springboot+freemarker实现导出word模板
freemarker
- FreeMarker是一款模板引擎: 即一种基于模板和要改变的数据, 并用来生成输出文本(HTML网页、电子邮件、配置文件、源代码等)的通用工具。 它不是面向最终用户的,而是一个Java类库,是一款程序员可以嵌入他们所开发产品的组件。
- FreeMarker是免费的,基于Apache许可证2.0版本发布。其模板编写为FreeMarker Template Language(FTL),属于简单、专用的语言。需要准备数据在真实编程语言中来显示,比如数据库查询和业务运算, 之后模板显示已经准备好的数据。在模板中,主要用于如何展现数据, 而在模板之外注意于要展示什么数据
项目配置:
<dependency>
<groupId>org.freemarkergroupId>
<artifactId>freemarkerartifactId>
<version>2.3.20version>
dependency>
#配置freemarker配置
#模板存放路径(默认地址为classpath:/templates/)
spring.freemarker.template-loader-path=classpath:/templates
#模板后缀
spring.freemarker.suffix= .ftl
#编码
spring.freemarker.charset= utf-8
#RequestContext属性的名称(默认为-)
spring.freemarker.request-context-attribute= request
注意:这里默认的模板文件是resources下的templates文件夹中(默认路径模板文件一定要放在resources的下面,程序在加载模板文件时freemarker提供了有多种方法取模板文件,可以自己去了解一下)
下一步我们要做的是先好我们的word模板然后将模板转换为xml文件。在word模板中需要定义好我们的占位符哦,使用${string}的方式。“string”根据自己的爱好定义就好了。
过程如下:
word文档:
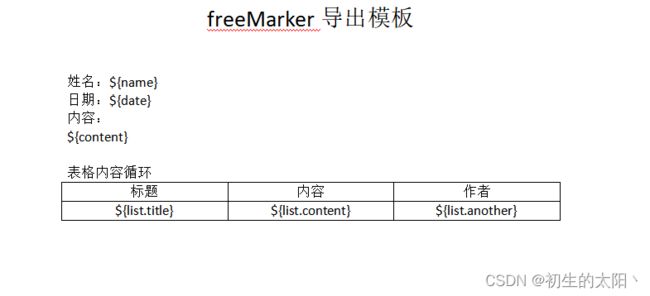
然后将我们的word文档另存为xml文档。
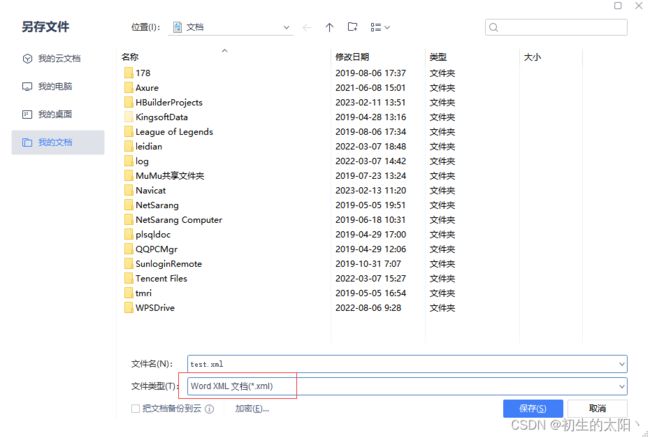
将我们的xml文档的后缀改为ftl,然后用可以打开ftl文件的软件打开我们的ftl文件。在这里我们有几个需要注意的地方。
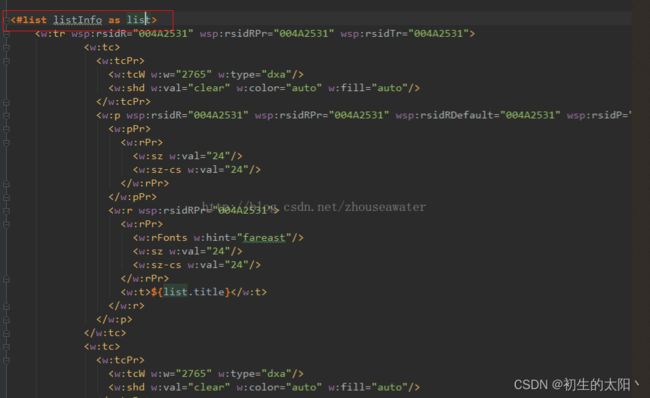
第一,定义的占位符可能会被分开了。就像下面这样:

我们需要做的就是删掉多余的部分,图中我定义的是${userName}.所以我就把多余的删掉,变成${userName}就可以了。
第二,我们需要注意的就是在我们的表格部分需要自己添加freeMarker标签。在表格代码间用自定的标签括起来。定义的参数要和我们在方法中定义的一致,否则无法取到值。
表格开始:
注意:
freemarker中文在线手册指令参考链接:http://freemarker.foofun.cn/ref_directives.html
下面是功能实现:
工具类
package com.newdo.base;
import freemarker.template.Configuration;
import freemarker.template.Template;
import javax.servlet.ServletOutputStream;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.*;
import java.net.URLEncoder;
import java.util.Map;
public class WordUtil {
/**
* 生成word文件
* @param dataMap word中需要展示的动态数据,用map集合来保存
* @param templateName word模板名称,例如:test.ftl
* @param filePath 文件生成的目标路径,例如:D:/wordFile/
* @param fileName 生成的文件名称,例如:test.doc
*/
@SuppressWarnings("unchecked")
public static void createWord(HttpServletRequest request, HttpServletResponse response, Map dataMap, String templateName, String filePath, String fileName){
try {
//创建配置实例
Configuration configuration = new Configuration();
//设置编码
configuration.setDefaultEncoding("UTF-8");
//ftl模板文件 取模板文件存放地址
configuration.setClassForTemplateLoading(WordUtil.class,"/templates");
//获取模板
Template template = configuration.getTemplate(templateName);
//输出文件
File outFile = new File(filePath+File.separator+fileName);
//如果输出目标文件夹不存在,则创建
if (!outFile.getParentFile().exists()){
outFile.getParentFile().mkdirs();
}
//检测是否存在 存在删除
if (outFile.exists()) {
outFile.delete();
}
//将模板和数据模型合并生成文件
Writer out = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(outFile),"UTF-8"));
//生成文件 实际这里已经将文件生成在指定位置
template.process(dataMap, out);
//以下操作是将文件下载
File file = new File(filePath + "\\" + fileName);
InputStream fin = new FileInputStream(file);
response.setCharacterEncoding("utf-8");
response.setContentType("application/msword");
// 设置浏览器以下载的方式,处理该文件名 ps:docx格式office可能存在打不开等问题
fileName = URLEncoder.encode(fileName, "utf-8");
response.setHeader("Content-Disposition","attachment;filename="+fileName);
ServletOutputStream out2 = response.getOutputStream();
byte[] buffer = new byte[512];
int bytesToRead = -1;
// 通过循环将读入的Word文件的内容输出到浏览器中
while ((bytesToRead = fin.read(buffer)) != -1) {
out2.write(buffer, 0, bytesToRead);
}
//关闭流
out.flush();
out.close();
fin.close();
out2.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
文件存放地址
方法调用
public static void main(String[] args) {
/** 用于组装word页面需要的数据 */
Map<String, Object> dataMap = new HashMap<String, Object>();
dataMap.put("name","测试");
dataMap.put("date","2023-03-09");
dataMap.put("content","测试内容");
List<Object> datas = new ArrayList<>();
for(int i=0;i<10;i++){
Data data = new Data();
data.put("title","标题" + i);
data.put("content","内容" + i);
data.put("another","作者" + i);
datas.add(data);
}
dataMap.put("listInfo",datas);
String filePath = "";
if (IsWhatSystem.whatSystem()) {
//文件路径
filePath = "D:/doc_f/";
}else {
filePath = "/doc_f/";
}
//文件唯一名称
String fileOnlyName = "生成Word文档.doc";
/** 生成word 数据包装,模板名,文件生成路径,生成的文件名*/
WordUtil.createWord(dataMap, "dacyjl.ftl", filePath, fileOnlyName);
}
另外模板中表格列也是可以实现合并的,这里就不再多说,下方参考链接中会有提到。
本文参考链接:
https://www.cnblogs.com/h-java/p/10026850.html
单元格合并参考链接
https://blog.csdn.net/weixin_43667830/article/details/106936546
https://blog.csdn.net/weixin_43165220/article/details/119537190