【Java基础】day15
day15
一、为什么需要使用多线程?
1、资源利用率提升,程序处理效率提高
2、软件运行效率提升
3、使用线程可以把占据时间长的程序中的任务放到后台去处理
4、充分利用 CPU 资源,多核 CPU 的情况下会更高效
二、Spring Boot 的启动流程?
1、启动 main() 方法开始
2、初始化配置,通过类加载器 loadFactories 读取 classpath 下所有的 spring.factories 配置文件,创建一些初始配置对象
3、通知监听器启动开始,创建环境对象 environment,用于读取环境配置,如 application.yml 等配置文件。
4、创建应用程序上下文 createApplicationContext,创建 Bean 工厂对象
5、刷新上下文(启动核心步骤)
- 配置工厂对象,包括上下文类加载器、对象发布处理器、
beanFactoryPostProcessorBean 工厂后置处理器 - 注册并实例化 Bean 工厂发布处理器,并且调用这些处理器,对包扫描解析(主要是 class 文件)
- 注册并实例化 Bean 发布处理器
BeanPostProcessor - 初始化一些与上下文有特别关系的 Bean 对象,创建 Tomcat 服务器
- 实例化所有 Bean 工厂缓存的 Bean 对象,将上一步剩下的 Bean 对象全部进行实例化
- 发布通知,通知上下文刷新完成,启动 Tomcat 服务器
6、通知监听者,启动程序完成
三、ThreadLocal 的底层原理是怎样的?
在线程隔离时,会通过使用线程副本来达到线程之间的隔离。
ThreadLocal 类提供了线程局部变量。这些变量不同于普通变量,因为访问某个变量(通过 get 或 set 方法)的每个线程都有自己的局部变量,它独立于变量的初始化副本。ThreadLocal 实例通常是类中的 private static 字段,它们希望将状态与某一个线程相关联,比如用户 ID 、事务 ID 这些状态值。
public T get() {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null) {
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
}
}
return setInitialValue();
}
ThreadLocal 中的 get 方法,直接利用 Thread 对象获取 ThreadLocalMap 。ThreadLocalMap 中的 Entry 的结构为:
static class Entry extends WeakReference<ThreadLocal<?>> {
/** The value associated with this ThreadLocal. */
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
这里不使用 HashMap 是因为要继承 WeakReference 弱引用,避免内存泄漏。
ThreadLocalMap(ThreadLocal<?> firstKey, Object firstValue) {
table = new Entry[INITIAL_CAPACITY];
int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1);
table[i] = new Entry(firstKey, firstValue);
size = 1;
setThreshold(INITIAL_CAPACITY);
}
该 Entry 继承自弱引用,一个对象若只被弱引用所引用,则被认为是不可访问(或弱可访问)的,并因此可能在任何时刻被回收。如果发生弱引用 Entry 被回收(key 被回收,value 没有),这个时候就导致 key 为 null 而 value 存在且为强引用,从而导致有可能访问不到 value 值,又因为 ThreadLocalMap 的生命周期和 Thread 的生命周期相同,所以容易发生内存泄漏。
内存泄漏:程序在申请内存之后,不能去释放一直不被使用的一个内存,导致内存占用最终耗光,可能出现 OOM。
ThreadLocal 的设计中,在进行 set 、get 、remove 、rehash 的操作的时候,会扫描一遍 key 为 null 的一些 entry ;发现之后会将对应的 value 也赋值为 null ,完成一个自动释放的操作。但是需要注意的是,如果 ThreadLocal 以后不会被使用,那么 set、get、remove、rehash 这些方法得不到使用,还是会造成内存的泄漏。
四、String 的 length 方法的返回值
一般来说,在普通的字符串变量下,length 方法返回的是 String 字符串的字面量长度,也就是我们自己人眼可以看到的长度。但是,并不是所有的 String 字符串使用 length 方法都会返回这个长度数值,可以参看下面的代码:
public static void main(String[] args) {
String b = "";
// 音符字符的 UTF-16 编码
String c = "\uD834\uDD1E";
System.out.println(c);
System.out.println(b.length()); // 输出:2
System.out.println(b.codePointCount(0, b.length())); // 输出:1
}
这个情况造成的原因,可以在源码中看到答案:
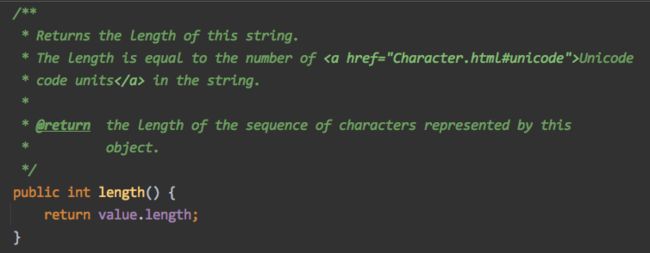
length() 方法判断长度,基本单位使用的是 Unicode 编码格式来进行判断。Java中 有内码和外码这一区分简单来说
- 内码: char 或 String 在内存里使用的编码方式。
- 外码:除了内码都可以认为是“外码”(包括 class 文件的编码)
而在 Java 中,内码 Unicode 使用的是 UTF-16 编码。所以 String 的 length 方法返回的就是字符串在 UTF-16 编码中长度。UTF-16 编码一个字符对于 U+0000-U+FFFF 范围内的字符采用 2 字节进行编码,而对于字符的码点大于 U+FFFF 的字符采用 4 字节进行编码。前者是两字节也就是一个代码单元,后者一个字符是四字节也就是两个代码单元。所以最开始直接调用 length方法返回的是 2 而不是 1。
如果想要按照正常的逻辑,想要返回这个字符的长度,也就是占用多个字符。我们可以使用 codePointCount 方法来实现。看这段代码可以看到具体的方法说明。这个方法返回的就是字符串的目标下标区间的 char 占用长度。
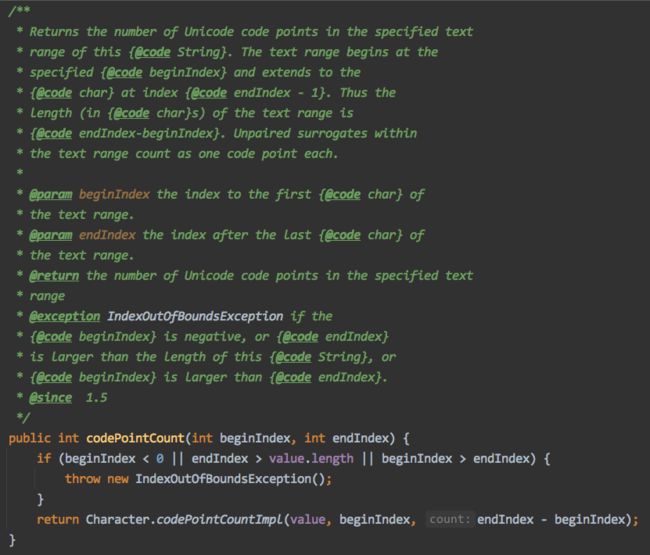
调用这个方法,就能正常返回 1 了。
五、实现序列化接口为何需要指定序列化 ID?
实现序列化,我们通常需要在类上实现 Serializable 接口。 JDK 官方对于这个接口做出了一些解释:
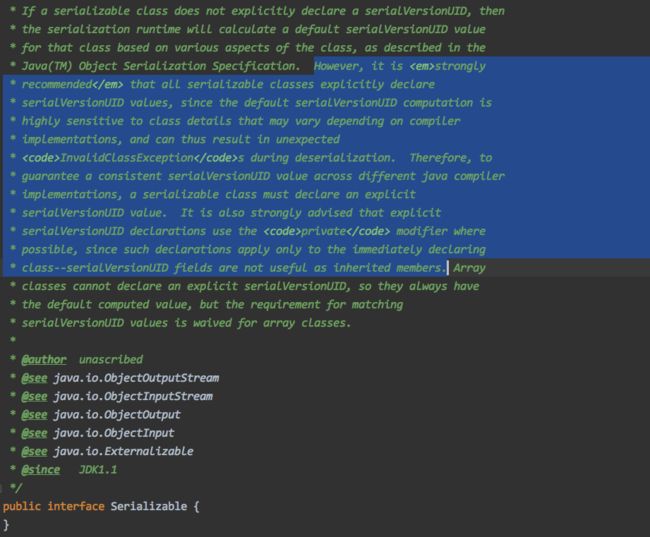
这段话的翻译为:
强烈建议所有可序列化的类都显式声明
serialVersionUID值,因为默认的serialVersionUID计算对类的细节高度敏感,这些细节可能因编译器实现而异,因此可能在反序列化期间导致意外的InvalidClassException。因此,为了保证在不同的 Java 编译器实现中具有一致的serialVersionUID值,可序列化的类必须声明一个显式的serialVersionUID值。还强烈建议显式serialVersionUID声明尽可能使用private修饰符,因为此类声明仅适用于立即声明的类——serialVersionUID字段不能用作继承的成员。
如果没有明确指定 serialVersionUID,序列化的时候会根据字段和特定的算法生成一个 serialVersionUID,当属性有变化时这个 id 会发生变化,所以反序列化的时候就会失败,抛出“本地 class 的唯一 id 和流中 class 的唯一 id 不匹配”。
总结:
- 为了实现跨 Java 编译器的一致性。
- 默认的
serialVersionUID计算对类细节高度敏感,这些细节可能因编译器实现而有不同。 - 为了保证在不同的 java 编译器实现中具有一致的
serialVersionUID值,需要显式声明 UID 的值。