MySQL查询排序Order By原理分析
目录
- 一个使用order by 的简单例子
- order by 工作原理
-
- explain 执行计划
- 全字段排序
- 磁盘临时文件辅助排序
- rowid 排序
- 全字段排序与rowid排序对比
- order by的一些优化思路
-
- 联合索引优化
- 调整参数优化
- 使用order by 的一些注意点
-
- 没有where条件,order by字段需要加索引吗
- 分页limit过大时,会导致大量排序怎么办?
- 索引存储顺序与order by不一致,如何优化?
- 使用了in条件多个属性时,SQL执行是否有排序过程
日常开发中,我们经常会使用到order by,但是很多人不清除它的原理以及优化方法。
一个使用order by 的简单例子
假设有一张员工表,表结构如下:
CREATE TABLE `staff` (
`id` bigint(11) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '主键id',
`id_card` varchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '身份证号码',
`name` varchar(64) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '姓名',
`age` int(4) UNSIGNED NOT NULL COMMENT '年龄',
`city` varchar(64) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '城市',
PRIMARY KEY (`id`) USING BTREE,
INDEX `idx_city`(`city`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 1 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci COMMENT = '员工表' ROW_FORMAT = Dynamic;
插入数据如下:
INSERT INTO `staff` VALUES (1, '449006xxxxxxxx2134', '小明', 22, '广州');
INSERT INTO `staff` VALUES (2, '449006xxxxxxxx2135', '小李', 23, '深圳');
INSERT INTO `staff` VALUES (3, '449006xxxxxxxx2136', '小刚', 28, '东莞');
INSERT INTO `staff` VALUES (4, '449006xxxxxxxx2137', '小红', 27, '山海');
INSERT INTO `staff` VALUES (5, '449006xxxxxxxx2138', '小芳', 26, '北京');
INSERT INTO `staff` VALUES (6, '449006xxxxxxxx2139', '小丽', 24, '深圳');
INSERT INTO `staff` VALUES (7, '449006xxxxxxxx2140', '小华', 25, '湛江');
INSERT INTO `staff` VALUES (8, '449006xxxxxxxx2141', '小赵', 29, '武汉');
INSERT INTO `staff` VALUES (9, '449006xxxxxxxx2142', '小胡', 35, '长沙');
INSERT INTO `staff` VALUES (10, '449006xxxxxxxx2143', '小甘', 21, '襄阳');
我们现在有这么一个需求:查询前10个,来自深圳员工的姓名、年龄、城市,并且按照年龄小到大排序。对应的 SQL 语句就可以这么写:
SELECT name,age,city FROM staff WHERE city = '深圳' ORDER BY age LIMIT 10;
这条语句的逻辑很清楚,但是它的底层执行流程是怎样的呢?
order by 工作原理
explain 执行计划
我们先用Explain关键字查看一下执行计划

- 执行计划的key这个字段,表示使用到索引
idx_city - Extra 这个字段的
Using index condition表示索引条件 - Extra 这个字段的
Using filesort表示用到排序
我们可以发现,这条SQL使用到了索引,并且也用到排序。那么它是怎么排序的呢?
全字段排序
MySQL 会给每个查询线程分配一块小内存,用于排序的,称为 sort_buffer。什么时候把字段放进去排序呢,其实是通过idx_city索引找到对应的数据,才把数据放进去啦。
我们回顾下索引是怎么找到匹配的数据的,现在先把索引树画出来吧,idx_city索引树如下:
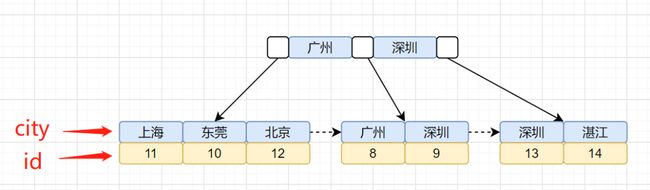
idx_city索引树,叶子节点存储的是主键id。还有一棵id主键聚族索引树,我们再画出聚族索引树图吧:
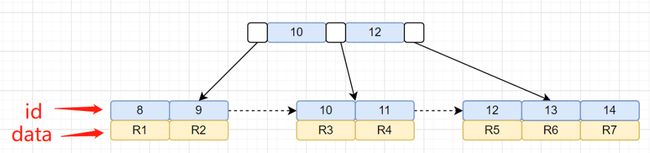
我们的查询语句是怎么找到匹配数据的呢?先通过idx_city索引树,找到对应的主键id,然后再通过拿到的主键id,搜索id主键索引树,找到对应的行数据。
加上order by之后,整体的执行流程就是:
1、MySQL 为对应的线程初始化sort_buffer,放入需要查询的name、age、city字段;
2、从索引树idx_city, 找到第一个满足 city='深圳’条件的主键 id,也就是图中的id=9;
3、到主键 id 索引树拿到id=9的这一行数据, 取name、age、city三个字段的值,存到sort_buffer;
4、从索引树idx_city 拿到下一个记录的主键 id,即图中的id=13;
5、重复步骤 3、4 直到city的值不等于深圳为止;
6、前面5步已经查找到了所有city为深圳的数据,在 sort_buffer中,将所有数据根据age进行排序;
7、按照排序结果取前10行返回给客户端。
执行示意图如下:
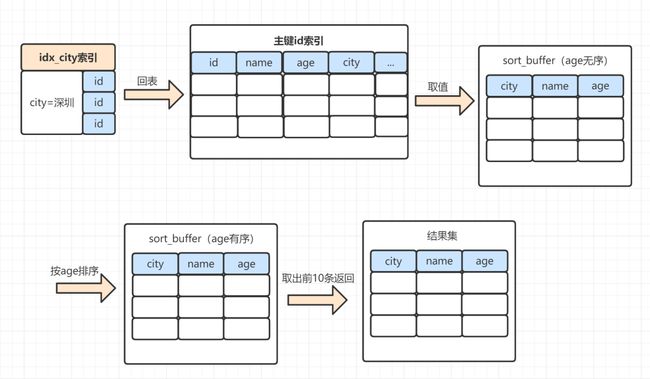
将查询所需的字段全部读取到sort_buffer中,就是全字段排序。这里面,有些小伙伴可能会有个疑问,把查询的所有字段都放到sort_buffer,而sort_buffer是一块内存来的,如果数据量太大,sort_buffer放不下怎么办呢?
磁盘临时文件辅助排序
实际上,sort_buffer的大小是由一个参数控制的:sort_buffer_size。如果要排序的数据小于sort_buffer_size,排序在sort_buffer 内存中完成,如果要排序的数据大于sort_buffer_size,则借助磁盘文件来进行排序
如何确定是否使用了磁盘文件来进行排序呢?可以使用以下这几个命令
## 打开optimizer_trace,开启统计
set optimizer_trace = "enabled=on";
## 执行SQL语句
select name,age,city from staff where city = '深圳' order by age limit 10;
## 查询输出的统计信息
select * from information_schema.optimizer_trace
可以从 number_of_tmp_files 中看出,是否使用了临时文件。
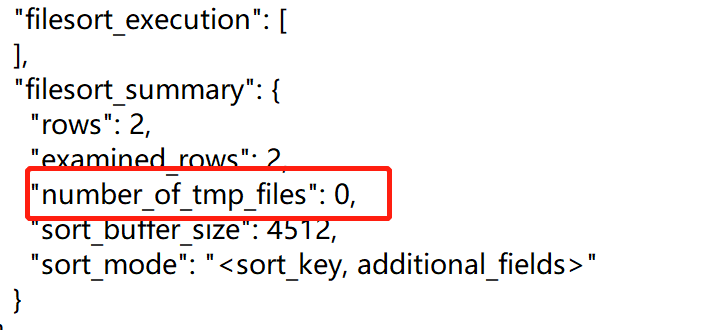
number_of_tmp_files 表示使用来排序的磁盘临时文件数。如果number_of_tmp_files>0,则表示使用了磁盘文件来进行排序。
使用了磁盘临时文件,整个排序过程又是怎样的呢?
1、从主键Id索引树,拿到需要的数据,并放到sort_buffer内存块中。当sort_buffer快要满时,就对sort_buffer中的数据排序,排完后,把数据临时放到磁盘一个小文件中。
2、继续回到主键 id 索引树取数据,继续放到sort_buffer内存中,排序后,也把这些数据写入到磁盘临时小文件中。
3、继续循环,直到取出所有满足条件的数据。最后把磁盘的临时排好序的小文件,合并成一个有序的大文件。
借助磁盘临时小文件排序,实际上使用的是
归并排序算法。
小伙伴们可能会有个疑问,既然sort_buffer放不下,就需要用到临时磁盘文件,这会影响排序效率。那为什么还要把排序不相关的字段(name,city)放到sort_buffer中呢?只放排序相关的age字段,它不香吗?可以了解下rowid 排序。
rowid 排序
rowid 排序就是,只把查询SQL需要用于排序的字段和主键id,放到sort_buffer中。那怎么确定走的是全字段排序还是rowid 排序排序呢?
实际上有个参数控制的。这个参数就是max_length_for_sort_data,它表示MySQL用于排序行数据的长度的一个参数,如果单行的长度超过这个值,MySQL 就认为单行太大,就换rowid 排序。我们可以通过命令看下这个参数取值。
show variables like 'max_length_for_sort_data';
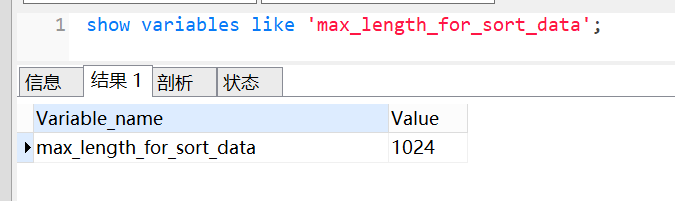
max_length_for_sort_data 默认值是1024。因为本文示例中name,age,city长度=64+4+64 =132 < 1024, 所以走的是全字段排序。我们来改下这个参数,改小一点,
## 修改排序数据最大单行长度为32
set max_length_for_sort_data = 32;
## 执行查询SQL
select name,age,city from staff where city = '深圳' order by age limit 10;
使用rowid 排序的话,整个SQL执行流程又是怎样的呢?
1、MySQL 为对应的线程初始化sort_buffer,放入需要排序的age字段,以及主键id;
2、从索引树idx_city, 找到第一个满足 city='深圳’条件的主键 id,也就是图中的id=9;
3、到主键 id 索引树拿到id=9的这一行数据, 取age和主键id的值,存到sort_buffer;
4、从索引树idx_city 拿到下一个记录的主键 id,即图中的id=13;
5、重复步骤 3、4 直到city的值不等于深圳为止;
5、前面5步已经查找到了所有city为深圳的数据,在 sort_buffer中,将所有数据根据age进行排序;
6、遍历排序结果,取前10行,并按照 id 的值回到原表中,取出city、name 和 age 三个字段返回给客户端。
执行示意图如下:
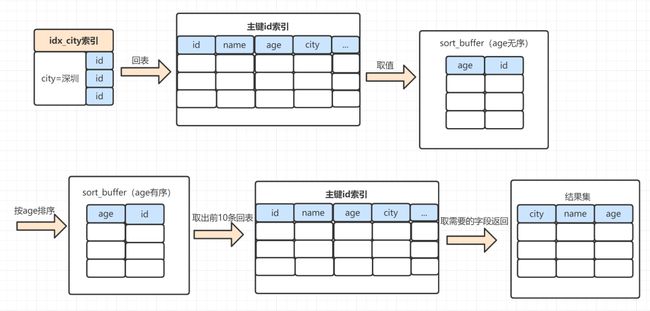
对比一下全字段排序的流程,rowid 排序多了一次回表。
什么是回表?拿到主键再回到主键索引查询的过程,就叫做回表
我们通过optimizer_trace,可以看到是否使用了rowid排序的:
## 打开optimizer_trace,开启统计
set optimizer_trace = "enabled=on";
## 执行SQL语句
select name,age,city from staff where city = '深圳' order by age limit 10;
## 查询输出的统计信息
select * from information_schema.optimizer_trace

全字段排序与rowid排序对比
- 全字段排序:sort_buffer内存不够的话,就需要用到磁盘临时文件,造成
磁盘访问。 - rowid排序:sort_buffer可以放更多数据,但是需要再回到原表去取数据,比全字段排序多一次
回表。
一般情况下,对于InnoDB存储引擎,会优先使用全字段排序。可以发现 max_length_for_sort_data 参数设置为1024,这个数比较大的。一般情况下,排序字段不会超过这个值,也就是都会走全字段排序。
order by的一些优化思路
我们如何优化order by语句呢?
- 因为数据是无序的,所以就需要排序。如果数据本身是有序的,那就不用排了。而索引数据本身是有序的,我们通过建立
联合索引,优化order by 语句。 - 我们还可以通过调整
max_length_for_sort_data等参数优化;
联合索引优化
再回顾下示例SQL的查询计划
explain select name,age,city from staff where city = '深圳' order by age limit 10;

我们给查询条件city和排序字段age,加个联合索引idx_city_age。再去查看执行计划
alter table staff add index idx_city_age(city,age);
explain select name,age,city from staff where city = '深圳' order by age limit 10;

可以发现,加上idx_city_age联合索引,就不需要Using filesort排序了。为什么呢?因为索引本身是有序的,我们可以看下idx_city_age联合索引示意图,如下:
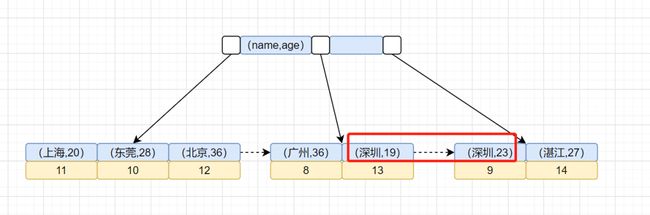
整个SQL执行流程变成酱紫:
1、从索引idx_city_age找到满足city='深圳’ 的主键 id
2、到主键 id索引取出整行,拿到 name、city、age 三个字段的值,作为结果集的一部分直接返回
3、从索引idx_city_age取下一个记录主键id
4、重复步骤 2、3,直到查到第10条记录,或者是不满足city='深圳’ 条件时循环结束。
流程示意图如下:
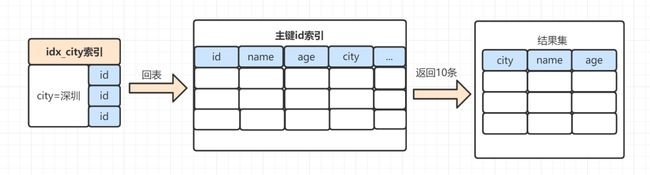
从示意图看来,还是有一次回表操作。针对本次示例,有没有更高效的方案呢?有的,可以使用覆盖索引:
覆盖索引:在查询的数据列里面,不需要回表去查,直接从索引列就能取到想要的结果。换句话说,你SQL用到的索引列数据,覆盖了查询结果的列,就算上覆盖索引了。
我们给city,name,age 组成一个联合索引,即可用到了覆盖索引,这时候SQL执行时,连回表操作都可以省去啦。
调整参数优化
我们还可以通过调整参数,去优化order by的执行。比如可以调整sort_buffer_size的值。因为sort_buffer值太小,数据量大的话,会借助磁盘临时文件排序。如果MySQL服务器配置高的话,可以使用稍微调整大点。
我们还可以调整max_length_for_sort_data的值,这个值太小的话,order by会走rowid排序,会回表,降低查询性能。所以max_length_for_sort_data可以适当大一点。
当然,很多时候,这些MySQL参数值,我们直接采用默认值就可以了。
使用order by 的一些注意点
没有where条件,order by字段需要加索引吗
日常开发过程中,我们可能会遇到没有where条件的order by,那么,这时候order by后面的字段是否需要加索引呢。如有这么一个SQL,create_time是否需要加索引:
select * from A order by create_time;
无条件查询的话,即使create_time上有索引,也不会使用到。因为MySQL优化器认为走普通二级索引,再去回表成本比全表扫描排序更高。所以选择走全表扫描,然后根据全字段排序或者rowid排序来进行。
如果查询SQL修改一下:
select * from A order by create_time limit m;
- 无条件查询,如果m值较小,是可以走索引的.因为MySQL优化器认为,根据索引有序性去回表查数据,然后得到m条数据,就可以终止循环,那么成本比全表扫描小,则选择走二级索引。
分页limit过大时,会导致大量排序怎么办?
假设SQL如下:
select * from A order by a limit 100000,10
- 可以记录上一页最后的id,下一页查询时,查询条件带上id,如:where id > 上一页最后id limit 10。
- 也可以在业务允许的情况下,限制页数。
索引存储顺序与order by不一致,如何优化?
假设有联合索引 idx_age_name, 我们需求修改为这样:查询前10个员工的姓名、年龄,并且按照年龄小到大排序,如果年龄相同,则按姓名降序排。对应的 SQL 语句就可以这么写:
select name,age from staff order by age ,name desc limit 10;
我们看下执行计划,发现使用到Using filesort。

这是因为,idx_age_name索引树中,age从小到大排序,如果age相同,再按name从小到大排序。而order by 中,是按age从小到大排序,如果age相同,再按name从大到小排序。也就是说,索引存储顺序与order by不一致。
我们怎么优化呢?如果MySQL是8.0版本,支持Descending Indexes,可以这样修改索引:
CREATE TABLE `staff` (
`id` bigint(11) NOT NULL AUTO_INCREMENT COMMENT '主键id',
`id_card` varchar(20) NOT NULL COMMENT '身份证号码',
`name` varchar(64) NOT NULL COMMENT '姓名',
`age` int(4) NOT NULL COMMENT '年龄',
`city` varchar(64) NOT NULL COMMENT '城市',
PRIMARY KEY (`id`),
KEY `idx_age_name` (`age`,`name` desc) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=15 DEFAULT CHARSET=utf8 COMMENT='员工表';
使用了in条件多个属性时,SQL执行是否有排序过程
如果我们有联合索引idx_city_name,执行这个SQL的话,是不会走排序过程的,如下:
select * from staff where city in ('深圳') order by age limit 10;

但是,如果使用in条件,并且有多个条件时,就会有排序过程。
explain select * from staff where city in ('深圳','上海') order by age limit 10;

这是因为:in有两个条件,在满足深圳时,age是排好序的,但是把满足上海的age也加进来,就不能保证满足所有的age都是排好序的。因此需要Using filesort。
原文地址