MySQL 主从同步及延迟原因分析
主从同步的基本原理
MySQL主从同步步骤详见 MySQL binlog模式及主备的基本原理
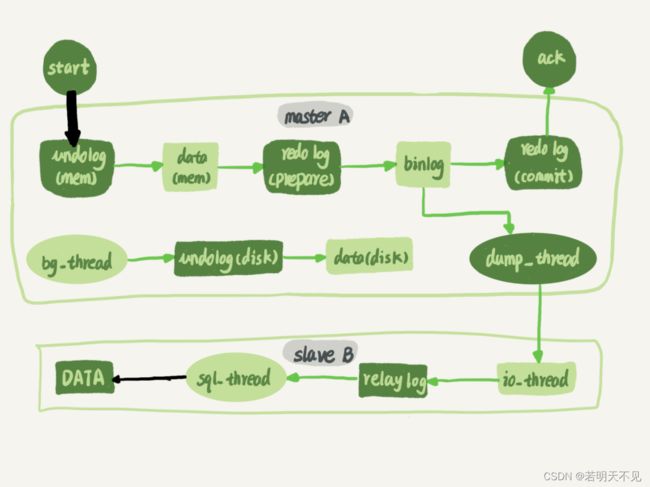
谈到主备的并行复制能力,我们要关注的是图中黑色的两个箭头。一个箭头代表了客户端写入主库,另一箭头代表的是从库上sql_thread执行中转日志(relay log)
如果用箭头的粗细来代表并行度的话,那么真实情况就如图 1 所示,第一个箭头要明显粗于第二个箭头。
在主库上,影响并发度的原因就是各种锁。 由于 InnoDB 引擎支持行锁,除了所有并发事务都在更新同一行(热点行)这种极端场景外,它对业务并发度的支持还是很友好的。所以,你在性能测试的时候会发现,并发压测32个线程就比单线程时,总体吞吐量高
而日志在备库上的执行,就是图中备库上sql_thread更新数据 (DATA) 的逻辑。如果是用单线程的话,就会导致备库应用日志不够快,造成主备延迟。
主从延迟分析
主从延迟原因分析
正常情况下,在排除网络延迟或丢包的情况下,最直接的影响主从延迟就是从库上sql_thread执行中转日志(relay log),而造成原因一般是以下几种:
1. 从库的机器性能比主库要差
比如将20台主库放在4台机器,把从库放在一台机器。这个时候进行更新操作,由于更新时会触发大量读操作,导致从库机器上的多个从库争夺资源,导致主从延迟。
不过,目前大部分部署都是采取主从使用相同规格的机器部署。
2. 从库的压力大
按照正常的策略,读写分离,主库提供写能力,从库提供读能力。将进行大量查询放在从库上,结果导致从库上耗费了大量的CPU资源,进而影响了同步速度,造成主从延迟。
对于这种情况,可以通过一主多从,分担读压力;也可以采取binlog输出到外部系统,比如Hadoop,让外部系统提供查询能力。
3. 大事务的执行
一旦执行大事务,那么主库必须要等到事务完成之后才会写入binlog。
比如主库执行了一条insert … select非常大的插入操作,该操作产生了近几百G的binlog文件传输到只读节点,进而导致了只读节点出现应用binlog延迟。
因此,DBA经常会提醒开发,不要一次性地试用delete语句删除大量数据,尽可能控制数量,分批进行。
4. 主库的DDL(alter、drop、create)
- 只读节点与主库的DDL同步是串行进行,如果DDL操作在主库执行时间很长,那么从库也会消耗同样的时间,比如在主库对一张500W的表添加一个字段耗费了10分钟,那么从节点上也会耗费10分钟。
- 从节点上有一个执行时间非常长的的查询正在执行,那么这个查询会堵塞来自主库的DDL,表被锁,直到查询结束为止,进而导致了从节点的数据延迟。
5. 锁冲突
锁冲突问题也可能导致从节点的SQL线程执行慢,比如从机上有一些select … for update的SQL,或者使用了MyISAM引擎等。
6. 从库的复制能力
一般场景中,因偶然情况导致从库延迟了几分钟,都会在从库恢复之后追上主库。但若是从库执行速度低于主库,且主库持续具有压力,就会导致长时间主从延迟,很有可能就是从库复制能力的问题。
从库上的执行,即sql_thread更新逻辑,在5.6版本之前,是只支持单线程,那么在主库并发高、TPS高时,就会出现较大的主从延迟
因此,MySQL自5.7版本后就已经支持并行复制了。可以在从服务上设置slave_parallel_workers为一个大于0的数,然后把slave_parallel_type参数设置为LOGICAL_CLOCK
SHOW VARIABLES LIKE 'slave_parallel%';
主从延迟影响
-
查询数据不准确
为分担主库压力,业务通常会将一些读的请求发送至从库,但如果主从存在延迟的情况,这时读到的可能就是过期的数据。当然,目前在实际业务架构设计中,也会考虑到主从延迟因素的存在,通过如强制走主库、配合半同步(semi-sync)、sleep等方案优化,避免“过期读”对业务造成的影响。 -
主库宕机,数据丢失
主库宕机后,需要较长的恢复时间,但特别是核心业务系统需要快速恢复的紧急情况下,如果之前存在延迟,强制切换主库,保证业务可用,就会导致部分数据丢失,后期的补偿也将会是件很麻烦的事情。
主从延迟处理方案
主从同步问题永远都是一致性和性能的权衡,得看实际的应用场景,若想要减少主从延迟的时间,可以采取下面的办法:
- 降低多线程大事务并发的概率,优化业务逻辑
- 优化SQL,避免慢SQL,减少批量操作,建议写脚本以update-sleep这样的形式完成
- 提高从库机器的配置,减少主库写binlog和从库读binlog的效率差
- 尽量采用短的链路,也就是主库和从库服务器的距离尽量要短,提升端口带宽,减少binlog传输的网络延时
- 实时性要求的业务读强制走主库,从库只做灾备,备份
并行复制策略
MySQL 5.6 版本前,只支持单线程复制,由此在主库并发高、TPS 高时就会出现严重的主备延迟问题。从单线程复制到最新版本的多线程复制,中间的演化经历了好几个版本
多线程复制机制,都是要把主从流程图中只有一个线程的
sql_thread,拆成多个线程
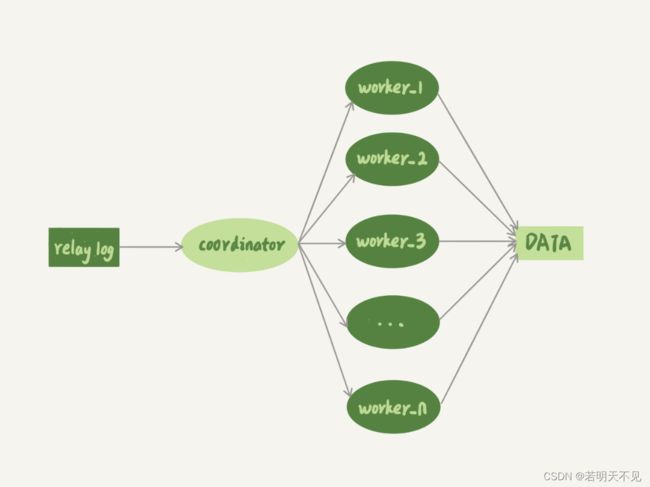
coordinator就是原来的sql_thread, 不过现在它不再直接更新数据了,只负责读取中转日志和分发事务。真正更新日志的,变成了worker线程。而worker线程的个数,就是由参数slave_parallel_workers决定的
coordinator在分发的时候,需要满足以下这两个基本要求:
- 不能造成更新覆盖。这就要求更新同一行的两个事务,必须被分发到同一个
worker中 - 同一个事务不能被拆开,必须放到同一个
worker中
各个版本的多线程复制,都遵循了这两条基本原则
MySQL 5.5 版本
官方 MySQL 5.5 版本是不支持并行复制的。此段并行策略总结自[MySQL 实战 45 讲]
按表分发策略

可以看到,每个 worker 线程对应一个 hash 表,用于保存当前正在这个 worker 的“执行队列”里的事务所涉及的表。hash 表的 key 是“库名. 表名”,value 是一个数字,表示队列中有多少个事务修改这个表
事务在分发的时候,跟所有 worker 的冲突关系包括以下三种情况:
- 如果跟所有 worker 都不冲突,coordinator 线程就会把这个事务分配给最空闲的 woker
- 如果跟多于一个 worker 冲突,coordinator 线程就进入等待状态,直到和这个事务存在冲突关系的 worker 只剩下 1 个
- 如果只跟一个 worker 冲突,coordinator 线程就会把这个事务分配给这个存在冲突关系的 worker
这个按表分发的方案,在多个表负载均匀的场景里应用效果很好。但是,如果碰到热点表,比如所有的更新事务都会涉及到某一个表的时候,所有事务都会被分配到同一个 worker 中,就变成单线程复制了
按行分发策略
要解决热点表的并行复制问题,就需要一个按行并行复制的方案。按行复制的核心思路是:如果两个事务没有更新相同的行,它们在备库上可以并行执行。显然,这个模式要求 binlog 格式必须是 row
基于行的策略,事务 hash 表中还需要考虑唯一键,即 key 应该是“库名 + 表名 + 索引 a 的名字 +a 的值”
对比按表分发和按行分发这两个方案的话,按行分发策略的并行度更高。不过,如果是要操作很多行的大事务的话,按行分发的策略有两个问题:
- 耗费内存。比如一个语句要删除 100 万行数据,这时候 hash 表就要记录 100 万个项
- 耗费 CPU。解析 binlog,然后计算 hash 值,对于大事务,这个成本还是很高的
MySQL 5.6 版本
官方 MySQL5.6 版本,支持了并行复制,只是支持的粒度是按库并行。
理解了上面介绍的按表分发策略和按行分发策略,你就理解了,用于决定分发策略的 hash 表里,key 就是数据库名。
这个策略的并行效果,取决于压力模型。如果在主库上有多个 DB,并且各个 DB 的压力均衡,使用这个策略的效果会很好。
相比于按表和按行分发,这个策略有两个优势:
- 构造 hash 值的时候很快,只需要库名;而且一个实例上 DB 数也不会很多,不会出现需要构造 100 万个项这种情况。
- 不要求 binlog 的格式。因为 statement 格式的 binlog 也可以很容易拿到库名
理论上你可以创建不同的 DB,把相同热度的表均匀分到这些不同的 DB 中,强行使用这个策略。不过由于需要特地移动数据,这个策略应使用得并不多
MySQL 5.7 版本
MySQL5.7 版本也提供了“模拟主库的并行模式”的功能,由参数 slave-parallel-type 来控制并行复制策略:
并行复制策略是通过在主库上将数据分成多个“组”(group)并在从库上并行重放这些组来实现的。每个组包含一组有序的事务,它们可以独立地在从库上重放,而不会与其他组冲突

只要能够到达 redo log prepare 阶段,就表示事务已经通过锁冲突的检验了,也就表示这些食事务可以并行处理了
MySQL 5.7 并行复制策略的思想是:
- 同时处于
prepare状态的事务,在备库执行时是可以并行的 - 处于
prepare状态的事务,与处于commit状态的事务之间,在备库执行时也是可以并行的
在 MySQL 5.7 的并行复制策略里,通过调整参数以拉长
binlog从write到sync的时间,以此减少binlog的写盘次数,以此来制造更多的“同时处于prepare阶段的事务”。这样就增加了备库复制的并行度
在MySQL 5.7中,可以通过配置参数来控制并行复制的行为。以下是一些与并行复制有关的参数:
| 参数 | 作用 |
|---|---|
| slave_parallel_workers | 指定从库上并行执行复制的线程数 |
| slave_parallel_type | 指定并行复制的类型,可以是LOGICAL_CLOCK或DATABASE |
| log_slave_updates | 指定是否在主库上记录从库执行的更新操作,以便在从库上进行并行复制 |
| binlog_group_commit_sync_delay | 指定在主库上等待多长时间来组合多个事务并将它们写入binlog文件 |
| binlog_group_commit_sync_no_delay_count | 指定在等待时间之前,可以在binlog组合提交中组合的最大事务数 |
MySQL 5.7.22 版本
MySQL 5.7.22 版本里,MySQL 增加了一个新的并行复制策略,基于WRITESET的并行复制。
相应地,新增了一个参数 binlog-transaction-dependency-tracking,用来控制是否启用这个新策略。这个参数的可选值有以下三种。
COMMIT_ORDER:表示的就是前面介绍的,根据同时进入prepare和commit来判断是否可以并行的策略WRITESET:表示的是对于事务涉及更新的每一行,计算出这一行的 hash 值,组成集合writeset。如果两个事务没有操作相同的行,也就是说它们的writeset没有交集,就可以并行WRITESET_SESSION:是在WRITESET的基础上多了一个约束,即在主库上同一个线程先后执行的两个事务,在备库执行的时候,要保证相同的先后顺序
对比前面介绍的基于 MySQL 5.5 版本的按行分发的策略是差不多的。不过,MySQL 官方的这个实现还是有很大的优势:
- writeset 是在主库生成后直接写入到 binlog 里面的,这样在备库执行的时候,不需要解析 binlog 内容(event 里的行数据),节省了很多计算量
- 不需要把整个事务的 binlog 都扫一遍才能决定分发到哪个 worker,更省内存
- 由于备库的分发策略不依赖于 binlog 内容,所以 binlog 是 statement 格式也是可以的
对于“表上没主键”和“外键约束”的场景,
WRITESET策略也是没法并行的,也会暂时退化为单线程模型
参考资料:
- MySQL binlog模式及主备的基本原理
- MySQL 实战 45 讲
- 加了个字段导致数据库主从延迟,卧槽,疯狂告警
- MySQL 常见主从延迟原因分析