JDBC概述三(批处理+事务操作+数据库连接池)
一(批处理)
1.1 批处理简介
批处理,简而言之就是一次性执行多条SQL语句,在一定程度上可以提升执行SQL语句的速率。批处理可以通过使用Java的Statement和PreparedStatement来完成,因为这两个语句提供了用于处理批处理的方法。
1.2 批处理的3个方法
1.void addBatch(String sql):将需要执行的SQL语句添加到批处理中。
2.int [] executeBatch();执行批处理。
3.clearBatch();清空批处理。
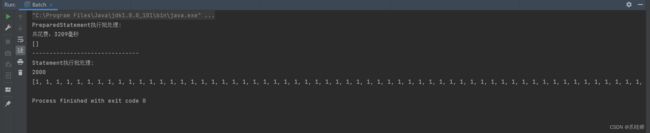
分别使用Statement和PreparedStatement执行批处理:
package batch.transaction;
import com.yxp.util.DBUtils;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.Arrays;
/**
* 批处理:本质就是执行多条SQL语句
* 步骤1.添加进批处理addBath()
* 步骤2.执行批处理executeBatch()
* 步骤3.清空批处理clearBatch()
*/
public class Batch {
static Connection con= null;
public static void main(String[] args) throws SQLException {
/**
* 使用封装思想,更加贴近面向对象设计,代码的可读性更高
*/
//PreparedStatement执行批处理
System.out.println("PreparedStatement执行批处理:");
ps(con);
System.out.println("-------------------------------");
//Statement执行批处理
System.out.println("Statement执行批处理:");
st(con);
}
private static void st(Connection con) throws SQLException {
//1.获得连接
con=DBUtils.getConnection();
//2.获得语句处理对象
Statement s=con.createStatement();
for (int i =1; i <=2000 ; i++) {
//3.写sql语句
String sql_Statement="insert into t1_batch(name)values ('"+i+"')";
//4.将sql语句放入批处理对象中
s.addBatch(sql_Statement);
}
//5.执行批处理
int[] arr1=s.executeBatch();
//6.清空批处理
s.clearBatch();
System.out.println(arr1.length);
System.out.println(Arrays.toString(arr1));
}
private static void ps(Connection con) throws SQLException {
//1.获得连接
con= DBUtils.getConnection();
//2.写sql语句
String sql_preparedStatement="insert into t1_batch (name)values (?)";
//3.获得语句处理对象
PreparedStatement ps=con.prepareStatement(sql_preparedStatement);
long time1=System.currentTimeMillis();
for (int i = 1; i <=2000 ; i++) {
//4.参数赋值
ps.setString(1,i+"_");
//5.添加进批处理
ps.addBatch();
if(i%500==0){//每添加500个才执行一次,防止内存溢出
//6.执行批处理
ps.executeBatch();
//每执行一次批处理就清空一次
ps.clearBatch();
}
}
//此段仍然不能丢失,剩余的可能不是500整数的需要单独处理
int[] arr=ps.executeBatch();//一条sql语句更新处理以后,返回一个int数据,批处理他返回的是一个int[]
//7.清空批处理
ps.clearBatch();
long time2=System.currentTimeMillis();
System.out.println("共花费:"+(time2-time1)+"毫秒");
System.out.println(Arrays.toString(arr));
}
}
二(事务操作)
2.1 事务的简介
事务指逻辑上的一组操作,组成这组操作的各个单元,要么全部成功,要么全部失败。在不同的环境中,都可以有事务。对应在数据库中,就是数据库事务。(访问并可能操作各种数据项的一个数据库操作序列)。 事务由事务开始(begin transaction)和事务结束(end transaction)之间执行的全体操作组成。
事务结束有两种,事务中的步骤全部成功执行时,提交事务。如果其中一个失败,那么将会发生回滚操作,并且撤销之前的所有操作。也就是说,事务内的语句,要么全部执行成功,要么全部执行失败。
2.2 事务四大特征ACID
2.2.1. 原子性(Atomicity)
原子性是指事务是一个不可分割的工作单位,整个事务中的所有操作要么全部提交成功,要么全部失败回滚,对于一个事务来说,不可能只执行其中的一部分操作。
2.2.2 一致性(Consistency)
一致性是指事务必须使数据库从一个一致性状态变换到另一个一致性状态。也就是说事务前后数据的完整性必须保持一致。
2.2.3 隔离性(Isolation)
隔离性是指一个事务的执行不能有其他事务的干扰,事务的内部操作和使用数据对其他的并发事务是隔离的,互不干扰。
2.2.4 持久性(Durability)
持久性是指一个事务一旦提交,对数据库中数据的改变就是永久性的。此时即使数据库发生故障,修改的数据也不会丢失。接下来其他的操作不会对已经提交了的事务产生影响。
模拟转账操作
package batch.transaction;
import com.yxp.util.DBUtils;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.SQLException;
/**
* 事务4大特性:ACID
* 1.原子性Atomicity
* 2.一致性Consistency
* 3.隔离性Isolation
* 4、持久性Duration
*/
//模拟转账操作
public class Transaaction {
static Connection con= null;
static PreparedStatement ps=null;
public static void main(String[] args) {
transferaccounts(1,2,10000);
}
/**
*
* @param from 从谁的账户转
* @param to 转给谁
* @param money 转多少
*/
private static void transferaccounts(int from, int to,double money) {
//1.获得连接
con= DBUtils.getConnection();
//2.写sql语句
String sql1="update t1_icbc set money=money-? where id=? ";
String sql2="update t1_icbc set money=money+? where id=? ";
//3.获得语句处理对象
try {
PreparedStatement ps1=con.prepareStatement(sql1);
PreparedStatement ps2=con.prepareStatement(sql2);
//4.参数赋值
ps1.setDouble(1,money);
ps1.setInt(2,from);
ps2.setDouble(1,money);
ps2.setInt(2,to);
//如果需要回滚,需要设置事务手动提交
con.setAutoCommit(false);
//5.执行sql
int res1=ps1.executeUpdate();
/**
* 模拟一个异常,程序结束
*/
int a=4/0;
int res2=ps2.executeUpdate();
//判定:当二者都执行成功了
if(res1==1&&res2==1){
con.commit();//提交事务
}
} catch (Exception throwables) {
throwables.printStackTrace();
//数据要回滚,本身sql是默认自动提交事务的,无法回滚
//异常被捕获,说明之前提交的数据需要回滚
try {
System.out.println("哎呀,转账失败……");
con.rollback();//事务回滚
} catch (SQLException e) {
e.printStackTrace();
}finally {
//由于数据库现在被设置手动提交,为了防止影响后续操作,运行以后一定需要将提交方式设置为自动
try {
con.setAutoCommit(true);
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}
}
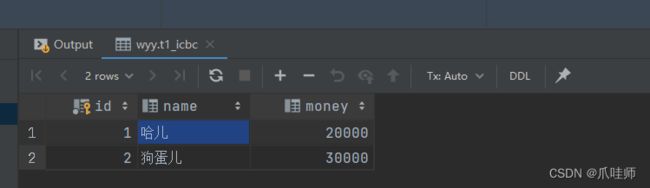
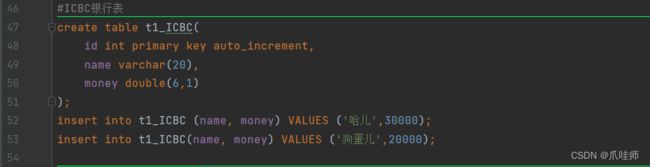 转账前,哈儿有30000元,狗蛋儿有20000元,当哈儿给狗蛋转账10000元后,哈儿就变成20000元,狗蛋儿就有30000元。
转账前,哈儿有30000元,狗蛋儿有20000元,当哈儿给狗蛋转账10000元后,哈儿就变成20000元,狗蛋儿就有30000元。
1.脏读
脏读是指在一个事务处理过程里读取了另一个未提交的事务中的数据。比如在事务 A 修改数据之后提交数据之前,这时另一个事务 B 来读取数据,如果不加控制,事务 B 读取到 A 修改过数据,之后 A 又对数据做了修改再提交,则 B 读到的数据是脏数据,此过程称为脏读。
2.不可重复读
不可重复读是指在数据库访问中,一个事务范围内多次查询却返回了不同的数据值。这是由于在查询间隔中,其他事务修改并提交而引起的。比如事务 T1 读取某一数据,事务 T2 读取并修改了该数据,T1 为了对读取值进行检验而再次读取该数据,便得到了不同的结果。
3. 幻读
幻读是指当事务不是独立执行时发生的一种现象,例如第一个事务对一个表中的数据进行了修改,比如这种修改涉及到表中的全部数据行。同时,第二个事务也修改这个表中的数据,这种修改是向表中插入一行新数据。那么,以后就会发生操作第一个事务的用户发现表中还有没有修改的数据行,就好象发生了幻觉一样。比如事务 A 在按查询条件读取某个范围的记录时,事务 B 又在该范围内插入了新的满足条件的记录,当事务 A 再次按条件查询记录时,会产生新的满足条件的记录。
SQL的四个隔离级别
1.未提交读(Read Uncommitted)
一个事务能够读取到别的事务中没有提交的更新数据。事务中的修改,即使没有提交,其他事务也可以看得到。在这种隔离级别下有可能发生脏读,不可重复读和幻读。
2.提交读(Read Committed)
事务中的修改只有提交以后才能被其它事务看到。在这种隔离级别下解决了脏读,但是有可能发生不可重复读和幻读。
3.可重复读(Repeated Read)
保证了在同一事务中先后执行的多次查询将返回同一结果,看到的每行的记录的结果是一致的,不受其他事务的影响。但是这种级别下有可能发生幻读。
4.可串行化(Serializable)
不允许事务并发执行,强制事务串行执行。就是在读取的每一行数据上都加上了锁,读写相互都会阻塞,所以效率很低下。这种隔离级别最高,是最安全的,但是性能最低,不会出现脏读,不可重复读,幻读。
三(数据库连接池)
3.1 数据库连接池简介
简而言之,就是一个容器内有多个数据库连接,当程序需要操作数据库的时候直接从池中取出连接,使用完之后再还回去,和线程池一个道理。连接池必须实现javax.sql.DataSource 接口,连接池里面维护的是一个DataSource的数据源。
3.2 使用数据库连接池的好处
(1)节省资源,如果每次访问数据库都创建新的连接,创建和销毁都浪费系统资源
(2)响应性更好,省去了创建的时间。
(3)统一的进行数据库管理,超时机制,减少JVM垃圾,减少数据库的过载。
3.3 常见的数据库连接池对象
1.DBCP2(DataBase Connection Pool 2)
数据库连接池,从Tomcat 5.5开始,Tomcat 内置了DBCP的数据源实现,所以可以非常方便地配置DBCP数据源.
2. C3P0
hibernate工作组进行维护,自动回收空闲连接。
3.德鲁伊 Druid
3.4 数据库连接池的常见参数配置
1、driverClassName 使用的JDBC驱动的完整有效的Java类名,如连接 mysql:com.mysql.cj.jdbc.Driver
2、url 数据库的连接地址。如 jdbc:mysql://127.0.0.1:3306/mydatabase
3、username 数据库的用户名,如 root
4、password 数据库的用户密码
5、initialSize 连接池创建的时候,自动创建的数据库连接数量(初始化连接数量),建议 10-50足够
6、maxIdle 最大空闲连接:连接池中允许保持空闲状态的最大连接数量,超过的空闲连接将被释放,如果设置为负数表示不限制,建议设置和 与initialSize相同,减少释放和创建的性能损耗。
7、minIdle 最小空闲连接:连接池中容许保持空闲状态的最小连接数量,低于这个数量将创建新的连接,如果设置为0则不创建
8、maxActive 最大同时激活的连接数量。
9、maxWait 如果连接池中没有可用的连接,最大的等待时间,超时则没有可用连接,单位毫秒,设置-1时表示无限等待,建议设置为100毫秒
10、testxxx 在对连接进行操作时,是否检测连接的有效性,如 testOnBorrow 在申请连接的时候会先检测连接的有效性,执行validationQuery ,建议线上的把此配置设置为false,因为会影响性能。
11、validationQuery 检查池中的连接是否仍可用的 SQL 语句,drui会连接到数据库执行该SQL, 如果正常返回,则表示连接可用,否则表示连接不可用,建议 select 1 from dual
3.5 如何使用Druid
1.导入druid jar包
![]()
3.5.2 使用数据库连接池与数据库获得连接
配置文件:druid.properties
driverClassName=com.mysql.cj.jdbc.Driver
url=jdbc:mysql://localhost:3306/wyy?serverTimezone=UTC&characterEncoding=utf8&useUnicode=true&useSSL=false&allowPublicKeyRetrieval=true
username=root
password=123456
#初始化连接数量
initialSize=5
#最大的活动连接
maxActive=10
#最大的等待时间
maxWait=6000package druid;
import com.alibaba.druid.pool.DruidDataSourceFactory;
import javax.sql.DataSource;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStream;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.Properties;
public class DruidUtil {
//连接池里面维护的是一个DataSource的数据源
private static DataSource dataSource;
static {
Properties p=new Properties();
try {
InputStream is=new FileInputStream("D:\\javaEE\\VIP07_1\\jdbc\\src\\druid\\druid.properties");
//使用配置文件对象读取字节流
p.load(is);
//数据源赋值
dataSource= DruidDataSourceFactory.createDataSource(p);
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 获得连接对象
*/
public static Connection getCon(){
Connection conn=null;
try {
conn=dataSource.getConnection();
} catch (SQLException e) {
e.printStackTrace();
}
return conn;
}
/**
* 关闭链接
*/
public static void close(Connection conn, Statement ps, ResultSet rs){
if(rs!=null){
try {
rs.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if(ps!=null){
try {
ps.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if(conn!=null){
try {
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) {
System.out.println(getCon());
}
}
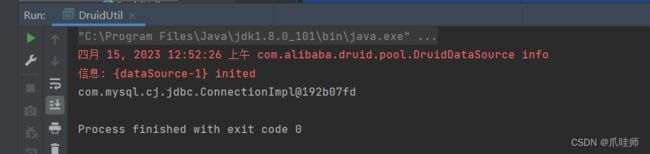
经测试,使用数据库连接池来与数据库获得连接,同样连接成功。