由本溯源,带你探索BI实时性的本质
BI 采用T+1模式
BI的数据仓库架构本身就决定了对数据的实时性要求没有那么高,ETL的过程不可或缺,Extraction 抽取、Transformation 转换、Loading 加载,这三个环节本身就是有时间损耗的。

BI - 派可数据BI可视化分析平台
首先,Extraction抽取,这些业务数据要使用SQL或者ETL工具从业务数据库查询并通过网络传输加载到BI数据仓库,视数据量的大小这个查询和加载会花费一定的时间,比如五分钟、十分钟甚至更长。这只是其中的一个查询,所有查询和加载全部执行完短则几分钟,长则小时算很正常。
第二,数据加载到BI数据仓库中了,数据要被加工处理,比如去重、合并、循环计算等等算出各种指标放到数据仓库不同的层里面,这个数据处理的过程在BI里是最耗时间的,几十分钟到几个小时。指标越多,业务逻辑越复杂,计算处理花的时间越长。 这个就是ETL处理的核心,Transformation 转换。
第三,Transformation 转换处理后的数据要写入到目标表比如BI中维度表、事实表里面,即Loading 加载。
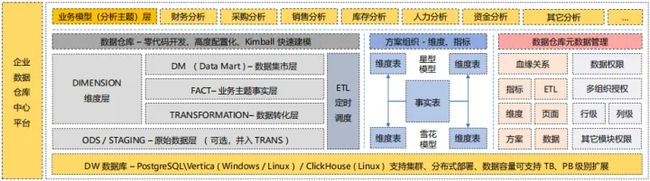
数据仓库 - 派可数据BI可视化分析平台
ETL是BI数据仓库的数据处理关键,其中E是数据源头,T是中间数据计算处理的过程,L是将计算结果写入、加载到目标表。
并且很多时候白天业务系统有人可能会用的比较晚,有些数据业务部门更新的时间也比较晚。所以大部分情况下,BI都会选择在晚上12点以后执行ETL的调度从业务数据源将12点以前的所有已更新的数据同步过来处理。
所以,通常BI在晚上先把前两个阶段的事情给处理了,所有的数据都抽取、加工、计算完了,都提前存放在数据仓库里。第二天页面在刷新的时候直接访问的是已经计算好的数据仓库的数据,这样就很快了。
数据可视化 - 派可数据BI可视化分析平台
BI数据仓库ETL架构
一般的 BI 数据仓库 ETL 架构是这么来设计的,分成四个 ETL 包、或者五个 ETL 包,每个包就是数据仓库的一个分层的 ETL 合集。

BI数据仓库 - 派可数据BI可视化分析平台
第一个包是 ODS 或者 Staging 层,里面包含了所有的从业务系统数据源抽取源表到 ODS 层的ETL 处理过程。
第二个包要优先处理所有的维度 Dimension Table。
第三个包就开始处理标准的事实层 Fact Tables。
第四个包处理Data Mart 数据集市层。
第五个包处理OLAP CUBE 等等。
这几个包是由严格的依赖关系顺序的,是串行的。也就是说第一个包没有处理完,第二个包是不能执行的;第二个包没有执行完,第三个包也是不会启动的。
我上面讲到的 BI 数据仓库 ETL架构是非常标准的分层架构设计,这五个包通常会放到比如Windows定时任务JOB里面去做定时调度,比如每天晚上执行一次。
BI数据仓库ETL架构问题
但这里面就有这么个问题,某些指标想做准实时就不能按照上面的BI数据仓库ETL架构来设计,就需要把这几个指标单独拎出来,把这几个指标的上下游依赖的ODS层、维度层、事实层的指标单独打包来处理,然后在JOB里面单独做定时调度。一个指标一个JOB,十个指标就是十个JOB。这样这些指标的执行就不依赖于原有的整体ETL架构,可以单独跑,这是第一个点。
数据可视化 - 派可数据BI可视化分析平台
第二个点就是,这个JOB定时执行的任务时间间隔要大于这个JOB的执行最长时间。比如这个JOB一般执行一分钟,那设置BI定时调度的时间间隔最好就是两分钟或以上。什么意思呢,这个指标整个流程还没有计算完,下个定时任务启动了,上次执行正好把数据写入完成了,这次任务就把数据给清空了,这样就乱套了。
所以,针对这个问题要额外进行一些BI数据仓库ETL日志框架的开发和改造,让每次ETL执行时去检查一下日志,上次没有执行完成这次就先不启动,等待上次执行完毕之后再启动就不会出现冲突了。
BI数据仓库ETL架构改造
这些我们之前在一些大型的项目上并行跑上百个包就是通过对BI数据仓库ETL框架的改造来完成数据指标的准实时实现,当然这个BI准实时要取决于指标自身的计算时间周期和过程。
所以,我们会大量的使用增量抽取,包括对BI中数据表索引、查询性能的优化。
数据可视化大屏 - 派可数据BI可视化分析平台
以往是串行的从下往上执行每个包,一个包的调度等到之前的包的调度执行完毕再执行。现在相当于把需要做实时或者准实时的BI指标从原来的包中分离出来单独的来维护组成一个新的串行,这种BI数据仓库ETL架构的设计方式跟以往传统的数据仓库ETL架构就有很大的区别了。
我们现在在我们自己BI产品的ETL调度就是按指标为线性的方式来实现的,每个指标可以独立的进行抽取调度,并且全部都是配置化的。这种BI中ETL调度的方式也是为实时性数据仓库、实时性BI打下了基础。
BI的实时要求
通常在BI项目里面,大部分的分析指标、数据是不要求做到实时的,特别是像企业的经营管理分析、财务分析等等。这些数据在BI项目中的准确性要求远远大于时效性,所以此类数据隔天看基本上是足以满足企业大部分的业务分析场景的。
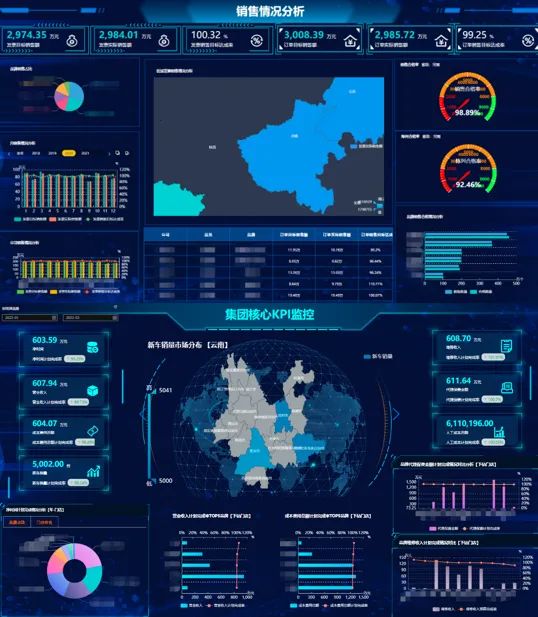
数据可视化大屏 - 派可数据BI可视化分析平台
但在BI项目里面也有一些例外,比如像实时预警类的、监控类的一些数据指标,对这种数据的实时性要求就会比较高一些,数据延迟时间不能太长,要求达到秒级、分钟级以内,这类数据就需要进行BI实时处理。这两种不同形态的数据处理方式是不一样的。
BI离线数据处理
在以往的BI项目中,离线数据量不大的时候,比如TB级别以下,传统的数据仓库ETL架构大部分场景都可以满足。数据量大的时候比如TB、PB级别或以上的数据处理,底层就可以采用Hadoop分布式系统框架,通过集群的方式进行高速运算和存储。最底层的HDFS分布式文件系统存储数据,MapReduce分布式计算框架对数据进行计算处理。

数据仓库 - 派可数据BI可视化分析平台
Hadoop的数据仓库Hive通过HiveSQL就是HSQL转换成MapReduce作业任务执行数据查询。Hive清洗处理后的结果如果是面向海量数据随机查询的场景还可以存入HBase Hadoop Database中。
HBase 是真正的数据库,NoSQL数据库,目的主要是为了支持和弥补Hadoop对实时数据操作的瓶颈。Hive就是一个壳,但它简化了Hadoop的复杂性,不需要学JAVA就可以通过SQL操作MapReduce去访问HDFS,即通过SQL语句像操作关系数据库一样操作HDFS系统中的目录和文件。
上面讲到的就是传统的数据仓库模式下的离线数据处理和大数据架构下的离线数据处理,那么我们再来说下大数据技术下的实时数据仓库的数据处理架构。
BI实时数据处理
我们之前也研究过很多不同的框架,比如早期的Lambda架构,通过Kafaka、Flume组件对底层数据源数据进行收集,然后分两条线进行处理,一条处理实时数据指标,一条处理T+1数据。

数据可视化大屏 - 派可数据BI可视化分析平台
实时数据指标的计算主要是进入到流式计算平台,像Storm、Flink或者SparkStreaming;非实时的、大批量的数据就进入到批数据离线计算平台,就是前面提到的Hadoop、Mapreduce、Hive 数据仓库去处理非实时性的T+1的指标。这样的一种架构兼顾了小批量的实时性数据和大批量的非实时性数据处理,但运维成本很高,因为是两套分布式系统,维护的工作量很大。
把Lambda架构做简化,去掉了离线批处理部分,就是Kappa架构,数据以流的方式被采集,就只关心流式计算。因为现在的Kafaka是可以支持数据持久化的,可以保存更长时间的历史数据,代替了Lambda架构中离线批处理的部分。但对于历史数据吞吐能力就会有所限制,只能通过增加计算资源来解决。包括数据的容错性,对有些场景也并不非常适合Kappa架构。
我们目前在一些项目上采用的数据实时处理架构,比如使用数据库binlog日志,或者其它非关系型数据库产生的流式数据发送到Kafaka或者Flink-CDC,再通过Flink流处理引擎创建表映射、注册表,然后通过Flink引擎提供的FlinkSQL相关接口实现数据流式处理,最终将变化的数据实时写入到BI数据仓库供前端可视化做实时展现和分析。
BI业务场景需求
除了我上面提到的一些技术解决方案之外,大家在网上也可以看到各种各样的大数据实时处理框架或者解决方案的介绍。就会发现虽然大家都是在讲同一件事,但是实现方式和路径、采用的技术框架各不相同,为什么?因为具体要解决的业务场景不一样。
数据可视化大屏 - 派可数据BI可视化分析平台
比如有些BI项目可能就不是一个BI分析需求,就是一个大屏的实时数据展现,但用户一看大屏可视化,就会认为这个不就是BI嘛,拿BI来做。
但实际上 ,这样理解是有问题的,可视化就一定是BI吗?WEB前端直接开发行不行,是完全可以的。底层使用Flume+Kafaka+Flink+Redis 架构,再找个前端开发就可以设计大屏的实时数据刷新了,跟BI有什么关系,并没有关系。
BI的强项不是去做可视化实时数据展现的,BI的强项是多系统打通、数据仓库建模以及对历史数据的多维分析、钻透、关联等分析路径的实现。
不同的行业、不同的分析型项目数据源各不相同。业务分析场景、数据场景众多,很难用某一种技术框架解决所有的问题。要考虑兼顾数据的时效性,又要考虑兼顾数据的准确性,还有考虑数据量吞吐和处理能力,以及兼顾随时变化的业务计算规则。这么多的场景和要求,很难通过标准化的技术方案去平衡,只能看具体的业务场景再针对性的提供相应的解决办法。

数据可视化 - 派可数据BI可视化分析平台
大家就比较容易理解为什么BI分析工具不去提供这种实时数据的处理能力,因为这种实时数据处理的场景是非标的,很难标准化去适应各种复杂的业务场景。
即使BI有这个能力,也是基于某些特定场景之下的,一定不会适配所有的场景。所以一般BI都是和这种大数据平台、实时数据处理平台去搭配使用的,针对不同的业务场景设计不同的大数据实时数据处理方案,把数据规范化、标准化、模型化,BI负责只对接到这一层就可以了。
BI实时数据处理总结
不管是离线数据还是实时数据采用什么样的架构都是为了解决特定业务场景下的问题,什么时候采用离线处理、什么时候采用实时处理。除了这些需求的重要性、紧迫度需要评估外,还需要考虑资源的投入。

数据可视化 - 派可数据BI可视化分析平台
企业是用最小的、最经济的资源达成既定的业务目标,而不是为了追求所谓的数据实时而追求实时。做不到实时分析,只做离线就是技术不行、产品不行、能力不行。造子弹跟造原子弹都是造弹,但毕竟还不一样。
数据准实时处理场景
理性一点的朋友就会说了,几秒钟看交易数据、交易金额有什么用啊,几秒钟能进来多少钱啊,根本就没有必要看。确实如此,我也认为没有必要。没有必要的原因可能是因为这个数据不会有太大的变化,如果变化大比如一秒钟增加十几万,十秒钟上百万的交易金额,这个是不是就很有点意思了?我们正好就有这样的客户,几秒钟时间大屏的数据刷一下,交易额就增加了几十万、有时上百万,一年五千个亿往上的交易金额,这个只是其中某一个渠道的交易金额。那这个数据就非常有意思了,很刺激,隔一会那个牌子就跳一下,再算下变了多少万了。
数据可视化 - 派可数据BI可视化分析平台
每次交易金额可能就几百块以内,所以每秒钟交易的笔数累计下来就非常的多,一年下来几十亿条交易数据很正常。如果直接用SQL去查询,有可能页面每10秒钟刷新一次,前一次这个指标的ETL里面的查询都没有执行完,数据还没有填充到数据仓库表,后面的查询就又来了。这种实现方式明显是有问题的,效率比较低。
数据准实时处理思路
那怎么来实现呢?就跟一层窗户纸一样,一捅就破,一讲大家就明白了。
多做几个ETL,第一个ETL每天晚上执行一次,计算从今年开始到今天累计的交易金额,这个值算出来单独存起来。哪怕是全量计算,也不怕,晚上执行,哪怕执行一个小时我也不怕,肯定能算的完。

数据仓库 - 派可数据BI可视化分析平台
第二个ETL每小时执行一次,计算从今天零点到现在当前小时的交易金额,到这个阶段数据查询的范围就变小了,又算一个值存储起来。
第三个ETL每分钟执行一次,计算从当前小时零分到现在这一分钟计算的值,存起来放着。
最后一个ETL每十秒钟执行一次,计算这一分钟里交易金额,又算出一个值更新到一个表里面。同时,这个更新的值和前面三个ETL算出来的值一加起来,不就是全年累计的实时交易金额吗?这个问题就解决掉了。
这个过程实际上就是利用时间日期戳和ETL做了增量抽取更新,以及增量计算,把整个数据表的聚合汇总砍成一节一节的,不同的ETL计算不同的时间段的数据,这样整体数据量会比较小。调度时间间隔大的ETL,执行的数据查询范围就越大。调度间隔小,执行的数据查询范围就越小。
数据可视化 - 派可数据BI可视化分析平台
这种方式大家可以在项目上试一试,是完全可以实现一些准实时效果的。当然,一个指标就用了四个不同的ETL调度。十个指标,理论上就需要四十个。当然按天或者按小时执行的指标视情况可以放到一个ETL调度里,减少一些维护工作量。但总体上来说指标越多,ETL的调度配置就会越多,后期维护成本自然也会比较高一些。