Redis 核心技术与实战-实践篇读书笔记 20~终结
文章目录
- 20 | 删除数据后,为什么内存占用率还是很高?
-
- 如何判断是否有内存碎片?
- 如何清理内存碎片呐?
- 21 | 缓冲区:一个可能引发“惨案”的地方(暂略)
- 23 | 旁路缓存:Redis 是如何工作的?
-
- 只读缓存与读写缓存
- 24 | 替换策略:缓存满了怎么办?(即内存淘汰策略)
-
- 如何处理被淘汰的数据?
- 25 | 缓存异常(上):如何解决缓存和数据库的数据不一致问题?
-
- 只读缓存
-
- 不一致的几种情况及解决方法
- 读写缓存
-
- 同步直写时不一致的几种情况及解决方法
- 如何解决数据不一致问题?
-
- 先操作 缓存,后操作 数据库
-
- 解决:缓存延时双删
- 先操作 数据库,后操作 缓存
- 总结
- 26 | 缓存异常(下):如何解决缓存雪崩、击穿、穿透难题?
- 27 | 缓存被污染了,该怎么办?
- 29 | 无锁的原子操作:Redis如何应对并发访问?
-
- 如何解决?(两种方式)
- 30 | 如何使用Redis实现分布式锁?
-
- 基于单个 Redis 节点实现分布式锁
-
-
- 使用 SETNX 和 DEL 时存在的两个风险
-
- 基于多个 Redis 节点实现高可靠的分布式锁
- 31 | 事务机制:Redis能实现ACID属性吗?(暂略)
- 32 | Redis主从同步与故障切换,有哪些坑?(暂略)
- 33 | 脑裂:一次奇怪的数据丢失
-
- 如何解决?
- 36 | Redis 支撑秒杀场景的关键技术和实践都有哪些?
- 37 | 数据分布优化:如何应对数据倾斜?
-
- 数据量倾斜的成因和应对方法
- 数据访问倾斜的成因和应对方法
- 39 | Redis 6.0的新特性:多线程、客户端缓存与安全
20 | 删除数据后,为什么内存占用率还是很高?
主要原因:内存碎片引起的
内存碎片的产生主要是:(1)分配机制 (2)键值对大小不一样和删改操作
如何判断是否有内存碎片?
看 INFO memory 命令中的 mem_fragmentation_ratio Redis 当前的内存碎片率指标。 mem_fragmentation_ratio 大于 1 但小于 1.5。这种情况是合理的。而大于 1.5 后则认为不是合理的范畴。
如何清理内存碎片呐?
启动碎片清理即可。
config set activedefrag yes
这个命令只是启用了自动清理功能,但是,具体什么时候清理,会受到下面这两个参数的控制。这两个参数分别设置了触发内存清理的一个条件,如果同时满足这两个条件,就开始清理。在清理的过程中,只要有一个条件不满足了,就停止自动清理。

21 | 缓冲区:一个可能引发“惨案”的地方(暂略)
23 | 旁路缓存:Redis 是如何工作的?
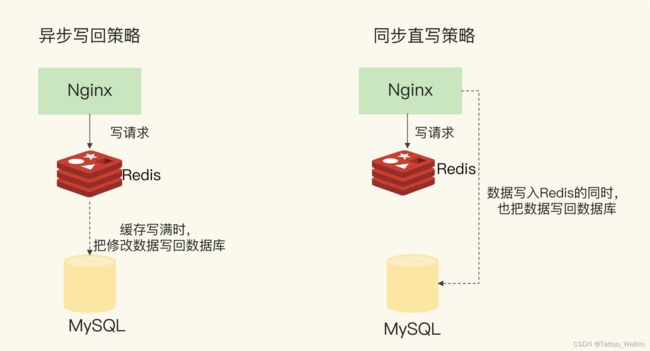
只读缓存与读写缓存
- 只读缓存:缓存只处理读,所有的写请求,会直接发往后端的数据库,在数据库中增删改。对于删改的数据来说,如果 Redis 已经缓存了相应的数据,应用 需要把这些缓存的数据删除 ,Redis 中就没有这些数据了。当应用再次读取这些数据时,会发生缓存缺失,应用会把这些数据从数据库中读出来,并写到缓存中。这样一来,这些数据后续再被读取时,就可以直接从缓存中获取了,能起到加速访问的效果。
- 读写缓存:缓存会被写。写的策略有两种,如图:
24 | 替换策略:缓存满了怎么办?(即内存淘汰策略)
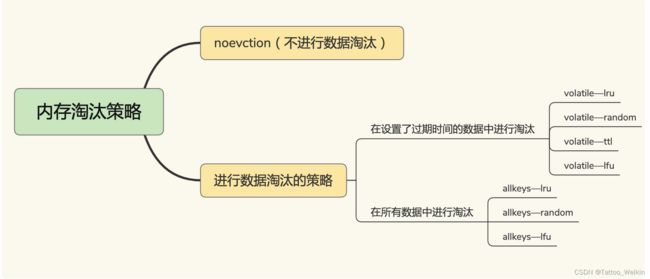
具体在使用上有什么经验呐?
- 优先使用 allkeys-lru 策略。这样,可以充分利用 LRU 这一经典缓存算法的优势,把最近最常访问的数据留在缓存中,提升应用的访问性能。如果你的业务数据中有明显的冷热数据区分,我建议你使用 allkeys-lru 策略。
- 如果业务应用中的数据访问频率相差不大,没有明显的冷热数据区分,建议使用 allkeys-random 策略,随机选择淘汰的数据就行。
- 如果你的业务中有置顶的需求,比如置顶新闻、置顶视频,那么,可以使用 volatile-lru 策略,同时不给这些置顶数据设置过期时间。这样一来,这些需要置顶的数据一直不会被删除,而其他数据会在过期时根据 LRU 规则进行筛选。
如何处理被淘汰的数据?
一旦被淘汰的数据选定后,如果这个数据是没被修改过数据,那么我们就直接删除;如果这个数据被修改过,我们需要把它写回数据库。
25 | 缓存异常(上):如何解决缓存和数据库的数据不一致问题?
只读缓存
不一致的几种情况及解决方法
首先回忆下只读缓存的处理流程:
- 增删改 请求先到达数据库进行处理
- 针对 删改 操作需要单独删除缓存中已缓存的数据
针对上述情况还是会出现 两者操作上的不一致性,那么就还是需要保证同时更新缓存和数据库。
读写缓存
同步直写时不一致的几种情况及解决方法
同步直写需要保证同时更新缓存和数据库。所以,我们要在业务应用中使用事务机制,来保证缓存和数据库的更新具有原子性,也就是说,两者要不一起更新,要不都不更新,返回错误信息,进行重试。否则,我们就无法实现同步直写。
如何解决数据不一致问题?
因为是 保证同时更新缓存和数据库。所以总的排列组合只有两种。
(1)先 操作 缓存 , 后操作 数据库
(2)先 操作 数据库 ,后操作 缓存
先操作 缓存,后操作 数据库
可能会出现的异常情况是:
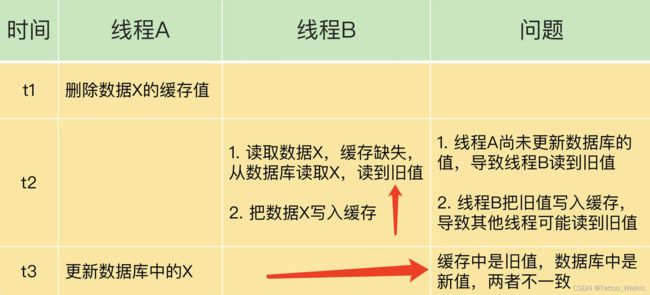
解决:缓存延时双删
在线程 A 更新完数据库值以后,我们可以让它先 sleep 一小段时间,再进行一次缓存删除操作。
先操作 数据库,后操作 缓存
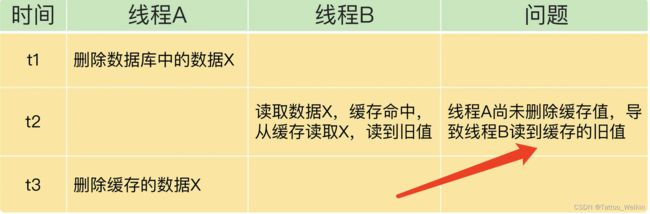
此类问题,一般影响不大,可以忽略~,后续工作中遇到了再说。
总结
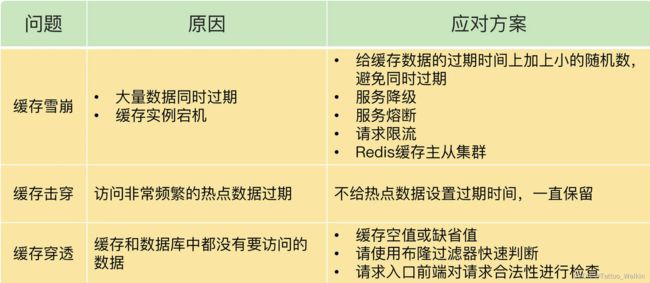
26 | 缓存异常(下):如何解决缓存雪崩、击穿、穿透难题?
27 | 缓存被污染了,该怎么办?
29 | 无锁的原子操作:Redis如何应对并发访问?
客户端对数据的修改操作步骤主要有:
- 客户端先把数据读取到本地
- 在本地进行修改;
- 再写回 Redis
把这个流程叫做“读取 - 修改 - 写回”操作(Read-Modify-Write,简称为 RMW 操作)。当有多个客户端对同一份数据执行 RMW 操作的话,我们就需要让 RMW 操作涉及的代码以原子性方式执行。访问同一份数据的 RMW 操作代码,就叫做临界区代码。
如何解决?(两种方式)
- 原子操作命令 INCR 和 DECR
- Lua 脚本
30 | 如何使用Redis实现分布式锁?
基于单个 Redis 节点实现分布式锁
其实就是在 Redis 中保存一个 key:value 就行了。
加锁包含了三个操作(读取锁变量、判断锁变量值以及把锁变量值设置为 1),而这三个操作在执行时需要保证原子性。那怎么保证原子性呢?
原子性有两种实现方式:
- 单命令实现
- 使用 Lua 脚本
在这里可以直接使用 SETNX 和 DEL 命令组合来实现加锁和释放锁操作
- SETNX:在执行时会判断键值对是否存在,如果不存在,就设置键值对的值,如果存在,就不做任何设置。
- DEL:删除锁变量
那么这样做会存在什么问题呐?
使用 SETNX 和 DEL 时存在的两个风险
- 假如某个客户端在执行了 SETNX 命令、加锁之后,紧接着却在操作共享数据时发生了异常,结果一直没有执行最后的 DEL 命令释放锁。因此,锁就一直被这个客户端持有,其它客户端无法拿到锁,也无法访问共享数据和执行后续操作,这会给业务应用带来影响。
针对这个问题,一个有效的解决方法是,给锁变量设置一个过期时间。这样一来,即使持有锁的客户端发生了异常,无法主动地释放锁,Redis 也会根据锁变量的过期时间,在锁变量过期后,把它删除。其它客户端在锁变量过期后,就可以重新请求加锁,这就不会出现无法加锁的问题了。
- 假设客户端 A 执行完 SETNX 命令成功加锁,并且给锁设置了超时时间 10s,然后开始执行业务逻辑,但是由于其他原因导致执行业务逻辑时间超出了 10s ,锁自动释放了,注意客户端 A 的业务逻辑仍然在执行中,此时客户端 B 成功加锁并且设置锁超时时间,而后开始执行业务逻辑,但是在客户端 B 执行业务逻辑期间,客户端 A 执行完毕,然后开始调用 DEL 指令释放锁,这就有可能导致将客户端 B 加的锁释放掉。
本质上来讲,其实就是要能区分来自不同客户端的锁操作。
SETNX 命令,对于不存在的键值对,它会先创建再设置值(也就是“不存在即设置”),为了能达到和 SETNX 命令一样的效果,Redis 给 SET 命令提供了类似的选项 NX,用来实现“不存在即设置”。如果使用了 NX 选项,SET 命令只有在键值对不存在时,才会进行设置,否则不做赋值操作。此外,SET 命令在执行时还可以带上 EX 或 PX 选项,用来设置键值对的过期时间。
举个例子,执行下面的命令时,只有 key 不存在时,SET 才会创建 key,并对 key 进行赋值。另外,key 的存活时间由 seconds 或者 milliseconds 选项值来决定。
SET key value [EX seconds | PX milliseconds] [NX]
因此,加锁操作可以:
// 加锁, unique_value作为客户端唯一性的标识
SET lock_key unique_value NX PX 10000
解锁操作可以:
// KEYS[1]表示 lock_key,ARGV[1]是当前客户端的唯一标识,
// 这两个值都是我们在执行 Lua 脚本时作为参数传入的。
//释放锁 比较 unique_value 是否相等,避免误释放
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end
因为,释放锁操作的逻辑也包含了读取锁变量、判断值、删除锁变量的多个操作。所以需要使用 Lua 脚本(unlock.script)实现的释放锁操作的伪代码。
redis-cli --eval unlock.script lock_key , unique_value
基于多个 Redis 节点实现高可靠的分布式锁
为了避免 Redis 实例故障而导致的锁无法工作的问题,Redis 的开发者 Antirez 提出了分布式锁算法 Redlock。
Redlock 算法的基本思路,是让客户端和多个独立的 Redis 实例依次请求加锁,如果客户端能够和半数以上的实例成功地完成加锁操作,那么我们就认为,客户端成功地获得分布式锁了,否则加锁失败。这样一来,即使有单个 Redis 实例发生故障,因为锁变量在其它实例上也有保存,所以,客户端仍然可以正常地进行锁操作,锁变量并不会丢失。
分为三步:
- 客户端获取当前时间。
- 客户端按顺序依次向 N 个 Redis 实例执行加锁操作。
- 一旦客户端完成了和所有 Redis 实例的加锁操作,客户端就要计算整个加锁过程的总耗时。

31 | 事务机制:Redis能实现ACID属性吗?(暂略)
32 | Redis主从同步与故障切换,有哪些坑?(暂略)
33 | 脑裂:一次奇怪的数据丢失
所谓的脑裂,就是指在主从集群中,同时有两个主节点,它们都能接收写请求。而脑裂最直接的影响,就是客户端不知道应该往哪个主节点写入数据,结果就是不同的客户端会往不同的主节点上写入数据。而且,严重的话,脑裂会进一步导致数据丢失。
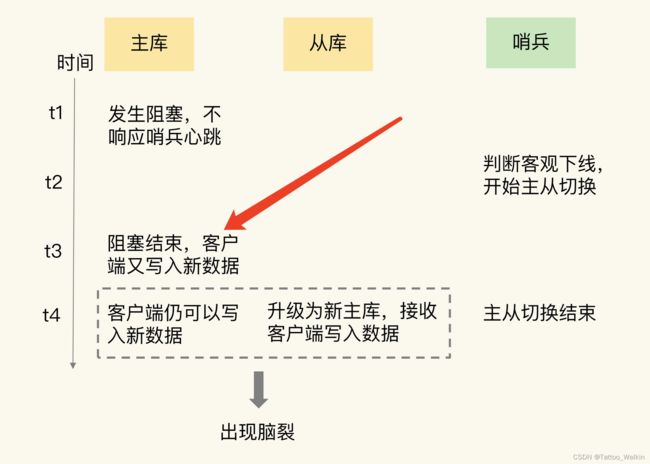
那么为什么脑裂会导致数据丢失呐?
主从切换后,从库一旦升级为新主库,哨兵就会让原主库执行 slave of 命令,和新主库重新进行全量同步。而在 全量同步 执行的最后阶段,原主库需要清空本地的数据,加载新主库发送的 RDB 文件,这样一来,原主库在主从切换期间保存的新写数据就丢失了。
所以原主库会丢失切换期间保存的数据!
如何解决?
既然问题是出在原主库发生假故障后仍然能接收请求上,我们就开始在主从集群机制的配置项中查找是否有限制主库接收请求的设置。
通过查找,我们发现,Redis 已经提供了两个配置项来限制主库的请求处理,分别是 min-slaves-to-write 和 min-slaves-max-lag。
- min-slaves-to-write:这个配置项设置了主库能进行数据同步的最少从库数量;
- min-slaves-max-lag:这个配置项设置了主从库间进行数据复制时,从库给主库发送 ACK 消息的最大延迟(以秒为单位)。

设置的建议:假设从库有 K 个,可以将 min-slaves-to-write 设置为 K/2+1(如果 K 等于 1,就设为 1),将 min-slaves-max-lag 设置为十几秒(例如 10~20s),在这个配置下,如果有一半以上的从库和主库进行的 ACK 消息延迟超过十几秒,我们就禁止主库接收客户端写请求。
36 | Redis 支撑秒杀场景的关键技术和实践都有哪些?
- 秒杀前:用户会不断刷新商品详情页。把商品详情页的页面元素静态化,然后使用 CDN 或是浏览器把这些静态化的元素缓存起来。
- 秒杀中:用户点击商品详情页上的秒杀按钮,所以具体的操作就是:库存查验、库存扣减和订单处理,这个时候的压力全都在 库存查验 操作上,因此这里就 需要 Redis 来提升性能。
订单处理可以在数据库中执行,但库存扣减操作,不能交给后端数据库处理。当库存查验完成后,一旦库存有余量,我们就立即在 Redis 中扣减库存。而且,为了避免请求查询到旧的库存值,库存查验和库存扣减这两个操作需要保证原子性。
- 秒杀后:在这个阶段,可能还会有部分用户刷新商品详情页,尝试等待有其他用户退单。而已经成功下单的用户会刷新订单详情,跟踪订单的进展。不过,这个阶段中的用户请求量已经下降很多了,服务器端一般都能支撑,直接忽略即可。
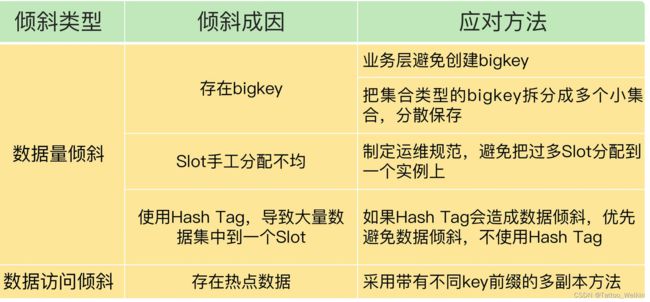
37 | 数据分布优化:如何应对数据倾斜?
数据倾斜有两类。
- 数据量倾斜:在某些情况下,实例上的数据分布不均衡,某个实例上的数据特别多。
- 数据访问倾斜:虽然每个集群实例上的数据量相差不大,但是某个实例上的数据是热点数据,被访问得非常频繁。
数据量倾斜的成因和应对方法
- bigkey 导致倾斜:我们在业务层生成数据时,要尽量避免把过多的数据保存在同一个键值对中。此外,如果 bigkey 正好是集合类型,我们还有一个方法,就是把 bigkey 拆分成很多个小的集合类型数据,分散保存在不同的实例上。
- Slot 分配不均衡导致倾斜:迁移 slot
- Hash Tag 导致倾斜:(@TODO 暂时忽略)
数据访问倾斜的成因和应对方法
- 通常来说,热点数据以服务读操作为主,在这种情况下,我们可以采用热点数据多副本的方法来应对。
这个方法的具体做法是,我们把热点数据复制多份,在每一个数据副本的 key 中增加一个随机前缀,让它和其它副本数据不会被映射到同一个 Slot 中。这样一来,热点数据既有多个副本可以同时服务请求,同时,这些副本数据的 key 又不一样,会被映射到不同的 Slot 中。在给这些 Slot 分配实例时,我们也要注意把它们分配到不同的实例上,那么,热点数据的访问压力就被分散到不同的实例上了。