【Paper Note】Attention is all your need
Attention is all your need
- 难以理解的问题
- Introduction
- Background
- Model Architecture
-
- 3.1 Encoder and Decoder Stacks
-
- Encoder
- Decoder
- Attention
-
- 3.2.1 Scaled Dot-Product Attention
-
- Masked
- Multi-head attention
- 3.2.3 Applications of attentions in our model
-
- encoder 的注意力层
- decoder 的 masked multi-head attention
- decoder 的 multi-head attention
- Position-wise Feed-Forward Networks
- 3.4 Embeddings and Softmax
- 3.5 Positional Encoding
- 4. Why Self-attention
Attention is all your need链接
b站李沐论文带读
b站对transformer图解
难以理解的问题
什么是残差链接?
h 个不一样的距离空间指的是什么?
Introduction
循环模型难以并行
Background
Transformer是第一个完全依靠self-attention来计算输入和输出表示而不使用序列对齐RNN或卷积的转导模型。
Model Architecture
输入序列(x1,…,xn) 通过encoder映射z = (z1,…,zn)(即机器学习算法可以使用的向量,一个句子有 n 个词,xt 是第 t 个词,zt 是第 t 个词的向量表示)。 根据z,decoder生成符号的一个输出序列(y1,…,ym) 。 在每一步decoder中,模型都是auto-regressive自回归的(过去时刻的输出也会作为当前时刻的输入)

对上图的描述:
- 输入经过一个 Embedding层, i.e., 一个词进来之后表示成一个向量。得到的向量值和 Positional Encoding (3.5)相加。
- Nx:N个 Transformer 的 block 叠在一起。
- Add & Norm: 残差连接 + Layernorm
- Feed Forward: 前馈神经网络 MLP
- decoder 是 encoder 相同部分 和 Masked Multi-Head Attention 组成一个块,重复 Nx 次
- Shifted right 指的是 decoder 在之前时刻的一些输出,作为此时的输入。一个一个往右移
3.1 Encoder and Decoder Stacks
Encoder
- Encoder 结构:重复 6 个图中红色的 layer(论文中让n=6)
- 每个 layer 有 2 个 sub-layers:
- 第一个 sub-layer 是 multi-head self-attention
- 第二个 sub-layer 是 simple, position-wise fully connected feed-forward network, 简称 MLP
- 每个 sub-layer 的输出做 残差连接 和 LayerNorm
- L a y e r N o r m ( x + S u b l a y e r ( x ) ) LayerNorm(x + Sublayer(x)) LayerNorm(x+Sublayer(x))
- residual connections 需要输入输出维度一致,不一致需要做投影。简单起见,固定 每一层的输出维度dmodel = 512
- 简单设计:只需调 2 个参数 dmodel 每层维度有多大 和 N 多少层,影响后续一系列网络的设计,BERT、GPT。
- Remark:和 CNN、MLP 不一样。MLP 通常空间维度往下减;CNN 空间维度往下减,channel 维度往上拉
batchnorm和layernorm
- 标准化过程:均值变0方差变1,即所有数据减去均值再除以方差
- 前者对每个特征(列feature行样本,一次处理一列),后者对每个样本norm
- Mini-batch 的均值和方差:如果样本长度变化比较大的时候,每次计算小批量的均值和方差,均值和方差的抖动大。
- LayerNorm 更稳定,不管样本长还是短,均值和方差是在每个样本内计算。
Decoder
- auto-regressive 自回归。
- 当前时刻的输入集 是 之前一些时刻的输出。做预测时,decoder 不能看到 之后时刻的输出。
- 但是attention mechanism 每一次能看完完整的输入,所以要避免这个情况的发生。
- 在 decoder 训练的时候,在预测第 t 个时刻的输出的时候,decoder不应该看到 t 时刻以后的那些输入。
- 它的做法是通过一个带掩码 masked 的注意力机制Masked Multi-Head Attention。来保证 训练和预测时 行为一致。
Attention
Attention函数可以描述为将query和一组key-value映射成一个输出的函数,其中query、key、value和输出都是向量。
output为value的加权和,output 中 value 的权重 等价于 query 和对应的 key 的相似度
不同注意力机制就是相似度算法不同
3.2.1 Scaled Dot-Product Attention
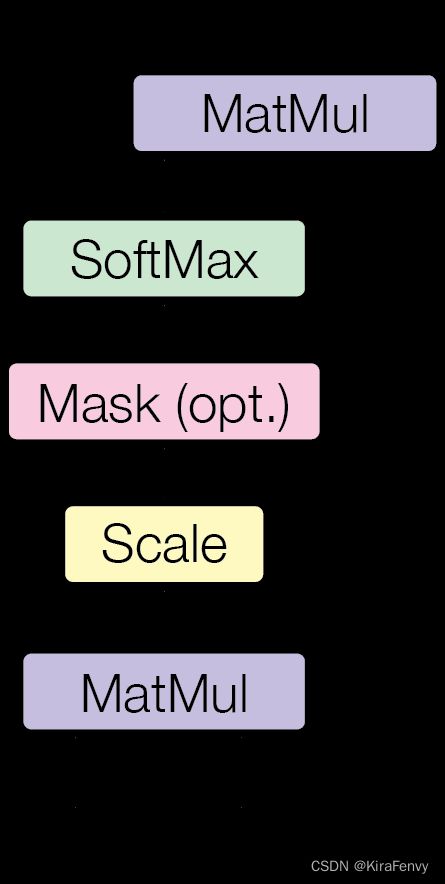
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V \mathrm{Attention}(Q,K,V)=\mathrm{softmax}(\dfrac{QK^T}{\sqrt{d_k}})V Attention(Q,K,V)=softmax(dkQKT)V
query 和 key 的长度是等长的,都等于 dk。value 的维度是 dv,输出也是 dv。
实际计算:不会一个 query 一个 query 的计算,因为运算比较慢。把多个 query 写成 一个矩阵,并行化运算。
Q:n * dk
K: m * dk
Q * K T:(n * dk) * (m * dk)T = (n * m)
softmax会让大的数据更大,小的更小(因为指数函数的曲线,建议回忆一下softmax的公式)
因为 softmax 最后的结果是希望 softmax 的预测值,置信的地方尽量靠近,不置信的地方尽量靠近零,以保证收敛差不多了。这时候梯度就会变得比较小,那就会跑不动,所以要除以根号dk,防止梯度过小
Masked
怎么做 mask :
- 避免在 t 时刻,看到 t 时刻以后的输入。
- 在计算权重的时候,t 时刻只用了 v1, …, vt-1 的结果,不要用到 t 时刻以后的内容。
- 把 t 时刻以后 Qt 和 Kt 的值换成一个很大的负数,如 1 ^ (-10),进入 softmax 后,权重为0。 --> 和 V 矩阵做矩阵乘法时,没看到 t 时刻以后的内容,只看 t 时刻之前的 key - value pair。
- 理解:mask是个 0 1矩阵,和attention(scale QK)size一样,t 时刻以后 mask 为 0
Multi-head attention

把整个 query、key、value 整个投影 project 到 1个低维,投影 h 次。然后再做 h 次的注意力函数,把每一个函数的输出 拼接在一起,然后 again projected,会得到最终的输出
- 输入是:原始的 value、key、query
- 进入一个线性层,线性层把 value、key、query 投影到比较低的维度。然后再做一个 scaled dot product (图 2 左图)。
- 执行 h 次会得到 h 个输出,再把 h 个 输出向量全部合并 concat 在一起,最后做一次线性的投影 Linear,会回到我们的 multi-head attention。
为什么要做多头注意力机制呢?一个 dot product 的注意力里面,没有什么可以learn的参数。具体函数就是内积,为了识别不一样的模式,希望有不一样的计算相似度的办法。
加性 attention 有一个权重可learn,也许能learn到一些内容。
本文的 dot-product attention,先投影到低维,投影的 w 是可以学习的。
multi-head attention 给 h 次机会去学习 不一样的投影的方法,使得在投影进去的度量空间里面能够去匹配不同模式需要的一些相似函数,然后把 h 个 heads 拼接起来,最后再做一次投影。
multi-head attention 具体公式
MuItiHad ( Q K , V ) = Concat ( head 1 , . . . , head n ) W O \text{MuIti}\text{Had}(QK,V)=\text{Concat}(\text{head}_1,...,\text{head}_n)W^O\quad MuItiHad(QK,V)=Concat(head1,...,headn)WO
head i = Attempt ( Q W i Q , K W i K , V W i V ) \text{head}_i=\text{Attempt}(QW_i^Q,KW_i^K,VW_i^V) headi=Attempt(QWiQ,KWiK,VWiV)
其中
W i Q ∈ R d m o d e l × d k , W i K ∈ R d m o d e l x d k , W i V ∈ R V m o d e l × d , W O ∈ R h d v × d model . W_{i}^{Q}\in\mathbb{R}^{d\mathrm{model}\times d k},W_{i}^{K}\in\mathbb{R^{d\mathrm{model}x d}k},W_{i}^{V}\in\mathbb{R^{\mathrm{model}\times d}_{V}},W^O\in\mathbb{R}^{hd_v\times d\text{model}}. WiQ∈Rdmodel×dk,WiK∈Rdmodelxdk,WiV∈RVmodel×d,WO∈Rhdv×dmodel.
Multi-head 的输入还是Q,K,V
但是输出是 不同的头的输出的 concat 起来,再投影到一个 WO 里面。
每一个头 headi :是把 Q,K,V 通过 可以学习的 Wq, Wk, Wv 投影到 dv 上,再通过注意力函数,得到 headi。
本文采用 8 个 heads。因为有残差连接的存在使得输入和输出的维度至少是一样的。
投影维度 dv = dmodel / h = 512 / 8 = 64,每个 head 得到 64 维度,concat,再投影回 dmodel。
3.2.3 Applications of attentions in our model
回顾一下这张图
三个黄色的方框是三种不一样的注意力层
encoder 的注意力层
encoder 的注意力层,有三个输入,它分别表示的是key、value 和 query (所以有三个箭头)
一根线过来分叉成了三个:同样一个东西,既 key 也作为 value 也作为 query,所以叫做自注意力机制。key、value 和 query 其实就是一个东西,就是自己本身。
输入了 n 个 query,每个 query 会得到一个输出,那么会有 n 个输出。
输出 是 value 加权和(权重是 query 和 key 的相似度),输出的维度 == d – > 输入维度 == 输出维度
一般每个key和自身的相似度最大,权重最高

- 不考虑 multi-head 和 有投影的情况:输出是 输入的加权和,其权重来自 每个向量与其它向量的相似度。
- multi-head 和 有投影的情况:学习 h 个不一样的距离空间,使得输出变化。
decoder 的 masked multi-head attention
和前面的multi-head attention区别只有看不到t时刻以后的输入(权重为0)
decoder 的 multi-head attention
不再是self-attention,因为query 是来自 decoder 里 masked multi-head attention 的输出(看看三个箭头的来源)
Position-wise Feed-Forward Networks
Point-wise: 把一个 MLP 对每一个词 (position)作用一次,对每个词作用的是同样的 MLP
FFN: Linear + ReLU + Linear
单隐藏层的 MLP,中间 W1 扩维到4倍 2048,最后 W2 投影回到 512 维度大小,便于残差连接。
pytorch实现:2个线性层。因为pytorch在输入是3d的时候,默认在最后一个维度做计算。
最简单情况:没有残差连接、没有 layernorm、 attention 单头、没有投影。看和 RNN 区别
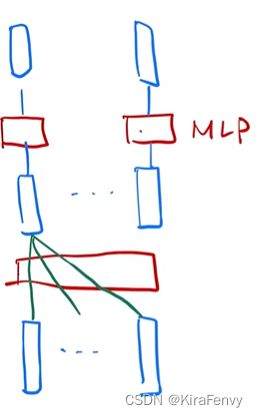
对上图的解释:
- attention 对输入做一个加权和,加权和 进入 point-wise MLP。(画了多个红色方块 MLP, 是一个权重相同的 MLP)
- point-wise MLP 对 每个输入的点 做计算,得到输出。
- attention 作用:把整个序列里面的信息抓取出来,做一次汇聚 aggregation
- 因为这个地方序列信息已经被汇聚完成,所以 MLP 是可以分开做的,也就整这个 transformer 是如何抽取序列信息,然后把这些信息加工成我最后要的语义空间,向量的过程
对比 RNN 怎么做的:

图中 绿色 表示之前的信息
- RNN 跟 transformer 异:如何传递序列的信息
- RNN 是把上一个时刻的信息输出传入下一个时候做输入。Transformer 通过一个 attention 层,去全局的拿到整个序列里面信息,再用 MLP 做语义的转换。
- RNN 跟 transformer 同:语义空间的转换 + 关注点
用一个线性层 or 一个 MLP 来做语义空间的转换。
关注点:怎么有效的去使用序列的信息。
3.4 Embeddings and Softmax
embedding:将输入的一个词、词语 token 映射成 为一个长为 d 的向量。
乘根号dmodel让embedding 和 positional encosing 的 scale 差不多,可以做加法。
3.5 Positional Encoding
attention 不会有时序信息 。
但我们要处理时序数据怎么办呢?因此在输入里面加入时序Positional Encoding
怎么加入?一个在位置 i 的词,会把 i 位置信息加入到输入里面,
周期不一样的 sin 和 cos 函数计算 --> 任何一个值可以用一个长为 512 的向量来表示。
P E ( c o s , 2 ) = s i n ( p os/ 1000 0 2 i / d mode ) P E ( p os, 2 i + 1 ) = c o s ( p os/ 1000 0 2 i/ d mode ) \begin{matrix}P E_{(cos,2)}=sin(p\text{os/}10000^{2i\text{/}d\text{mode})}\\ P E_{(p\text{os,}2i\text{+}1)}=cos(p\text{os/}{}10000^{2\text{i/}d\text{mode}})\end{matrix} PE(cos,2)=sin(pos/100002i/dmode)PE(pos,2i+1)=cos(pos/100002i/dmode)
4. Why Self-attention
文章中和RNN CNN进行了对比
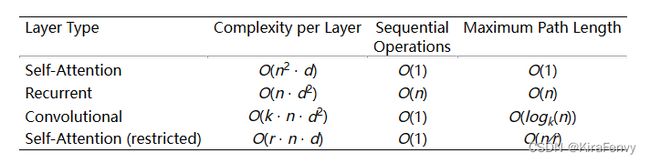
Maximum Path Length(一个信息从一个数据点走到另外一个数据点要走多少步)越短越好
attention主要需要使用更多的数据量