redis
一)认识NoSQL
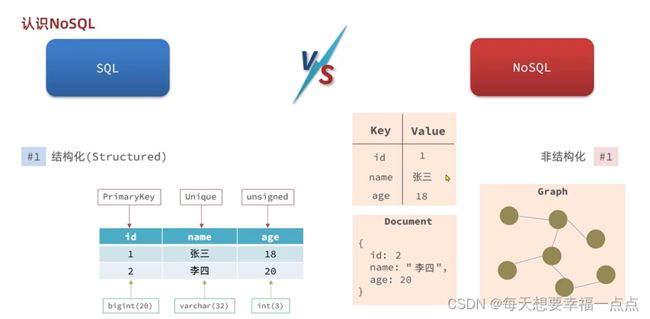
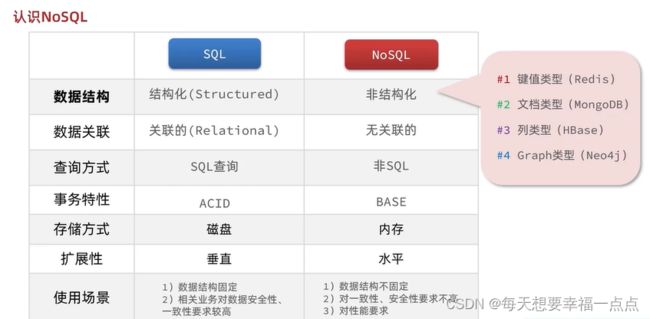
格式化数据VS格式化
1)SQL关系型数据库,在关系型数据库里面表中的字段是有限制的,况且最好不要随意删除修改表结构,存入到关系型数据库中的数据,都是结构化的数据,对于这些数据都是必须要有格式化的要求,这些要求都是通过表的结构以及表的约束来进行定义的
2)比如说下面的用户表必须有三个字段,name,age和id,并且必须给id加约束,比如说加上主键约束,给name加上unique约束,不能重复,age加上unsigned,不能为负数
这些约束一旦定义好了,此时表的结构就固定了,将来我们插入表中的所有数据的时候,都需要严格地遵循这些约定,并且数据库也会对你插入的数据做校验,如果不符合这些约定,自然就会报错,不允许做插入;
3)但是NOSQL可以随意修改键值对的名字,键值型的关系型数据库redis,文档型数据库,字段任意,非常松散
关联性VS非关联性
表和表之间有着外键的关系,将来删除商品就会被不允许,数据库就会维护这些关系
1)关系型数据库通过嵌套的方式来进行关联,数据存储大量重复的数据,比如说张三买了荣耀6,但是李四也是可以买荣耀6的,非关系型数据库是不会帮你维护表和表之间的关系
2)但是我们的orders里面也是可以进行存储手机id,再来另外一张表来进行存储手机的信息,此时就需要依靠程序员的业务逻辑来进行维护了,因为非关系型数据库不会帮你进行维护表和表之间的关联关系,无关联数据;
查询:
SQL查询语句固定,通用语法;
NOSQL:查询语法:不同的库有不同的语法
事务:
NOSQL数据库无法满足事务


安装redis
1)打开云服务器:切换到/usr/local/src目录下面
2)rz+redis安装包的名字,进行拖拽
3)进行执行命令:tar -zxvf redis-6.2.6.tar.gz进行解压缩
4)进行进入到redis-6.2.6目录下面,也就是刚刚解压好的redis目录
5)验证redis是否安装成功:
6)启动redis:
6.1)在任意目录都可以进行运行:redis-server,弹出界面但是啥也敲不出来,是卡死的,这种启动方式毛用没有,除非重新打开一个窗口进行连接redis
6.2)进行修改配置文件启动redis
6.2.1)进行先备份配置文件: cp 文件路径1 文件路径2
6.2.2)使用 vim redis.conf进行修改
修改过程中,可以按下esc使用/文件名来快速查找对应的文件
先进入到reds-6.2.6进行到安装路径
最后执行命令:redis-server redis.conf
7)检测redis是否启动成功:
8)kill -9+进程ID
(359条消息) Redis设置开机自启动_小码助力助你前行的博客-CSDN博客
这是图形化界面安装教程(359条消息) 一、Redis入门之——介绍、安装,图形化界面(GUI)工具Redis Desktop Manager (RDM)安装_redis图形化界面_程序员在线炒粉8元1份顺丰包邮送可乐的博客-CSDN博客



二)redis的连接
启动redis:redis-server redis.conf
1)链接redis:在bin目录下面使用 redis-cli -h 127.0.0.1 -p 6379 -a 12503487来进行连接redis,前提是你必须提前启动了redis
2)表示当前没有权限, redis-cli -h 127.0.0.1 -p 6379
AUTH+密码

三)redis常见通用的命令:
redis一般是一个Key-Value的数据库,Key一般是String类型,但是value的类型多种多样
可以通过help @hash/generic/来查看帮助手册

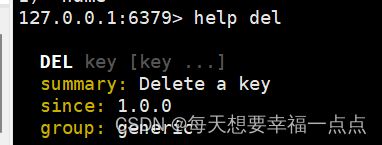
常用命令:help+commond可以查看一个命令的具体用法
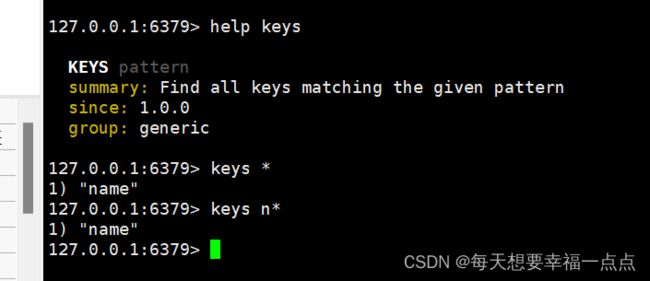
1)keys+patten:查看符合模版的所有key,查看帮助文档就是help keys,*代表所有
底层是使用模糊匹配查询,搜索会很长时间,redis是单线程,在生产环境下不适合使用
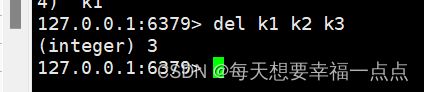
2)del:删除固定的key,返回值表示删除的个数
3)exists+key值,返回值表示存在几个
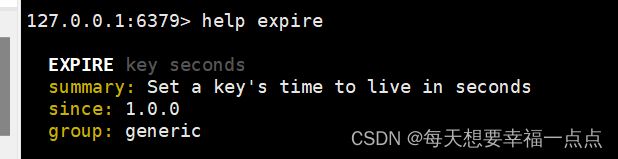
4)expire+key+seconds(key表示给谁设置有效期,seconds表示有效期的时长是多少)
给key设定一个有效期,有效期到期的时候这个key会自动删除
set name zhangsan ex 10
5)TTL+Key值表示查看key的剩余有效时间
-1代表永远存在,-2表示不存在

一)String类型
String类型也就是字符串类型,是redis中最简单的数据类型,其value是字符串,不过根据字符串的格式不同,又可以分成三类,不管是哪一种格式,在底层都是使用字节数组进行存储,只不过是编码形式不同,字符串类型的最大空间不能超过512M
1.1)String就是普通字符串
1.2)int:整数类型,可以做自增,自减操作
1.3)float:浮点类型,可以做自增,自减操作
String类型的常见命令:
1)set:添加或者修改已经存在的String类型的键值对
2)get:根据key获取String类型的value
3)mset:批量添加多个String类型的键值对,返回值就是多个值形成的一个数组
4)incr:让一个整形的key自增1
5)incrby:让一个整形的key并指定步长,比如说incrby num 2,就是在让num的值自增2,可以使用正数也可以使用负数
6)incrbyfloat:让一个浮点类型的数字自增并且指定步长
7)setnx:添加一个String类型的键值对,前提是这个key不存在,否则不执行,真正的新增功能,等同于set key value nx
8)setex:添加一个String类型的键值对,并且指定有效期,setex key seconds value
set key seconds ex+时间
相当于是一个组合命令:set key expire+时间


二)key的层级格式:
1)因为redis中没有类似于MYSQL这样的Table的概念,如何来进行区分不同类型的Key呢?
比如说需要进行存储用户商品信息到redis,有一个用户ID是1,那么此时还有一个商品ID也是1
解决方案:Redis中的key是允许有多个单词组成层级结构,多个单词之间使用冒号来分开,格式如下:
项目名称:类型:ID的值
2)假设此时我们有一个项目名称叫做:BlogSystem,有user和blog两种不同的类型的数据,我们就可以这样来定义Key:
存放user相关的Key=value
BlogSystem:user:1=‘{id:"1","username:"zhangsan",password:"123456"}’
存放product相关的Key=value:
BlogSystem:product:1=‘{"id":1,"productname":"小米“,productprice:"20"}’
vaue值是把Java对象序列化成字符串的结果,如果说value是一个JAVA对象,那么可以将对象序列化成JSON字符串之后进行存储
set BlogSystem:user:1 '{id:"1",username:"zhangsan",password:"123456"}'
set BlogSystem:user:2 '{id:"2","username:"lisi",password:"123"}'
set BlogSystem:product:1 '{id:"1","productname":"小米“,productprice:"20"}'
set BlogSystem:product:2 '{id:"2","productname":"华为“,productprice:"30"}'
在图形化界面就可以形成了正常的层级结构,就实现了Key的分级存储
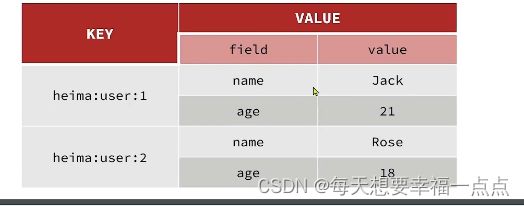
三)Hash类型
hash类型,也叫做散列,类似于Java中的HashMap
之前学习过的String结构是将对象序列化之后形成JSON格式的字符串来进行存储,但是当我们进行修改某一个字段的时候并不方便
但是此时哈希结构可以将对象中的每一个字段单独来进行存储,可以针对单个字段来做CRUD
常见的命令:
1)hash key field value:添加或者修改hash类型中的key的field的值
2)hget key filed:获取一个hash类型的key的fileld的值
3)hmset:批量添加多个hash类型的key的fileld的值
4)hmget:批量获取多个hash类型的key的filed的值
5)hgetall:获取一个hash类型的key的key中的所有field和value
6)hkeys:获取一个hash类型的key中的所有field的值
7)hvalues:获取一个hash类型的key中的所有value
8)hincrby:让一个hash类型的key的字段值自增并指定步长
9)hsetnx:坦加一个hash类型的key的field值,前提是这个field不存在,否则不执行
一)hset product:user:1 name zhangsan
hset+key+key.fileld+key.value
二)hget product:user:1 name
hget key+key.field
三)hmset product:user:1 name jackon age 10 classID 19 idadmin 1
上面就是一个id为1的用户,向数据库中存入了名字是jackon,classID是19,isadmin为1的用户信息
hmset key key.field1 key.value1 key.field2 key.value2 key.field3 key.value3
四)hmget product:user:1 name age classID isadmin
hmget key key.field1 key.field2 key.field3
五)hgetall product:user:1
hgetall+key值六) hincrby product:user:1 number 30
hincrby key值 key.field 要进行自增的值,后面也是可以是一个负数
七)hsetnx product:user:2 number 40


四)List类型:常用的是保存有序的顺序
redis中的List类型和Java中的LinkedList类型相似,可以看作是一个双向链表,既可以支持正向检索还可以支持反向检索,特征也是和LinkedList相似
1)有序
2)元素可以重复
3)插入和删除速度比较快
4)查询速度一般
常用命令:
1)lpush list名字 element.....向列表左侧插入一个或者多个元素
2)lpop list名字 数量 移除并返回列表中的第一个或者多个元素元素,没有那么直接返回null
3)rpush list名字 element:向列表右侧插入一个或者多个元素
4)rpop list名字 element:移除并返回列表右侧的第一个元素
5)lrange list名字 star end:返回一段角标范围内的所有元素
6)blpop brpop:和lpop和rpop类似,只不过是在没有元素的时候等待指定时间,而不是直接返回null,B表示阻塞;

1)lpush users 1 2 3,users代表list的名字
2)rpush users 4 5 6,users代表list的名字
3)lpop users 4,取出users这个list中的四个元素并且返回删除
4) blpop users 10,表示取出users这个list中的一个元素,如果没有等待10s后进行返回
如何使用list数据结构来模拟一个栈?
栈是一种先进后出的数据结构,入口和出口在同一边,rpush和rpop就是栈
如何使用list数据结构来模拟一个队列?
队列是一种先进后出的数据结构,入口和出口不在同一边,rpush和lpop就是队列
如何使用list数据结构来模拟一个阻塞队列?
首先是队列,况且入口和出口在不同边,blpop,brpop
五)redis的Set类型
redis中的Set集合是和Java中的HashSet类似,可以看作是一个value=null的HashMap,也是一个哈希表,因此也具备和HashSet类似的特征
没有顺序,元素不可重复,查找快,支持交集,并集,差集等功能
常见命令:
1)sadd key number:向Set中添加一个或者多个元素
2)srem key number:移除set中的指定元素
3)scard key:返回set集合中的元素的个数
4)sismember key number:判断一个元素是否存在于Set中
5)smembers:获取Set中的所有的元素
6)sinter key1 key2求key1和key2两个元素集合的交集
7)sdiff key1 key2求key1和key2两个元素的差集,就是求key1里面存在的但是key2里面不存在的
8)union key1 key2:求key1和key2的并集
1)sadd set 1 2 3
2)srem set 1
3)scard set4)sismember set 1
5)smembers set
1)sadd set1 lisi wangwu zhaoliu
2)sadd set2wangwu mazi ergou
3)scard set1
4)sinter set1 set2
5)sdiff set1 ste2
6)union set1 set2

六)SortedSet类型:
redis的SortSet是一个可以进行排序的set集合,和JAVA中的TreeSet有些类似,但是底层的数据结构差异却非常大,SortedSet中的每一个元素都带有一个Score属性,底层的实现是一个跳表加上哈希表,SortedSet具备以下特性:
可以进行排序
元素不重复
查询速度快
因为SortedSet这样的可排序特性,经常用来实现排行榜这样的功能
SortedSet中的常见命令:
1)zadd key score mumber:添加一个元素或者多个元素到sortedSet,如果已经存在那么直接更新SortedSet的值
2)zrem key mumber:删除SortedSet中的一个指定元素
3)zscore key mumber:获取到SortedSet中的指定元素的score值
4)zrank key mumber:获取到SortedSet中指定元素的排名
zrevrank key mumber:降序排名
5)zcard key:获取到sortedset中的元素个数
6)zcount key min max:统计score值在给定范围内所有元素的个数,查询的是数量
7)zincrby key increment member:让sortSet中的元素自增,步数为指定的increment值
8)zrange key min max:按照score排序之后,获取指定排名范围之内的元素,查询的是具体的元素,默认是升序
zrevrange默认是降序
9)zrangebyscope key min max:按照score排序之后,获取指定score范围内的元素
10)zdiff zinter zunion:求交集,差集,并集
这里面的key是 student
1)zadd student 85 jack 89 lucy 82 rose 95 tom 78 jerry 92 amy 76 miles
2)zrem student tom;
3)zrank student rose;
4)zcount student 0 80
5)zincrby student 2 tom
6)zrange student 0 2:获取0-2名的元素
7)zrevrange student 0 2:获取倒序的0-2的元素
8)zrangebyscore student 0 80查找出从0-80分的所有同学