【Redis 进阶之路】4. Redis 预分区 以及集群
1. 分区的目的:
想要知道分区的目的,首先我们要知道如果是单实例的话,会出现什么问题:
- 单点故障
- 压力大
- 内存容量有限
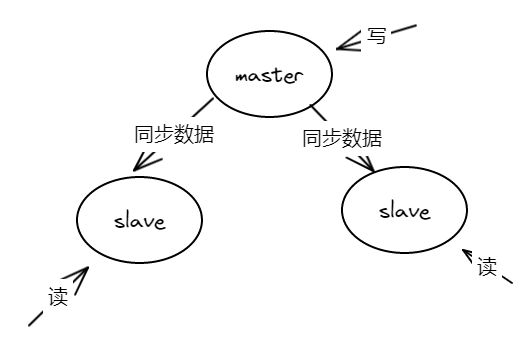
上述截图是简约版的主从部署架构(一主两从)。如果项目中部署了主从架构,从一定程度上可以解决压力大,单点故障的问题。
但是主从架构其实是将数据全量的备份到slave节点,所以相同的数据会在三个节点同时出现。
这种主从架构并没有解决内存容量有限的问题
但是实际生产环境中并非一定要将数据添加到一台Redis中,我们可以部署多台Redis实例,将不同的数据分散打入到不同的Redis中,其实这就是我们所说的分区。 那就让我们一步一步来看下分区的演进:
2. 实现分区的方式
2.1 手动干预分区:

如果数据之间关联不大的话,我们可以通过在client端手动干预,将不同的数据手动打入不同的Redis实例中,通过这种方式来完成数据的分区
缺点:
- 前置条件过于苛刻,真正的业务数据中很少有关联性不大的
- 如果要添加一台或是几台Redis实例的话,数据的平移都需要手动干预
2.2 hash 以及取模:

我们可以通过上述的hash + 取模来实现数据的分区,其实也是需要client端进行干预
缺点:
- 取模数就是Redis实例的个数,是固定的,按指定个数将数据划分到不同的实例,如果实例个数一旦发生变化,会找不到原来的值。除非每次增加/ 减少实例后,进行
rehash操作 - 影响分布式下的扩展性
2.3 random 随机

上述截图中,多个Redis实例中都存在相同的keyooxx. 当请求发送过来的时候利用API lpush向Redis中推送数。随机保存到不同实例的相同key中。另一端使用rpop来进行消费。
有点类似于消息队列的性质,先进先消费。在高并发下将内容保存到多台实例中,再以一定速度去消费
缺点:
- 因为是
random,所以随机性太大,从一端无法获取到数据 - 因为是不同的数据,推送到不同实例的相同key中。消费端不一定连接哪台实例进行消费,所以总体的顺序是无法保证的
2.4 一致性Hash 算法
其实此方案也算是相对权威的方案了。但是讲述此方法之前我们先来回顾下上述的方案有什么不足:
- 上述的方案,如果实例不增加或是减少的情况下还行。一旦出现了改变实例个数,依据
取模运算就无法定位到存在数据的实例了 - 其结果都是不利于
分布式扩展
2.4.1 什么是一致性Hash
我们先来看下,一致性Hash的官方定义,无非是解决:分布式缓存的问题。
如果没有一致性Hash应该怎么做呢???
-
我们分布式缓存的目的之一:就是为了解决服务器中缓存不足的问题,我们需要将不同的数据分散到不同的服务器上。那我们怎么能平均的分散的不同的服务器上呢???
取模运算必不可少。一旦牵扯到固定值模数。弊端就暴露出来了。 -
因为每次读取缓存/ 更新缓存,都需要通过
hash + 取模来确定哪台服务器。 但是如果服务器的个数发生变化,那么通过计算的结果都不正确了,可以理解为间接导致缓存失效。
我们一致性Hash算法就是在增加/ 减少 服务器时,能够尽可能小得改变已存在的服务请求 以及处理请求服务之间的映射关系
2.4.2 一致性Hash讲解实例
可以先看下 上述讲述的官方定义后,再来看接下来的内容:
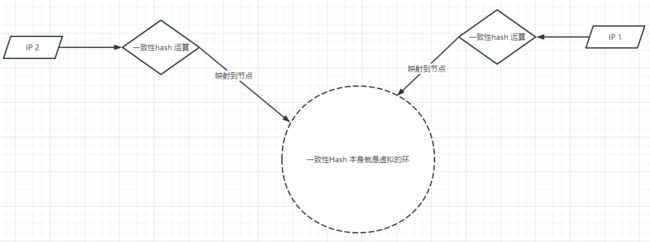
从虚拟的角度来讲的话,可以将一致性Hash 理解为一个闭环。这个环的长度是![]() .
.
而我们获取服务器的node(这里的node,可以是IP,也可以是服务器的id。 保存唯一就行) 通过hash运算 映射到Hash环中的一个位置。说到这里就跟取模没什么关系了
如果我们想存储数据,数据的基础结构一般是:key/ vaue. 我们可以拿到key,经过hash运算,再次拿到闭环中一个对应的值,此值在闭环中不一定有内容(有内容指的是:通过IP(node) 映射到该节点)。但是我们可以向前找,找到被映射到的节点,从该节点对应的服务器中进行 增删改查。如下图所示:
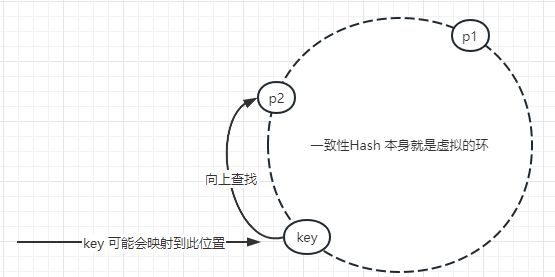
如果说此时有新服务器加入怎么办呢???
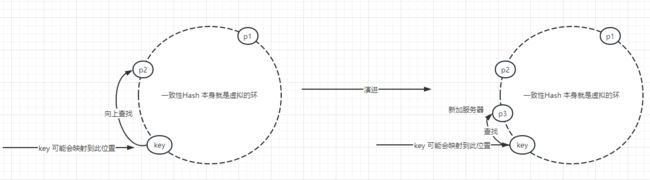
会出现如上图所示:
有可能会添加一个服务器p3. 还是使用原来的key 进行查询 以及添加。 如果向上找的时候,可能会找不到数据。但是最起码不会影响到别的数据,所以使用一致性Hash也是存在一定问题
优点:增加/ 减少服务器 不会影响到别的数据(其实这个就是,一致性Hash的目的)。
缺点:如果增加服务器后,可能会出现部分数据查询不到。
综合上述而言,这种方式更倾向于做缓存,而不是数据库
3. Redis Server 连接成本
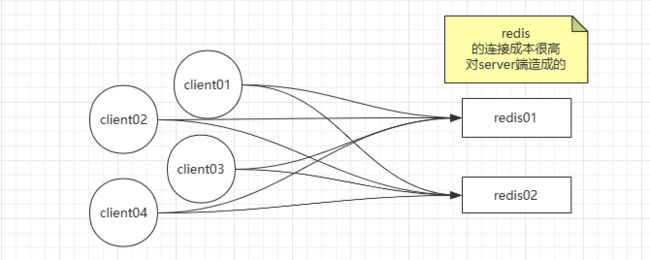
如上述截图所示:
如果高并发的情况下,每台client都会连接Redis Server。连接成本是非常高的

其实我们可以在client以及Redis Server端之间,添加一个代理层。
其实代理层就是一个转发的过程。 我们只要关注代理层的性能就可以了
4. 预分区
我们上述讨论的方案都是基于现有Redis实例,进行分区。那什么叫
预分区呢
比如:此时公司的Redis服务器是3台,但是会随着业务的不断扩大,同时增加Redis服务器,最大可以部署到10台。那我们就可以基于10台服务器进行预分区,而不是真实的3台服务器
其实10台服务器的预分区跟部署3台服务器,从本质来说没有任何变化,只不过需要添加映射关系,怎么理解呢???

因为我们的最大部署实例是10台,但是目前只有3台服务器。
我们可以将计算Hash结果进行10的取模运算. 通过一定的映射关系来找到具体的Redis实例。比如:我们规定,如果是0~2都会放到第一台服务器中,5~7放到第二台服务器中,以此类推。
如果此时服务器增加到了4台,我们可以重新调整mapping 映射关系。如下图:
- 我们只需要修改代理层的
Mapping 映射关系 - 同时将部分Redis上的数据 移动到新的Redis实例上
- 这样做其实避免了Hash运算,同时也避免了获取不到数据
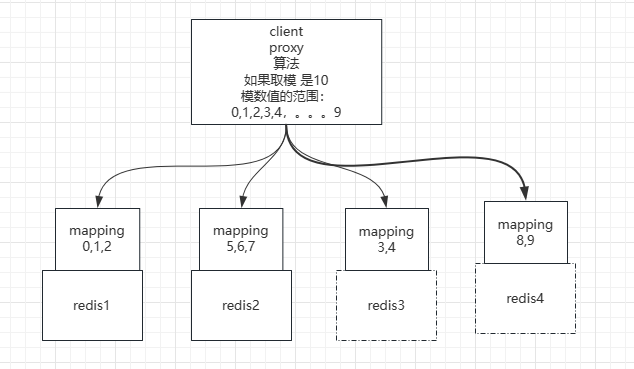
但是即使是使用这种方案,我们还是需要一个代理层的角色,来规定数据到底会流向哪个服务器
所以我们出现了一种新的方案,可以避免使用代理层:
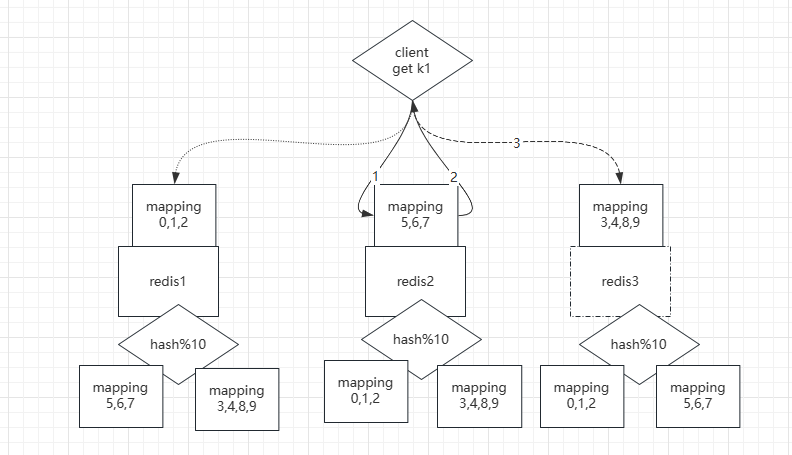
我们完全可以将代理层的角色放到每个Redis实例中,从实例内部告诉我们,数据是否存在于该实例,如上述截图中的1, 2, 3步
- 此时有一个key
k1被推入到Redis实例2中, 由Redis内部来判断该key 是否属于该实例 - 如果不属于该实例的话,会重定向到另一个实例中(
实例3). 此时步骤其实就是上述第二步 - 重定向到
实例3后,再对k1的数据进行操作。
其实上述就是数据分治的过程。但是存在一个问题:聚合操作难以实现。例如:事务。因为每次在编辑key的时候,不一定会修改哪个实例的数据。
但是我们可以手动人为的控制,例如下图:我们可以通过给key添加共同的前缀,能让不同的key落到同一个实例上,而从实现事务等 聚合操作。

上述的方式是Hash槽位的一种实现,虽然此时我们的Redis实例是3天,但是将来最大是10台,那么我们就可以按照10台实例进行预分区。
其实Redis cluster集群的数据分片也是相同的原理。只不过是槽位更多,原文可以参照

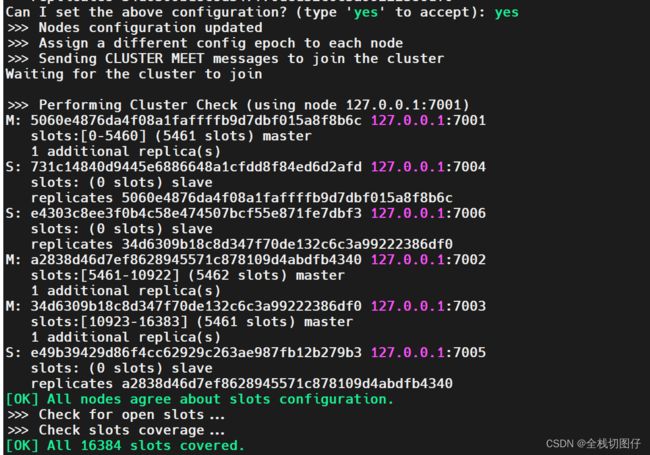
5. 简单配置集群
5.1 创建简单配置文件
为了每个集群节点 创建一个配置文件,配置文件内容如下:
vi redis-7001.conf
port 7001
cluster-enabled yes
cluster-config-file nodes-7001.conf
cluster-node-timeout 15000
daemonize yes
protected-mode no
pidfile /var/run/redis_7001.pid
5.2 修改每个文件端口
需要几个节点,就将上述配置文件赋值几份。修改每个配置文件的端口
使用此命令:%s/7001/7002/g修改
5.3 创建一个shell 快速启动集群
```bash
#!/bin/bash
for i in {1..6}
do
./redis-server "redis-700${i}.conf"
done
## 5.4 关联集群
```shell
./redis-cli --cluster create 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 127.0.0.1:7006 --cluster-replicas 1