torch.gather()原理讲解,并结合BERT分词的实际应用
torch.gather()使用方法
问题分析
在阅读OneIE代码时,突然看到一段代码十分精妙,用来预测BERT等预训练语言模型在使用tokenizer进行分词时,会将一个单词可能分成多个token,如原始句子为"(END VIDEO CLIP)",正常理解按照空格和字符进行划分为["(", "END", "VIDEO", "CLIP", ")"],然而BERT的划分结果为["(", "E", "##ND", "VI", "##DE", "##O", "C", "##L", "##IP", ")"],则每个token对应的长度为token_lens=[1, 2, 3, 3, 1]。所以在经过BERT之后,单词END的表征将变成了两个部分(E,##ND),所以END的表示便有了歧义,常见的做法有:1、取E和##ND表征的平均值。2、取E来表示END。3、E和##ND表征进行连接,在经过线性变化进行降维。如果还有其他做法可以进行补充。
为什么上述问题要用到torch.gather()函数呢?这个是因为这个函数可以按照给出的索引对原始的tensor进行取值,类似于列表中的索引和切片。
原理分析
先看官方文档,官方文档给出了函数的定义及其相关解析。
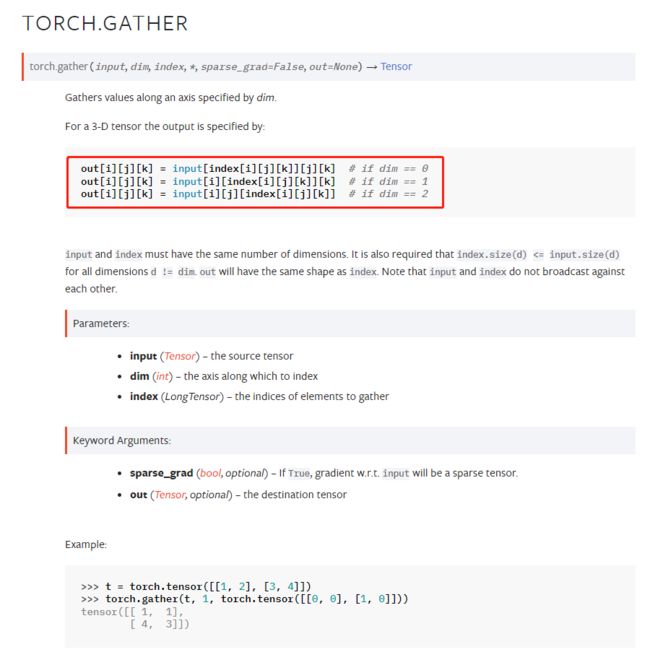
红色框中表明了函数根据index的索引进行取值的规则。建议多看几遍!!!dim的取值为多少,就代表
函数存在三个输入参数:
input:表示输入向量
dim:按照该轴进行取值,和常规的函数相同用法
index:需要在输入向量中取值的索引位置
值得注意是,dim的值要小于输入向量input的维度,如果是一个二维的向量,则dim只能取值为0或1,和常规的函数相同使用。函数输出的向量形状和index向量必须一致。index向量中的取值要小于input的形状维度。更加详细的规则如下所示:
以官方示例为例,

扩展dim=0将会产生不一样的结果

BERT的token表征分析
回到问题中,部分token在tokenizer时会分成多个表示,我们将以OneIE代码为例进行分析和讲解:
from transformers import BertTokenizer, BertModel
import torch
def token_lens_to_idxs(token_lens):
"""Map token lengths to a word piece index matrix (for torch.gather) and a
mask tensor.
For example (only show a sequence instead of a batch):
token lengths: [1,1,1,3,1]
=>
indices: [[0,0,0], [1,0,0], [2,0,0], [3,4,5], [6,0,0]]
masks: [[1.0, 0.0, 0.0], [1.0, 0.0, 0.0], [1.0, 0.0, 0.0],
[0.33, 0.33, 0.33], [1.0, 0.0, 0.0]]
Next, we use torch.gather() to select vectors of word pieces for each token,
and average them as follows (incomplete code):
outputs = torch.gather(bert_outputs, 1, indices) * masks
outputs = bert_outputs.view(batch_size, seq_len, -1, self.bert_dim)
outputs = bert_outputs.sum(2)
:param token_lens (list): token lengths. (batch,seq_len)
:return: a index matrix and a mask tensor.
"""
max_token_num = max([len(x) for x in token_lens])
max_token_len = max([max(x) for x in token_lens])
idxs, masks = [], []
for seq_token_lens in token_lens:
seq_idxs, seq_masks = [], []
offset = 0
for token_len in seq_token_lens:
seq_idxs.extend([i + offset for i in range(token_len)
] + [-1] * (max_token_len - token_len))
seq_masks.extend([1.0 / token_len] * token_len +
[0.0] * (max_token_len - token_len))
offset += token_len
seq_idxs.extend([-1] * max_token_len *
(max_token_num - len(seq_token_lens)))
seq_masks.extend([0.0] * max_token_len *
(max_token_num - len(seq_token_lens)))
idxs.append(seq_idxs)
masks.append(seq_masks)
return idxs, masks, max_token_num, max_token_len
def data_process(datas):
token_lens = []
tokens = []
pieces = []
sentences = []
for data in datas:
token_lens.append(data['token_lens'])
tokens.append(data['tokens'])
pieces.append(data['pieces'])
sentences.append(data['sentence'])
return token_lens, tokens, pieces, sentences
def get_bert_input(pieces, tokenizer, max_length=24):
_piece_idxs = []
_attn_masks = []
for piece in pieces:
piece_idxs = tokenizer.encode(piece,
add_special_tokens=True,
max_length=max_length,
truncation=True)
pad_num = max_length - len(piece_idxs)
attn_mask = [1] * len(piece_idxs) + [0] * pad_num
piece_idxs = piece_idxs + [0] * pad_num
_piece_idxs.append(piece_idxs)
_attn_masks.append(attn_mask)
_piece_idxs = torch.LongTensor(_piece_idxs)
_attn_masks = torch.LongTensor(_attn_masks)
return _piece_idxs, _attn_masks
data_example = [{"doc_id": "CNN_IP_20030409.1600.02", "sent_id": "CNN_IP_20030409.1600.02-21", "tokens": ["Yet", "until", "this", "war", "is", "fully", "won", ",", "we", "cannot", "be", "overconfident", "in", "our", "position", "."], "pieces": ["Yet", "until", "this", "war", "is", "fully", "won", ",", "we", "cannot", "be", "over", "##con", "##fi", "##dent", "in", "our", "position", "."], "token_lens": [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 4, 1, 1, 1, 1], "sentence": "Yet until this war is fully won, we cannot be overconfident in our position.", "entity_mentions": [{"id": "CNN_IP_20030409.1600.02-E10-53", "text": "we", "entity_type": "GPE", "mention_type": "PRO", "entity_subtype": "Nation", "start": 8, "end": 9}, {"id": "CNN_IP_20030409.1600.02-E10-54", "text": "our", "entity_type": "GPE", "mention_type": "PRO", "entity_subtype": "Nation", "start": 13, "end": 14}], "relation_mentions": [], "event_mentions": [{"id": "CNN_IP_20030409.1600.02-EV1-1", "event_type": "Conflict:Attack", "trigger": {"text": "war", "start": 3, "end": 4}, "arguments": []}]},
{"doc_id": "CNN_IP_20030409.1600.02", "sent_id": "CNN_IP_20030409.1600.02-22", "tokens": ["And", "we", "must", "not", "underestimate", "the", "desperation", "of", "whatever", "forces", "remain", "loyal", "to", "the", "dictator", "."], "pieces": ["And", "we", "must", "not", "under", "##est", "##imate", "the", "desperation", "of", "whatever", "forces", "remain", "loyal", "to", "the", "dictator", "."], "token_lens": [1, 1, 1, 1, 3, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], "sentence": "And we must not underestimate the desperation of whatever forces remain loyal to the dictator.", "entity_mentions": [{"id": "CNN_IP_20030409.1600.02-E10-55", "text": "we", "entity_type": "GPE", "mention_type": "PRO", "entity_subtype": "Nation", "start": 1, "end": 2}, {
"id": "CNN_IP_20030409.1600.02-E31-56", "text": "forces", "entity_type": "PER", "mention_type": "NOM", "entity_subtype": "Group", "start": 9, "end": 10}, {"id": "CNN_IP_20030409.1600.02-E12-57", "text": "dictator", "entity_type": "PER", "mention_type": "NOM", "entity_subtype": "Individual", "start": 14, "end": 15}], "relation_mentions": [{"id": "CNN_IP_20030409.1600.02-R17-1", "relation_type": "GEN-AFF", "relation_subtype": "GEN-AFF:Citizen-Resident-Religion-Ethnicity", "arguments": [{"entity_id": "CNN_IP_20030409.1600.02-E31-56", "text": "forces", "role": "Arg-1"}, {"entity_id": "CNN_IP_20030409.1600.02-E12-57", "text": "dictator", "role": "Arg-2"}]}], "event_mentions": []},
{"doc_id": "CNN_IP_20030409.1600.02", "sent_id": "CNN_IP_20030409.1600.02-23", "tokens": ["(", "END", "VIDEO", "CLIP", ")"], "pieces": ["(", "E", "##ND", "VI", "##DE", "##O", "C", "##L", "##IP", ")"], "token_lens": [
1, 2, 3, 3, 1], "sentence": "(END VIDEO CLIP)", "entity_mentions": [], "relation_mentions": [], "event_mentions": []},
{"doc_id": "CNN_IP_20030409.1600.02", "sent_id": "CNN_IP_20030409.1600.02-18", "tokens": ["(", "BEGIN", "VIDEO", "CLIP", ")"], "pieces": ["(", "B", "##EG", "##IN", "VI", "##DE", "##O", "C", "##L", "##IP", ")"], "token_lens": [1, 3, 3, 3, 1], "sentence": "(BEGIN VIDEO CLIP)", "entity_mentions": [], "relation_mentions": [], "event_mentions": []}]
bert_dim = 1536
batch_size = 1
tokenizer = BertTokenizer.from_pretrained('./bert/bert-base-cased')
# output_hidden_states=True,表示输出bert中间层的结果
bert = BertModel.from_pretrained(
'./bert/bert-base-cased', output_hidden_states=True)
token_lens, tokens, pieces, sentences = data_process(data_example)
piece_idxs, attention_masks = get_bert_input(pieces, tokenizer, 24)
all_bert_outputs = bert(piece_idxs, attention_mask=attention_masks)
bert_outputs = all_bert_outputs[0]
# 取BERT倒数第三层的输出连接,使效果更佳
extra_bert_outputs = all_bert_outputs[2][-3]
bert_outputs = torch.cat([bert_outputs, extra_bert_outputs], dim=2)
# 最为关键多个token融合,并选出最终的bert输出表示
idxs, masks, token_num, token_len = token_lens_to_idxs(token_lens)
# +1 是因为第一个向量是[CLS],并且将idxs中最小值有-1变化为0,expand是为了进行广播
idxs = piece_idxs.new(idxs).unsqueeze(-1).expand(batch_size, -1, bert_dim) + 1
# 便于后续的矩阵逐元素乘法
masks = bert_outputs.new(masks).unsqueeze(-1)
# 逐元素乘法,因为mask会对多个词token进行平均化,并且将没有分割的token的mask填充置0
bert_outputs = torch.gather(bert_outputs, 1, idxs) * masks
bert_outputs = bert_outputs.view(batch_size, token_num, token_len, bert_dim)
bert_outputs = bert_outputs.sum(2)
print(bert_outputs)
上述代码就是采用方法一,取E和##ND表征的平均值进行特征融合,如果还是很复杂,可以看以下精简版代码示例就可以看出特征融合的原理,最好自己运行代码查看:
import torch
bert_outputs = torch.rand((1, 12, 8))
idxs = [0, -1, -1, 1, -1, -1, 2, 3, -1, 4, -1, -1]
masks = [1, 0, 0, 1, 0, 0, 0.5, 0.5, 0, 1, 0, 0]
idxs = torch.LongTensor(idxs)
idxs = idxs.unsqueeze(-1).expand(1, -1, 8) + 1
# 便于后续的矩阵逐元素乘法
masks = bert_outputs.new(masks).unsqueeze(-1)
# 逐元素乘法,因为mask会对多个词token进行平均化,并且将没有分割的token的mask填充置0,
# dim=1表示在bert_outputs的seq上进行采样,gather对batch和dimension上维度保持不变,在乘mask则会将多余的清零
print(bert_outputs)
bert_outputs = torch.gather(bert_outputs, 1, idxs)
print(bert_outputs)
bert_outputs=bert_outputs* masks
print(bert_outputs)
bert_outputs = bert_outputs.view(1, 4, 3, 8)
bert_outputs = bert_outputs.sum(2)
print(bert_outputs)
gather函数实在是精妙无比,以一段代码解决了复杂的特征融合方式。
参考资料
https://zhuanlan.zhihu.com/p/352877584
https://blog.csdn.net/weixin_42200930/article/details/108995776 (推荐阅读)