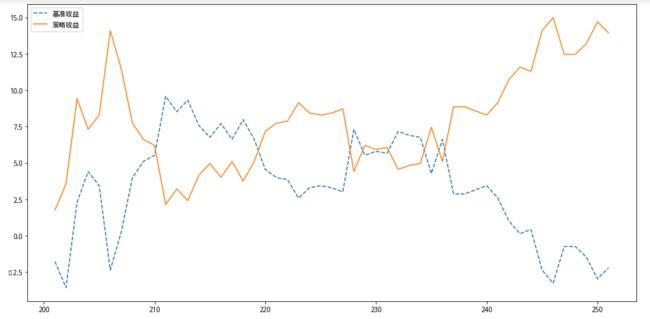
通过KNN分类模型预测股票涨跌,然后与基准收益画图对比
目录
1 获取数据
2 特征工程:定义一个用于分类的函数
3 特征工程:生成训练数据
4 根据训练数据对分类模型进行拟合,并给出得分
5 使用训练完成的分类模型进行数据预测
6 定义几个有用的函数
7 生成基准收益和策略收益对比结果
记录一下学习过程,是对学习思路的一个梳理和总结,有利于加深理解。
机器学习和人工智能风起云涌,能否利用这种工具找出海量股票数据中的财富密码,相信是很多朋友非常感兴趣的话题。本文记录了通过KNN分类模型预测股票涨跌,并根据生成的信号进行买卖(称之为策略交易),最后通过画图对比策略收益与基准收益,是非常有意思的一个学习过程。
本文数据来自于聚宽,学习内容来自于《深入浅出python量化交易实战》。
1 获取数据
import pandas as pd
import numpy as np
from jqdata import *
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
# start_date = '2022-01-01'
end_date = '2022-12-31'
# columns=['open','close','high','low']
df = get_price('000012.XSHE', count=252, end_date=end_date, skip_paused=True)
# type(arr_data)
# df = pd.DataFrame(arr_data, columns=columns)
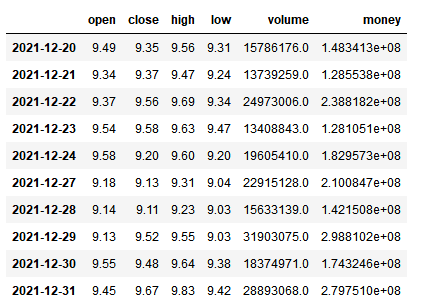
df.head(10)返回结果:
2 特征工程:定义一个用于分类的函数
生成用于后面进行训练的特征数据。
# 定义一个用于分类的函数,给数据表增加3个字段
def classification_tc(df):
df['open-close'] = df['open'] - df['close']
df['high-low'] = df['high'] - df['low']
# 添加一个target字段,如果次日收盘价高于当日收盘价,标记为1,反之为-1
df['target'] = np.where(df['close'].shift(-1)>df['close'], 1, -1)
# 去掉有空值的行
df = df.dropna()
# 将open-close和high-low作为数据集的特征
X = df[['open-close', 'high-low']]
# X = df[['open-close']]
# 将target赋值给y
y = df['target']
return X,y
3 特征工程:生成训练数据
生成训练数据后,人工验证一下 target 是否正确。这个target是上面函数计算出来的,不是分类模型生成的,因为到现在还没开始训练。
#使用classification_tc函数生成数据集的特征与目标
X,y = classification_tc(df)
# 这里设定一个确定的 random_state 值,这样后面的准确率就不会每次都改变
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.8, random_state=5)
print('X长度:', len(X))
print('y长度:', len(y))
df.head(10)
需要注意非常重要的一点,这里要设定一个确定的 random_state 值,这样后面的准确率就不会每次都改变。
4 根据训练数据对分类模型进行拟合,并给出得分
# 创建一个KNN实例,
knn_clf = KNeighborsClassifier(n_neighbors=95)
# 使用KNN拟合训练集
knn_clf.fit(X_train, y_train)
#查看模型在训练集和验证集中的准确率
print('训练集准确率 %.2f'%knn_clf.score(X_train, y_train))
print('验证集准确率 %.2f'%knn_clf.score(X_test, y_test))训练集准确率 0.58 验证集准确率 0.55
看上去准确率不高。
现在完成分类模型拟合(训练)。
5 使用训练完成的分类模型进行数据预测
预测结果保存在'predict_signal'字段。
# 使用KNN模型预测每日股票的涨跌,保存为Predict_Signal
df['predict_signal'] = knn_clf.predict(X)
# 增加一个收益字段 return 对数收益
df['return'] = np.log(df['close']/df['close'].shift(1))
# df[df['predict_signal']==1]
df.head(10)
这是预测出来的结果,不明白为什么绝大部分预测结果都是-1。
6 定义几个有用的函数
# 定义一个累计基准收益的函数
def cum_return(df, split_value):
cum_return = df[split_value:]['return'].cumsum()*100
return cum_return
# 定义一个使用策略收益的函数
def strategy_return(df, split_value):
df['strategy_return'] = df['return']*df['predict_signal'].shift(1)
cum_strategy_return = df[split_value:]['strategy_return'].cumsum()*100
return cum_strategy_return
# 定义一个绘图函数,对比2种收益
def plot_chart(cum_return, cum_strategy_return, symbol1, symbol2):
plt.figure(figsize=(16, 8))
plt.plot(cum_return, '--', label=symbol1)
plt.plot(cum_strategy_return, label=symbol2)
plt.legend()
plt.show()7 生成基准收益和策略收益对比结果
# !!! 上面运行后,这里接着运行才行,否则这里连续运行2次就出错。不知道哪里的问题
# 首先计算基准收益
cum_return = cum_return(df, split_value=len(X_train))
# 然后计算使用算法交易带来的收益(同样只计算预测集)
cum_strategy_return = strategy_return(df, split_value=len(X_train))
# 利用图像对比
plot_chart(cum_return, cum_strategy_return, '基准收益', '策略收益')