聚焦弹性问题,杭州铭师堂的 Serverless 之路
作者:王彬、朱磊、史明伟
得益于互联网的发展,知识的传播有了新的载体,使用在线学习平台的学生规模逐年增长,越来越多学生在线上获取和使用学习资源,其中教育科技企业是比较独特的存在,他们担当的不仅仅是教育者的角色,更是让新技术的创新者和实践者。作为一家在线教育高科技企业,杭州铭师堂成立十余年来一致致力于用“互联网+教育”的科技手段让更多的学生能享有优质的教育,促进他们的全面成长,在不断汇聚优质的全国各地教育资源的同时,杭州铭师堂深度聚焦教学效率的提升,深耕先进技术,促进其在学校教育智能化领域、个性化学习领域广泛应用。
目前网上教学需求的常态化,教师在线审阅作业需求量急剧增大,为了减轻老师的审批工作量,提升教学效率,杭州铭师堂教育基于 Serverless 创造性的开发了学习笔记评优系统, 提升弹性效率,并大幅度降低成本。
01 峰值流量破万后,如何更好处理任务处理的实时性问题?
杭州铭师堂业务涵盖全国 20 多个省份,成立十余年来,杭州铭师堂不断汇聚优质的全国各地教育资源,并展开先进科学技术在学校教育智能化领域、个性化学习领域的应用研究。在教育信息化 2.0 趋势下,公司致力于促进线上教育与线下教育的高度融合,以学校为核心场景,与学校携手共建互联网学习空间,为学校与学生提供学习解决方案,极大促进教学效率的提升。
K8s+ 消息,系统难以处理数据并行度问题
学生做完作业后,会将作业拍照,然后上传到作业批阅系统,后端系统此时会有多个动作:
-
将作业照片上传到 OSS
-
将用户作业信息落到数据库
-
发送一条消息到阿里云消息队列 Kafka
其中第 3 步发送消息到阿里云消息队列 Kafka 后,通过消息队列 Kafka 的 connector 功能,驱动函数计算(简称 FC) 进行数据处理。函数计算作为业务的计算平台,承载了所有的处理逻辑,通过图像识别和数据分类算法,自动识别作业的完成情况。
在一年的大多数时间里,业务流量都比较平稳,但在寒暑假时,一般会迎来一年中的高峰,在过去的 2022 年暑假期间,平均每天需要处理 100 多万的作业图片处理,峰值流量更是达到了万级别。
作业图片的处理程序原先部署在 Kubernetes(简称 K8s),程序通过订阅 Kafka 的 topic,获取数据路径,从 OSS 获取数据进行处理,这一部分涉及到数据并行度的处理,主要存在两方面问题:
-
Kafka 的消费端并发度受限于 topic 的 partition,消费端个数最多只能跟 partition 数齐平,消费端数量超过 Kafka topic partition 数会导致超过 partition 数目的消费端没法订阅数据,也就没有实际的意义;
-
每个消费端消费到数据之后会将数据发到处理线程处理,处理线程在最好的情况下是可以根据业务流量动态调整,当然更多的线程就需要更多的资源,这又涉及到任务资源的水平扩容和垂直扩容问题。实际实现时杭州铭师堂消费端个数与 topic partition 保持一致,消费线程数经过调优之后保持了固定数量,在绝大多数时间里,程序能够很好的满足数据处理的的实时性要求,但对于高峰期,由于处理能力的限制,还是会经常出现任务积压的情况。
为了能够更好的实现任务处理的实时性要求,杭州铭师堂架构组寻求新的架构,经过对云产品的对比之后,最终选择了阿里云函数计算 FC。
02 兼顾弹性和成本,选定函数计算新方案
通过基于函数计算的新方案,很好的解决了老架构存在的问题,同时,开发迭代速度,运维效率和成本都得到了很大的优化,新老方案对比如下:

通过以上对比可以看出,函数计算对于杭州铭师堂学习笔记评优系统还是非常合适,在解决弹性痛点的同时,资源成本,开发运维效率都得到了一定的提升。
03 杭州铭师堂的 Serverless 落地之路
在技术架构的实施过程中,最初也遇到了一点问题:
Java 冷启动的问题:第一个问题是语言的问题,原来的后端程序采用 Java 微服务框架,整个服务中有多个接口,刚开始直接将整个服务部署到函数计算。由于 Java 程序启动的特性,加上整个服务框架加载的模块和数据较多,导致冷启动时间比较长,触发冷启动时没法很好的满足业务接口响应要求。
对于这个问题,杭州铭师堂开发同学主要做了两个迭代,首先将代码粒度拆细,在函数计算平台部署真正的处理代码,第二步,将 Java 语言的代码替换成 TypeScript。替换成 TypeScript 一是因为开发同学比较熟悉 TypeScript,二是因为 Node.js 启动速度很快。通过这两次迭代,使得函数的弹性效率大大提升,冷启动的情况下也能够达到 50ms 内完成单次请求。
资源利用率问题:第二个问题是资源的利用率,由于把函数逻辑拆分很细,单个请求对 CPU 和 Memory 的需求都很小,微了提高利用率,选择开启函数计算的单实例多并发,通过 PTS 的压测,在并发度和资源上的到了很好的平衡,资源利用率高达 70%+。
超出预期的惊喜:执行时间快和弹性效率高
通过解决这两个问题,整体开发流程顺利,项目上线后也达到不错的效果,在一些小的方面还有超出预期的表现,主要惊喜来自于执行时间快和弹性效率高。
执行时间快:在原来服务部署在 K8s 时,业务高峰期,单个请求响应时间在 100~200ms 左右,放到函数计算后,在高峰期,请求处理时间也能够维持在 50ms 左右,这是大大超出预期的,分析其中的原因主要是函数计算运行资源比较独立,每个实例处理固定的并发上限,超过部分通过弹出新的实例承载,所以高峰期请求脉冲到来时,也不会出现资源争抢。
弹性效率高:之前在架构设计时,很担心函数计算的冷启动问题,因为冷启动涉及到软硬件资源的初始化。但在实际运行表现看,这点担心也是可以忽略的。函数计算后端机器是神龙服务器,单台机器配置很高,单台机器可以切分出很多的运行实例,并且函数计算在镜像拉取,实例热备方面都有优化,运行实例拉起速度非常快,再加上 Node.js 启动速度的优势,在遇到冷启动时,请求也能够在 100ms 以内响应,这一点对于实时业务非常友好。
业务接口上线到函数计算后,很好的解决了之前高峰期的堆积问题,并且通过函数计算内置的监控和日志服务,在出现问题时,可以更好的辅助问题的排查,最重要的一点,通过函数计算的实时弹性,不再需要提前规划资源和部署冗余服务,使得资源成本也有一定降低。
04 为客户带来更多价值,杭州铭师堂继续探索 Serverless
通过这次项目,函数计算在杭州铭师堂内部的应用得到了更大的推广,将高脉冲和高资源要求的接口剥离出原服务,统一放到函数计算平台承载,对内部系统完成了一次 Serverless 架构的升级。
在整体使用过程中,杭州铭师堂架构团队也对函数计算提出了一些不足点:
产品集成割裂:在调用链路中,Kafka 数据通过 Kafka connector 触发函数计算的调用,Kafka 触发器与函数计算的使用界面有点割裂,具体表现为 Kafka 侧的订阅消费情况在 Kafka 控制台显示,函数计算的调用和监控需要跳转到函数计算,当出现问题时,排查问题需要两边控制台跳转,使用体验很不友好。
部署系统对接不够顺滑:杭州铭师堂经过多年发展,内部有成熟的 CICD 系统,中间加入函数计算之后,需要将函数计算纳入到自有的 CICD 系统中,这方面起初采用函数计算的 Open api,后来经过升级采用了 Serverless Devs 工具,虽然对接体验有了一定提升,细节方面还需要继续打磨。
未来,杭州铭师堂将与阿里云函数计算团队一道在集成,体验和技术深度等方面持续深耕,一起探索 Serverless 在实际业务的落地,以科技服务教育,用互联网改变教育,让中国人都有好书读。
开始使用函数计算
函数计算是事件驱动的全托管计算服务。使用函数计算,客户无需采购与管理服务器等基础设施,只需编写并上传代码或镜像。函数计算即可准备好计算资源,弹性地、可靠地运行任务,并提供日志查询、性能监控和报警等功能。
函数计算主要包含服务、函数、运行环境、触发器、层、应用中心等功能组件,具体产品组件架构图如下所示。

函数计算底层借助阿里云基础设施,如神龙服务器,网络通信,存储,安全组件等,构建安全,可靠,高性能的服务。弹性伸缩,负载均衡,流量控制,租户隔离,容灾等能力采用自研系统,保证了函数计算的计算密度,弹性效率,计费精度等核心竞争力。
函数计算的使用流程如下:
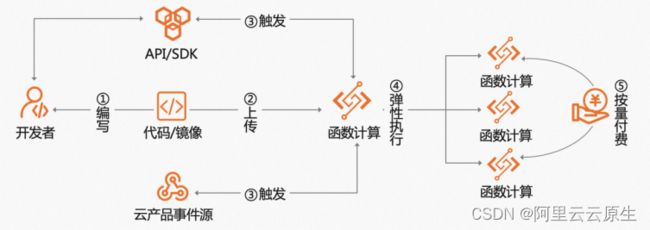
-
创建函数,编写代码。
-
将第 1 步中编写好的代码以函数的形式部署到函数计算。
-
函数计算支持通过触发器快速构建事件驱动架构业务流程的能力。
-
函数计算支持按请求付费的模式,在函数有调用时,后端会弹出真实的计算资源,当同时有多个请求打到函数计算,函数计算会并发的弹出多个计算实例进行并行处理,每个启动计算实例都会保持一定时间的在线,超过一定时间,系统会回收计算实例。
-
最终收费时,按照实际函数运行的时间收费。
通过函数计算的平台,客户只需要专注业务代码,面向函数极简编程(可选多种编程语言),通过函数计算提供的 SDK,Serverless Devs 工具,丰富的云产品事件驱动触发器,可以快速构建完整的调用链路。开发者不再需要直面 IaaS 资源和容器资源,通过将云上业务拆分到函数级别,多个函数组成服务,多个服务构建应用,让开发者从小处处着手,快速实现业务落地。
整体调用链路如下:
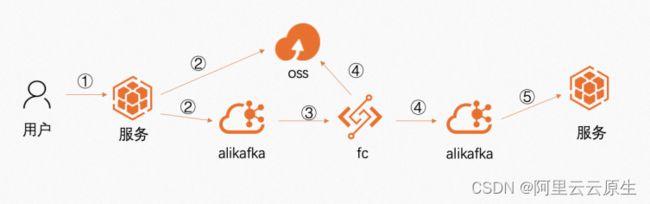
处理步骤细节:
-
用户提交作业出发提交流程,将请求打到后端服务。
-
后端服务将用户提交的作业图片上传到 OSS,并将 OSS 地址作为一条消息发送到 Kafka。
-
函数计算的 Kafka 触发器实时的感知 Kafka topic,当有新数据到达,实时触发函数处理。
-
函数计算函数获取到触发请求中的数据,从 OSS 获取数据,并对数据进行处理,将处理结果发回到 Kafka topic。
-
后端程序订阅 Kafka topic,对处理结果进行存储和下一步的展示。
点击此处,直达函数计算!