Python-DQN代码阅读(12)
目录
1.代码
1.1代码解读
1.2 代码分解
1.2.1 latest_checkpoint = tf.train.latest_checkpoint(checkpoint_dir)
1.2.2 saver.restore(sess, latest_checkpoint)
1.2.3 sess.run(tf.global_variables_initializer())
1.2.4 deep_q_learning()
1.3 输出结果
1.4 问题
1.4.1 程序终止的条件
1.4.2 打印输出的time steps含义
1.4.3 为何一个episode打印出来的time steps不一致?
1.4.4 打印输出的episode_rewards含义?为何数值不一样,有大有小,还有零?
1.4.5 total_t是怎么个变化情况和趋势?
1.4.6 epsilon是怎么个变化趋势?
1.4.7 len(replay_memory是怎么个变化趋势?
1.代码
1.1代码解读
with tf.Session() as sess:
# 加载模型/初始化模型
if ((train_or_test == 'train' and train_from_scratch == False) or train_or_test == 'test'):
latest_checkpoint = tf.train.latest_checkpoint(checkpoint_dir)
print("加载模型 ckpt {}...\n".format(latest_checkpoint))
saver.restore(sess, latest_checkpoint)
elif (train_or_test == 'train' and train_from_scratch == True):
sess.run(tf.global_variables_initializer())
# 运行深度 Q 学习算法
deep_q_learning(sess, env, q_net=q_net, target_net=target_net, state_processor=state_processor, num_episodes=25000,
train_or_test=train_or_test, train_from_scratch=train_from_scratch, start_iter=start_iter,
start_episode=start_episode,
replay_memory_size=300000, replay_memory_init_size=5000, update_target_net_every=10000,
gamma=0.99, epsilon_start=epsilon_start, epsilon_end=[0.1, 0.01], epsilon_decay_steps=[1e6, 1e6],
batch_size=32)
这段代码使用 TensorFlow 的 Session 上下文管理器创建了一个会话(session),并在其中加载或初始化了模型参数。根据 train_or_test 和 train_from_scratch 参数的不同,可以选择加载已有的模型或从头开始初始化模型参数。
接着,通过调用 deep_q_learning() 函数来运行深度 Q 学习算法。这个函数接受多个参数,包括 TensorFlow 会话对象 sess、环境对象 env、Q 网络 q_net、目标网络 target_net、状态处理器对象 state_processor,以及其他一些超参数。在函数内部,将根据指定的参数进行深度 Q 学习算法的训练或测试过程。
1.2 代码分解
1.2.1 latest_checkpoint = tf.train.latest_checkpoint(checkpoint_dir)
latest_checkpoint = tf.train.latest_checkpoint(checkpoint_dir)tf.train.latest_checkpoint(checkpoint_dir) 是 TensorFlow 提供的一个函数,用于获取指定目录下最新的模型检查点文件的路径。
在代码中,checkpoint_dir 是用于保存模型检查点文件的目录路径。latest_checkpoint 变量会被赋值为 checkpoint_dir 目录下最新的模型检查点文件的路径,用于后续的模型加载操作。
这个函数在训练过程中可以用来自动获取最新的模型检查点文件,从而实现断点续训的功能。通过加载最新的模型检查点文件,可以从上一次训练的状态继续训练,而不是从头开始训练。这在长时间运行的训练过程中非常有用,例如在训练复杂的深度神经网络时。
1.2.2 saver.restore(sess, latest_checkpoint)
saver.restore(sess, latest_checkpoint)saver.restore(sess, latest_checkpoint) 是 TensorFlow 提供的一个函数,用于从模型检查点文件中恢复模型的参数。
在代码中,saver 是通过 tf.train.Saver() 函数创建的一个模型参数保存和恢复的对象,用于保存和加载模型的权重和偏置等参数。
latest_checkpoint 是通过 tf.train.latest_checkpoint(checkpoint_dir) 函数获取的最新的模型检查点文件的路径,用于从该文件中恢复模型的参数。
通过调用 saver.restore(sess, latest_checkpoint),可以将之前训练过的模型参数加载到当前的 TensorFlow 会话 (sess) 中,从而恢复之前训练的模型状态,继续训练或进行模型推断等操作。这在断点续训或模型部署时非常有用,可以避免从头开始训练或重新训练模型的时间和资源消耗。
1.2.3 sess.run(tf.global_variables_initializer())
sess.run(tf.global_variables_initializer())sess.run(tf.global_variables_initializer()) 是 TensorFlow 提供的一个函数,用于初始化全局变量。
在 TensorFlow 中,变量的值需要在会话 (sess) 中进行初始化,包括模型的权重、偏置等参数。tf.global_variables_initializer() 是一个初始化操作,用于将所有全局变量初始化为默认的初始值。
在代码中,通过调用 sess.run(tf.global_variables_initializer()) 可以在 TensorFlow 会话 (sess) 中初始化所有的全局变量,为模型的训练或推断做好准备。这通常在训练开始前调用一次,以确保模型的参数都被正确初始化,从而避免在训练过程中出现未定义的参数值。
1.2.4 deep_q_learning()
deep_q_learning(sess, env, q_net=q_net, target_net=target_net, state_processor=state_processor, num_episodes=25000,
train_or_test=train_or_test, train_from_scratch=train_from_scratch, start_iter=start_iter,
start_episode=start_episode,
replay_memory_size=300000, replay_memory_init_size=5000, update_target_net_every=10000,
gamma=0.99, epsilon_start=epsilon_start, epsilon_end=[0.1, 0.01], epsilon_decay_steps=[1e6, 1e6],
batch_size=32)deep_q_learning() 函数的调用中的参数值如下:
sess: TensorFlow会话对象env: 环境对象,用于与环境交互q_net: Q网络对象,用于进行Q值的估计和更新target_net: 目标Q网络对象,用于生成目标Q值state_processor: 状态处理器对象,用于对环境状态进行预处理num_episodes: 训练或测试的总回合数train_or_test: 指示是进行训练还是测试的标志train_from_scratch: 指示是否从头开始训练的标志start_iter: 训练开始的迭代次数start_episode: 训练开始的回合数replay_memory_size: 经验回放缓冲区的大小replay_memory_init_size: 经验回放缓冲区的初始大小update_target_net_every: 更新目标Q网络的频率gamma: 折扣因子epsilon_start: 初始探索率epsilon_end: 探索率的最终值epsilon_decay_steps: 探索率衰减的步数batch_size: 每次训练的样本批量大小
这些参数值可能是根据具体的实验需求和问题设置的,可能与 deep_q_learning() 函数定义中的默认参数值不一致。在实际应用中,根据具体问题和环境的特点,可以通过调整这些参数值来优化模型的训练效果。需要注意的是,最佳的参数值可能因问题和环境的不同而有所变化,通常需要通过实验和调优来找到最佳的超参数组合。
1.3 输出结果
print('\n Eisode: ', ep, '| time steps: ', time_steps, '| total episode reward: ', episode_rewards,'| total_t: ', total_t, '| epsilon: ', epsilon, '| replay mem size: ', len(replay_memory))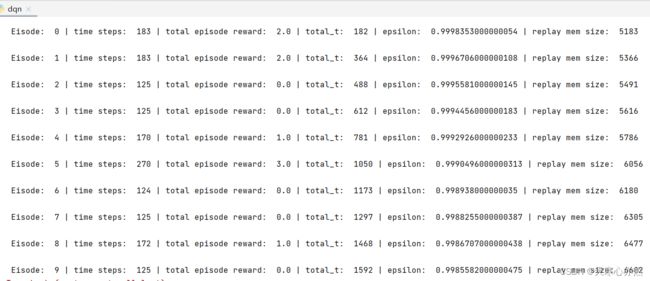
1.4 问题
1.4.1 程序终止的条件
在 deep_q_learning() 函数中,for 循环的迭代次数由 num_episodes 指定,但并没有在循环内部对 ep(episode) 进行累加操作。
因此,实际上是通过循环的次数来控制执行的 Episode 数量的,当循环完成 num_episodes 次后,循环就会停止。程序停止的条件是通过 num_episodes 参数控制的,即当训练的总Episode数达到了 num_episodes 的设定值时,程序会停止执行。在代码中调用 deep_q_learning() 函数时,传入了 num_episodes=25000,因此程序会在训练完成 25000 个Episode 后停止执行。
1.4.2 打印输出的time steps含义
在强化学习中,"time step" 通常指的是在一个 Episode 中的单个步骤或单个动作。在深度 Q 网络(Deep Q-Network, DQN)算法中,一个 Episode 包含多个 time step,每个 time step 包括以下几个步骤:
- 环境接收当前状态(state)作为输入。
- 根据当前策略选择一个动作(action)。
- 执行选定的动作,并观察环境的反馈,包括下一个状态(next state)、即时奖励(reward)和是否终止(done)的标志。
- 根据观察到的反馈更新网络的权重,以优化 Q 值的估计。
- 进入下一个 time step,重复上述步骤。
打印输出的 time steps 意味着每个 Episode 中已经执行的步骤数。这可以作为评估算法性能的一种指标,通常情况下,随着训练的进行,time steps 的数量应该逐渐增加,表示算法在与环境交互中进行了更多的决策和动作选择。在训练过程中,可以观察 time steps 的变化,以了解算法的训练进度和效果。
1.4.3 为何一个episode打印出来的time steps不一致?
在强化学习中,任务(task)通常指的是智能体需要完成的具体目标,而环境(environment)则是智能体与之交互的外部环境。在某些情况下,任务和环境可能是一样的,即智能体需要在一个特定的环境中完成一个特定的任务。然而,在其他情况下,任务和环境可能是不同的,智能体可能需要在不同的环境中完成不同的任务。
在强化学习中,每个 episode 的时间步数(time steps)是指智能体与环境进行一次动作和观察的过程,从智能体选择动作开始,到环境返回新的状态、奖励等信息,再到智能体选择下一步动作,这个过程称为一个时间步。因此,在不同的环境和任务中,智能体与环境交互的时间步数可能会不同,因此每个 episode 的时间步数也会不同。
在本例中,每个 episode 的时间步数可能会因为不同的环境和任务而有所不同,因此在打印输出的时候,你可能会看到每个 episode 的时间步数不一样。这是正常的现象,因为不同的环境和任务可能需要不同的时间步数来完成。
1.4.4 打印输出的episode_rewards含义?为何数值不一样,有大有小,还有零?
episode_rewards 是每个 episode 完成后,智能体在该 episode 中获得的总奖励(或回报)的累积值。
在强化学习中,智能体的行为策略可能会随着训练的进行而不断改变。在训练初期,智能体可能会随机探索环境,导致 episode_rewards 的值较为不稳定,有时甚至可能为零。随着训练的进行,智能体应该逐渐学习到更好的策略,从而导致 episode_rewards 的值逐渐增加。因此 episode_rewards 的数值会因 episode 中智能体与环境的交互而有所不同。
此外,episode_rewards 的值还可能受到环境的随机性和任务的复杂性的影响。在某些环境中,奖励可能会因环境的状态、目标的位置、障碍物的分布等而有所变化,从而导致 episode_rewards 的波动性较大。这种情况下,episode_rewards 的值可能会在不同的 episode 之间有较大的差异。
根据深度 Q 网络 (DQN) 算法的训练过程,智能体的性能在训练开始时可能较差,但随着训练的进行,智能体应该逐渐优化其行为策略和价值估计,从而在任务中表现出更好的性能。
在训练初期,由于智能体的行为策略和价值估计不断调整和优化,episode_rewards 可能会出现较大的波动,甚至可能为零或负值。随着训练的继续,episode_rewards 应该呈现逐渐增加的趋势,反映了智能体在任务中取得了更好的性能。在训练接近完成时,episode_rewards 应该趋于稳定,波动较小,并保持在较高的水平。
需要注意的是,训练过程中的具体趋势和性能表现会受到许多因素的影响,包括任务的难度、智能体的网络结构和超参数设置等。因此,无法准确预测训练过程的最终趋势,需要根据具体的任务和设置进行实际训练和观察。
1.4.5 total_t是怎么个变化情况和趋势?
在 DQN 算法中,total_t 是用来统计所有时间步的计数器,用于记录智能体在整个训练过程中的步数。在每一步中,智能体与环境进行交互,并更新其行为策略和价值估计。
total_t 的变化情况和趋势会随着训练的进行而不断增加。在训练初期,total_t 会从零开始逐步增加,因为智能体会不断与环境交互,并执行动作。随着训练的进行,total_t 会持续累加,直到达到预定的训练步数或 episode 数量。
total_t 的具体趋势取决于任务的难度、智能体的网络结构和超参数设置等。通常情况下,total_t 会随着训练的进行而逐步增加,直到达到训练停止的条件(如达到预定的训练步数或 episode 数量)。如果智能体在训练过程中能够学到较好的行为策略和价值估计,total_t 可能会呈现较快的增长趋势。如果智能体在训练过程中遇到困难,total_t 的增长速度可能较慢或波动较大。
需要注意的是,total_t 的具体变化情况和趋势可能因不同的任务和设置而异,需要根据实际情况进行观察和分析。
1.4.6 epsilon是怎么个变化趋势?
在深度 Q 网络的训练中,epsilon 是用来控制探索和利用之间的平衡的参数,它决定了智能体在选择动作时是按照当前最优动作(利用)还是随机选择动作(探索)。
在程序中,epsilon 的初始值为 epsilon_start,每个 episode 结束后,epsilon 会按照线性衰减的方式减小。具体而言,epsilon 在 epsilon_start 和 epsilon_end 之间进行线性插值,衰减步数为 epsilon_decay_steps。衰减率为 (epsilon_start - epsilon_end) / epsilon_decay_steps,即每个 episode 结束后 epsilon 会减小一个固定的步长,直到 epsilon 达到 epsilon_end,即 [0.1, 0.01] 中的一个较小值。
由于 epsilon_start 的初始值较高(为1),而 epsilon_end 的最终值较低([0.1, 0.01] 中的一个较小值),所以在开始阶段 epsilon 会较大,接近 1,随着训练进行,epsilon 会逐渐衰减到较小的值,趋近于 epsilon_end。这样设计的目的是在训练初期加强探索,帮助智能体更好地探索环境,而在训练后期逐渐减少探索,提高利用当前最优动作的机会。
1.4.7 len(replay_memory是怎么个变化趋势?
replay_memory 是用于存储经验回放的缓冲区,其长度可以随着训练的进行而变化。
在程序中,replay_memory 的初始长度为 replay_memory_init_size,即在开始训练时先向 replay_memory 中添加一定数量的初始经验样本,用于初始化缓冲区。之后,每当智能体与环境交互并生成新的经验样本时,会将其添加到 replay_memory 中。
随着训练的进行,replay_memory 的长度会逐渐增加,直到达到设定的 replay_memory_size。当 replay_memory 的长度达到最大值后,新的经验样本会替换掉最早的经验样本,从而保持 replay_memory 的固定长度。
因此,replay_memory 的变化趋势是逐渐增加,直到达到最大长度后保持不变。当训练进行较长时间后,replay_memory 中会保存较多的经验样本,用于智能体进行经验回放和学习。