(Long saveTimeCom) {
Order order = orderMapper.findBySaveTimeCom(saveTimeCom);
return order;
}
@Override
public void createTable() {
orderMapper.createTable();
}
}
9)mapper
package com.dashuai.mapper;
import com.dashuai.pojo.Order;
import org.apache.ibatis.annotations.Param;
import java.util.ArrayList;
import java.util.List;
public interface OrderMapper {
Order findById(@Param("id") Long orderId);
Order findBySaveTimeCom(@Param("saveTimeCom") Long saveTimeCom);
void createTable();
void insert(Order order);
void insertBatch(@Param("orders") ArrayList<Order> orders);
List<Order> findByOrderBytemporalInterval(@Param("startTime") long startTime, @Param("endTime") long endTime);
}
xml
<mapper namespace="com.dashuai.mapper.OrderMapper">
<resultMap id="BaseResultMap" type="com.dashuai.pojo.Order">
<id column="id" property="id" />
<result column="a_id" property="aId" />
<result column="b_id" property="bId" />
<result column="c_id" property="cId" />
<result column="d_id" property="dId" />
<result column="e_id" property="eId" />
<result column="save_time" property="saveTime" />
<result column="save_time_com" property="saveTimeCom" />
<result column="param1" property="param1" />
<result column="param2" property="param2" />
<result column="param3" property="param3" />
<result column="param4" property="param4" />
<result column="param5" property="param5" />
<result column="param6" property="param6" />
<result column="param7" property="param7" />
<result column="param8" property="param8" />
<result column="param9" property="param9" />
<result column="param10" property="param10" />
<result column="param11" property="param11" />
<result column="param12" property="param12" />
<result column="param13" property="param13" />
<result column="param14" property="param14" />
<result column="param15" property="param15" />
<result column="param16" property="param16" />
<result column="param17" property="param17" />
<result column="param18" property="param18" />
<result column="param19" property="param19" />
resultMap>
<insert id="insert">
INSERT INTO t_order(`a_id`, `b_id`, `c_id`, `d_id`, `e_id`, `save_time`, `save_time_com`, `param1`, `param2`, `param3`, `param4`, `param5`, `param6`, `param7`, `param8`, `param9`, `param10`, `param11`, `param12`, `param13`, `param14`, `param15`, `param16`, `param17`, `param18`, `param19`)
VALUES
(#{aId}, #{bId}, #{cId}, #{dId}, #{eId}, #{saveTime}, #{saveTimeCom}, #{param1}, #{param2}, #{param3}, #{param4}, #{param5}, #{param6}, #{param7}, #{param8}, #{param9}, #{param10}, #{param11}, #{param12}, #{param13}, #{param14}, #{param15}, #{param16}, #{param17}, #{param18}, #{param19})
insert>
<insert id="insertBatch">
INSERT INTO t_order(`a_id`, `b_id`, `c_id`, `d_id`, `e_id`, `save_time`, `save_time_com`, `param1`, `param2`, `param3`, `param4`, `param5`, `param6`, `param7`, `param8`, `param9`, `param10`, `param11`, `param12`, `param13`, `param14`, `param15`, `param16`, `param17`, `param18`, `param19`)
VALUES
<foreach collection="orders" item="order" separator=",">
(#{order.aId}, #{order.bId}, #{order.cId}, #{order.dId}, #{order.eId}, #{order.saveTime}, #{order.saveTimeCom}, #{order.param1}, #{order.param2}, #{order.param3}, #{order.param4}, #{order.param5}, #{order.param6}, #{order.param7}, #{order.param8}, #{order.param9}, #{order.param10}, #{order.param11}, #{order.param12}, #{order.param13}, #{order.param14}, #{order.param15}, #{order.param16}, #{order.param17}, #{order.param18}, #{order.param19})
foreach>
insert>
<update id="createTable">
CREATE TABLE `t_order` (
`id` bigint(20) NOT NULL COMMENT '主键id',
`a_id` int(11) NULL DEFAULT NULL COMMENT '所属建筑物id',
`b_id` int(11) NULL DEFAULT NULL COMMENT '数采器id',
`c_id` tinyint(3) NULL DEFAULT NULL COMMENT '卡槽id',
`d_id` tinyint(3) NULL DEFAULT NULL COMMENT '通道id',
`e_id` tinyint(3) NULL DEFAULT NULL COMMENT '测点id',
`save_time` datetime(0) NULL DEFAULT NULL COMMENT '保存时间',
`save_time_com` bigint(20) NOT NULL DEFAULT 0 COMMENT '时间戳',
`param1` smallint(6) NULL DEFAULT NULL COMMENT '数据类型:0:实时存储数据 1:定时存储数据 2:报警存储数据(状态变化才存储)3:黑匣子存储数据',
`param2` tinyint(3) NULL DEFAULT NULL COMMENT '单位1:\"µm\", 2:\"mm\", 3:\"mil\", 4:\"mm/s\", 5:\"inch/s\", 6:\"m/s2\", 7:\"g\",10:”KPa” 11:”MPa” 12:dB',
`param3` tinyint(3) NULL DEFAULT NULL COMMENT '数据类型, 0 : RMS ;1 :P ; 2 : P-P;',
`param4` int(11) NULL DEFAULT NULL COMMENT '特征值高报状态标志,按位,1表示报警 ; Bit0: 有效值 Bit 1: 峰值 Bit 2: 峰峰值 Bit 3: 峭度 Bit 4: 波峰因数 Bit 10: 通频值 Bit 11: 1X幅值 Bit 12:1X相位 Bit 13:2X幅值 Bit 14:2X相位',
`param5` int(11) NULL DEFAULT NULL COMMENT '特征值高高报状态标志,按位,1表示报警 ;',
`param6` tinyint(3) NULL DEFAULT NULL COMMENT '综合报警标志,所有特征值中的最高报警标志;',
`param7` float NULL DEFAULT NULL COMMENT '转速',
`param8` float NULL DEFAULT NULL COMMENT '有效值',
`param9` float NULL DEFAULT NULL COMMENT '峰值',
`param10` float NULL DEFAULT NULL COMMENT '峰峰值',
`param11` float NULL DEFAULT NULL COMMENT '峭度',
`param12` float NULL DEFAULT NULL COMMENT '波峰因数',
`param13` float NULL DEFAULT NULL COMMENT '通频值',
`param14` float NULL DEFAULT NULL COMMENT '1倍频幅值',
`param15` float NULL DEFAULT NULL COMMENT '1倍频相位',
`param16` float NULL DEFAULT NULL COMMENT '2倍频幅值',
`param17` float NULL DEFAULT NULL COMMENT '2倍频相位',
`param18` float NULL DEFAULT NULL COMMENT '平均值',
`param19` float NULL DEFAULT NULL COMMENT '间隙电压,单位V',
PRIMARY KEY (`id`, `save_time_com`) USING BTREE,
INDEX `saveTimeCom`(`save_time_com`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci COMMENT = '振动/压力脉动 特征值 历史数据存储表' ROW_FORMAT = Compact;
update>
<select id="findById" resultMap="BaseResultMap">
select * from t_order where id = #{id}
select>
<select id="findBySaveTimeCom" resultMap="BaseResultMap">
select * from t_order where save_time_com = #{saveTimeCom}
select>
<select id="findByOrderBytemporalInterval" resultMap="BaseResultMap">
select * from t_order where save_time_com between #{startTime} and #{endTime}
select>
mapper>
10)建库建表
库的名的话随便叫什么,只要和配置类中的createDataSourceMap()对应起来即可,此案例是order+年份,例如现在2021,那么2021年的库就叫order_2021,注意,这里库名随便取,但是createDataSourceMap()里面构建的map的key不能随便取!!!
表名的话也不能随便取,这里是按年分库按月分表,所以这里使用月份作为表名的后缀,例如订单表2020年的1月份的表为order_202101,2年就是24张表,当然,不用你建,交给sharding-jdbc
11)测试类
package com.dashuai.service;
import com.dashuai.mapper.OrderMapper;
import com.dashuai.pojo.Order;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
import java.text.SimpleDateFormat;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
import java.util.concurrent.ThreadLocalRandom;
@RunWith(SpringRunner.class)
@SpringBootTest
public class OrderServiceTest {
@Autowired
private OrderMapper orderMapper;
@Test
public void createTable() {
try {
orderMapper.createTable();
} catch (Exception e) {
e.printStackTrace();
}
}
@Test
public void insertOrder() {
final Date saveTime = new Date();
final long saveTimeCom = saveTime.getTime();
System.out.println("当前时间的毫秒是:" + saveTimeCom);
final Order order = new Order(1, 2, 3, 4, 5, saveTime, saveTimeCom, 1, 2, 3, 4, 5, 6, (float) 7, (float) 8, (float) 9, (float) 10, (float) 11, (float) 12, (float) 13, (float) 14, (float) 15, (float) 16, (float) 17, (float) 18, (float) 19);
orderMapper.insert(order);
}
@Test
public void insertBatch() throws InterruptedException {
final ArrayList<Order> orders = new ArrayList<>();
for (int i = 0; i < 10; i++) {
final Date saveTime = new Date();
final long saveTimeCom = saveTime.getTime();
System.out.println("saveTimeCom = " + saveTimeCom);
final Order order = new Order(1, 2, 3, 4, 5, saveTime, saveTimeCom, 1, 2, 3, 4, 5, 6, (float) 7, (float) 8, (float) 9, (float) 10, (float) 11, (float) 12, (float) 13, (float) 14, (float) 15, (float) 16, (float) 17, (float) 18, (float) 19);
orders.add(order);
Thread.sleep(100);
}
orderMapper.insertBatch(orders);
}
@Test
public void insertBatch2() {
// 采用随机时间进行测试,时间区间为2020-01-01到2121-12-31,经转换,2020开始毫秒为:1577808000000,2021结束毫秒为:1640966399000
final ThreadLocalRandom current = ThreadLocalRandom.current();
final ArrayList<Order> orders = new ArrayList<>();
final SimpleDateFormat format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
for (int i = 0; i < 10; i++) {
final long randomTime = current.nextLong(1577808000000L, 1640966399000L);
final Date saveTime = new Date(randomTime);
System.out.println("随机生成的时间为:" + format.format(saveTime) + "毫秒为:" + randomTime);
final Order order = new Order(1, 2, 3, 4, 5, saveTime, randomTime, 1, 2, 3, 4, 5, 6, (float) 7, (float) 8, (float) 9, (float) 10, (float) 11, (float) 12, (float) 13, (float) 14, (float) 15, (float) 16, (float) 17, (float) 18, (float) 19);
orders.add(order);
}
orderMapper.insertBatch(orders);
}
@Test
public void fingOrderById() {
final Order order = orderMapper.findById(564130608058466311L);
System.out.println("order = " + order);
}
@Test
public void findOrderBySaveTimeCom() {
final Order order = orderMapper.findBySaveTimeCom(1582496739530L);
System.out.println("order = " + order);
}
@Test
public void findByOrderBytemporalInterval() {
// 单库单表
// List orders = orderMapper.findByOrderBytemporalInterval(1609713297565L, 1611479203727L);
// orders.forEach(order -> System.out.println("order = " + order));
// 跨库范围查询
List<Order> orders = orderMapper.findByOrderBytemporalInterval(1592404225183L, 1618528709850L);
orders.forEach(order -> System.out.println("order = " + order));
}
}
12)测试解析
项目启动日志
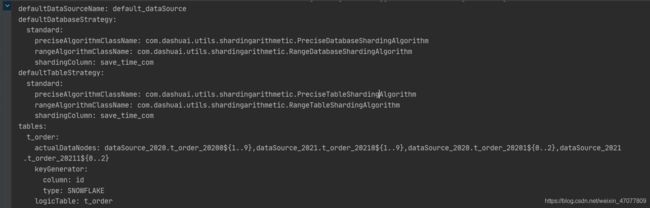
可以看到你的默认库是什么,分片算法、分片键、行表达式、逻辑表、主键生成策略等信息
建表
@Test
public void createTable() {
try {
orderMapper.createTable();
} catch (Exception e) {
e.printStackTrace();
}
}
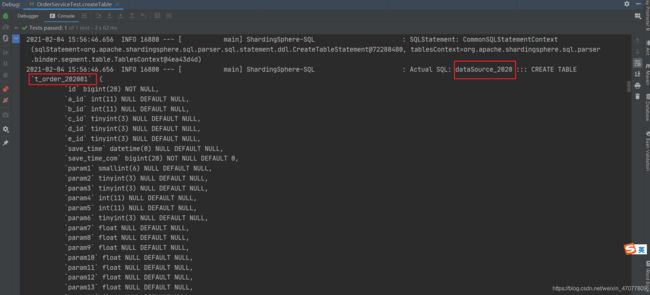
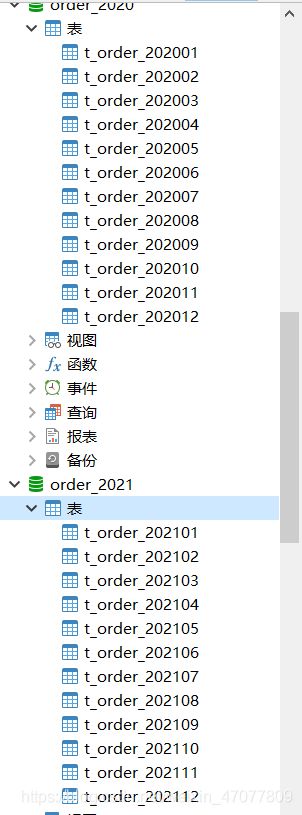
配置好分库分表配置之后,对于建表无需手动建,只需要让sharding-jdbc执行逻辑表的建表sql即可,通过日志可发现,sharding-jdbc发现是创建逻辑表之后就会对每个节点都创建出真实表
插入一条数据
@Test
public void insertOrder() {
final Date saveTime = new Date();
final long saveTimeCom = saveTime.getTime();
System.out.println("当前时间的毫秒是:" + saveTimeCom);
final Order order = new Order(1, 2, 3, 4, 5, saveTime, saveTimeCom, 1, 2, 3, 4, 5, 6, (float) 7, (float) 8, (float) 9, (float) 10, (float) 11, (float) 12, (float) 13, (float) 14, (float) 15, (float) 16, (float) 17, (float) 18, (float) 19);
orderMapper.insert(order);
}
在这里我们取的时间是当前的,当前是2021年2月份,那么,这条数据应该插入到2021年的库2月份的表,我们可以在分片算法中打断点查看SQL路由是否正确,插入数据的话走的是精确分片算法

可以看到在数据库精确分片算法中拿到了我们SQL传进来的save_time_com的值

通过这个毫秒我们可以进行时间转换得到这是毫秒的时间为2021年
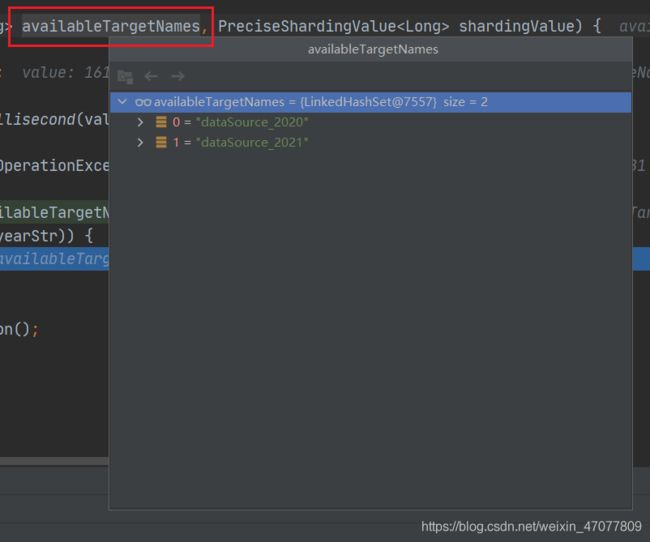
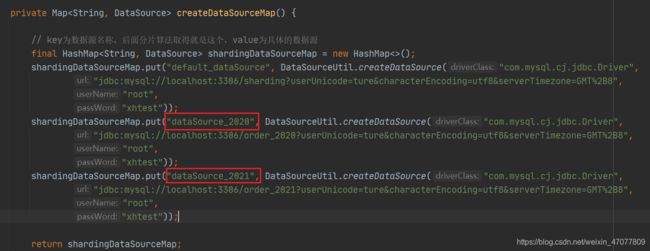
再看这两张图,有没有一种熟悉的感觉,availableTargetNames集合中就是你在配置类中创建数据源Map的key,sharding就是通过这个key来定位具体的实际数据源的
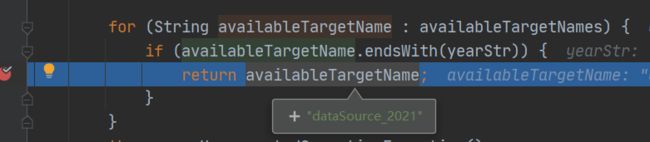
既然我们得到了传进来的时间的年份,又已经拥有我们所以数据源的key,那么就可以用来定位具体需要操作哪个库了,在这里自然是找到了2021年的库

得到库了之后,那么在表的分片算法中的availableTargetNames就是已经确定好的库的所有实际表名
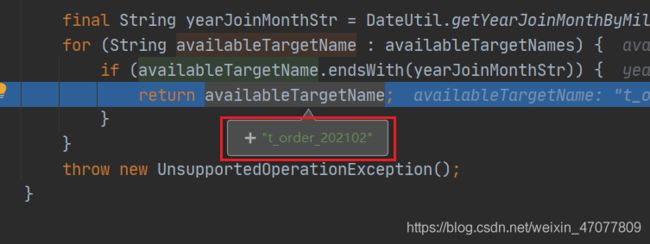
在以传进来的时间得到时间是几月份,则可以得到具体是操作那个表了,得到之后sharding-jdbc就会对其进行相应的操作

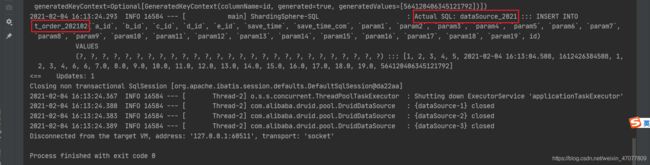
查看sharding-jdbc执行日志,逻辑SQL就是你写的SQL,根据你的逻辑SQL通过sharding配置和分片算法得到实际SQL来执行具体操作
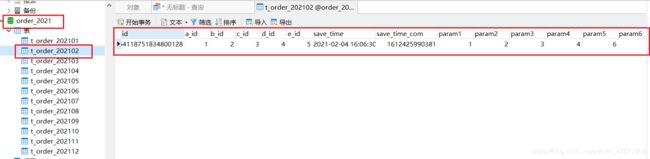
看结果,这条数据确实插入到2021年的库的2月份的表了
批量插入
@Test
public void insertBatch() throws InterruptedException {
final ArrayList<Order> orders = new ArrayList<>();
for (int i = 0; i < 10; i++) {
final Date saveTime = new Date();
final long saveTimeCom = saveTime.getTime();
System.out.println("saveTimeCom = " + saveTimeCom);
final Order order = new Order(1, 2, 3, 4, 5, saveTime, saveTimeCom, 1, 2, 3, 4, 5, 6, (float) 7, (float) 8, (float) 9, (float) 10, (float) 11, (float) 12, (float) 13, (float) 14, (float) 15, (float) 16, (float) 17, (float) 18, (float) 19);
orders.add(order);
Thread.sleep(100);
}
orderMapper.insertBatch(orders);
}
时间依然是取得当前的

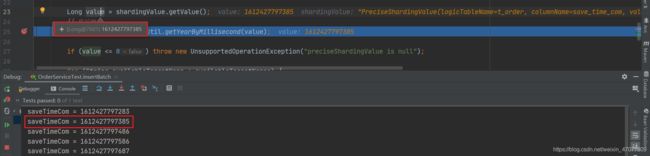
我们一次性插入十条数据,可以看到就会走十次数据库分片算法,挨个获取每条数据的路由

通过时间得到操作的是2021年的库
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mAZCj7Iu-1612505210191)(springboot整合sharding-jdbc实现按年分库按月分表.assets/image-20210204164001613.png)]
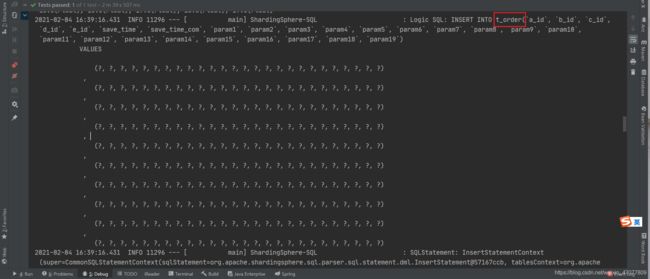
再看逻辑SQL,就是一个批量插入语句
实际SQL也是一条,这里sharding-jdbc有个很聪明的点,请看下一条测试解析
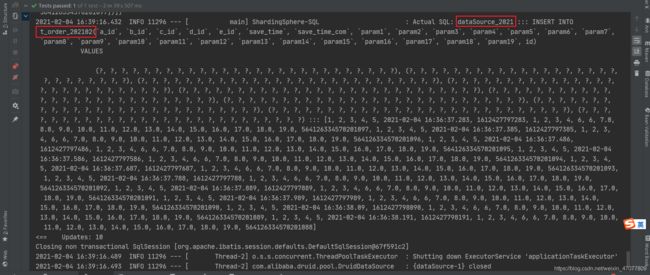
看结果,数据成功插入至对应库
批量插入,时间不同
@Test
public void insertBatch2() {
// 采用随机时间进行测试,时间区间为2020-01-01到2121-12-31,经转换,2020开始毫秒为:1577808000000,2021结束毫秒为:1640966399000
final ThreadLocalRandom current = ThreadLocalRandom.current();
final ArrayList<Order> orders = new ArrayList<>();
final SimpleDateFormat format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
for (int i = 0; i < 10; i++) {
final long randomTime = current.nextLong(1577808000000L, 1640966399000L);
final Date saveTime = new Date(randomTime);
System.out.println("随机生成的时间为:" + format.format(saveTime) + "毫秒为:" + randomTime);
final Order order = new Order(1, 2, 3, 4, 5, saveTime, randomTime, 1, 2, 3, 4, 5, 6, (float) 7, (float) 8, (float) 9, (float) 10, (float) 11, (float) 12, (float) 13, (float) 14, (float) 15, (float) 16, (float) 17, (float) 18, (float) 19);
orders.add(order);
}
orderMapper.insertBatch(orders);
}
因为一开始我们配的库就只有2020年和2021年的,所以我们只在这两年之间进行随机

这是我们随机生成的时间,可以看到2020年2月份的数据有何2021年1月份的数据刚好都有两条
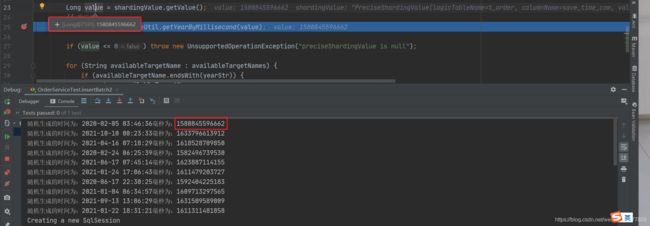
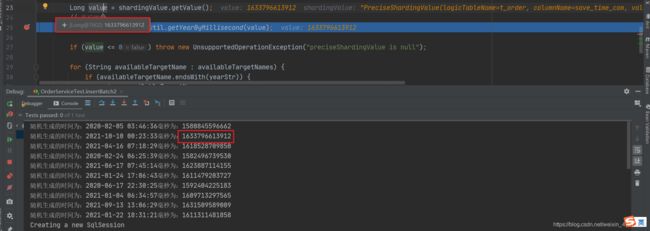
这里还是一样,每条数据都会进一次数据库分片算法,这样sharding-jdbc就可以得到所有需要操作的库

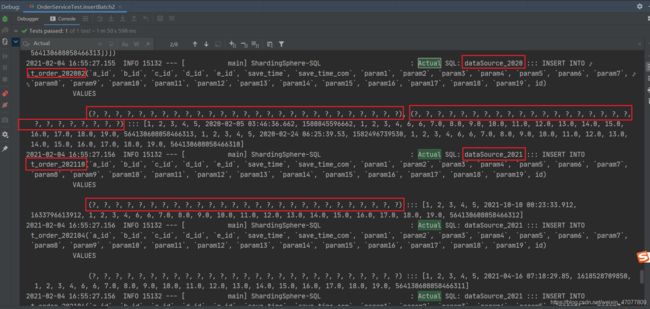
逻辑SQL,没什么问题

但是,看实际执行的SQL,现在是8条,sharding-jdbc把时间操作的库不一样的拆开了进行分别执行,我们是插入十条数据,有4个操作的是一样的,所以实际SQL应该就是8条,无误
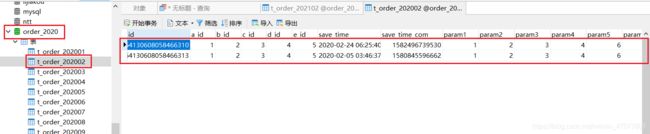
看2020年2月份的库,确实新增了两条数据
根据时间进行精确查询
@Test
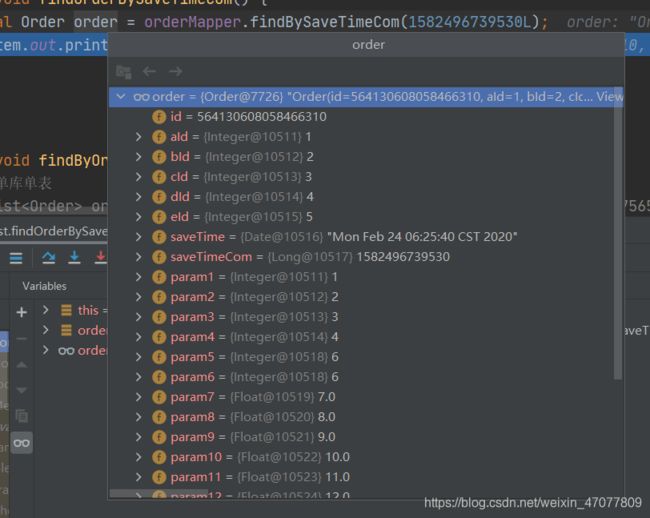
public void findOrderBySaveTimeCom() {
final Order order = orderMapper.findBySaveTimeCom(1582496739530L);
System.out.println("order = " + order);
}
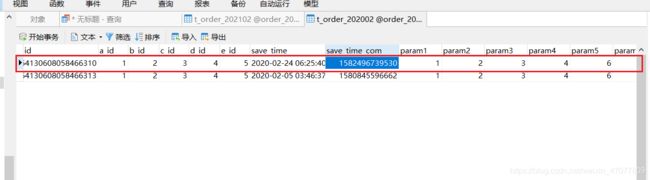
我们从刚才插入的数据中随便找个

拿到传进来的时间

得到年的时间

得到需要查询的库

得到月的时间

得到需要查询的表
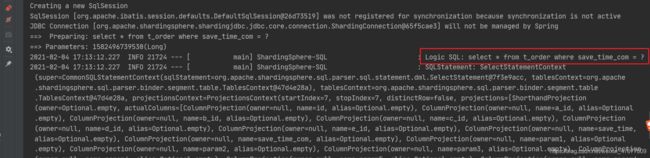
逻辑SQL
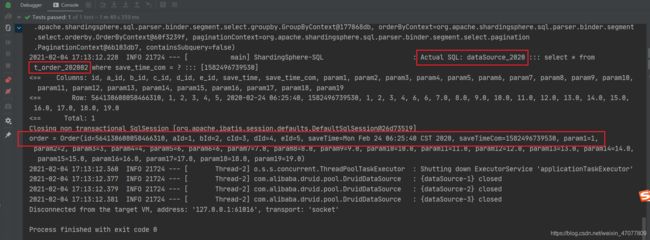
实际SQL
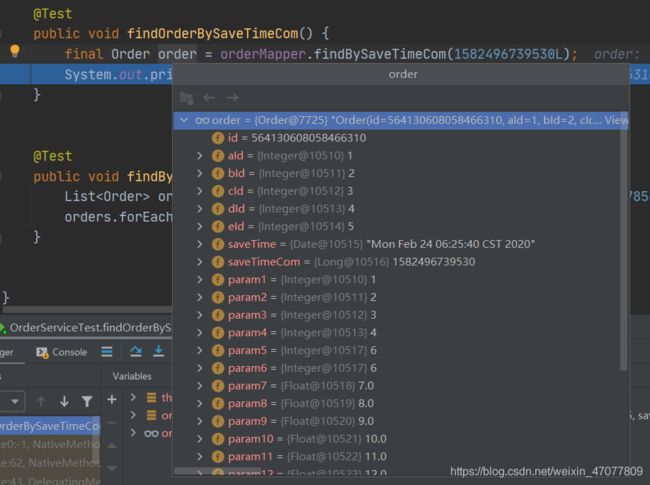
查看结果,无误
根据时间进行范围查询
@Test
public void findByOrderBytemporalInterval() {
// 单库单表
List<Order> orders = orderMapper.findByOrderBytemporalInterval(1609713297565L, 1611479203727L);
orders.forEach(order -> System.out.println("order = " + order));
}
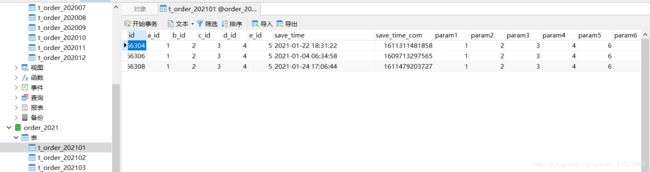
这里以2021年1月份的数据为例
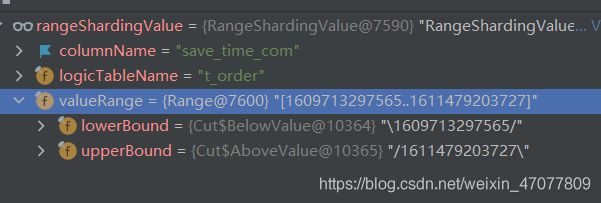
可以看到,传进来的值在valueRange对象中
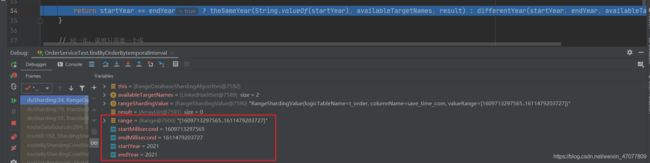
拿到range对象后拿时间并计算出开始年份和结束年份
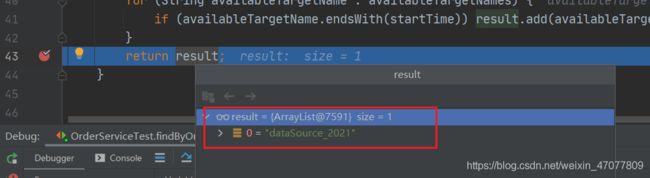
得到需要查询的库

表分片算法也是一样,拿到range对象拿时间,在算出年份和月份等信息
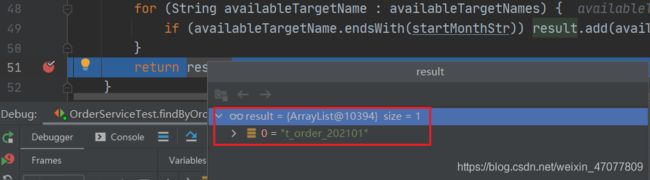
得到要查询的表

逻辑SQL

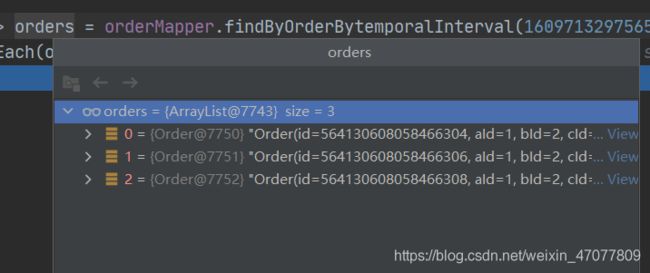
再看实际SQL,查询的为2021年的库里的1月份的表,结果也刚好三条
根据时间范围查询,跨库查询
@Test
public void findByOrderBytemporalInterval() {
// 单库单表
// List orders = orderMapper.findByOrderBytemporalInterval(1609713297565L, 1611479203727L);
// orders.forEach(order -> System.out.println("order = " + order));
// 跨库范围查询
List<Order> orders = orderMapper.findByOrderBytemporalInterval(1592404225183L, 1618528709850L);
orders.forEach(order -> System.out.println("order = " + order));
}
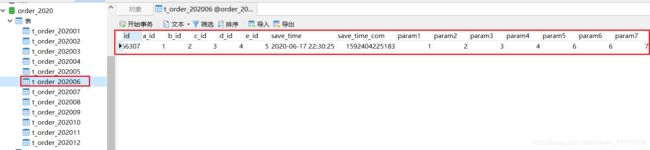
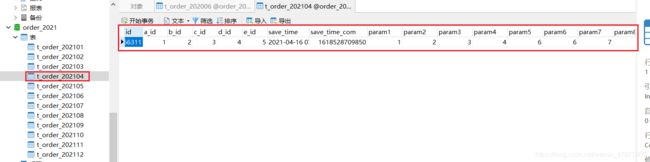
时间我们选用2020年6月开始到2021年4月结束的时间

一样进来拿到时间和算年份

得到需要查询两个库
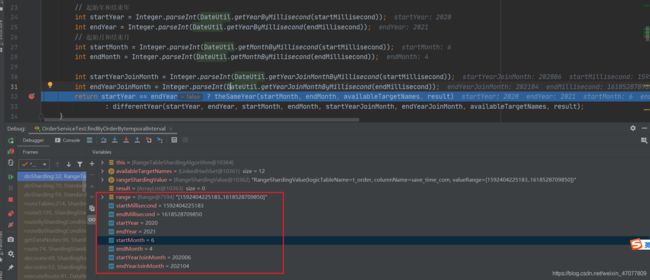
表分片算法也一样

这里需要注意一点的,此次进来的其实是2020年的库的表的信息
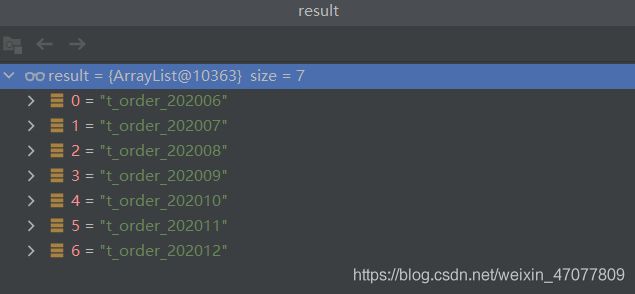
得到2020年需要查询的表,6到12月,没错
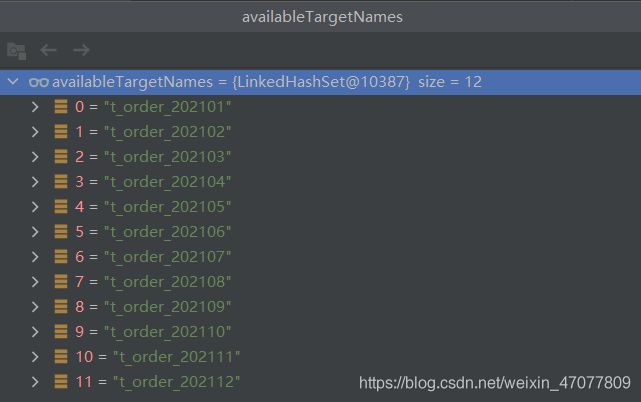
再把断点放开,会在进来一次,但是这次进来的是2021年的
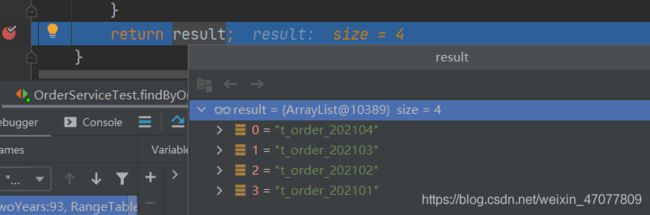
得到2021年需要查询的表

逻辑SQL
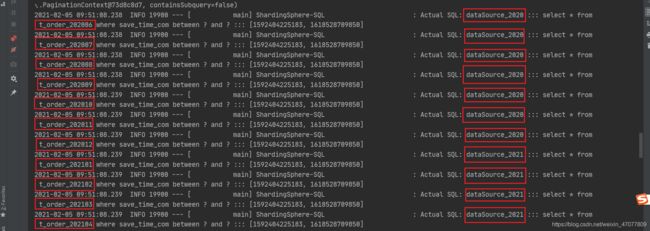
实际SQL,可以看到因为跨库跨表了,所以sharding-jdbc将这条SQL分别在需要查询的库和表都执行了一遍,最后sharding-jdbc会把所有查询到的数据进行结果归并
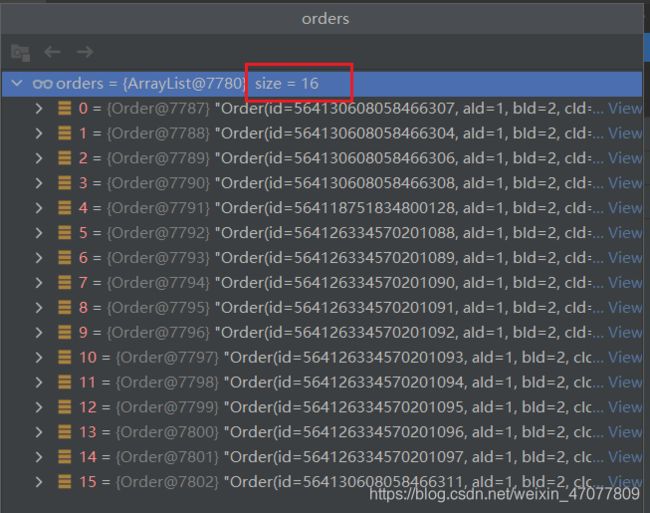
查看结果16条,去数据库数一数,确实是16条,无误
不使用分片键作为查询条件
@Test
public void fingOrderById() {
final Order order = orderMapper.findById(564130608058466311L);
System.out.println("order = " + order);
}
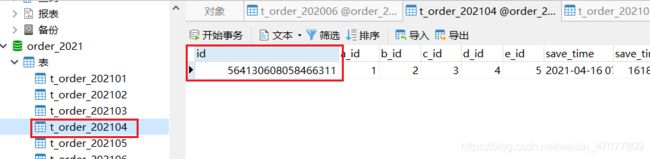
随便找条数据,这里就按id查询

把断点打在分片算法中,发现根本没有进来,因为查询语句没有以分片键作为查询条件,看逻辑SQL

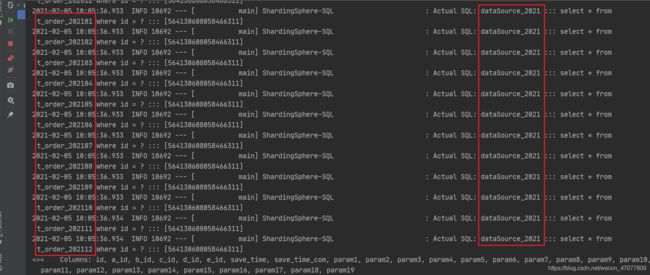
再看实际SQL和结果,发现如果不带分片键作为查询条件的话,会进行全库全表路由,虽说数据是能够查询来,但是效率属实不高,所以,做了分库分表,查询就务必把分片键带上!!!
关于默认库
这里虽然配了,但我这就不测了,很简单,如果你查询的表并非逻辑表,那么sharding-jdbc就会去你配置的默认库里找并执行对应的SQL
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pWpcM6ye-1612505210220)(springboot整合sharding-jdbc实现按年分库按月分表.assets/image-20210205101439925.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RIJOTLRp-1612505210220)(springboot整合sharding-jdbc实现按年分库按月分表.assets/image-20210205101452835.png)]
5.啰嗦几句
1):关于技术选型
sharding-jdbc是只支持java,如果你用其他语言的haul,可以考虑mycay或者sharding-proxy或者是其他的,这里简单整理了一下这三者的对比以供参考:
| Sharding-JDBC | Sharding-Proxy | MyCat | |
|---|---|---|---|
| 数据库 | 任意 | MySQL/PostgreSQL | MySQL |
| 连接消耗数 | 高 | 低 | 高 |
| 异构语言 | 仅Java | 任意 | 任意 |
| 性能 | 损耗低 | 损耗略高 | 一般 |
| 无中心化 | 是 | 否 | 否 |
| 是否支持自定义sharding路由 | 是 | 是 | 是 |
| 是否需要独立部署 | 否 | 是 | 是 |
至于要如何选择,就看你的实际项目情况了
2)关于sharding-jdbc的一些概念
首先严格来讲它应该不算一个中间件,所以相对轻量,整个案例下来,其实不难发现,主要是围绕着逻辑表、分片键、数据源Map、表名、行表达式、分片算法、策略、逻辑SQL这些配置来实现的
-
逻辑表:就是你需要给那张表做分库分表,例如这里order表,那么逻辑表就是他,注意一点,写SQL的时候,就写逻辑表名即可,不用写真实表名,因为如果sharding-jdbc发现不是逻辑表的话,就直接走默认库了
-
分片键`:就是在你的数据中,你要以什么字段的数据来决定对你的数据的切分,例如这里的毫秒时间save_time_com,这个案例是只使用了一个,你可以使用多个,库分片键一个,表分片键一个,或者复合分片等等…在你的SQL中,sharding-jdbc也是根据查看你是否带了分片键来决定是否走sharding-jdbc的分片算法的,所以,查询务必带上,否则全库全表路由,这里还有一个注意的点就是类型问题,在这里类型是严格的,就是说你的分片键假如在你的分片算法中是Long类型,那么你传进SQL的时候也必须是Long类型,如果你没做分库分表的话,或许mysql会帮你自动转换,但是sharding-jdbc不会,需严格遵守。
-
数据源Map、表名:数据源Map的key很重要,上面我们打断点也可以看到,他的key其实传到库分片算法中去了,成为了路由的条件,所以,不要乱取,最好自己制定好,前面怎么取名,后面就怎么用,表名也是一样的,怎么取名怎么用
-
行表达式:这个表达式我记得应该不是必须的,但是它可以更加方便的让你表达出你先要数据,这里用于表达数据节点,是sharding-jdbc初始化的依据,这里也需要和数据源Map的key对应起来
解释一下
dataSource_2020.t_order_20200${1..9},dataSource_2021.t_order_20210${1..9},dataSource_2020.t_order_20201${0..2},dataSource_2021.t_order_20211${0..2}
dataSource_2020.t_order_20200${1..9}:dataSource_2020需要和数据源Map的key对应起来,表示2020年的这个数据库里有9个order表,分别是202001到202009
dataSource_2021.t_order_20210${1..9}:这里也是一样的,只是这是2021年的
dataSource_2020.t_order_20201${0..2}:表示2020年这个库有三个order表,分别是202010到202012
dataSource_2021.t_order_20211${0..2}:同上
- 分片算法、策略:其实这里的实现度是很高的,官方只提供了接口,具体实现你可以根据你指定的方案来写,这里这里面可以用的数据有数据源Map的key、表名、分片键的值
- 逻辑SQL:其实就是你的正常SQL,只是sharding-jdbc给你做了解析和路由,还给你做了结果归并,不过,写SQL的时候需要注意的就是关于一些sharding-jdbc的不支持项,可以前往官网查看jdbc和SQL的不支持项,写SQL尽量避免它的不支持项,如果你的项目初期做分库分表的话,就需要格外注意了,建议熟读并背诵,如果是后期做的,那就只能改了,几乎所有SQL都得过一遍…如果你不想所有都过一遍的话,这里推荐一个mybatis-plus的插件
dynamic-datasource-spring-boot-starter,是一个基于springboot的快速集成多数据源的启动器,实现一个数据源分离的功能,让sharding-jdbc只专注于分库分表,其他的操作还是交给原来的数据源,好处是只需要改逻辑表的相关SQL,坏处是无法进行联合查询,当然数据量大了联合查询也不太合适,还有就是,如果你使用了sharding-jdbc,那么尽量不要使用mybatis-plus和通用mapper之类的拓展,毕竟它们其实是通过你的实体或者条件构造器来帮你构建一条符合你预期的SQL,但是这条SQL具体是什么其实对于开发者来说你没底的,可能肯定的是,他帮你构建的SQL能够帮你达到你的目的,但是,到了sharding-jdbc这里,他是需要解析刚才所构建的SQL的,这样的话可能会出现一些不可控的错误,所以,老老实实自己写SQL吧
3):关于此案例的一些改进点
一开始选择java的配置方式,是因为这种方式更加灵活,在配置行表达式和构建数据源Map的时候,是可以从数据库来读取这些配置信息的,还可以把这个配置做到后台管理,在通过一些方式使得sharding-jdbc重新加载或者项目重启,即可更加灵活不至于写死了,提供两个表作为参考:
CREATE TABLE `ly_sharding_data_source` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '自增主键',
`rule_name` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '路由数据源名称',
`url` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '连接地址',
`user_name` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '数据源 用户名',
`password` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '数据源密码',
`driver_class` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '驱动全类名',
`sharding_column` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '分库的列',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 26 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Compact;
CREATE TABLE `ly_sharding_data_source_detail` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '自增id',
`data_source_id` int(11) NULL DEFAULT NULL COMMENT '数据源id',
`logical_table` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '逻辑表名',
`sharding_column` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '分表列',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 160 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Compact;
4)最后几句
拓展一块我项目中测过了,可行,本来想整合进这个案例里来的,但是时间问题,就暂时没做…后期有时间的话我会加进去,还有查询性能测试。。。
,是可以从数据库来读取这些配置信息的,还可以把这个配置做到后台管理,在通过一些方式使得sharding-jdbc重新加载或者项目重启,即可更加灵活不至于写死了,提供两个表作为参考:
CREATE TABLE `ly_sharding_data_source` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '自增主键',
`rule_name` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '路由数据源名称',
`url` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '连接地址',
`user_name` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '数据源 用户名',
`password` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '数据源密码',
`driver_class` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '驱动全类名',
`sharding_column` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '分库的列',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 26 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Compact;
CREATE TABLE `ly_sharding_data_source_detail` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '自增id',
`data_source_id` int(11) NULL DEFAULT NULL COMMENT '数据源id',
`logical_table` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '逻辑表名',
`sharding_column` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '分表列',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 160 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Compact;
4)最后几句
拓展一块我项目中测过了,可行,本来想整合进这个案例里来的,但是时间问题,就暂时没做…后期有时间的话我会加进去,还有查询性能测试。。。
最后提前祝大家:新年快乐,假期愉快!