RDS for SQL server 空间问题排查汇总
SQL server的空间问题一直有客户在询问,今天就给大家汇总讲解下SQL server 的全部空间开销。
SQL server 的空间组成
从文件类型来看,SQL server 的文件类型分数据文件(MDF,NDF),日志文件(LDF)
从数据库来看分为系统数据库和用户数据库,其中系统数据库中,最容易出现空间问题的,就是临时数据库(tempdb)
下面我们将分别来研究下空间的常见问题和解决方法。
用户数据库的数据文件
正常情况下,数据文件是随着数据库使用,正常增长的。
sp_spaceused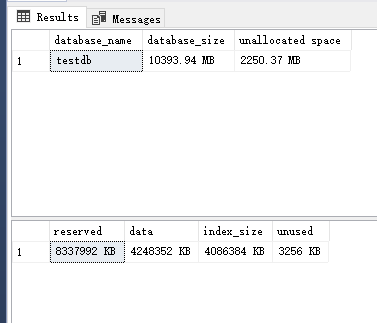
这里给大家解释下,这几个参数。假设我们只有一个MDF,和一个LDF。
那么MDF 的文件大小 = reserved(8142.5MB) + unallocated space (2250.37MB)
Reserved (8337992KB)= DATA(4248352KB) +INDEX_SIZE(4086384KB) + Unused(3256KB)
Database size(10393.94MB) = MDF(10392.94MB) + LDF(1MB)
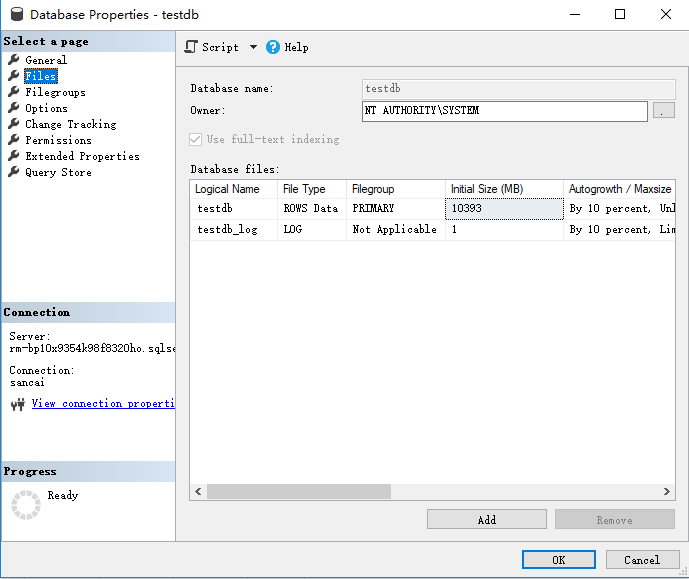
但是有时候,因为频繁更改,会带来碎片(fragmentation),碎片度太高,会导致内部的空间浪费。同时,每个SQL 操作,因为碎片,可能要访问更多的页面(page),导致开销变大。
可以通过这个命令查看下当前数据库的索引碎片。
SELECT dbschemas.[name] as 'Schema',
dbtables.[name] as 'Table',
dbindexes.[name] as 'Index',
indexstats.avg_fragmentation_in_percent,
indexstats.page_count
FROM sys.dm_db_index_physical_stats (DB_ID(), NULL, NULL, NULL, NULL) AS indexstats
INNER JOIN sys.tables dbtables on dbtables.[object_id] = indexstats.[object_id]
INNER JOIN sys.schemas dbschemas on dbtables.[schema_id] = dbschemas.[schema_id]
INNER JOIN sys.indexes AS dbindexes ON dbindexes.[object_id] = indexstats.[object_id]
AND indexstats.index_id = dbindexes.index_id
WHERE indexstats.database_id = DB_ID()
ORDER BY indexstats.avg_fragmentation_in_percent desc
通常情况下,碎片度大于30%的索引,我们会选择rebuild index。
ALTER INDEX [idx_name] ON [dbo].[test] REBUILD 当然rebuild 之后,这些碎片空间也不会直接被OS回收,而是作为数据文件的可重用空间。
如果特别想回收这部分空间,可以尝试下这个命令,回收下文件尾部的空间。
dbcc shrinkfile(N'testdb',0,truncateonly)
用户数据库的日志文件
SQL server的redo 段和 undo 段都是记录在 T-Log的,所以很容易被撑大。
我们的SQL Server都是使用 FULL RECOVERY 级别,所以日志空间并不会自动释放。
如何查看LOG 大小
dbcc sqlperf(logspace)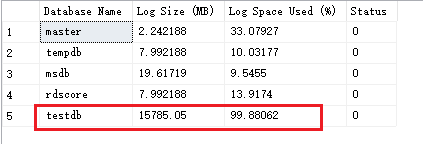
可以看见testdb 这个库,有15G的日志占用,切使用率99%
Log Reuse 的最常见的两种原因:
1) Log backup
2) Active transaction
那么,如何具体查看LOG 等待 reuse的原因?
select name,log_reuse_wait_desc,* from sys.databases where name='testdb'
原因一:日志产生过快,日志备份频率过低,等待日志备份

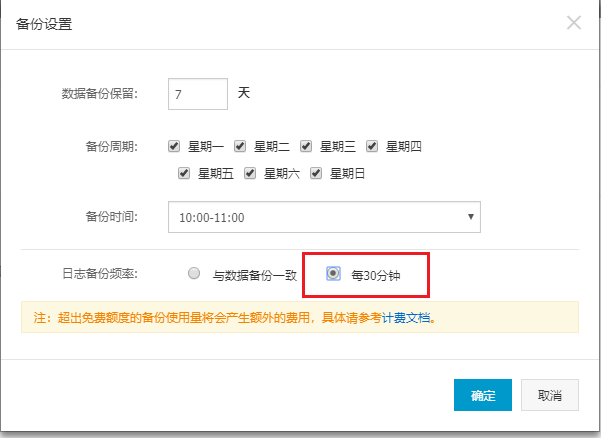
大部分情况,这里应该是log_backup, 这时候,如果日志占用很大且利用率很高,就可以考虑调整下日志备份策略。修改的地址在 备份恢复-> 备份设置-> 编辑,我们这里可以改成30分钟一次,以提高备份频率。
等到log使用率下降后,我们可以通过这个命令来shrink 日志文件,也可以通过控制台上“收缩事务日志”按钮来收缩日志。
-- 注意,可以通过这里查询下当前数据库的日志文件名,替换下文中的test_log
-- select name,* from sys.database_files where name='dbname'
-- 此处,将尽可能的让testdb_log日志收缩到100MB
dbcc shrinkfile (N'test_log',100)
原因二:有活跃事务阻塞了日志空间释放

如果是Active transaction, 那么可以这么去查
dbcc opentran 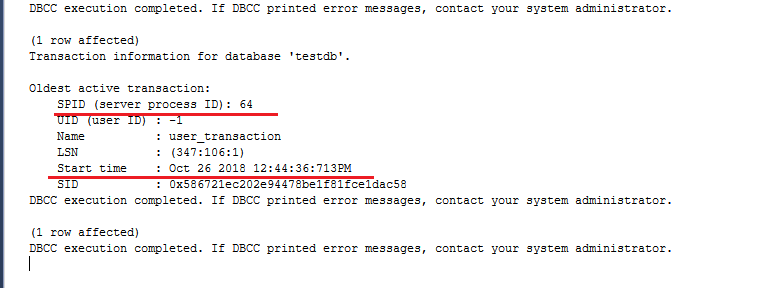
这里就能看见阻塞者的开始时间,已经SPID。根据SPID,可以再查到这个会话最后一条SQL语句是什么。
dbcc inputbuffer(64)

把session kill之后,再查下log_reuse_wait_desc ,如果变成log_backup,就可以尝试下shrink 了
tempdb的空间问题
tempdb是一个非常特殊的db,每次实例启动的时候,都会根据tempdb的默认值大小,重建tempdb文件。所以tempdb的空间问题,都可以通过重启解决。重点在于,找到tempdb的开销来自哪里,从根源上优化。
tempdb的空间,主要分为三块:
1) user objects
2) internal objects
3) versioning objects
想要看下当前tempdb的大小,可以试下这个语句
Select 'Tempdb' as DB, getdate() as Time,
SUM (user_object_reserved_page_count)*8 as user_objects_kb,
SUM (internal_object_reserved_page_count)*8 as internal_objects_kb,
SUM (version_store_reserved_page_count)*8 as version_store_kb,
SUM (unallocated_extent_page_count)*8 as freespace_kb
From sys.dm_db_file_space_usage
Where database_id = 2
这个命令可以查看到当前tempdb的空间开销
如果是user objects占用多,就要考虑下是否使用了大量的临时表,表变量等自建对象。
如果是 internal objects占用多,就要去检查自己的排序内存,hash内存是否不够
如果是versioning 占用多,就要去检查自己是否打开了versioning相关的设置,这个并发程度是否是预期内的。
如果是freespace 最大,就说明问题已经发生过了,需要定期抓取这个数据,等待问题重现来判断是上述三个中的哪一个导致的。
关于versioning可以查询下这里:
select is_read_committed_snapshot_on,snapshot_isolation_state_desc,*
from sys.databases 
以上就是本期的全部内容,如果有任何疑问,可以在下方留言。