Apache Linkis 介绍
关键名词
LinkisMaster:Linkis的计算治理服务层架中的管理服务,主要包含了AppManager、ResourceManager、LabelManager等几个管控服务。原名LinkisManager服务 。
Entrance:计算治理服务层架中的入口服务,完成任务的调度、状态管控、任务信息推送等功能 。
Orchestrator:Linkis的编排服务,提供强大的编排和计算策略能力,满足多活、主备、事务、重放、限流、异构和混算等多种应用场景的需求。现阶段Orchestrator被Entrance服务所依赖 。
EngineConn(EC):引擎连接器,负责接受任务并提交给底层引擎如Spark、hive、Flink、Presto、trino等进行执行 。
EngineConnManager(ECM):Linkis 的EC进程管理服务,负责管控EngineConn的生命周期(启动、停止)。
LinkisEnginePluginServer:该服务负责管理各个引擎的启动物料和配置,另外提供每个EngineConn的启动命令获取,以及每个EngineConn所需要的资源 。
PublicEnhencementService(PES): 公共增强服务,为其他微服务模块提供统一配置管理、上下文服务、物料库、数据源管理、微服务管理和历史任务查询等功能的模块。
Linkis 的作用
Linkis是在底层引擎和上层应用工具之间的一个通用的“计算中间件”的中间层,统一了上层应用工具到底层计算存储引擎的入口(作为大数据平台的统一入口),以标准化可重用的方式处理紧耦合、重复造轮子、扩展难、应用孤岛等计算治理问题。
通过使用Linkis 提供的REST/WebSocket/JDBC 等标准接口,上层应用可连接访问MySQL/Spark/Hive/Presto/Flink /Trino等底层引擎,同时实现变量、脚本、函数和资源文件等用户资源的跨上层应用互通,以及通过REST标准接口提供了数据源管理和数据源对应的元数据查询服务。
作为计算中间件,Linkis 提供了强大的连通、复用、编排、扩展和治理管控能力。通过计算中间件将应用层和引擎层解耦,简化了复杂的网络调用关系,降低了整体复杂度,同时节约了整体开发和维护成本。
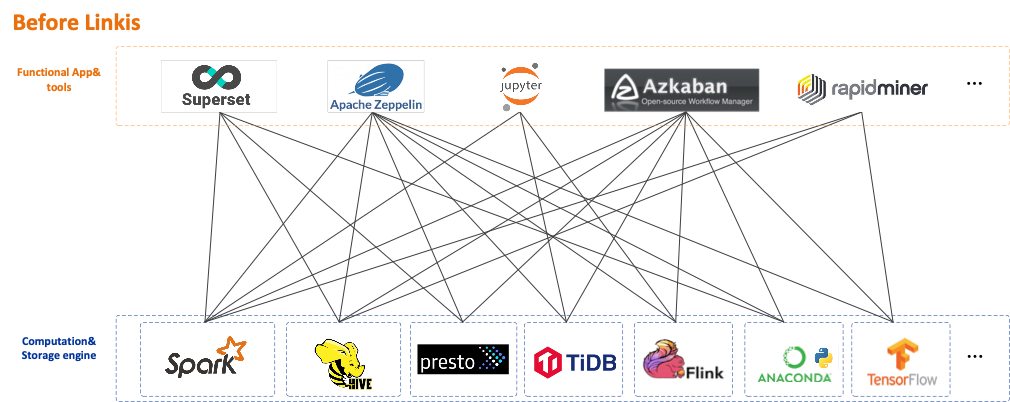 ** VS** 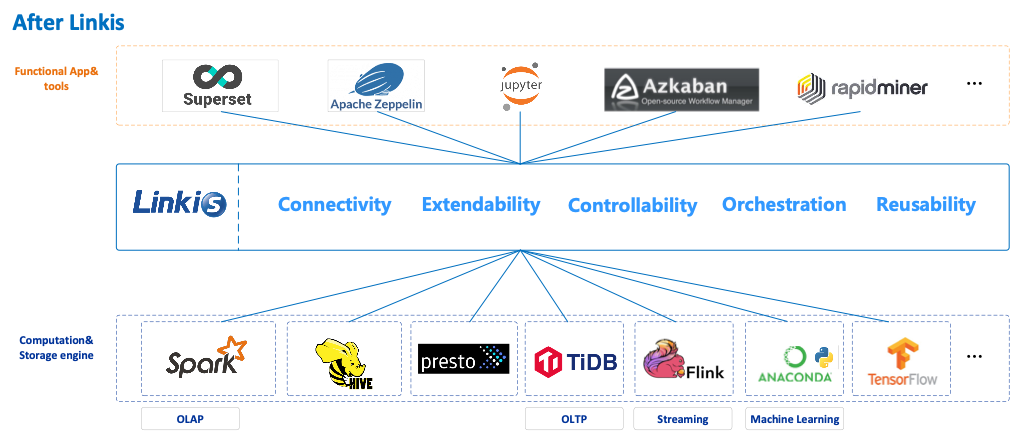
Linkis 的核心特点
- 丰富的底层计算存储引擎支持
目前支持的计算存储引擎:Spark、Hive、Flink、Python、Pipeline、Sqoop、openLooKeng、Presto、ElasticSearch、JDBC和Shell等。
正在支持中的计算存储引擎:Trino(计划1.3.1)、SeaTunnel(计划1.3.1)等。
支持的脚本语言:SparkSQL, HiveQL, Python,Shell, Pyspark, R, Scala 和JDBC 等。
- 强大的计算治理能力
基于Orchestrator、Label Manager和定制的Spring Cloud Gateway等服务,Linkis能够提供基于多级标签的跨集群/跨IDC 细粒度路由、负载均衡、多租户、流量控制、资源控制和编排策略(如双活、主备等)支持能力。
- 全栈计算存储引擎架构支持
能够接收、执行和管理针对各种计算存储引擎的任务和请求,包括离线批量任务、交互式查询任务、实时流式任务和存储型任务。
- 资源管理能力ResourceManager
不仅具备对 Yarn 和 Linkis EngineManager 的资源管理能力,还将提供基于标签的多级资源分配和回收能力,让 ResourceManager 具备跨集群、跨计算资源类型的强大资源管理能力。
- 统一上下文服务
为每个计算任务生成context id,跨用户、系统、计算引擎的关联管理用户和系统资源文件(JAR、ZIP、Properties等),结果集,参数变量,函数和UDF等,一处设置,处处可引用。
- 统一物料
系统和用户级物料管理,可分享和流转,跨用户、系统共享物料。
- 数据源管理服务
提供了hive、es、mysql、kafka等类型数据源的增删查改、版本控制、连接测试等功能,可以用于流式数仓、交互式分析等功能工具的数据源管理能力。并提供了hive、es、mysql、kafka等元数据的查询能力。
Linkis的服务架构
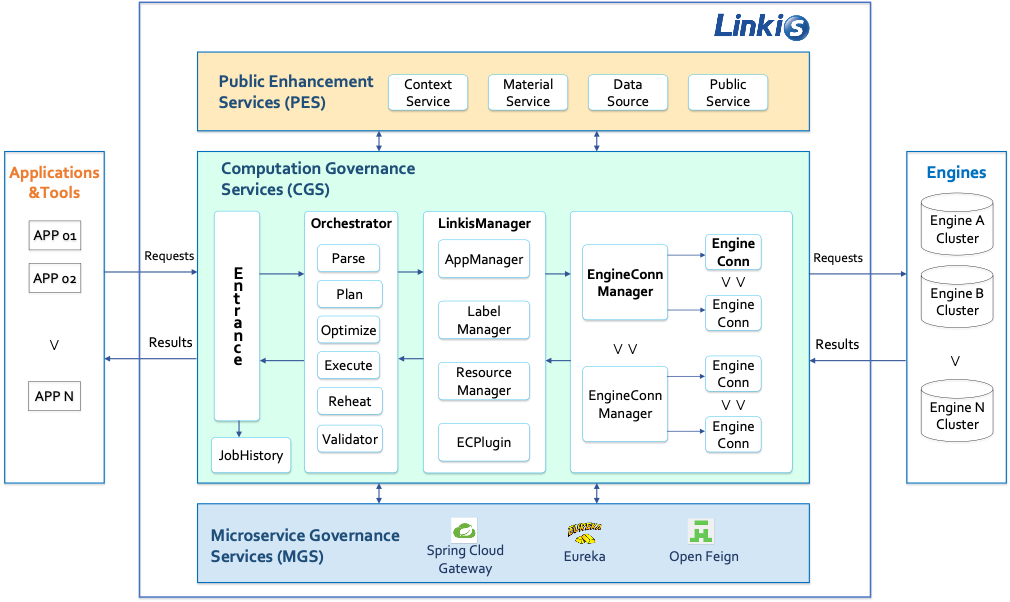
Linkis主要由三组服务组成:
- 计算治理服务组 CGS (Computation Governance Services)
完成计算任务和请求的提交、准备、执行、返回结果等主要步骤,且为每个步骤提供了强大和灵活的能力 。
提交阶段:主要提供通用的接口,接收上层应用工具提交过来的任务,并能提供基础的解析和拦截能力。
准备阶段:主要通过编排器Orchestrator,和LinkisMaster完成对任务的解析编排,并且做资源控制,和完成EngineConn的创建。
执行阶段:通过引擎连接器EngineConn来去实际完成和底层引擎的对接,通常每个用户要连接不同的底层引擎,就得先启动一个对应的底层引擎连接器EC。计算任务通过EC,来提交给底层引擎做实际的执行,和状态、日志、结果等信息的获取。
结果返回阶段:返回任务执行的结果信息,支持按照多种返回模式,如:文件流、JSON、JDBC等。
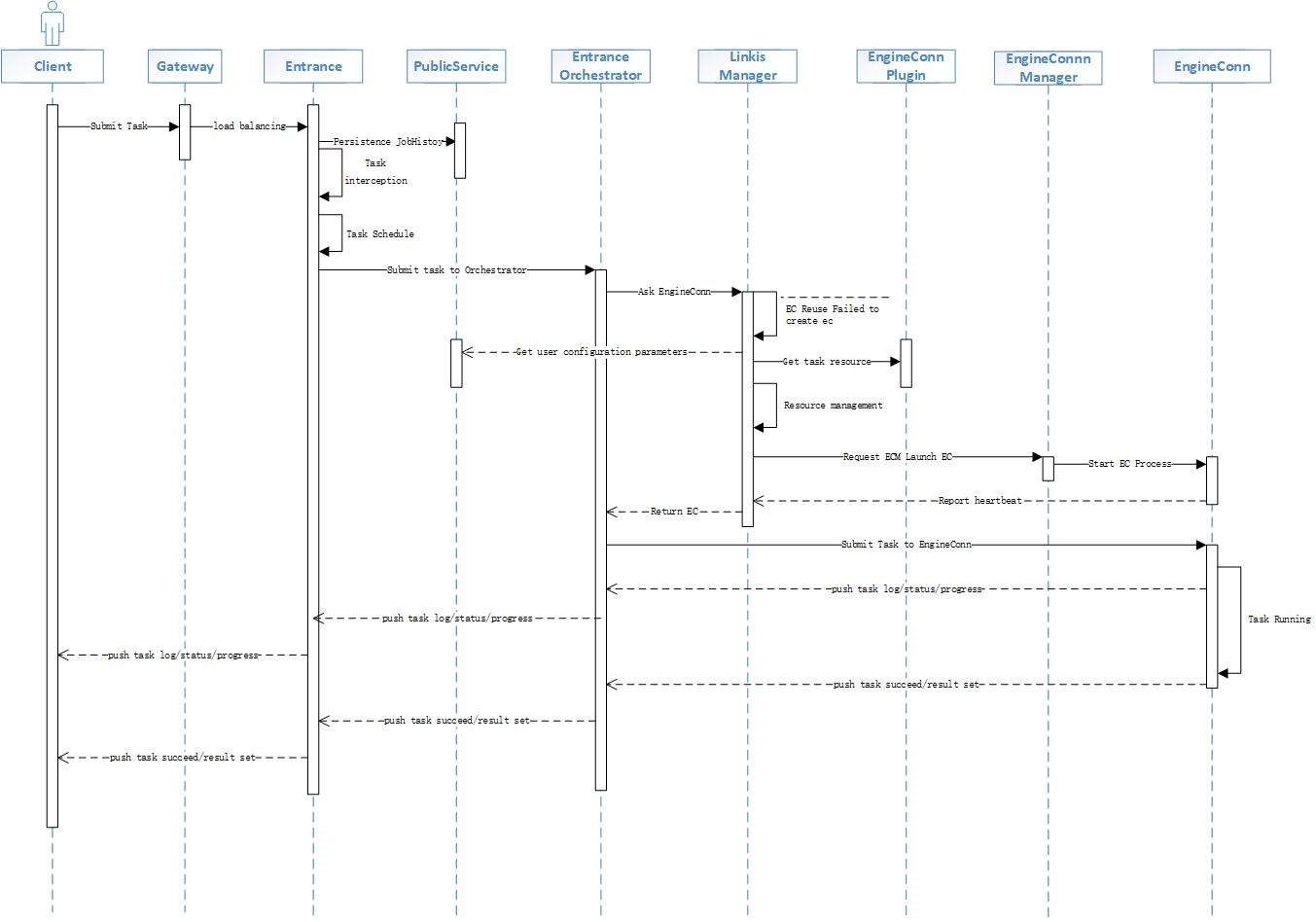
整体的时序图如下:
- 公共增强服务组 PES (Public Enhancement Services)
打破了上层应用工具间的孤岛,做到变量、函数、文件、结果集等上下文的共享。
主要提供了以下能力 :
公共的上下文能力:统一UDF、变量、小函数的定义规范和语义,做到一处定义多个工具都可使用。
统一的数据源能力:数据源在Linkis层进行统一定义和管理,应用工具只需要通过数据源名字来进行使用,不再需要去维护对应数据源的连接信息。而且在不同的工具间数据源的含义都是一样的。
统一物料的能力:提供统一的物料,在多个工具间支持共享访问这些物料,并且物料支持存储多种的文件类型,并支持版本控制。
- 微服务治理服务组 MGS (Microservice Governance Services)
主要复用了SpringCloud的能力。
Linkis 的引擎连接器
Linkis从4类引擎使用特点出发,包括AP(分析型)、TP(事务处理)、MACHINE LEARNING(机器学习)和STREAMING(流式计算),抽象出了3种场景,及对应的3种顶层的引擎连接器EngineConn:
**OLAP EngineConn:**对应AP和MACHINE LEARNING引擎,这两类底层引擎的计算任务处理过程比较类似,都需要能够提交、获得运行时进度、状态和日志、获得结果集等。
OLTP EngineConn:对应TP引擎,通过提供通用的JDBC/ODBC Driver和接口,来提供对OLTP引擎的对接支持。
Stream EngineConn:对应STREAMING流式计算引擎,能够完成流式计算任务的提交和管理,不需要获得结果集。
计算任务通过引擎连接器EngineConn,提交给底层引擎做实际的执行,和状态、日志、结果等信息的获取。
Linkis的优势
一般在对接和使用计算引擎的时候,一般会有环境准备、计算任务提交、计算任务执行、和系统运维管理4个阶段。
环境准备:需要安装和运维多个底层引擎的客户端和运行时环境。
计算任务提交:是否支持自定义参数,和执行的控制规则等功能,如超时、重试等;是否支持支持底层引擎的原生参数等。
计算任务执行:需要能够方便的去获取任务的执行结果、运行状态、日志等信息。
系统运维:是否支持多租户、细粒度的资源控制、高并发、高可用、审计等。
将Linkis作为计算中间件时,在各个阶段有以下优势:
环境准备
能解耦上层应用和底层引擎间的连接,简化上层应用工具的环境准备的维护,提供复用。
计算任务提交
- 可以支持用各种类型接口提交各种不同语言类型的任务,对上层工具调用底层引擎提供了很强的友好度和灵活度,让下层引擎的调用变得很便利;
- 基于多层级的异步调度模式,可以去支持百万级别的任务提交,等待运行并返回结果。
计算任务执行
通过执行节点ECM构建了一个连接层的资源池,把之前分散在各个上层工具系统中的用于启动client、driver的机器集中了起来,池化统一利用,方便运维。
系统运维:
支持高可用:利用了微服务架构的优势,所有的服务都是可以多活提供服务,并支持灰度更新去保证服务的稳定性。
支持多租户、细粒度的资源控制:基于Linkis的标签体系机制,可以做到Linkis层级的租户和机器隔离,支持多用户多租户场景。基于标签的多级精细化资源管控策略,可以从租户、用户、应用、EC类型、到具体启动的EC实例等多层级进行精细化资源控制。
更高的安全性:通过限制底层引擎的统一入口为Linkis,在Linkis层提供身份识别能力。提供任务的检验拦截功能,可以对高风险操作的任务,在任务执行前进行检验对Bad SQL,高危险SQL、敏感表查询进行识别拦截。
完善的日志审计功能:提供统一的日志和审计功能,所有的任务和接口请求都会进行记录,而不需要再去各个工具和引擎收集日志。
比如想统一用restful接口方式,向底层不同引擎提交计算任务,可以调Linkis的restful接口,如果是用python开发的上层工具,就可以用习惯的Python语言,初始化一个LinkisClient,然后提交比如Scala类型的任务,到spark集群执行,然后再方便的将返回结果集放到一个python dataframe中做进一步处理。
参考文章:
- 开源Apache Linkis:上层应用与底层引擎之间的计算中间件
- Linkis任务执行流程 | Apache Linkis