论文笔记:Prompt-Based Meta-Learning For Few-shot Text Classification

论文来源:EMNLP 2022
论文地址:2022.emnlp-main.87.pdf (aclanthology.org)
代码地址:GitHub - MGHZHANG/PBML
GB/T 7714
Zhang H, Zhang X, Huang H, et al. Prompt-Based Meta-Learning For Few-shot Text Classification[C]//Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 2022: 1342-1357.
摘要
元学习方法在各种小样本场景下取得了令人满意的结果,但是元学习方法通常需要大量的数据来构建许多用于元训练的小样本任务,这在实际小样本场景中是不切实际的。提示学习弥合了预训练任务和下游任务之间的差距,是另一种高效的小样本学习器。本文在结构上紧密结合了这两种小样本学习方法,并提出一种基于提示的元学习模型(PBML),通过添加提示机制来克服上述元学习问题。PBML为基础学习器分配标签词学习,为元学习器分配模板学习。
引言
关于元学习和提示学习方面的内容在此不再赘述,感兴趣者可以阅读相关论文。
PBML在提示方面,采用软策略,即使用连续可微的标签词和模板;元学习器主要学习软模板嵌入和基于MLM的编码器。两种方法相结合的核心思想是将模板和编码器学习分配给元学习,将标签词学习分配给基础学习器。
由于不同的任务可能涉及不同的类别,标签词需要考虑特定的类别,因此标签词的学习要交给基础学习器进行任务特定的适应。相应地,通过提示方法在[MASK]位置嵌入的输出反映了模型对文本的理解。各种任务应该共享这种自然语言理解(NLU)的能力,这就是为什么模板和编码器的学习被分配给元学习者的原因。
前期知识
小样本学习略
元学习的目的是通过不同的元任务训练元学习器,使得元学习器可以在小的支持集上快速获得特定任务的基础学习器。形式上,可以考虑元训练和元测试两个阶段。
提示学习略
方法
PBML框架如Figure 2 所示。PBML由3部分组成:首先,元学习器对实例进行编码,并为每个实例获得[MASK]标记的嵌入;其次,探索了一个外部知识图谱用于连续标签词初始化;然后基础学习器将使用支持集实例的预测嵌入来更新标签词嵌入。查询集的推理是基于自适应的标签词嵌入,并使用查询集上的损失进行元优化。

元编码器和模板设计
给定语句 ,首先将模板链接到,并获得
,首先将模板链接到,并获得 ,以主题分类为例,提示文本可以表示为:
,以主题分类为例,提示文本可以表示为:
= The topic is [MASK].
然后,MLM作为元编码器,将作为输入,输出 ,即[MASK]的隐藏状态作为预测答案表示。
,即[MASK]的隐藏状态作为预测答案表示。
本文采用了一种软提示策略,使用可学习的嵌入向量替代离散的模板标记,并使用它们的词嵌入来进行向量初始化。离散模板和软模板之间的比较如Figure 6和7所示。这种软策略允许对模板进行连续优化,而不是受离散标记的限制。将编码器参数表示为![]() ,软模板嵌入表示为
,软模板嵌入表示为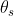 ,则元编码器被表述为:
,则元编码器被表述为:
![]()


软提示方法首先将离散的token-ids从原始文本映射到单词嵌入中,然后将可学习的向量之间连接到这些单词嵌入中。模型冻结了MLM的词嵌入层,并且只能从编码器层更新软模板嵌入和参数。
标签词初始化
虽然直接将类名作为标签词最为直观,但是类名的语义有时过于概念化,没有足够的语义信息。本文引入了外部知识图谱Related Words,用于从类名为每个类扩展丰富的标签词。具体而言,从知识图谱中探索以获得top ![]() 类名相关单词作为候选词。获得的候选词集
类名相关单词作为候选词。获得的候选词集![]() 包括同义词和以类名高度相关的单词。例如,与“Politics”相关的候选词有“policy”、“government”、“low”和“diplomatic”等。然后,通过平均候选词嵌入
包括同义词和以类名高度相关的单词。例如,与“Politics”相关的候选词有“policy”、“government”、“low”和“diplomatic”等。然后,通过平均候选词嵌入![]() ,将候选词合并到每个类的一个原型中。最后,得到了N个合成的连续标签词嵌入
,将候选词合并到每个类的一个原型中。最后,得到了N个合成的连续标签词嵌入![]() ,即包含初始N个标签词嵌入的矩阵。其中
,即包含初始N个标签词嵌入的矩阵。其中![]() 表示N个类的大致语义,并将在下一个模板中进一步调整。
表示N个类的大致语义,并将在下一个模板中进一步调整。
标签词快速调优
基础元学习器将使用支持集实例来连续优化初始化的标签词嵌入![]() 。本文的目标是通过合并来自支持集的上下文信息,使标签词嵌入更具有鉴别性。
。本文的目标是通过合并来自支持集的上下文信息,使标签词嵌入更具有鉴别性。
具体来说,本文强加了两个需要通过快速调优来实现的目标。(a)对于来自类 的支持集实例
的支持集实例![]() ,
,![]() 是[MASK]位置上的隐藏状态。期望
是[MASK]位置上的隐藏状态。期望![]() 和
和 (的标签词嵌入)之间的相似度高于
(的标签词嵌入)之间的相似度高于![]() 与其他标签词之间的相似度。(b)对于每个类,其标签词与属于的支持实例之间的相似度应该大于与其他类实例之间的相似度。为实现这两个目标,定义如下两个对比损失:
与其他标签词之间的相似度。(b)对于每个类,其标签词与属于的支持实例之间的相似度应该大于与其他类实例之间的相似度。为实现这两个目标,定义如下两个对比损失:

为了提高自适应的鲁棒性,通过系数![]() 增加了实例级注意力机制,该注意力得分用于衡量每个支持实例的信息程度(包含噪声数据等)。
增加了实例级注意力机制,该注意力得分用于衡量每个支持实例的信息程度(包含噪声数据等)。![]() 的定义如下:其中
的定义如下:其中 为温度超参数,设为3
为温度超参数,设为3

如果![]() 与初始标签词嵌入越相似,则认为其信息量越大,
与初始标签词嵌入越相似,则认为其信息量越大,![]() 的关注度越高,相比之下,在两个损失中为噪声实例分配了很少的关注,产生更小的梯度步长和更健壮的适应轨迹。
的关注度越高,相比之下,在两个损失中为噪声实例分配了很少的关注,产生更小的梯度步长和更健壮的适应轨迹。
在每次快速调优的迭代中,应用的梯度下降如下:其中,![]() 为学习率,
为学习率,![]() ,快速调优将迭代T步,并输出
,快速调优将迭代T步,并输出![]() 。
。

查询推理
通过计算查询嵌入![]() 和任务适应的标签词嵌入
和任务适应的标签词嵌入![]() 之间的内积来预测查询实例的标签,查询实例属于类的概率为:
之间的内积来预测查询实例的标签,查询实例属于类的概率为:

然后使用argmax函数进行预测。

元优化
在元训练过程中,从元训练集中随机构建了许多小样本元任务。基础元学习器的每一轮学习任务特定的标签词嵌入![]() ,然后从任务中元学习模板和编码器,考虑到查询集Q上的损失,根性元学习器M。元学习器的优化规则可以表述为:
,然后从任务中元学习模板和编码器,考虑到查询集Q上的损失,根性元学习器M。元学习器的优化规则可以表述为:

其中,![]() 是元参数
是元参数![]() 的元学习率,L是
的元学习率,L是![]() 上的交叉熵损失。
上的交叉熵损失。
将提示调优与元学习结合起来,既可以学习任务特定的知识,也可以学习任务不可知的知识。具体来说,(1)元学习器以较低的速度![]() 为软模板嵌入和编码器找到合适的参数;(2)基础学习器以更快的速度
为软模板嵌入和编码器找到合适的参数;(2)基础学习器以更快的速度![]() 学习连续标签词,以快速适应。
学习连续标签词,以快速适应。
实验
整体及消融实验

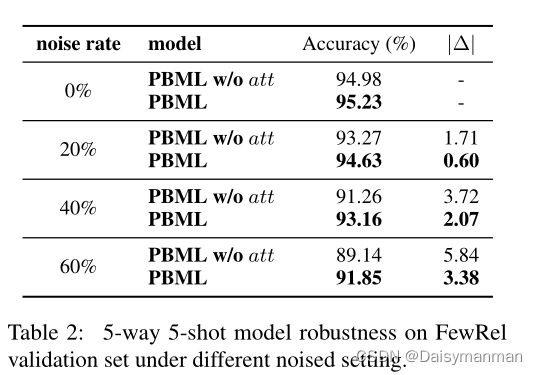
鲁棒性验证
训练数据影响
