springboot使用JPA,JPA常用注解
准备:环境:mysql8(mysql5在使用注解@Temporal(TemporalType.TIMESTAMP)的时候报错,不通过),IDEA。
简单的入门案例:
第一步,pom中引入依赖。
org.springframework.boot
spring-boot-starter-data-jpa
mysql
mysql-connector-java
org.projectlombok
lombok
true
第二步:配置文件的编写
spring:
datasource:
driver-class-nam: com.mysql.cj.jdbc.Driver
#?serverTimezone=UTC&useUnicode=true&characterEncoding=utf8时区的设置
url: jdbc:mysql://127.0.0.1:3306/test?serverTimezone=UTC&useUnicode=true&characterEncoding=utf-8&useSSL=true
username: root
password: root
#jpa的一些配置
jpa:
hibernate:
#update:代表更新或者创建数据表,ddl代表数据表的生成策略。当 没有的时候就会创建
ddl-auto: update
#控制台 显示sql
show-sql: true
#开发阶段设置为true,表示开启逆向工程(由表生成实体类)。如果设置为false,表示不开启逆向,即正向工程,由实体生成数据库表
generate-ddl: true
#制定了数据库的类型
database: mysql
#slf4j日志配置
logging:
level:
root: info
#分包配置级别,即不同的目录下可以使用不同的级别
com.fan: debug
#file.name生效了,用于指定日志的位置和名称
file:
#这样直接写,是在当前目录下生成这个文件名,也可以前面具体加文件路径d:/springboot.log
name: springboot.log
第三步:创建实体类,操作数据库的。数据库不需要创建任何表,只需要指定数据库即可(url: jdbc:mysql://127.0.0.1:3306/test)
package com.fan.domain;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import javax.persistence.*;
import java.util.Date;
//前三个注解用于生成set,get,toString方法的
@Data
@AllArgsConstructor
@NoArgsConstructor
@Entity//用于声明这是一个持久化类(与数据库进行关联)
@Table(name = "t_user")//声明这是一个数据库的表,name来指定生成的表名。当类名与表名一致时,可省略不写
public class User {
@Id//指定此属性作为数据库的主键
@GeneratedValue(strategy = GenerationType.IDENTITY)//主键生成策略,默认自增长
private Long id;
//当省略@Column(),默认数据库的字段名字和实体类属性名一致。
//当属姓名使用驼峰命名的话会,数据库的字段生成下划线的字段,userName(类属性名)变成user_name(数据库字段名)
@Column(name = "username")//这一行时配置数据库的信息。指定数据库的字段名,如果一致,则可以省略
private String userName;
private String addr;
private Integer age;
@Temporal(TemporalType.TIMESTAMP)//和数据库生成一致,TIMESTAMP :等于java.sql.Timestam
private Date birthday;
@Transient//表明该属性不会自动匹配到数据库表中
private String sex;
}
第四步:然后启动工程,就会发现数据库中,自动创建了数据表。
然后可以进行数据库的增删改查。
需要实现相应的接口,接口推荐命名方式:实体类名称+Repository,接口需要继承SpringData JPA提供的接口。
自己写一个dao包,然后写一个接口UserRepository去继承JpaRepository接口。
package com.fan.dao;
import com.fan.domain.User;
import org.springframework.data.jpa.repository.JpaRepository;
public interface UserRepository extends JpaRepository{
}

其他增删改查的方法都是用UserRepository去调用,类似。
JPA方法命名查询
注意:方法的名称必须要遵循驼峰命名规则,xxxBy+属性名称(首字母大写)+查询条件(首字母大写)
顾名思义,方法命名规则查询就是根据方法的名字,就能创建查询。只需要按照Spring Data JPA提供的方法命名规则定义方法的
名称,就可以完成查询工作。Spring Data JPA在程序执行的时候会根据方法名称进行解析,并自动生成查询语句进行查询
按照Spring Data JPA 定义的规则,查询方法以 findBy 开头,涉及条件查询时,条件的属性用条件关键字连接,要注意的是:条件属性首字母需大写。框架在进行方法名解析时,会先把方法名多余的前缀截取掉,然后对剩下部分进行解析。
案例:dao接口中写一个接口:
package com.fan.dao;
import com.fan.domain.User;
import org.springframework.data.jpa.repository.JpaRepository;
import java.util.List;
public interface UserRepository extends JpaRepository{
//自定义的查询方法,按照一定的命名规则书写
//根据用户名模糊查询
List findByUserNameLike(String username);
//根据年龄查询,GreaterThan是大于的意思,Equal是等于的意思,合起来是>=,查>=20岁的user
List findByAgeGreaterThanEqual(Integer age);
//根据用户名,年龄查询(并且的关系)
List findByUserNameLikeAndAgeGreaterThan(String userName,Integer age);
}
测试类测试:
package com.fan;
import com.fan.dao.*;
import com.fan.domain.*;
import com.fan.vo.StuVo;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.PageRequest;
import org.springframework.data.domain.Sort;
import org.springframework.data.jpa.domain.Specification;
import org.springframework.test.annotation.Commit;
import org.springframework.test.annotation.Rollback;
import org.springframework.transaction.annotation.Transactional;
import org.springframework.util.ObjectUtils;
import javax.annotation.Resource;
import javax.persistence.Transient;
import javax.persistence.criteria.CriteriaBuilder;
import javax.persistence.criteria.CriteriaQuery;
import javax.persistence.criteria.Predicate;
import javax.persistence.criteria.Root;
import java.sql.SQLException;
import java.util.*;
@SpringBootTest
class SpringbootjpaApplicationTest2 {
@Resource
private UserRepository userRepository;
//方法命名查询测试
@Test
public void method1() {
List users = userRepository.findByUserNameLike("%张%");
for (User user : users) {
System.out.println(user);
}
}
@Test
public void method2() {
List users = userRepository.findByAgeGreaterThanEqual(28);
for (User user : users) {
System.out.println(user);
}
}
@Test
public void method3() {
List users = userRepository.findByUserNameLikeAndAgeGreaterThan("%张%",22);
for (User user : users) {
System.out.println(user);
}
}
}
测试完美通过。
使用jpa进行数据的排序和分页(开发中我们继承JpaRepository就够用了)
排序:
第一步;先在实体类包下创建一个Stu类:
package com.fan.domain;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import javax.persistence.*;
import java.util.Date;
//前三个注解用于生成set,get,toString方法的
@Data
@AllArgsConstructor
@NoArgsConstructor
@Entity//用于声明这是一个持久化类(与数据库进行关联)
@Table(name = "t_stu")//声明这是一个数据库的表,name来指定生成的表名。当类名与表名一致时,可省略不写
public class Stu {
@Id//指定此属性作为数据库的主键
@GeneratedValue(strategy = GenerationType.IDENTITY)//主键生成策略,默认自增长
private Long id;
//当省略@Column(),默认数据库的字段名字和实体类属性名一致。
//当属姓名使用驼峰命名的话会,数据库的字段生成下划线的字段,userName(类属性名)变成user_name(数据库字段名)
@Column()//这一行时配置数据库的信息。指定数据库的字段名,如果一致,则可以省略
private String stuName;
private String addr;
private Integer age;
@Temporal(TemporalType.TIMESTAMP)//和数据库生成一致,TIMESTAMP :等于java.sql.Timestam
private Date birthday;
@Transient//表明该属性不会自动匹配到数据库表中
private String sex;
}
第二步:创建要操作的实体类的接口StuRepository,此接口继承的是PagingAndSortingRepository接口。
package com.fan.dao;
import com.fan.domain.Stu;
import org.springframework.data.repository.PagingAndSortingRepository;
public interface StuRepository extends PagingAndSortingRepository{
}
第三步:测试类测试:
package com.fan;
import com.fan.dao.StuRepository;
import com.fan.dao.UserRepository;
import com.fan.domain.Stu;
import com.fan.domain.User;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.domain.Sort;
import javax.annotation.Resource;
import java.sql.SQLException;
import java.util.Date;
import java.util.Iterator;
import java.util.Random;
@SpringBootTest
class SpringbootjpaApplicationTests {
@Resource
private StuRepository stuRepository;
//测试排序和分页
@Test
void testSort() throws SQLException {
//批量添加数据
for (int i = 0; i < 10; i++) {
Stu stu = new Stu();
stu.setStuName("tom"+i);
stu.setAddr("上海");
stu.setAge(18+ i);
stu.setBirthday(new Date());
stuRepository.save(stu);
}
Sort sort = Sort.by(Sort.Direction.DESC, "id");
//调用排序的方法。
Iterator iterator = stuRepository.findAll(sort).iterator();
//打印结果
while(iterator.hasNext()){
Stu stu = iterator.next();
System.out.println(stu);
}
}
@Test//测试分页
void testPage() throws SQLException {
int pageNo = 1;//当前页码
int pageSize =3;//每一页显示的数量
//设置分页信息
//PageRequest pageRequest = PageRequest.of(pageNo-1, pageSize);//当前页码从0开始
//分页和排序一起的方式,这里根据年龄倒序
PageRequest pageRequest = PageRequest.of(pageNo-1, pageSize, Sort.Direction.DESC,"age");//当前页码从0开始
//调用分页查询方法
Page page = stuRepository.findAll(pageRequest);
System.out.println("当前页码:"+(page.getNumber() + 1));
System.out.println("每页显示的数量:"+page.getSize());
System.out.println("总数量:"+page.getTotalElements());
System.out.println("总页数:"+page.getTotalPages());
//获取数据列表
List list = page.getContent();//获取内容
for (Stu stu : list) {
System.out.println(stu);
}
}
}


注意:开发中我们就继承JpaRepository接口就可以了,JpaRepository接口继承了分页排序的接口。有分页等方法。
JPA动态条件查询
实战应用请参考: http://www.cppcns.com/ruanjian/java/194803.html.
继承接口JpaSpecificationExecutor< Stu >(此接口用于实现动态条件查询),然后多继承接口PagingAndSortingRepository
package com.fan.dao;
import com.fan.domain.Stu;
import org.springframework.data.jpa.repository.JpaSpecificationExecutor;
import org.springframework.data.repository.PagingAndSortingRepository;
public interface StuRepository extends PagingAndSortingRepository,JpaSpecificationExecutor{
}
JpaSpecificationExecutor< T >.,T是泛型。
首先我们做条件查询会做一个类,vo类,我们放在com.fan.vo包下:
package com.fan.vo;
import com.fan.domain.Stu;
import lombok.Data;
//此类只是作为查询用的
@Data
public class StuVo extends Stu{
}
然后再测试类中进行测试:
@Test//测试动态条件查询的
void testFund() throws SQLException {
//创建查询条件对象
StuVo stuVo = new StuVo();
//stuVo.setAge(24);测试年龄的
stuVo.setAddr("上");
//创建分页对象
PageRequest pageRequest = PageRequest.of(0, 3, Sort.Direction.ASC, "id");
/*
//不分页的写法
@Override
public Predicate toPredicate(Root root, CriteriaQuery criteriaQuery, CriteriaBuilder builder) {
//获取条件对象
Predicate predicate = builder.conjunction();
//判断查询条件是否为空
if (stuVo != null) {
//按姓名模糊查询
if (!ObjectUtils.isEmpty(stuVo.getStuName())) {
//先是要查询的字段root.get("stuName"),然后模糊查询前后要加%
predicate.getExpressions().add(builder.like(root.get("stuName"), "%" + stuVo.getStuName() + "%"));
}
//查询大于指定年龄
if (!ObjectUtils.isEmpty(stuVo.getAge())) {//当查询实体属性不为空
//ge为大于的意思
predicate.getExpressions().add(builder.ge(root.get("age"), stuVo.getAge()));
}
if (!ObjectUtils.isEmpty(stuVo.getAddr())) {//判断查询实体是否为空
predicate.getExpressions().add(builder.like(root.get("addr"), "%"+stuVo.getAddr()+"%"));
}
}
return predicate;
}*/
//调用动态查询方法,如果是分页,返回的是Page ,不分页的返回的是List
Page page = stuRepository.findAll(new Specification() {
@Override
public Predicate toPredicate(Root root, CriteriaQuery criteriaQuery, CriteriaBuilder builder) {
//获取条件对象
Predicate predicate = builder.conjunction();
//判断查询条件是否为空
if (stuVo != null) {
//按姓名模糊查询
if (!ObjectUtils.isEmpty(stuVo.getStuName())) {
//先是要查询的字段root.get("stuName"),然后模糊查询前后要加%
predicate.getExpressions().add(builder.like(root.get("stuName"), "%" + stuVo.getStuName() + "%"));
}
//查询大于指定年龄
if (!ObjectUtils.isEmpty(stuVo.getAge())) {//当查询实体属性不为空
//ge为大于的意思
predicate.getExpressions().add(builder.ge(root.get("age"), stuVo.getAge()));
}
if (!ObjectUtils.isEmpty(stuVo.getAddr())) {//判断查询实体是否为空
predicate.getExpressions().add(builder.like(root.get("addr"), "%"+stuVo.getAddr()+"%"));
}
}
return predicate;
}
},pageRequest);//分页的动态条件,这里加一个参数,pageRequest
System.out.println("当前页码:"+(page.getNumber() + 1));
System.out.println("每页显示的数量:"+page.getSize());
System.out.println("总数量:"+page.getTotalElements());
System.out.println("总页数:"+page.getTotalPages());
//获取数据列表
List list = page.getContent();//获取内容
for (Stu stu : list) {
System.out.println(stu);
}
}
完整的测试类代码展示:
package com.fan;
import com.fan.dao.StuRepository;
import com.fan.dao.UserRepository;
import com.fan.domain.Stu;
import com.fan.domain.User;
import com.fan.vo.StuVo;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.PageRequest;
import org.springframework.data.domain.Sort;
import org.springframework.data.jpa.domain.Specification;
import org.springframework.util.ObjectUtils;
import javax.annotation.Resource;
import javax.persistence.criteria.CriteriaBuilder;
import javax.persistence.criteria.CriteriaQuery;
import javax.persistence.criteria.Predicate;
import javax.persistence.criteria.Root;
import java.sql.SQLException;
import java.util.Date;
import java.util.Iterator;
import java.util.List;
@SpringBootTest
class SpringbootjpaApplicationTests {
@Resource//将dao层的接口的注入一个bean
private UserRepository userRepository;
@Resource
private StuRepository stuRepository;
@Test
void contextLoads() {
}
@Test
void contextLoads2() throws SQLException {
User user = new User();
user.setUserName("tom");
user.setAddr("上海");
user.setAge(18);
user.setBirthday(new Date());
userRepository.save(user);
}
//测试排序和分页
@Test
void testSort() throws SQLException {
//批量添加数据
for (int i = 0; i < 10; i++) {
Stu stu = new Stu();
stu.setStuName("tom"+i);
stu.setAddr("上海");
stu.setAge(18+ i);
stu.setBirthday(new Date());
stuRepository.save(stu);
}
Sort sort = Sort.by(Sort.Direction.DESC, "id");
//调用排序的方法。
Iterator iterator = stuRepository.findAll(sort).iterator();
//打印结果
while(iterator.hasNext()){
Stu stu = iterator.next();
System.out.println(stu);
}
}
@Test//测试分页
void testPage() throws SQLException {
int pageNo = 1;//当前页码
int pageSize =3;//每一页显示的数量
//设置分页信息
//PageRequest pageRequest = PageRequest.of(pageNo-1, pageSize);//当前页码从0开始
//分页和排序一起的方式,这里根据年龄倒序
PageRequest pageRequest = PageRequest.of(pageNo-1, pageSize, Sort.Direction.DESC,"age");//当前页码从0开始
//调用分页查询方法
Page page = stuRepository.findAll(pageRequest);
System.out.println("当前页码:"+(page.getNumber() + 1));
System.out.println("每页显示的数量:"+page.getSize());
System.out.println("总数量:"+page.getTotalElements());
System.out.println("总页数:"+page.getTotalPages());
//获取数据列表
List list = page.getContent();//获取内容
for (Stu stu : list) {
System.out.println(stu);
}
}
@Test//测试动态条件查询的
void testFund() throws SQLException {
//创建查询条件对象
StuVo stuVo = new StuVo();
//stuVo.setAge(24);测试年龄的
stuVo.setAddr("上");
//创建分页对象
PageRequest pageRequest = PageRequest.of(0, 3, Sort.Direction.ASC, "id");
/*
//不分页的写法
@Override
public Predicate toPredicate(Root root, CriteriaQuery criteriaQuery, CriteriaBuilder builder) {
//获取条件对象
Predicate predicate = builder.conjunction();
//判断查询条件是否为空
if (stuVo != null) {
//按姓名模糊查询
if (!ObjectUtils.isEmpty(stuVo.getStuName())) {
//先是要查询的字段root.get("stuName"),然后模糊查询前后要加%
predicate.getExpressions().add(builder.like(root.get("stuName"), "%" + stuVo.getStuName() + "%"));
}
//查询大于指定年龄
if (!ObjectUtils.isEmpty(stuVo.getAge())) {//当查询实体属性不为空
//ge为大于的意思
predicate.getExpressions().add(builder.ge(root.get("age"), stuVo.getAge()));
}
if (!ObjectUtils.isEmpty(stuVo.getAddr())) {//判断查询实体是否为空
predicate.getExpressions().add(builder.like(root.get("addr"), "%"+stuVo.getAddr()+"%"));
}
}
return predicate;
}*/
//调用动态查询方法,如果是分页,返回的是Page ,不分页的返回的是List
Page page = stuRepository.findAll(new Specification() {
@Override
public Predicate toPredicate(Root root, CriteriaQuery criteriaQuery, CriteriaBuilder builder) {
//获取条件对象
Predicate predicate = builder.conjunction();
//判断查询条件是否为空
if (stuVo != null) {
//按姓名模糊查询
if (!ObjectUtils.isEmpty(stuVo.getStuName())) {
//先是要查询的字段root.get("stuName"),然后模糊查询前后要加%
predicate.getExpressions().add(builder.like(root.get("stuName"), "%" + stuVo.getStuName() + "%"));
}
//查询大于指定年龄
if (!ObjectUtils.isEmpty(stuVo.getAge())) {//当查询实体属性不为空
//ge为大于的意思
predicate.getExpressions().add(builder.ge(root.get("age"), stuVo.getAge()));
}
if (!ObjectUtils.isEmpty(stuVo.getAddr())) {//判断查询实体是否为空
predicate.getExpressions().add(builder.like(root.get("addr"), "%"+stuVo.getAddr()+"%"));
}
}
return predicate;
}
},pageRequest);//分页的动态条件,这里加一个参数,pageRequest
System.out.println("当前页码:"+(page.getNumber() + 1));
System.out.println("每页显示的数量:"+page.getSize());
System.out.println("总数量:"+page.getTotalElements());
System.out.println("总页数:"+page.getTotalPages());
//获取数据列表
List list = page.getContent();//获取内容
for (Stu stu : list) {
System.out.println(stu);
}
}
}
结果展示:

JPA常用注解:
@Entity
@Table
@Basic:表示简单属性到数据库表字段的映射(几乎不用)
@Column
@GeneratedValue
@Id
@Transient
@Temporal
@Lob
@Enumerated:(很重要)
@OneToMany
@ManyToOne
@ManyToMany
@Query (Spring Data JPA 用法)
@Modifying
1、@Entity:
标记被注解的类是实体类,可被ORM框架用于持续化,常与@Table一起使用,指定关联的数据库表。该注解仅包含name属性,用于指明实体的名字,不指定时默认是实体类的名字,实体名可用于查询语句中,如下代码片段:
@Entity(name=”people_entity”)//查询的实体名字为people_entity
@Table(name=”people”)//数据库中生成的表名是people
public class People implements Serializable {
private static final long serialVersionUID = 1L;
@Id//指明此属性为数据库中的主键
@GeneratedValue(strategy = GenerationType.AUTO)//主键的生成策略
private Integer id;
@Column(name = "name", length = 32)//数据库中的字段要求
private String name;
// ……省略getter和setter方法
}
2、@Table
该属性与@Entity一起使用,用来描述实体对应的数据库表,其name属性指定实体对应的数据库名,name属性用的较多,catalog和schema属性指定数据表所在目录名或数据库名,跟具体使用数据库相关,uniqueConstraints属性用来对数据表列唯一性做限制,index属性用来描述索引字段,实际使用根据具体需求来配置。
3、@Basic(一般很少用)
@Basic 表示一个简单的属性到数据库表的字段的映射,对于没有任何标注的 getXxxx() 方法,默认即为@Basic
@Basic fetch: 表示该属性的读取策略,有 EAGER 和 LAZY 两种,分别表示主支抓取和延迟加载,默认为 EAGER.
optional:表示该属性是否允许为null, 默认为true
4、@Column
Column的主要属性信息:
name 自定义数据库的字段名称
nullable 是否为空
length: 如果是字符型,可以限定长度
unqiue 是否为唯一性
precision/scale 对于小数的精度控制
insertable/updatable 可插入/可更新设置
columnDefinition: 定义建表时创建此列的DDL
.secondaryTable: 从表名。如果此列不建在主表上(默认建在主表),该属性定义该列所在从表的名字。
@Column(name = “user_code”, nullable = false, length=32)//设置属性userCode对应的字段为user_code,长度为32,非空
private String userCode;
@Column(name = “user_wages”, nullable = true, precision=12, scale=2)//设置属性wages对应的字段为user_wages,12位数字可保留两位小数,可以为空
@Column用来建立模型对象与数据库表字段之间的映射关系,可以使用在方法和属性上。
在不做声明的情况下,默认会建立与数据库的映射。
详细的信息可以参阅其源代码的说明:
Example 1:
* @Column(name="DESC", nullable=false, length=512)
* public String getDescription() { return description; }
*
* Example 2:
* @Column(name="DESC",
* columnDefinition="CLOB NOT NULL",
* table="EMP_DETAIL")
* @Lob
* public String getDescription() { return description; }
*
* Example 3:
* @Column(name="ORDER_COST", updatable=false, precision=12, scale=2)
* public BigDecimal getCost() { return cost; }
5、@GeneratedValue
用来描述主键生成策略,包含如下策略:
GenerationType.TABLE:ORM框架通过数据库的一张特定的表格来生成主键,该策略一般与另外一个注解@TableGenerator一起使用,@TableGenerator对这张特定的表进行描述,该策略的好处就是不依赖于外部环境和数据库的具体实现,在不同数据库间可以很容易的进行移植,但由于其不能充分利用数据库的特性,一般不会优先使用;
GenerationType.SEQUENCE:
Oracle不支持主键自增长,其提供了一种叫做"序列(sequence)"的机制生成主键,GenerationType.SEQUENCE就可以作为主键生成策略,不足之处是只能使用于部分支持序列的数据库(Oracle,PostgreSQL,DB2),一般与@SequenceGenerator一起使用,@SequenceGenerator注解指定了生成主键的序列,不指定序列时自动生成一个序列SEQ_GEN_SEQUENCE;
GenerationType.IDENTITY:
该策略类同SEQUENCE策略,主键自增策略,需要具体的数据库支持才能使用,mysql支持该策略;
GenerationType.AUTO
ORM框架依据使用的数据库在以上三种主键生成策略中选择其中一种,该策略是默认的策略,比较常用。
6、@Id
被该属性标注的实体字段被标记为数据表的主键,与@Column, @GeneratedValue一起配合使用用来描述主键字段,如下实例,People类的id被映射成主键,对应数据库字段名为pid,ORM框架依据具体使用的数据库使用对应的主键生成策略:
@Entity(name=”people_entity”)
@Table(name=”people”)
public class People implements Serializable {
private static final long serialVersionUID = 1L;
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
@Column(name=”pid”)
private Integer id;
…….
}
7、@Transient(临时的):排除持久化字段声明
表示该属性并非一个到数据库表的字段的映射,ORM框架将忽略该属性.
如果一个属性并非数据库表的字段映射,就务必将其标示为@Transient,否则,ORM框架默认其注解为@Basic
//工具方法,不需要映射为数据表的一列
8、@Temporal
在核心的 Java API 中并没有定义 Date 类型的精度(temporal precision). 而在数据库中,表示 Date 类型的数据有 DATE, TIME, 和 TIMESTAMP 三种精度(即单纯的日期,时间,或者两者 兼备).当我们使用到java.util包中的时间日期类型,则需要此注释来说明转化java.util包中的类型为数据库中的那三种类型。
注入数据库的类型有三种:
TemporalType.DATE(2008-08-08)
TemporalType.TIME(20:00:00)
TemporalType.TIMESTAMP(2008-08-08 20:00:00.000000001)
用法示例:
import java.util.Date;//java类中日期格式,不能导错包。
@Column(name = "created_time")
@Temporal(TemporalType.TIMESTAMP)
private Date createdTime;
9、@Lob :存储空间大的数据类型
@Lob: 用来声明字段需要大的存储空间。
如果声明了String类型, 则在数据库中默认映射为LongText。
对于二进制数据,domain对象使用byte/Byte[], 则数据库中类型映射为LongBlob。
由于此字段比较大,如果直接加载,则会消耗很大内存。如果设置为延迟加载,则会更为人性化,可以通过@Basic(fetch=LAZY/EAGER),EAGER为立即加载,设置为延迟加载:
使用示例如下:
@Lob
@Basic(fetch=LAZY)
private Byte[] file;
10、@Enumerated:(很重要,枚举类型)
用法:
定义枚举类, 其有两个值:Male/Female
public enum Gender {
Female, Male
}
领域对象的列定义:
@Column(name="t_gender", nullable=false)
@Enumerated(EnumType.ORDINAL)
private Gender gender;
上述列定义中EnumType支持String/Ordinal类型, String是枚举的字符描述值,Ordinal是其位置信息,例如Female其位置为0, Male的位置为1,其存入数据库的值即为0/1.
使用此注解映射枚举字段,以String类型存入数据库
注入数据库的类型有两种:EnumType.ORDINAL(Interger)、EnumType.STRING(String)
11.字段排序
在加载数据的时候可以为其指定顺序,使用@OrderBy注解实现
@Table(name = “USERS”)
public class User {
@OrderBy(name = “group_name ASC, name DESC”)
private List books = new ArrayList();
}
其他注解:
10、@Embedded、@Embeddable:
当一个实体类要在多个不同的实体类中进行使用,而其不需要生成数据库表
@Embeddable:注解在类上,表示此类是可以被其他类嵌套
@Embedded:注解在属性上,表示嵌套被@Embeddable注解的同类型类
11、@ElementCollection:集合映射
12、@CreatedDate、@CreatedBy、@LastModifiedDate、@LastModifiedBy:(很重要)
表示字段为创建时间字段(insert自动设置)、创建用户字段(insert自动设置)、最后修改时间字段(update自定设置)、最后修改用户字段(update自定设置)
用法:
1、@EntityListeners(AuditingEntityListener.class):申明实体类并加注解
2、@EnableJpaAuditing:在启动类中加此注解
3、在实体类中属性中加上面四种注解
4、自定义添加用户
13、@MappedSuperclass:(很重要)
实现将实体类的多个属性分别封装到不同的非实体类中
注解的类将不是完整的实体类,不会映射到数据库表,但其属性将映射到子类的数据库字段
注解的类不能再标注@Entity或@Table注解,也无需实现序列化接口
注解的类继承另一个实体类 或 标注@MappedSuperclass类,他可使用@AttributeOverride 或 @AttributeOverrides注解重定义其父类属性映射到数据库表中字段。
@OneToOne
两实体一对一关系,例如雇员和工作证就是一对一关系,一个雇员只能有一个工作证,一个工作证只能属于一个雇员。
单向关联:查询包含关联属性的实体对象时,能同步从数据库中获取关联的实体对象,反过来不行;
代码如下:
数据库数据:

Employee 类:放到实体类包下。
package com.fan.domain;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import javax.persistence.*;
import java.io.Serializable;
@Data
@AllArgsConstructor
@NoArgsConstructor
@Entity
@Table
public class Employee implements Serializable {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Integer id;
private String name;
@OneToOne
private Card card;
}
Card类:放到实体类包下。
package com.fan.domain;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import javax.persistence.*;
import java.io.Serializable;
@Data
@AllArgsConstructor
@NoArgsConstructor
@Entity
@Table
public class Card implements Serializable {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Integer id;
private String num;
}
EmployeeRepositpry接口:放到dao包下
package com.fan.dao;
import com.fan.domain.Employee;
import org.springframework.data.jpa.repository.JpaRepository;
public interface EmployeeRepositpry extends JpaRepository {
}
CardRepository接口,放到dao包下
package com.fan.dao;
import com.fan.domain.Card;
import org.springframework.data.jpa.repository.JpaRepository;
public interface CardRepository extends JpaRepository {
}
测试类:
package com.fan;
import com.fan.dao.*;
import com.fan.domain.*;
import com.fan.vo.StuVo;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.PageRequest;
import org.springframework.data.domain.Sort;
import org.springframework.data.jpa.domain.Specification;
import org.springframework.test.annotation.Commit;
import org.springframework.transaction.annotation.Transactional;
import org.springframework.util.ObjectUtils;
import javax.annotation.Resource;
import javax.persistence.Transient;
import javax.persistence.criteria.CriteriaBuilder;
import javax.persistence.criteria.CriteriaQuery;
import javax.persistence.criteria.Predicate;
import javax.persistence.criteria.Root;
import java.sql.SQLException;
import java.util.Date;
import java.util.Iterator;
import java.util.List;
import java.util.Optional;
@SpringBootTest
class SpringbootjpaApplicationTest2 {
@Resource
private EmployeeRepositpry employeeRepositpry;
@Resource
private CardRepository cardRepository;
@Test
@Transactional
@Commit
void contextLoads() {
Optional employee = employeeRepositpry.findById(1);
System.out.println(employee);
System.out.println("=================");
Optional card = cardRepository.findById(1);
System.out.println(card);
}
}

这里查询Employee能同步获取到对应的Card,但是查询Card获取不到。
双向关联:
@JoinColumn(name=“address_id”)//注释本表中指向另一个表的外键。会在此类所对应的表中,创建一个列名叫address_id。
双向关联:包含外键定义的实体是拥有关系实体,在关联的非拥有关联实体中,需要用注解的mappedBy属性指明拥有关系实体的关联属性名,如下示例:
package com.fan.domain;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import javax.persistence.*;
import java.io.Serializable;
@Data
@AllArgsConstructor
@NoArgsConstructor
@Entity
@Table
public class Employee implements Serializable {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Integer id;
private String name;
@OneToOne(mappedBy = "employee",fetch = FetchType.LAZY)
private Card card;
}
package com.fan.domain;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import javax.persistence.*;
import java.io.Serializable;
@Data
@AllArgsConstructor
@NoArgsConstructor
@Entity
@Table
public class Card implements Serializable {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Integer id;
private String num;
@OneToOne
@JoinColumn(name = "employee_id")//本表中指向另一个表的外键
private Employee employee;
}
顺带说明下@OneToOne注解中的fetch、cascade属性的意义,@OneToMany、@ManyToOne、@ManyToMany同样具有这两个属性,意义是相同的。fetch属性指明数据抓取策略,EAGER即立即抓取,LAZY延迟加载,指明关联实体对象获取策略;
cascade属性指明级联特性:
CascadeType.PERSIST:级联持久化操作,当将实体保存至数据库时,其对应的关联实体也会被保存至数据库;
CascadeType.REMOVE:级联删除操作,从数据库删除当前实体时,关联实体也会被删除;
CascadeType.DETACH:级联脱管,当前实体被ORM框架脱管,关联实体也被同步脱管,处于脱管状态的实体,修改操作不能持久化到数据库,如下实例:
CascadeType.MERGE:级联合并操作,脱管实体状态被复制ORM框架管理的对应同一条数据库记录的实体中,关联的实体同样执行复制操作,
CascadeType.REFRESH:级联刷新,当前实体修改保存至数据库时,关联的实体状态会重新从数据库加载,忽略掉先前的状态,
CascadeType.ALL:包含上述所有级联操作。
7.一对多双向映射关系
有T_One和T_Many两个表,他们是一对多的关系,注解范例如下
主表Pojo
@Entity
@Table(name = "T_ONE")
public class One implements Serializable {
private static final long serialVersionUID = 1L;
@Id
@Column(name = "ONE_ID", nullable = false)
private String oneId;
@Column(name = "DESCRIPTION")
private String description;
@OneToMany(cascade = CascadeType.ALL, mappedBy = "oneId")//指向多的那方的pojo的关联外键字段
//以@One..开口的我们称为主表,以@Many开头 的我们称为从表。
private Collection manyCollection;
//以@One…开口的我们称为主表,即一的一方;以@Many开头 的我们称为从表,即多的一方。一般从表设置外键,需要设置@JoinColumn;
从表Pojo
@Entity
@Table(name = "T_MANY")
public class Many implements Serializable {
private static final long serialVersionUID = 1L;
@Id
@Column(name = "MANY_ID", nullable = false)
private String manyId;
@Column(name = "DESCRIPTION")
private String description;
@JoinColumn(name = "ONE_ID", referencedColumnName = "ONE_ID")//设置对应数据表的列名和引用的数据表的列名
@ManyToOne//设置在“一方”pojo的外键字段上
private One oneId;
说明: 一对多双向关联跟多对一是一样的 ,在多端生成一个外键,不生成第三张表来管理对应关系,由外键来管理对应关系
我们写一个案例理解以下:
domain包下的类:
Role1类 :
package com.fan.domain;
import lombok.Data;
import javax.persistence.*;
import java.util.List;
/*
* 要求是添加角色的同时将多个用户添加进数据库 */
@Data
@Entity
public class Role1 {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Integer id;
private String roleName;
//一个角色对应多个用户,一对多,cascade = CascadeType.ALL设置级联关系
@OneToMany(cascade = CascadeType.ALL,mappedBy = "role1")//让多的一方放弃关系维护,让一的一方去维护
private List users;
}
User1 类:
package com.fan.domain;
import lombok.Data;
import javax.persistence.*;
@Data
@Entity
public class User1 {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY )
private Integer id;
private String userName;
//多个用户对应一个角色
@ManyToOne
@JoinColumn(name = "role1_id")
private Role1 role1;
}
dao包下的接口:
package com.fan.dao;
import com.fan.domain.User;
import com.fan.domain.User1;
import org.springframework.data.jpa.repository.JpaRepository;
public interface User1Repository extends JpaRepository{
}
package com.fan.dao;
import com.fan.domain.Role1;
import com.fan.domain.User;
import org.springframework.data.jpa.repository.JpaRepository;
public interface Role1Repository extends JpaRepository{
}
springboot测试类:
package com.fan;
import com.fan.dao.*;
import com.fan.domain.*;
import com.fan.vo.StuVo;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.PageRequest;
import org.springframework.data.domain.Sort;
import org.springframework.data.jpa.domain.Specification;
import org.springframework.test.annotation.Commit;
import org.springframework.transaction.annotation.Transactional;
import org.springframework.util.ObjectUtils;
import javax.annotation.Resource;
import javax.persistence.Transient;
import javax.persistence.criteria.CriteriaBuilder;
import javax.persistence.criteria.CriteriaQuery;
import javax.persistence.criteria.Predicate;
import javax.persistence.criteria.Root;
import java.sql.SQLException;
import java.util.*;
@SpringBootTest
class SpringbootjpaApplicationTest2 {
//注入接口
@Resource
private User1Repository user1Repository;
@Resource
private Role1Repository role1Repository;
@Test
void contextLoads() {
//级联添加:添加角色的同时添加用户
//创建角色对象
Role1 role1 = new Role1();
role1.setRoleName("射手");
//创建两个用户
User1 user1 = new User1();
user1.setUserName("寒冰");
User1 user2 = new User1();
user2.setUserName("好运姐");
//设置两个对象之间的关联关系,给每个用户设置自己的角色
user1.setRole1(role1);
user2.setRole1(role1);
//获取角色的集合,将用户add进去集合中,角色设置自己的所有用户
ArrayList users = new ArrayList<>();
users.add(user1);
users.add(user2);
role1.setUsers(users);
//级联保存
role1Repository.save(role1);
}
}
数据库结果:
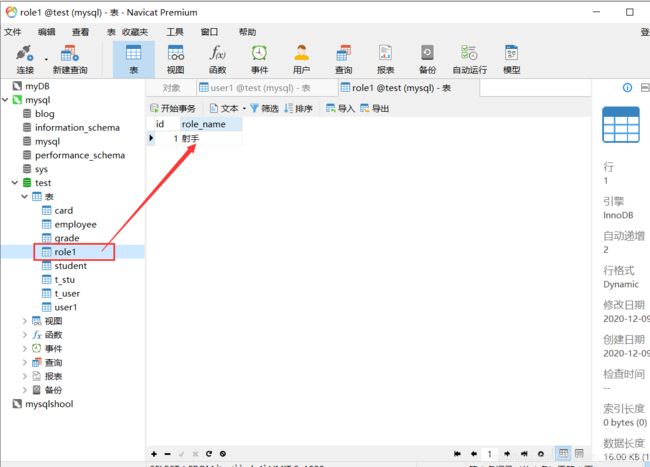
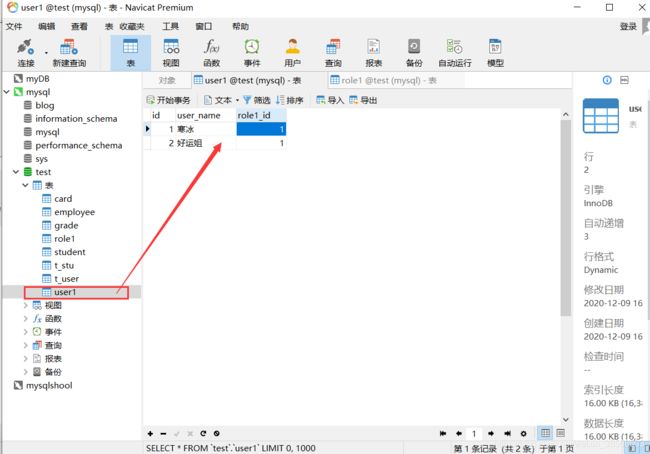

@ManyToMany:多对多
代码演示:
Employee类:
package com.fan.domain;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import javax.persistence.*;
import java.util.ArrayList;
import java.util.List;
@Data
@NoArgsConstructor
@AllArgsConstructor
@Entity
public class Employee {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Integer id;
private String empName;
//一个员工负责多个项目,多对多放弃维护权,被动的一方放弃
@ManyToMany(mappedBy = "emps")
private List projects = new ArrayList();//这里需要初始化list
//名字的构造方法
public Employee(String empName) {
this.empName = empName;
}
}
Project类:
package com.fan.domain;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import javax.persistence.*;
import java.util.ArrayList;
import java.util.List;
//给项目分配员工
@Data
@NoArgsConstructor
@AllArgsConstructor
@Entity
public class Project {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Integer id;
private String projectName;
//一个项目被多个员工负责,targetEntity:代表对方的实体类字节码
/**
* 级联保存:::::cascade = CascadeType.ALL
* 配置员工到项目的多对多关系
* 配置多对多的映射关系
* 1.声明表关系的配置
* @ManyToMany(targetEntity = Employee.class) //多对多
* targetEntity:代表对方的实体类字节码
* 2.配置中间表(包含两个外键)
* @JoinTable
* name : 中间表的名称
* joinColumns:配置当前对象在中间表的外键
* @JoinColumn的数组
* name:外键名
* referencedColumnName:参照的主表的主键名
* inverseJoinColumns:配置对方对象在中间表的外键
*/
@ManyToMany(targetEntity = Employee.class,cascade = CascadeType.ALL)
@JoinTable(
//代表中间表名称
name = "employee_project",
//中间表的外键对应到当前表的主键名称,name = "project_id",是自己命名的
joinColumns = {@JoinColumn(name = "project_id", referencedColumnName = "id")},
//中间表的外键对应到对方表的主键名称
inverseJoinColumns = {@JoinColumn(name = "emp_id", referencedColumnName = "id")}
)
private List emps=new ArrayList();//要new 初始化
//名字的构造方法
public Project(String projectName) {
this.projectName = projectName;
}
}
dao接口:
package com.fan.dao;
import com.fan.domain.Project;
import org.springframework.data.jpa.repository.JpaRepository;
public interface ProjectRepository extends JpaRepository{
}
测试类:
package com.fan;
import com.fan.dao.*;
import com.fan.domain.*;
import com.fan.vo.StuVo;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.PageRequest;
import org.springframework.data.domain.Sort;
import org.springframework.data.jpa.domain.Specification;
import org.springframework.test.annotation.Commit;
import org.springframework.test.annotation.Rollback;
import org.springframework.transaction.annotation.Transactional;
import org.springframework.util.ObjectUtils;
import javax.annotation.Resource;
import javax.persistence.Transient;
import javax.persistence.criteria.CriteriaBuilder;
import javax.persistence.criteria.CriteriaQuery;
import javax.persistence.criteria.Predicate;
import javax.persistence.criteria.Root;
import java.sql.SQLException;
import java.util.*;
//测试级联添加:给项目分配员工
@SpringBootTest
class SpringbootjpaApplicationTest2 {
//注入接口
@Resource
private ProjectRepository projectRepository;
@Test//以下两个注解必须提供
@Transactional//开启事务
@Rollback(false)//取消回滚
public void testAdd() {
//创建两个项目对象
Project project1=new Project("超市管理系统");
Project project2=new Project("酒店管理系统");
//创建三个员工对象
Employee employee1=new Employee("张三");
Employee employee2=new Employee("李四");
Employee employee3=new Employee("王五");
// 设置关联关系//给超市管理系统分配员工
project1.getEmps().add(employee1);
project1.getEmps().add(employee2);
project1.getEmps().add(employee3);
//给酒店管理系统分配员工
project2.getEmps().add(employee1);
project2.getEmps().add(employee2);
//若没有级联,则必须要进行EmployeeRepository.save(employee1);的保存操作
//保存
projectRepository.save(project1);
projectRepository.save(project2);
}
}