神奇的 SQL 之擦肩而过 → 真的用到索引了吗
索引的数据结构
什么是数据库索引 ,相信大家都能答上来,索引就是为了加速对表中数据行的检索而创建的一种分散存储的数据结构(索引是一种数据结构)
但具体是什么样的数据结构,很多小伙伴可能就不知道了
索引的数据结构包括 哈希表、B树、B+树 等,而用的最多的就是 B+树
我们以 MySQL 为例,来看看 B+树 结构的索引到底是什么样的
表: tbl_index

c1 上有聚簇索引, c2 上有二级索引(即非聚簇索引)
InnoDB 的索引
InnoDB 下的聚簇索引 和 二级索引还是有区别的
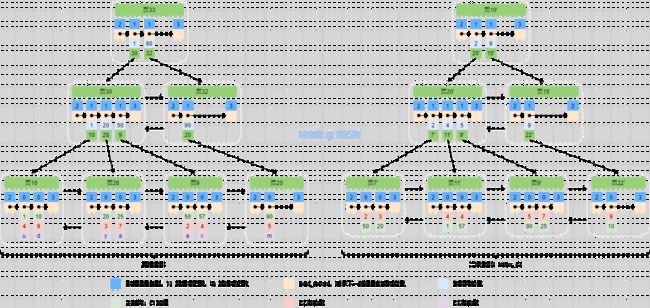
MyISAM 的索引
MyISAM 聚簇索引和二级索引结构基本一致,只是聚簇索引有个唯一性约束
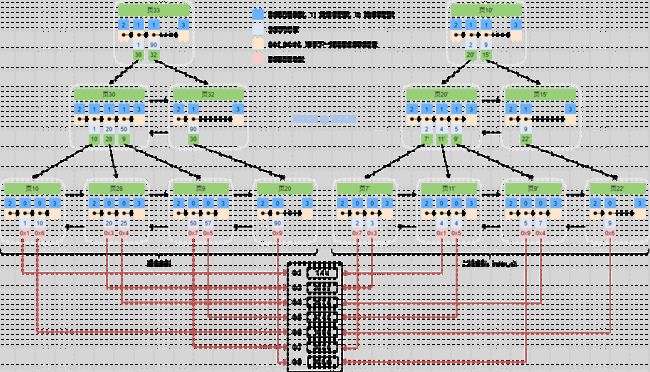
B+树 就是如上图中的那样一个倒立的树结构
B+树 有很多特性,这里就不细讲了,有兴趣的可以去查阅相关资料
组合索引的列顺序
单列索引的列顺序好说,它就一列,不存在列先后顺序的问题,按这个列的值进行顺序排序,存储到 B+树 中就好,上面两图都是单列索引
但在实际应用中,更多的还是用到组合索引(在多列上建一个索引),既然有多列,那就存在列与列之间的顺序问题了
那组合索引的的结构具体是什么样的了?
我们有表: tbl_group_index ,在 c2 列和 c3 列上建一个组合索引 idx_c2_c3

那么,索引 idx_c2_c3 的结构如下
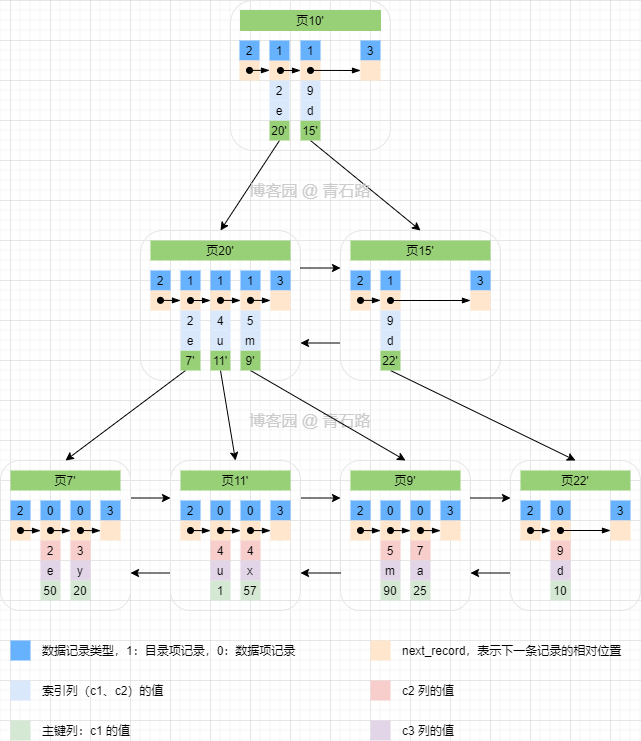
先按 c1 列排序,若 c1 列相等了再按 c2 列排序
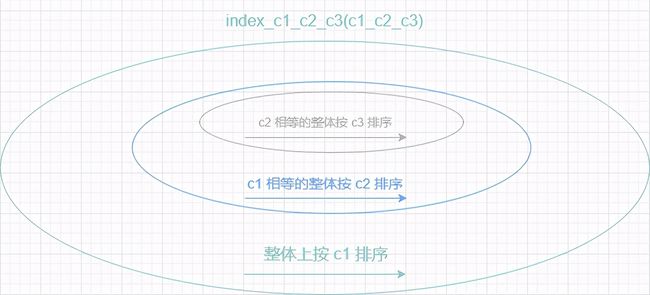
抽象化就是,按组合索引指定的列,从左往右逐个排序;整体上先按第一列排序,第一列相等的数据整体按第二列排序,第一列相等且第二列相等的数据整体按第三列排序,以此类推
索引的擦肩而过
有的小伙伴可能急了:“楼主,前戏太多了,我要看主角!!!”
楼主:“你怕是个杠精吧,前戏不写长点,怎么凑够篇幅? 你去看看现在的动漫,哪个不是正戏不够前戏来扣?(更可恶的是还有一大截尾戏拼凑)”
好了,不多扯了(再扯楼主怕是有生命危险了),我们一起来看看今天的主角们!
环境准备
MySQL 版本: 5.7.30-log ,存储引擎: InnoDB
准备表:
tbl_customer_recharge_record ,并初始化 7 条数据
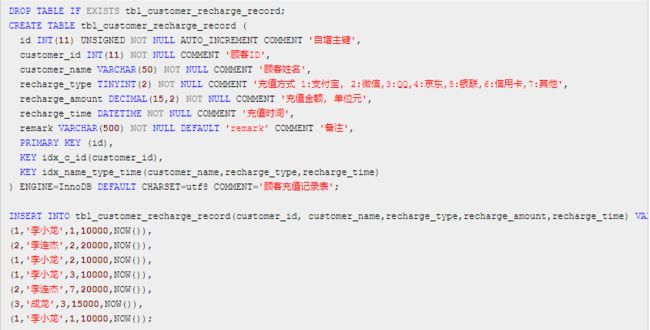
一共有 3 个索引:
id 列上的聚簇索引
customer_id 列上的二级索引: idx_c_id
以及 customer_name,recharge_type,recharge_time 列上的组合索引: idx_name_type_time
后面我们会用 EXPLAIN 来查看执行计划,查看索引使用情况,对它还不熟的小伙伴,赶紧点进去先看看
全表扫描更优
这是什么意思了,就是说优化器在进行优化的时候,会从众多可选的执行计划中选择它认为最优的那一个
当优化器计算得出通过全表查询比通过索引查询更优时,它会选择全表扫描的方式进行查询
SQL: explain select * from tbl_customer_recharge_record where customer_id = 2;

相信大家对这个没什么异议,通过 idx_c_id 来完成查询,跟我们预想的一样
对于 explain select * from
tbl_customer_recharge_record where customer_id = 1; 大家睁大眼睛看清楚了啊!

能用的索引包括: idx_c_id ,但实际没用它,而是走的全表查询;因为优化器认为走全表查询成本更低,查询更快
MySQL5.6 新引入的一项跟踪功能: OPTIMIZER_TRACE ,可以跟踪优化器做出的各种决策(比如访问表的方法、各种开销计算、各种转换等)
并将跟踪结果记录到
INFORMATION_SCHEMA.OPTIMIZER_TRACE 中
跟踪功能默认是关闭的,我们要用它的话,需要将其开启: set optimizer_trace='enabled=on';
查看优化器优化步骤: select * from
information_schema.OPTIMIZER_TRACE;
优化器对 select * from
tbl_customer_recharge_record where customer_id = 1; 优化步骤如下
{
"steps":[
{
"join_preparation":{
"select#":1,
"steps":[
{
"expanded_query":"/* select#1 */ select `tbl_customer_recharge_record`.`id` AS `id`,`tbl_customer_recharge_record`.`customer_id` AS `customer_id`,`tbl_customer_recharge_record`.`customer_name` AS `customer_name`,`tbl_customer_recharge_record`.`recharge_type` AS `recharge_type`,`tbl_customer_recharge_record`.`recharge_amount` AS `recharge_amount`,`tbl_customer_recharge_record`.`recharge_time` AS `recharge_time`,`tbl_customer_recharge_record`.`remark` AS `remark` from `tbl_customer_recharge_record` where (`tbl_customer_recharge_record`.`customer_id` = 1)"
}
]
}
},
{
"join_optimization":{
"select#":1,
"steps":[
{
"condition_processing":{
"condition":"WHERE",
"original_condition":"(`tbl_customer_recharge_record`.`customer_id` = 1)",
"steps":[
{
"transformation":"equality_propagation",
"resulting_condition":"multiple equal(1, `tbl_customer_recharge_record`.`customer_id`)"
},
{
"transformation":"constant_propagation",
"resulting_condition":"multiple equal(1, `tbl_customer_recharge_record`.`customer_id`)"
},
{
"transformation":"trivial_condition_removal",
"resulting_condition":"multiple equal(1, `tbl_customer_recharge_record`.`customer_id`)"
}
]
}
},
{
"substitute_generated_columns":{
}
},
{
"table_dependencies":[
{
"table":"`tbl_customer_recharge_record`",
"row_may_be_null":false,
"map_bit":0,
"depends_on_map_bits":[
]
}
]
},
{
"ref_optimizer_key_uses":[
{
"table":"`tbl_customer_recharge_record`",
"field":"customer_id",
"equals":"1",
"null_rejecting":false
}
]
},
{
"rows_estimation":[
{
"table":"`tbl_customer_recharge_record`",
"range_analysis":{
"table_scan":{
"rows":7,
"cost":4.5
},
"potential_range_indexes":[
{
"index":"PRIMARY",
"usable":false,
"cause":"not_applicable"
},
{
"index":"idx_c_id",
"usable":true,
"key_parts":[
"customer_id",
"id"
]
},
{
"index":"idx_name_type_time",
"usable":false,
"cause":"not_applicable"
}
],
"setup_range_conditions":[
],
"group_index_range":{
"chosen":false,
"cause":"not_group_by_or_distinct"
},
"analyzing_range_alternatives":{
"range_scan_alternatives":[
{
"index":"idx_c_id",
"ranges":[
"1 <= customer_id <= 1"
],
"index_dives_for_eq_ranges":true,
"rowid_ordered":true,
"using_mrr":false,
"index_only":false,
"rows":4,
"cost":5.81,
"chosen":false,
"cause":"cost"
}
],
"analyzing_roworder_intersect":{
"usable":false,
"cause":"too_few_roworder_scans"
}
}
}
}
]
},
{
"considered_execution_plans":[
{
"plan_prefix":[
],
"table":"`tbl_customer_recharge_record`",
"best_access_path":{
"considered_access_paths":[
{
"access_type":"ref",
"index":"idx_c_id",
"rows":4,
"cost":2.8,
"chosen":true
},
{
"rows_to_scan":7,
"access_type":"scan",
"resulting_rows":7,
"cost":2.4,
"chosen":true
}
]
},
"condition_filtering_pct":100,
"rows_for_plan":7,
"cost_for_plan":2.4,
"chosen":true
}
]
},
{
"attaching_conditions_to_tables":{
"original_condition":"(`tbl_customer_recharge_record`.`customer_id` = 1)",
"attached_conditions_computation":[
],
"attached_conditions_summary":[
{
"table":"`tbl_customer_recharge_record`",
"attached":"(`tbl_customer_recharge_record`.`customer_id` = 1)"
}
]
}
},
{
"refine_plan":[
{
"table":"`tbl_customer_recharge_record`"
}
]
}
]
}
},
{
"join_execution":{
"select#":1,
"steps":[
]
}
}
]
}内容有点多,我们只关注

相比于使用索引,全表扫描效率更高,那为什么还选择索引呢?
LIKE 进行后方一致或中间一致的匹配
说的更通俗一点,就是以 % 开头进行匹配
如果 LIKE 进行前方一致匹配,索引还是会生效的
SQL: explain select * from
tbl_customer_recharge_record where customer_name like '成%';

如果以 % 开头进行匹配,则不会用到索引
SQL: explain select * from
tbl_customer_recharge_record where customer_name like '%杰';

OR 前后未同时使用索引
数据量太少,优化器会选择全表扫描,而不走索引了,我们再加点数据
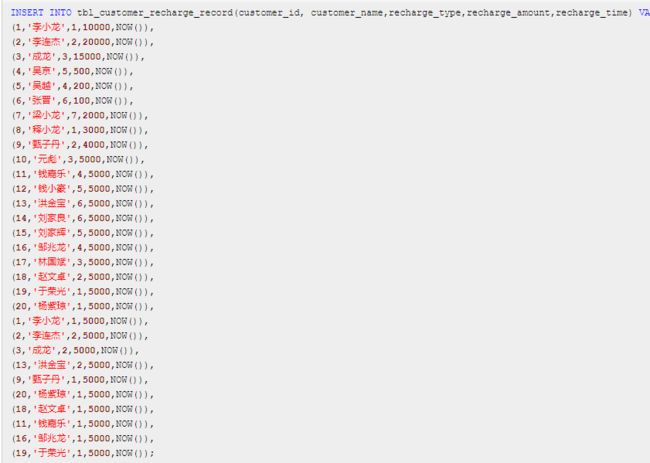

OR 前后都能用到索引的话,还是会走索引查询的
只要 OR 前后有一个走不了索引,那就会全表扫描了

组合索引,未遵循最左匹配原则
最左匹配指的是,按组合索引指定的列顺序,从左往右逐个列匹配,像这样

不能直接跨过前面的列,否则就不能用到索引了

强烈建议:组合索引中的第一列必须写在查询条件的开头,而且索引中列的顺序不能颠倒
虽说有些数据库(例如 MySQL)里顺序颠倒后也能使用索引(优化器会优化列顺序来适配索引),但是性能还是比顺序正确时差一些
至于为什么要遵从最左匹配原则,大家可以结合前面讲过的组合索引的数据结构来分析(还觉得我前戏太多吗,啊!)
使用否定形式
否定形式包括:<>, !=, NOT IN,NOT EXIST,会导致全表扫描

索引列上进行运算
说的更准确点,是在查询条件的左侧进行运算,这种情况就不能用索引了

在查询条件的右侧进行计算,还是能用到索引的

索引列上使用函数
说的更准确点,是在查询条件的左侧使用函数,这种情况就不能用索引了

在右侧使用函数,还是能用到索引的

强烈建议:使用索引时,条件表达式的左侧应该是原始列
进行默认的类型转换
新建表: tbl_char ,并初始化 7 条数据
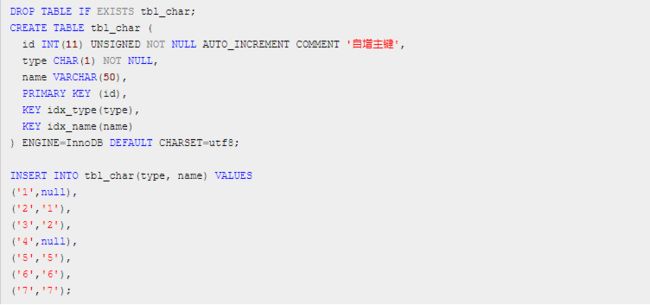
type 的类型是 char
SQL: explain select * from tbl_char where type = 2;

默认的类型转换不仅会增加额外的性能开销,还会导致索引不可用,可以说是有百害而无一利
(对于 int 类型的列,传字符串类型的值是可以走索引的,MySQL 内部自动做了隐式类型转换;相反,对于 char 或 varchar 类型的列,传入 int 值是无法走索引的)
强烈建议:使用索引时,条件表达式的右侧常数的类型应该与列类型保持一致
IS NULL 与 IS NOT NULL
我做个简单的测试,就不下结论了
SQL: explain select * from tbl_char where name is not null;

SQL: explain select * from tbl_char where name is null;

强烈建议:所有列都指定 NOT NULL 和默认值
NULL 的陷阱太多,详情可查看:神奇的 SQL 之温柔的陷阱 → 三值逻辑 与 NULL !
不走索引的情况,文中只列举了常见的部分,还有其他的场景未列举,欢迎小伙伴们补充
总结
1、索引数据结构
索引的数据结构包括 哈希表、B树、B+树 等,而用的最多的就是 B+数
2、未走索引的常见场景
全表扫描优于索引扫描
LIKE 进行后方一致或中间一致的匹配
OR 前后未同时使用索引
组合索引,未遵循最左匹配原则
进行默认的类型转换
使用否定形式
索引列上进行运算
索引列上使用函数
3、推荐做法
使用组合索引时,组合索引中的第一列必须写在查询条件的开头,而且索引中列的顺序不能颠倒
使用索引时,条件表达式的左侧应该是原始列,右侧是常数且类型与左侧列一致,左右侧都不参与计算、使用函数(计算、函数运算、逻辑处理都交由专门的开发语言去实现)
所有列都指定 NOT NULL 和默认值,避免 NULL 的陷阱
资源获取:
大家点赞、收藏、关注、评论啦 、查看微信公众号获取联系方式
精彩专栏推荐订阅:在下方专栏
每天学四小时:Java+Spring+JVM+分布式高并发,架构师指日可待