【Linux】进程控制——程序替换
文章目录
- 程序替换
-
- 概念
- 测试
- 程序替换的基本原理
- exec 接口的使用
-
- 理解
- 认识接口
- 如何理解环境变量可以被子进程继承下去
程序替换
概念
我们创建子进程的目的是——为了让子进程帮我执行特定的任务。
- 让子进程执行父进程的部分代码。
- 让子进程执行一段全新的代码。(程序替换)
对于 1 ,我们已经在上一篇文章仔细介绍了,那么本文就主要介绍程序替换的原理。
上一篇文章提到,写时拷贝可以对数据进行改变,但是不可以改变代码,实际上,程序替换就可以做到改变代码!
测试
程序替换要用到 exec 函数簇。
如下是使用 man 手册查看的该函数簇。
第一个函数 execl 中,第三个参数是 … 这是可变参数,可以类比 printf() 函数。可变参数允许我们传递任意个参数。

如下是测试代码。可变参数列表中,最后一个参数是 NULL,这是规定的,最后一个参数要为 NULL。
1 #include<stdio.h>
2 #include<unistd.h>
3
4
5 int main()
6 {
7 printf("begin\n");
8 printf("begin\n");
9 printf("begin\n");
10 printf("begin\n");
11
12 execl("/usr/bin/ls","ls","-a","-l",NULL);
13
14 printf("end\n");
15 printf("end\n");
16 printf("end\n");
17 printf("end\n");
18 return 0;
19 }
查看运行结果,打印完 begin 之后,就执行 ls -al 指令,然后并没有打印 end。
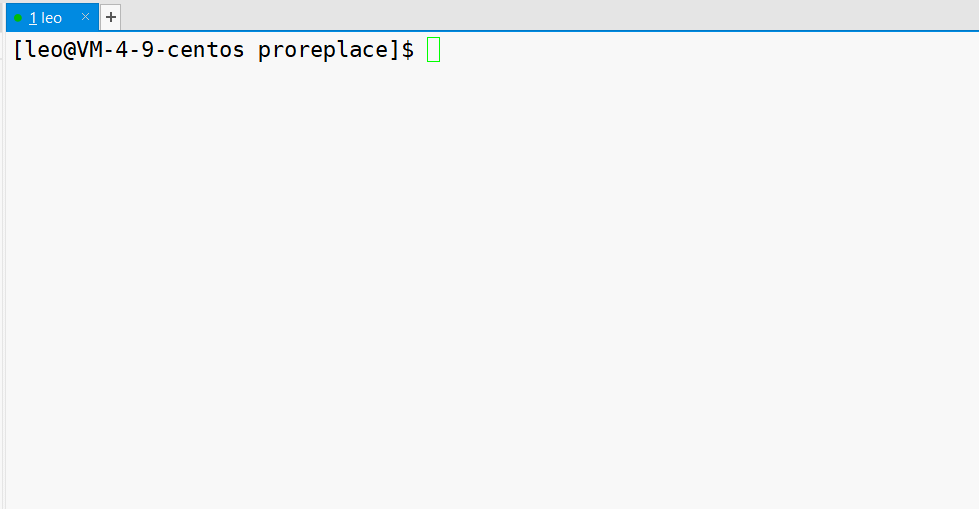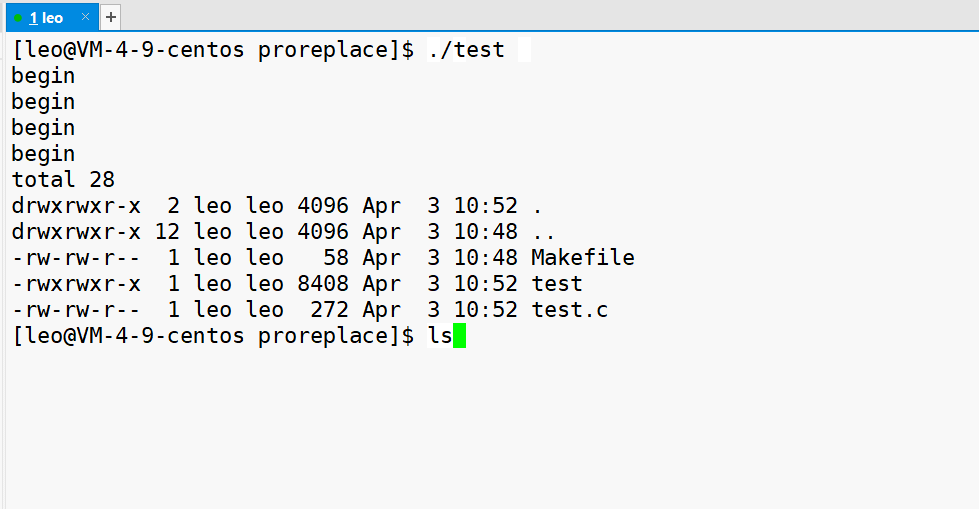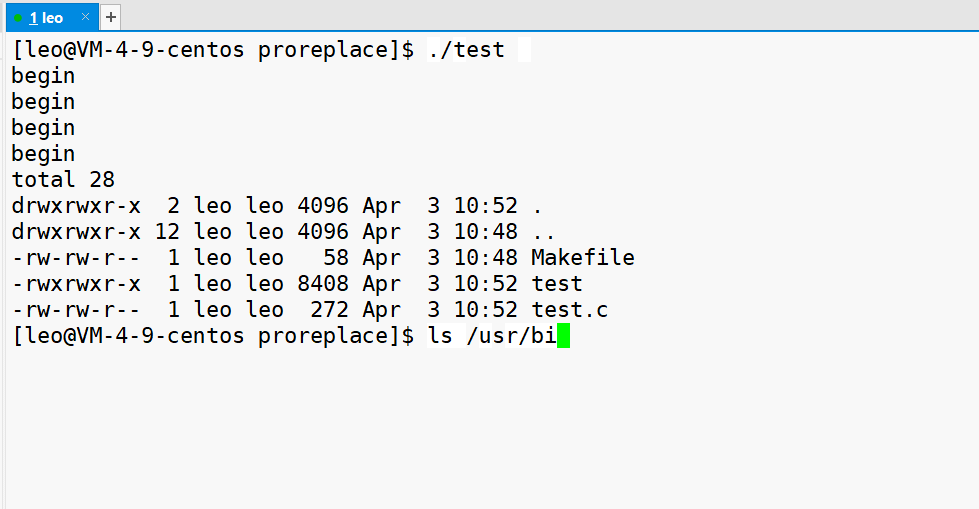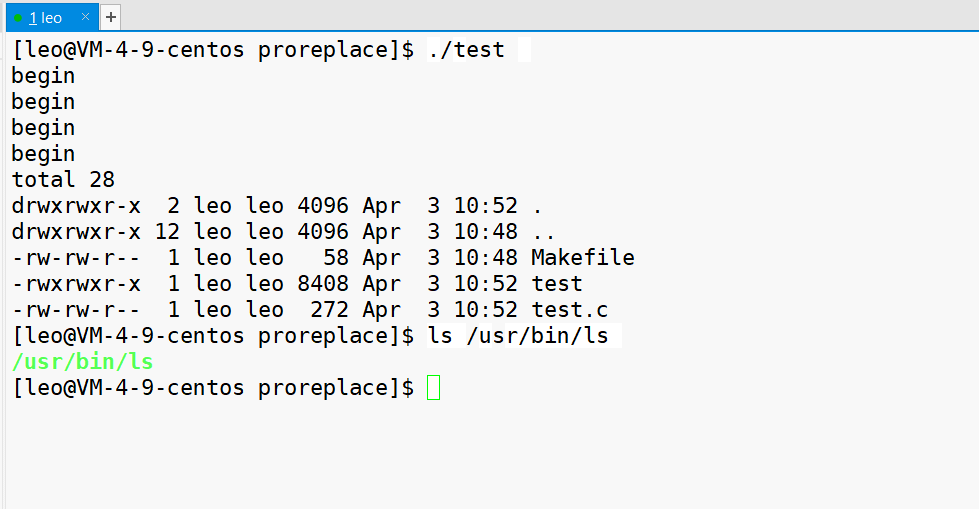
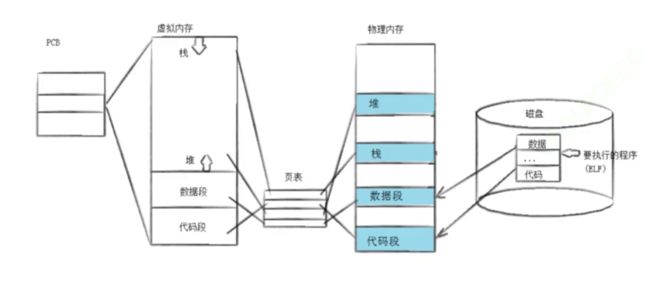
如下图,可以这样子理解。gcc 编译之后,生成 test 可执行文件,当我们 ./test 的时候,这个可执行文件就被执行,变成一个进程,那么代码和数据就会被加载到内存。
开始执行代码,打印 end。
遇到了系统调用 execl ,执行 ls,ls 的代码和数据也是在磁盘里的,也被加载到内存。只不过 ls 的代码和数据,会替换当前进程所有的代码和数据,然后执行 ls。
后面的代码已经被替换,没有机会执行。

所以,通过上面的例子,我们就可以大致理解程序替换在做什么 —— 让一个进程执行另一个在磁盘中的程序。
程序替换的基本原理
理解了进程地址空间之后,理解程序替换实际上就非常的容易。
如下图,当一个调用程序替换的系统调用时,就会从磁盘中加载要执行的程序A,将其代码和数据替换到进程的数据段和代码段,然后进程就会执行程序A。进程的内核数据结构是不改变的,只是替换了代码和数据。
进程的程序替换,并没有创建新的进程,只是把一个新的程序加载到当前进程的代码和数据,然后让CPU调度该进程。
我们可以从两个角度理解:
- 进程角度:进程只进行进程控制,对于进程控制而言,基本上没有改变, PCB、进程地址空间、页表左半部分都没有上面变化。
- 程序角度:自己被加载到内存。(可以将 exec 簇函数称作 “加载器”)
既然我们自己写的代码能加载新的程序,那么操作系统呢?操作系统当然也是可以的,只是在理解这个之前,我们要先理解 —— 创建一个进程,是先创建内核数据结构,还是先加载代码和数据到内存。
假设执行下列代码。只有程序替换,必然是先创建进程的内核数据结构、地址空间等等,然后去调用 execl,把代码和数据加载到内存。
1 #include<stdio.h>
2 #include<unistd.h>
3
4
5 int main()
6 {
7 execl("/usr/bin/ls","ls","-a","-l",NULL);
8 return 0;
9 }
那么,操作系统创建进程,以执行 C语言生成的可执行文件 test 为例,是先创建内核数据结构等等,然后CPU开始调度,最先执行的根本不是 main ,而是先调用系统调用 exec ,将用户的想要执行的指令传递给 exec (也就是 ./test ),然后把 test 的代码和数据加载到内存,执行。
也就是说,操作系统也可以进行程序替换,程序替换并不一定是自己的可执行程序内部才能进行。
exec 接口的使用
理解
程序替换是整体性的替换,不可以局部替换。
如下代码,如果子进程执行 execl() 系统调用,那么就会替换整个代码,父进程就无法执行。
运行该程序,结果却不是这样。
1 #include<stdio.h>
2 #include<unistd.h>
3 #include<sys/types.h>
4 #include<sys/wait.h>
5
6 int main()
7 {
8 pid_t id=fork();
9 if(id == 0)
10 {
11 // child
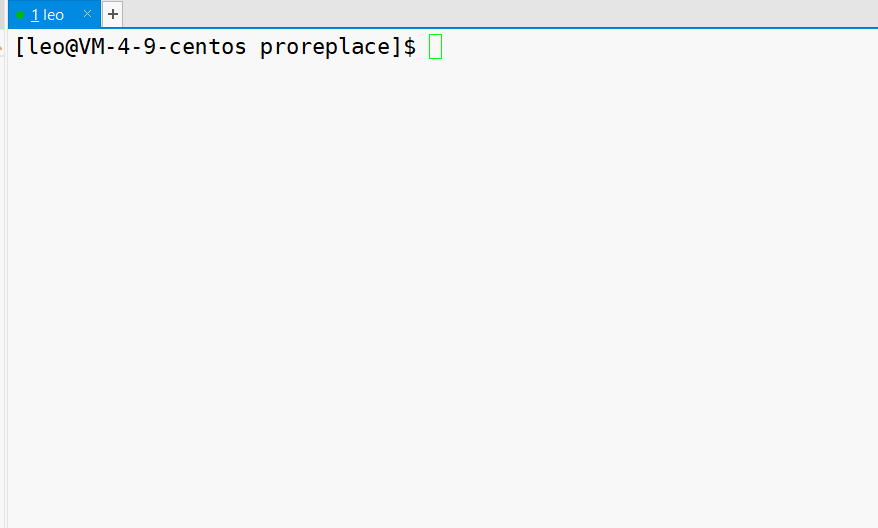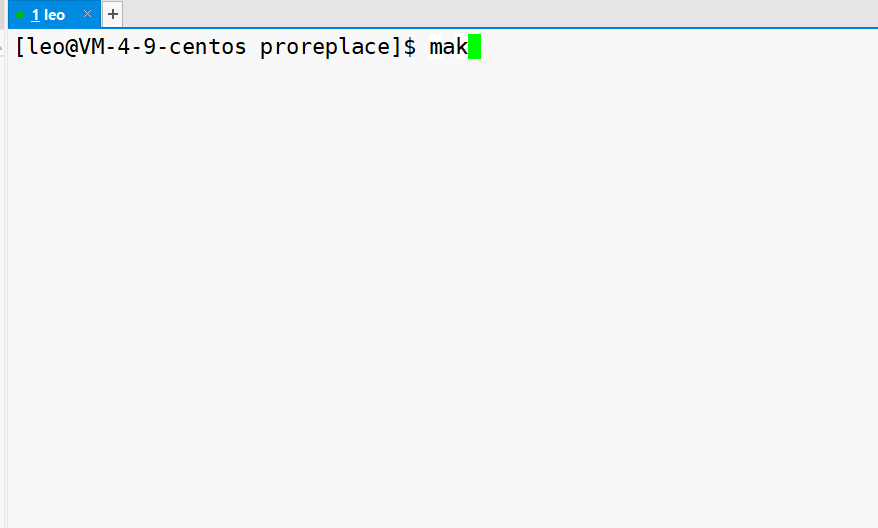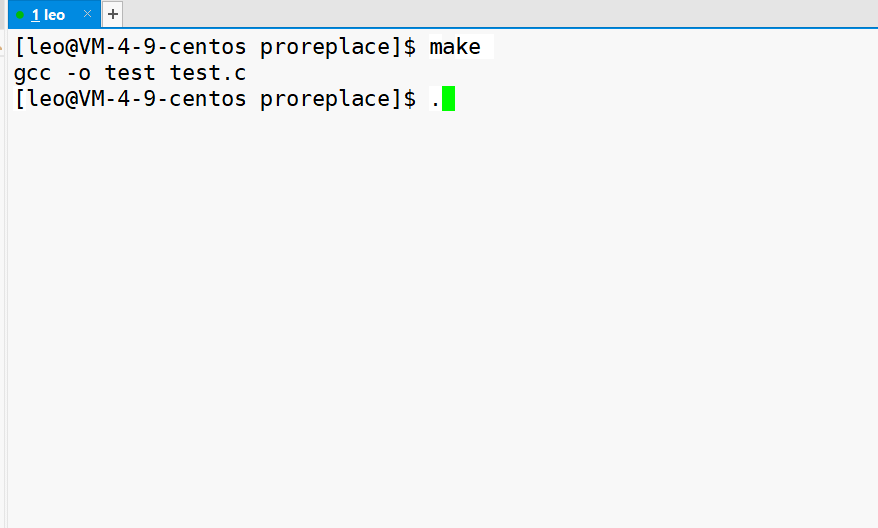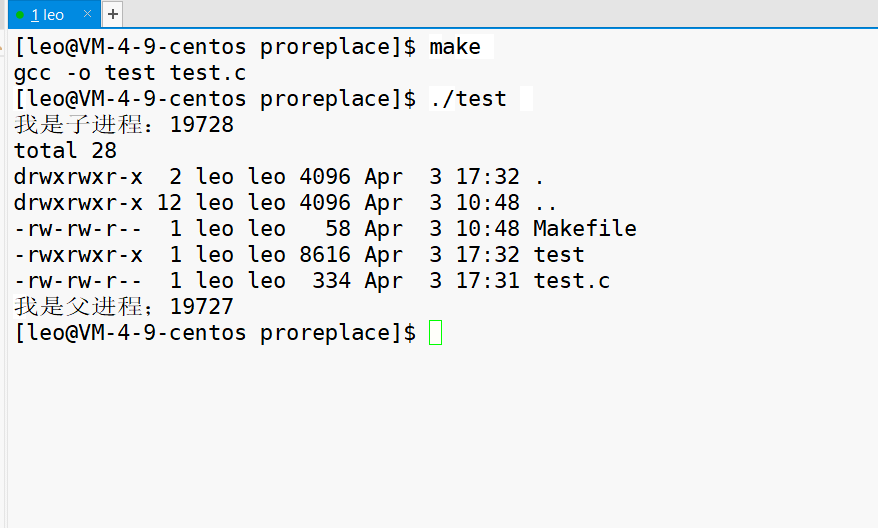
12 printf("我是子进程:%d\n",getpid());
13 execl("/usr/bin/ls","ls","-a","-l",NULL);
14 }
15 sleep(5);
16 printf("我是父进程;%d\n",getpid());
17 waitpid(id,NULL,0);
18 return 0;
19 }
如下运行结果,父进程依然执行自己的代码,这说明,在我们引入子进程之后,程序替换只影响调用程序替换的进程。
实际上,这也不难理解,这是为了保证进程的独立性。
那么,父进程如何得知子进程程序替换是否成功呢?必定是使用 waitpid 函数,得到子进程的退出码。
首先,exec 函数簇,如果程序替换成功,是没有返回值的;如果程序替换失败,才会返回。
也就是说,不需要对这一类函数进行返回值判断,只要程序按照原来的执行(没有进行替换),那么程序替换就是失败的。
1 #include<stdio.h>
2 #include<unistd.h>
3 #include<sys/types.h>
4 #include<sys/wait.h>
5 #include<stdlib.h>
6
7 int main()
8 {
9 pid_t id=fork();
10 if(id == 0)
11 {
12 // child
13 printf("我是子进程:%d\n",getpid());
14 execl("/usr/bin/ls","ls","-a","-l",NULL);
15 exit(1);
16 }
17 sleep(5);
18 int status=0;
19 printf("我是父进程;%d\n",getpid());
20 waitpid(id,&status,0);
21 printf("child exit code:%d\n",WEXITSTATUS(status));
22
23 return 0;
24 }
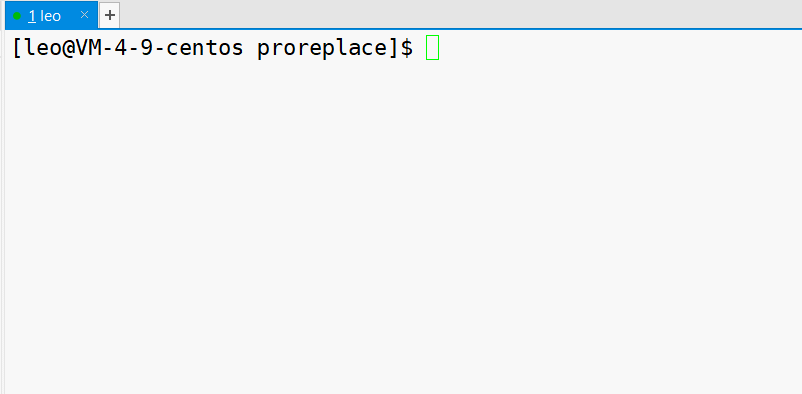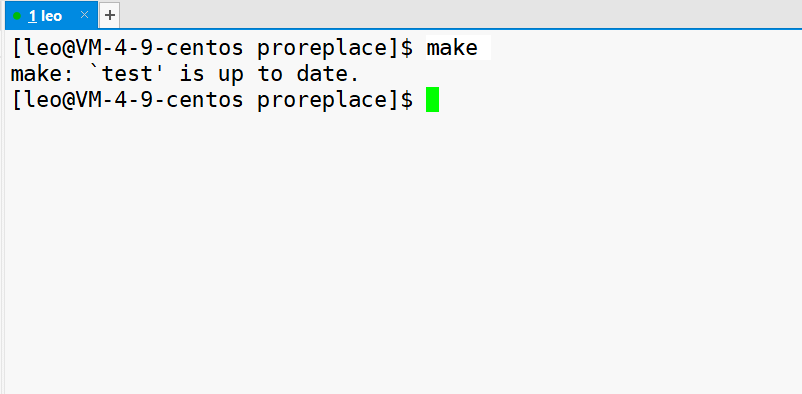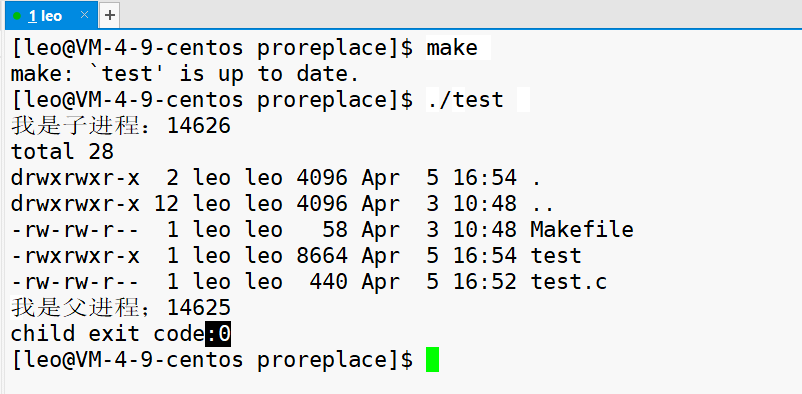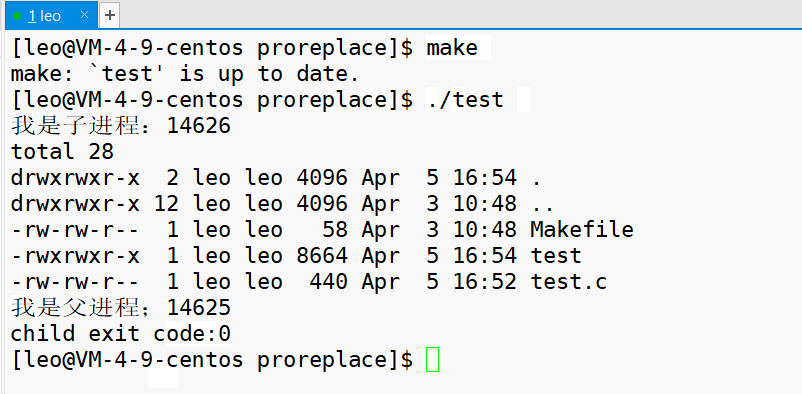
对于上述代码,执行结果如下。
程序替换是没有问题的,那么子进程就不会执行 exit(1) ,而是执行 ls 语句, 执行成功,子进程退出码是 0 。
认识接口
执行一个程序,需要 程序路径+执行方式。
execl 接口就不过多阐述了,上面也用了多次。主要就是其第一个参数,要是程序路径,这是为了找到程序。后面的参数就是执行方式,在命令行是怎么敲的,这里一摸一样,最后以 NULL 结尾。
execlp 函数
int execlp(const char* file,const char* arg,……)
该函数不需要我们自己写程序路径,这是因为他会自己在环境变量 PATH 里面找,第一个参数是程序名,所以只需要指定程序名即可。
如下是代码示例。第一个参数 ls ,代表的是要执行的程序文件名;第二个 ls 就是我们命令行里面敲击的 ls 指令一样。
1 #include<stdio.h>
2 #include<unistd.h>
3 #include<sys/types.h>
4 #include<sys/wait.h>
5 #include<stdlib.h>
6
7 int main()
8 {
9 pid_t id=fork();
10 if(id == 0)
11 {
12 // child
13 printf("我是子进程:%d\n",getpid());
14 execlp("ls","ls","-a","-l",NULL);
15 exit(1);
16 }
17 sleep(5);
18 int status=0;
19 printf("我是父进程;%d\n",getpid());
20 waitpid(id,&status,0);
21 printf("child exit code:%d\n",WEXITSTATUS(status));
22
23 return 0;
24 }
execvp 函数
int execvp(const char* file,char *const argv[ ])
这个函数在 ‘p’ 的基础上增加了一个 ‘v’ ,(函数名 ,execl、execlp,execvp)那么它也有 ‘p’ 的特点——不用传程序的具体地址,只需要传程序的名字。
v 的意思就是,执行指令的方式——不需要我们手动敲到函数的参数里面,只需要放到一个数组里面,传数组的指针即可,注意数组里面最后也要是 NULL 。
1 #include<stdio.h>
2 #include<unistd.h>
3 #include<sys/types.h>
4 #include<sys/wait.h>
5 #include<stdlib.h>
6
7 int main()
8 {
9 pid_t id=fork();
10 if(id == 0)
11 {
12 // child
13 printf("我是子进程:%d\n",getpid());
14 char * const myargv[]={
15 "ls",
16 "-a",
17 "-l",
18 "NULL"
19 };
20 execvp("ls",myargv);
21 exit(1);
22 }
23 sleep(5);
24 int status=0;
25 printf("我是父进程;%d\n",getpid());
26 waitpid(id,&status,0);
27 printf("child exit code:%d\n",WEXITSTATUS(status));
28
29 return 0;
30 }
execle 函数
int execle(const char* path,const char* arg,……,char* const envp[])
这个函数没有 ‘p’ ,也没有 ‘v’ ,那么就要手动输入地址,并且不能以数组的形式传递指令。
该函数最后一个参数是 自定义环境变量。
这里,我们不执行 Linux 原有的程序,我们在当前目录下 新建另一个目录 another,然后在里面写一个程序 mytest ,执行这个程序。
如下是 mytest.c 的程序,编译之后生成 mytest 这个可执行程序。
1 #include<iostream>
2 #include<stdlib.h>
3 using namespace std;
4
5 int main()
6 {
7 cout<<"我是另一个程序,自定义环境变量 hello = "<< getenv("hello")<<endl;
8 cout<<"我是另一个程序,系统环境变量 PATH ="<<(getenv("PATH")==NULL ? "不存在" : getenv("PATH"))<<endl;
9 return 0;
10 }
如下是原本的程序代码。
1 #include<stdio.h>
2 #include<unistd.h>
3 #include<sys/types.h>
4 #include<sys/wait.h>
5 #include<stdlib.h>
6
7 int main()
8 {
9 pid_t id=fork();
10 if(id == 0)
11 {
12 // child
13 printf("我是子进程:%d\n",getpid());
14 char * const myenv[]={
15 "hello=Hello World!",
16 NULL
17 };
18
19 execle("./another/mytest","mytest",NULL,myenv);
20 exit(1);
21 }
22 sleep(3);
23 int status=0;
24 printf("我是父进程;%d\n",getpid());
25 waitpid(id,&status,0);
26 printf("child exit code:%d\n",WEXITSTATUS(status));
27
28 return 0;
29 }
执行结果如下。我们发现,子进程里面,发生程序替换之后,自己传入的环境变量是打印了出来,但是系统环境变量却找不到了。这说明传入的自定义环境变量参数是一种 覆盖式传参。
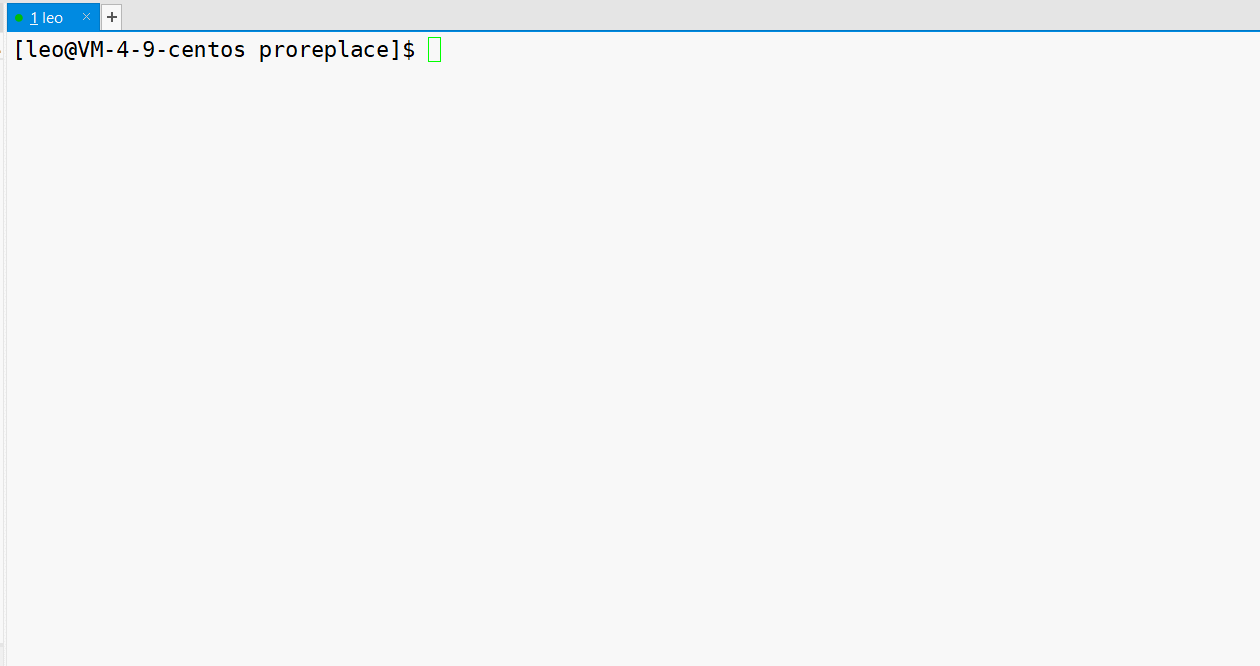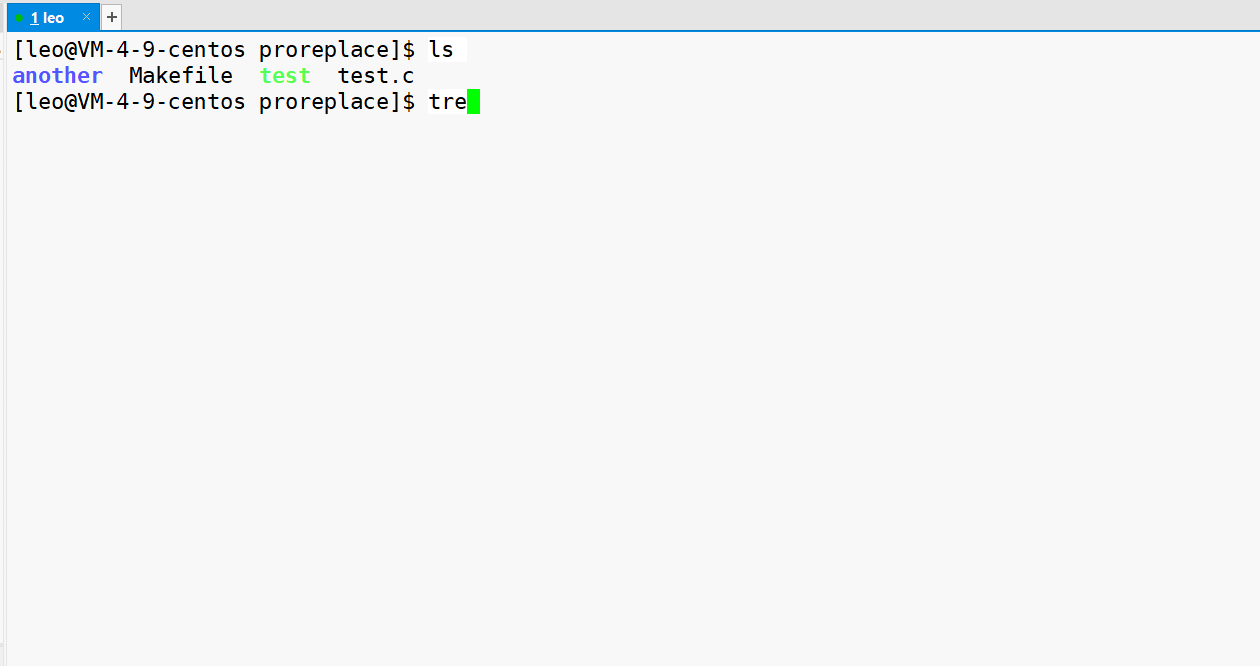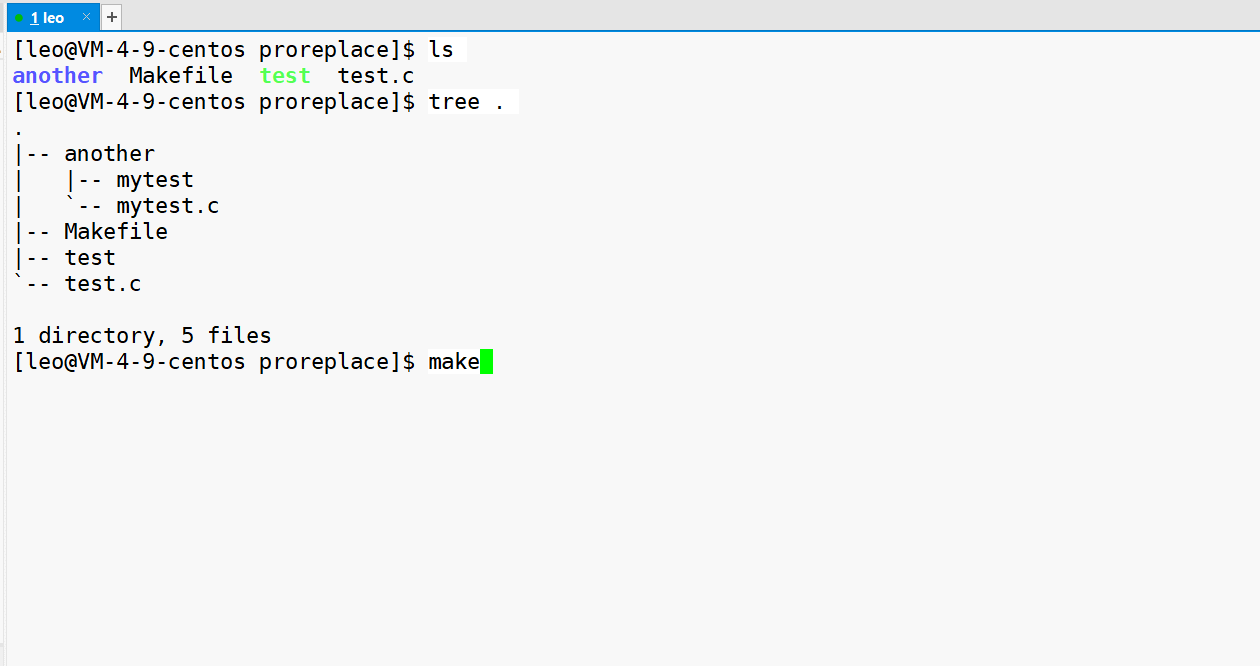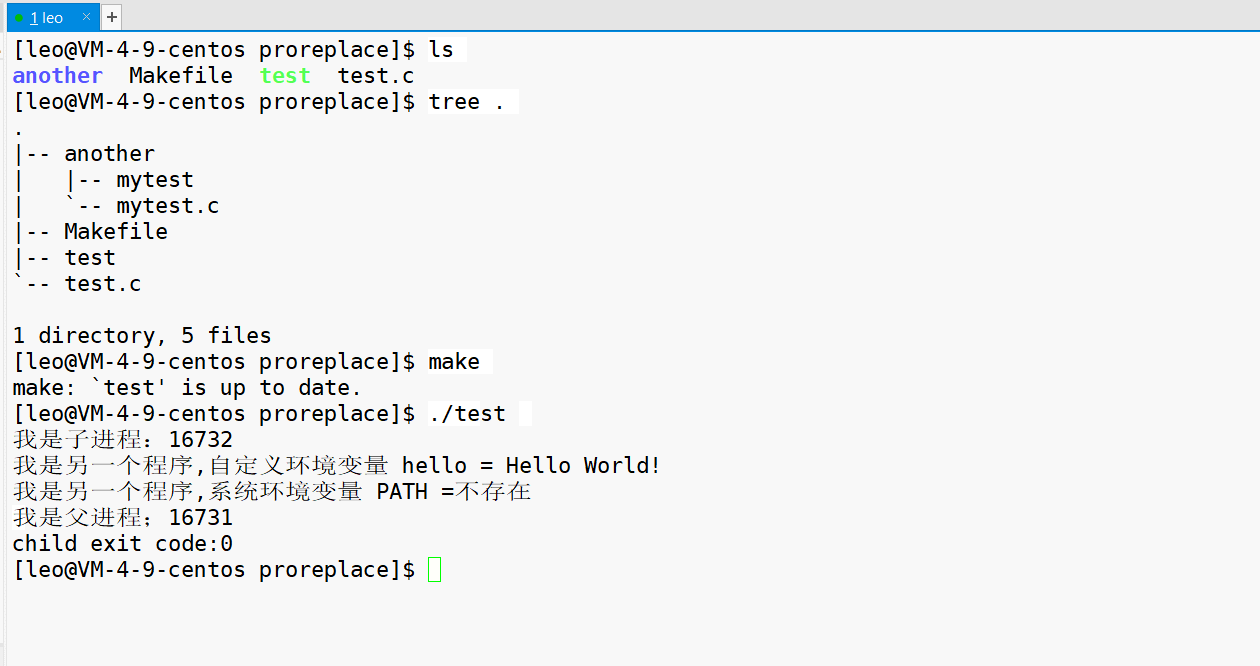
其他的几个函数,分别是对 ‘p’ ‘v’ ‘e’ 的一些组合,本质上明白了这三个,就可以理解。
上述的几个接口,其实是对 execve 接口的封装,execve 是操作系统提供的,唯一的程序替换的系统调用。另外几个接口是操作系统对 execve 的封装,这是为了适合不同场景的应用。

如何理解环境变量可以被子进程继承下去
如下,部分代码,使用 putenv 函数将 hello 导入当前进程环境变量,然后将环境变量传给子进程。
1 #include<stdio.h>
2 #include<unistd.h>
3 #include<sys/types.h>
4 #include<sys/wait.h>
5 #include<stdlib.h>
6
7 int main()
8 {
9 extern char** environ;
10 pid_t id=fork();
11 if(id == 0)
12 {
13 // child
14 printf("我是子进程:%d\n",getpid());
15 putenv("hello=HELLO WORLD!");
16 execle("./another/mytest","mytest",NULL,environ);
17 exit(1);
18 }
19 sleep(3);
20 int status=0;
21 printf("我是父进程;%d\n",getpid());
22 waitpid(id,&status,0);
23 printf("child exit code:%d\n",WEXITSTATUS(status));
24
25 return 0;
26 }
这段代码的运行结果如下。
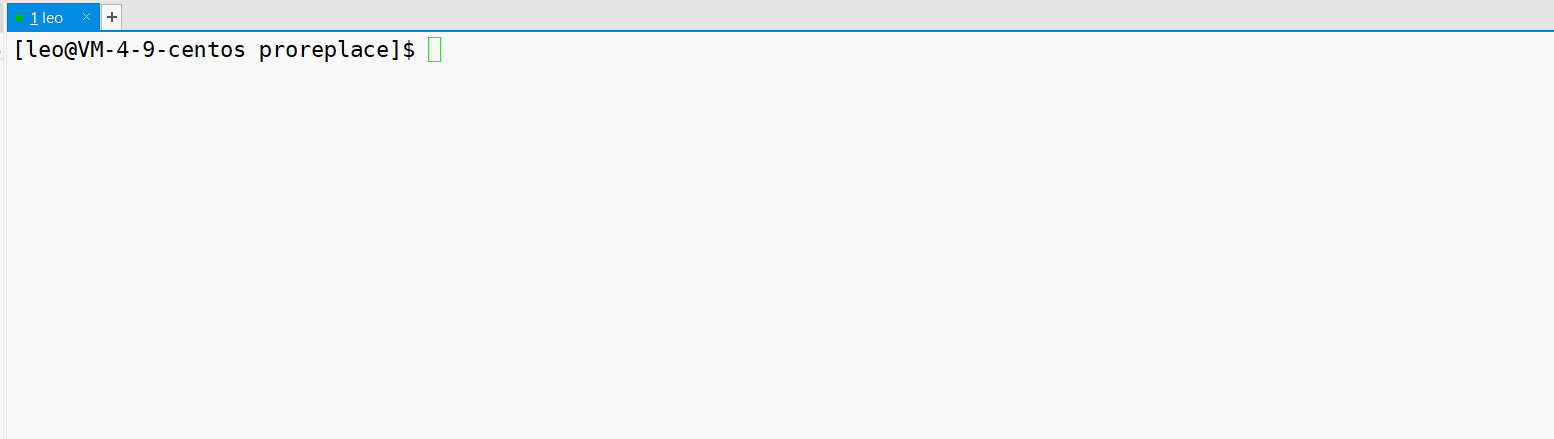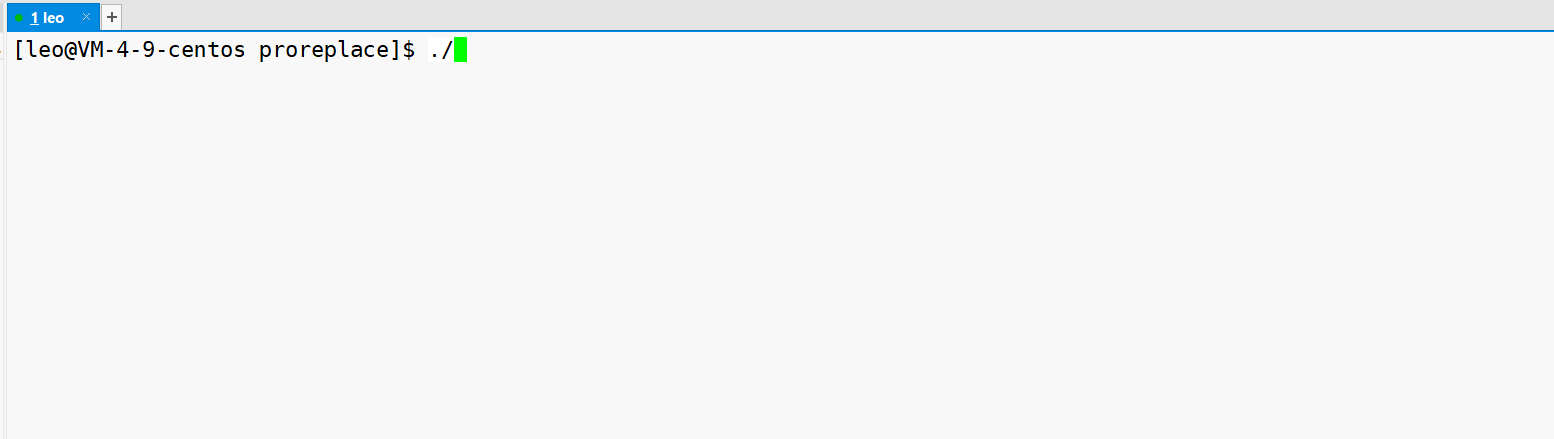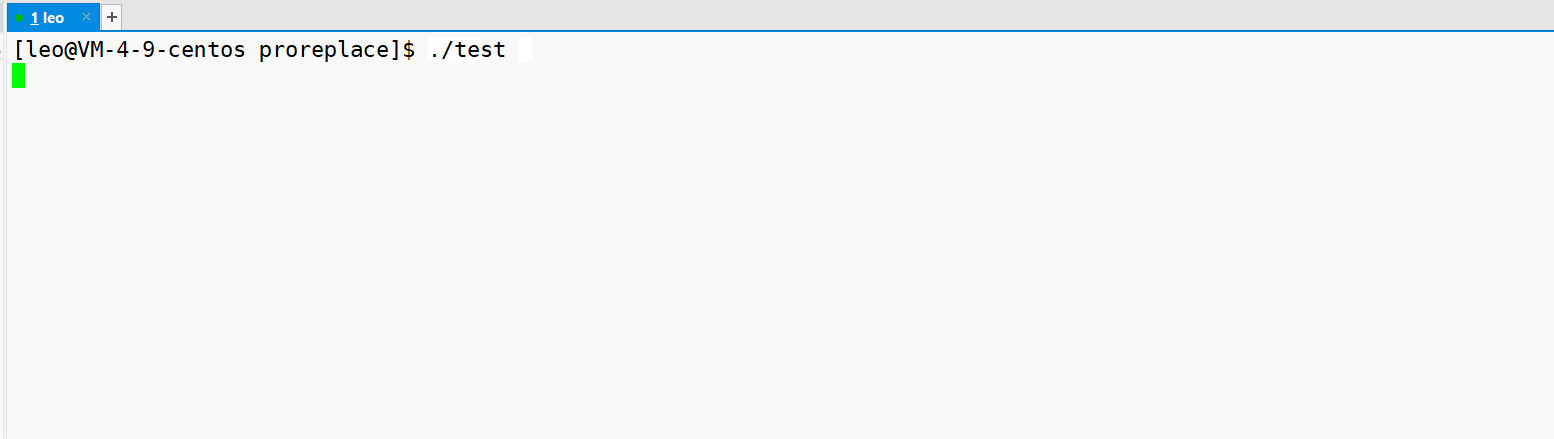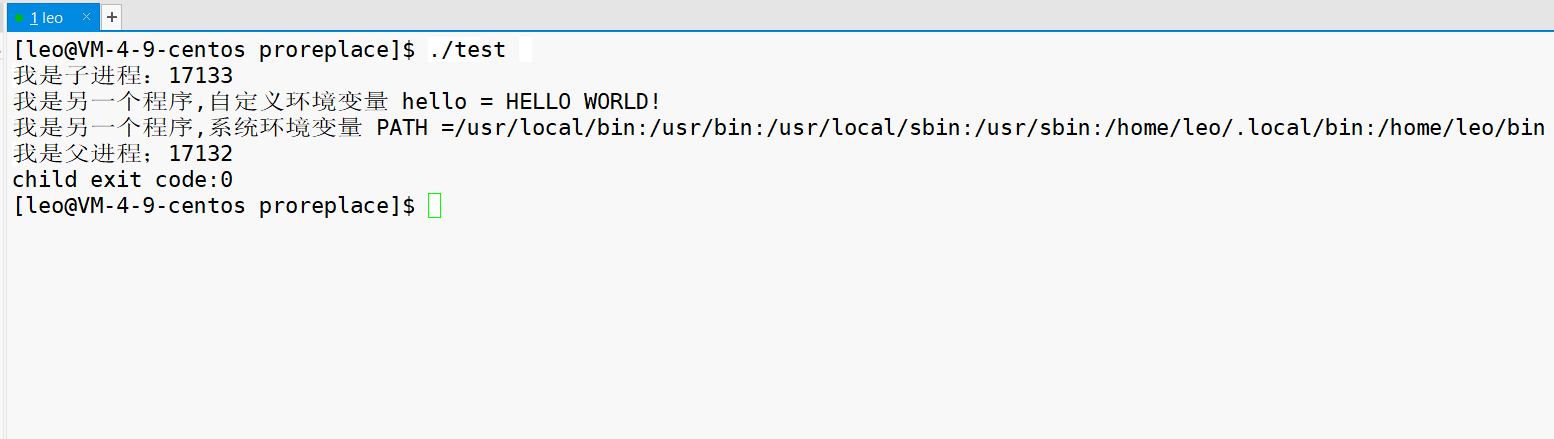
到这里,就可以理解为什么环境变量具有全局属性,可以被子进程继承下去。
我们在命令行上敲击的所有指令都是 bash 的子进程,bash 可以通过 exec 来执行,要将 bash 的环境变量交给子进程,可以通过 execle 来完成。通过execle,就完成了将环境变量传递给子进程的操作。