编译原理实验——使用x86汇编、C、Java、Python、Haskell进行快速排序并分析效率
文章目录
- 省流
- 代码和配置思路
-
- x86汇编
-
- irvine32.inc
- 头文件冲突
- 代码
- C++、Java、Python
- haskell
-
- 建议用Linux
- 配置和踩坑
- 代码,无
省流
编译原理实验:
要求给定一个特定的功能,分别使用 C/C++、Java、Python 和 Haskell 实现该功能,对采用这几种语言实现的编程效率,程序的规模,程序的运行效率进行对比分析。例如分别使用上述几种语言实现一个简单的矩阵乘法程序,输入两个矩阵,输出一个矩阵,并分析相应的执行效果。
代码其实并不难,C,Java,Python一抓一大把,即便是x86和Haskell,网上也有很多代码可以借鉴,都是程式化的东西,大家写的都差不多。
难点在于x86汇编和haskell的环境配置。我的建议是,用linux系统跑,不然haskell会折磨的你很痛苦,我光是配环境就配了一天多,而舍友用Linux很快就搞定了。
代码和配置思路
测试不同的数据规模有两种思路:
- 同样的算法,不同规模的数据。
- 同样的数据,不断重复核心代码,不同规模的重复。
比如,对50个数据快排10000次。我就是采用这种重复的方法测试的,效果也不错,写起来比生成数据容易,毕竟x86这东西文件读写很麻烦,反之重复就用一个loop就可以。
x86汇编
x86汇编的难度在于环境搭建。最开始自然是建立一个空项目,然后配置masm32的项目依赖。到此时,你自己写一个hello world就可以成功。
irvine32.inc
但是后面网上x86的代码常常会用到irvine32.inc,尤其是要统计程序时间的时候,需要用到的一个函数就是irvine32.inc里的。
所以首先你要获取到irvine32.inc,把他放到masm32的include文件夹里。
irvine32.inc获取
头文件冲突
其次,irvine32.inc本质上就是个头文件,如果你还有自己写的头文件(比如下面这个网站的代码),就可能出现冲突,报错就是can not resolve,此时把自己写的头文件里和irvine32头文件里声明冲突的部分就好。
代码
这个是参考。
汇编排序
在实际应用过程中,导入irvine32后会出现头文件冲突,因此我修改了head.inc。同时,因为我是要反复快排的,所以我还增加了初始化的代码,我的初始化原则是逆序,比如50个数据就是50,49,······,2,1。而快排的结果是正序,所以整个过程就是在反复的初始化逆序,排序到正序。
到这里,汇编就可以成功运行快排并且实现运行时间统计的功能。
main.asm,主文件
TITLE It is Main function
.386
.MODEL flat,stdcall
Include Irvine32.inc
INCLUDE head.inc
Includelib Irvine32.lib
Includelib kernel32.lib
Includelib user32.lib
.data
pArray SDWORD 50 dup(?)
len SDWORD ($-pArray)/4
startTime DWORD ?
endTime DWORD ?
.code
start:
;------------------------------------------------
;初始化
INVOKE Init,ADDR pArray,len
mov EAX,OFFSET pArray
mov ECX,len
P1:
INVOKE PrintNumber,[EAX]
ADD EAX,4
LOOP P1
;测速
INVOKE GetMseconds
mov startTime,eax ;初始时间
mov ecx,10000 ;循环核心代码次数
kernel:
;恢复初始逆序状态
INVOKE Init,ADDR pArray,len
;排序到顺序
INVOKE QuickSort,ADDR pArray,len
loop kernel
INVOKE GetMseconds ;结尾时间
mov endTime,eax
;输出结果
;------------------------------------------------
mov EAX,OFFSET pArray
mov ECX,len
P2:
INVOKE PrintNumber,[EAX]
ADD EAX,4
LOOP P2
mov eax,endTime
sub eax,startTime
INVOKE writeint
INVOKE ExitProcess,0
end start
head.inc,这是头文件,声明了函数原型
ExitProcess PROTO, dwExitCode:DWORD ;Windows API
GetStdHandle PROTO, nStdHandle:DWORD ;Windows API
PrintNumber PROTO, inputNumber:SDWORD
BubbleSort PROTO, pArray:PTR SDWORD,
len : SDWORD
HeapSort PROTO, pArray : PTR SDWORD,
len : SDWORD
AdjustHeap PROTO, pArray : PTR SDWORD,
len : SDWORD,
rootIndex : SDWORD
Init PROTO, pArray : PTR SDWORD,
len : SDWORD
QuickSort PROTO, pArray : PTR SDWORD,
len : SDWORD
QuickSortRecursion PROTO,pArray:PTR SDWORD,
headIndex : SDWORD,
tailIndex : SDWORD
PrintNumber.asm,一个文件,里面实现了数字打印的函数。
TITLE Print Number
.386
.MODEL flat,stdcall
INCLUDE head.inc
.code
PrintNumber PROC USES eax ecx edx esi edi,
inputNumber:SDWORD
LOCAL IsNegative:DWORD,
outputBuffer[13]:BYTE,
handle:DWORD,
charWritten:DWORD
;Decide if inputNumber is a negative number,
;if it is, then IsNegative=1,inputNumber=-inputNumber
mov IsNegative,0
bt inputNumber,31
jnc L1
mov IsNegative,1
neg inputNumber
L1:
mov EAX,inputNumber
mov EDX,0
;EDI will be the dividend.
mov EDI,10
lea ESI,outputBuffer
;"line break" is insert at the end of outputBuffer
mov [ESI+11],BYTE PTR 0Ah
mov [ESI+12],BYTE PTR 0Dh
;ECX is the current index of outputBuffer
mov ECX,11
;convert inputNumber to chars and store it into outputBuffer.
L2:
div edi
add EDX,'0'
dec ECX
mov [ESI+ECX],DL
mov EDX,0
cmp EAX,0
jnz L2
;if inputNumber is negative number, insert '-' at front of string
cmp IsNegative,0
jz L3
dec ECX
mov [ESI+ECX],BYTE PTR '-'
;print the number
L3:
INVOKE GetStdHandle,-11
mov handle,eax
lea EDX,charWritten
;ESI+ECX is the beginning of printed buffer.
add ESI,ECX
;len of printed buffer = 13-ECX
sub ECX,13
neg ECX
INVOKE WriteConsoleA,handle,ESI,ECX,EDX,0
ret
PrintNumber ENDP
END
QuickSort.asm,实现了初始化和快排。
TITLE Quick Sort
.386
.MODEL flat,stdcall
INCLUDE Head.inc
.code
Init PROC USES eax ecx esi,
pArray:PTR SDWORD,
len:SDWORD
mov ecx,len
mov eax,pArray
mov esi,0
L1:
mov [eax+4*esi],ecx
inc esi ;指针右移
loop L1
ret
Init ENDP
QuickSort PROC USES eax ,
pArray:PTR SDWORD,
len : SDWORD
mov eax,len
dec eax
INVOKE QuickSortRecursion,pArray,0,eax
ret
QuickSort ENDP
QuickSortRecursion PROC USES eax ebx ecx esi edi,
pArray : PTR SDWORD,
headIndex : SDWORD,
tailIndex : SDWORD
mov EAX,pArray
mov ESI,headIndex
mov EDI,tailIndex
mov EBX,[EAX+4*ESI]
;ESI = left pointer, EDI = right pointer, EBX= middle number
L1:
CMP ESI,EDI
jge L4
L2:
cmp ESI,EDI
jge L4
cmp EBX,[EAX+4*EDI]
jg E1
dec EDI
jmp L2
E1:
mov ECX,[EAX+4*EDI]
mov [EAX+4*ESI],ECX
inc ESI
L3:
cmp ESI,EDI
jge L4
cmp EBX,[EAX+4*ESI]
jl E2
inc ESI
jmp L3
E2:
mov ECX,[EAX+4*ESI]
mov [EAX+4*EDI],ECX
dec EDI
jmp L1
L4:
mov [EAX+4*ESI],EBX
dec ESI
inc EDI
cmp ESI,headIndex
jle L5
INVOKE QuickSortRecursion,pArray,headIndex,ESI
L5:
cmp EDI,tailIndex
jge END1
INVOKE QuickSortRecursion,pArray,EDI,tailIndex
END1:
ret
QuickSortRecursion ENDP
END
C++、Java、Python
这几个简单的很,都是一刀流。
C
#includeJava
public class Main {
public static void main(String[] args) {
int LEN=50;
int[] array = new int[LEN];
init(array,LEN);
print(array,LEN);
long start = System.currentTimeMillis();
for(int i=0;i<100;i++){
init(array,LEN);
sort(array,0,LEN-1);
}
long end = System.currentTimeMillis();
print(array,LEN);
double cost = (end - start) / 100.0; // 单位转换为秒
System.out.println("cost time = " + cost + "s");
}
public static void print(int[] arrays,int len){
for(int i=0;i<len;i++){
System.out.println(arrays[i]);
}
}
public static void init(int[] arrays,int len){
for(int i=0;i<len;i++){
arrays[i]=len-i;
}
}
public static void sort(int[] arrays, int left, int right) {
if(left > right) {
return;
}
int l = left;
int r = right;
int pivot = arrays[left];
int temp = 0;
while(l < r) {
while(pivot <= arrays[r] && l < r) {
r--;
}
while(pivot >= arrays[l] && l < r) {
l++;
}
if(l <= r) {
temp = arrays[r];
arrays[r] = arrays[l];
arrays[l] = temp;
}
}
arrays[left] = arrays[l];
arrays[l] = pivot;
sort(arrays, left, l - 1);
sort(arrays, l + 1, right);
}
}
Python
import time
def Qsort(arr):
if len(arr) > 1:
pivot = arr[len(arr) - 1]
l, h = [], []
arr.remove(pivot)
for ele in arr:
if ele >= pivot:
h.append(ele)
else:
l.append(ele)
return Qsort(l) + [pivot] + Qsort(h)
else:
return arr
res = []
times = 100
data_scale=50
start = time.time()
for i in range(times):
test_arr = list(range(data_scale))[::-1] # 逆序
res = Qsort(test_arr)
end = time.time()
print(res)
print(end-start)
haskell
建议用Linux
Haskell在windows下很难配置,再说一次,建议你去Linux,已经写好的代码在Linux上都可以轻松复现,也不用担心前功尽弃。我就这么说吧,前面4种语言+报告,顶多一天也就搞定了,而你要是在Windows上卡一整天,那就真的是亏死,时间翻倍。
配置和踩坑
Stack官方介绍
haskell是一门语言,对应很多工具。其中,stack是一个比较好的平台,可以方便的下载编译器,环境依赖。
听起来不错,但是呢,学了这么久编程,像haskell这么多bug的东西我还是头一次见到。其安装过程究极麻烦,而且容易出现各种问题,我就踩了好多坑,在这里我给出参考文章,并且指出可能出现问题的地方:
【VS Code】Windows10下VS Code配置Haskell语言环境
- 这篇文章整体上,是先配置haskell环境,再在vs code中通过插件导入这个环境。过程中会出现很多问题,不是人的问题,是haskell生态本身就不行,小众东西太容易出问题了。坑的是,不同人电脑不一样,就算是同一个人的电脑,前后输入同样的指令,可能第一次的bug第二次就没了,很奇怪。
- 网络问题。这篇文章里经常会在命令行里进行各种下载,第二节开头给出了一些命令,比如stack new 项目(在项目虚拟环境里安装ghc),或者直接在全局环境安装ghc,此时就会出现网络问题。即使是你开了全局代理,也没有用,命令行里是无法下载的,还是有网络报错。此时就一定要先按照第二步后面的设置配置清华源,再去进行第三步的setup命令(同第二步开头)。
- 版本问题。即使是你下载成功,你stack new成功,之后在stack build的时候有可能出现问题。
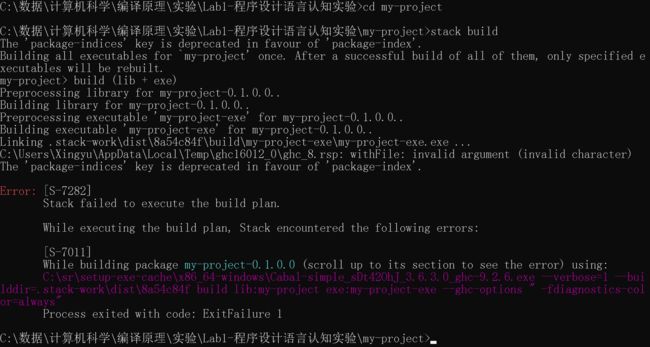
这个问题的原因在于stack lts版本和ghc不对应。比如你最开始在全局锁定了18.8的lts版本(对应8.10.6的ghc),之后再stack new一个新环境,此时这个新环境里你没有指定版本,所以默认下载的是9.2.6的ghc,但是你在主环境里已经指定了18.8的lts版本了,所以你new的虚拟环境也是18.8的lts版本。问题就在这里,虚拟环境里的lts版本和ghc不对应,所以就报错。即使是你把主环境的lts锁定会20.12,也没用,new出来的还会报错。
此时有两种办法。
1:在全局环境里锁定lts版本,和ghc版本对上,之后你new的环境里,lts版本理论上应该就是锁定后的版本了,对应ghc。
2:理论是理论,实践是实践。锁定主环境后,new的环境可能还会出问题,此时你应该进入你new的环境里,在虚拟环境里锁定lts版本,与ghc版本对上,此时build时,代号7282和7011的bug就会消除。

- 路径问题。解决了版本问题后,还有代号6602的问题。

用人话翻译一下就是,读取不到这个文件,但是你点进去看,这个文件是存在的。所以问题在于路径里带了中文,这是个很经典的错误,qt这个软件也会出这种错。解决办法就是去纯英文路径里重新new一个项目,这个时候你就会发现这个bug也没了。此刻我只想狠狠吐槽haskell,bug真多。
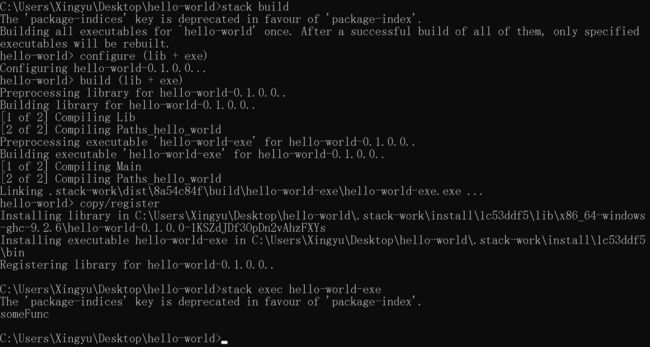
- 库的安装。如果你环境里没有库,肯定就跑不了复杂的代码,这是常识。但是haskell难点在于,怎么下载,安装库。我的建议是去看官方文档,我知道你很急,但是这也没办法。【官方文档】
添加依赖,大致上是先用stack install下载库,之后在package.yaml里添加依赖。或者直接添加也行,官网里就是,说明他会自动下载依赖。需要注意的是,package.yaml里有三个dependencies:,我们选择最开始那个,剩下两个都时局部的,第一个是整个项目级别的。
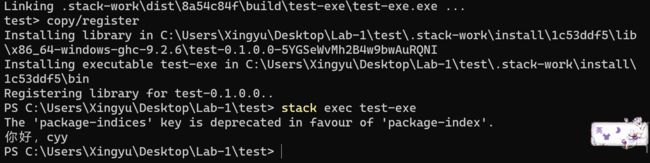
- [S-7282]报错。此时你再跑一个代码,又会出错。

一种原因是,{-# LANGUAGE OverloadedStrings #-},这个东西一定要有,他不是注释,如果去掉就会报上面的错。

但是呢,在我从网上找的代码里加上这个以后,还是会出现这种问题,后面就折腾linux去了,代码也就不放出来了。
代码,无
代码不放出来了,后面去折腾linux。
我武断地将 haskell 里 bug 多的问题归结于生态差。其实 haskell 生态不差,Haskell 真正的问题是 windows 兼容性差,容易出错。后面又去 linux 上试了一下,很快就通了,由此可见,Windows 或许不太适合程序员这个职业,他更多的是提供一个窗口界面,供普通用户或者程序员日常使用,真要工作起来,为了避免各种不兼容,还是应该用 linux。