【CV】MLP-Mixer:用于CV任务的全 MLP 架构
论文名称:MLP-Mixer: An all-MLP Architecture for Vision
论文下载:https://arxiv.org/abs/2105.01601
论文年份:NeurIPS 2021
论文被引:284(2022/05/03)
论文代码:https://github.com/google-research/vision_transformer(torch)
论文总结
Mixer Layers:
Mixer 使用两种类型的 MLP 层:通道混合 MLP 和标记混合 MLP。
-
通道混合 MLP 允许不同通道之间的通信;它们独立地对每个标记进行操作,并将表的各个行作为输入。
-
标记混合 MLP 允许不同空间位置(标记)之间的通信;它们独立地在每个通道上运行,并将表的各个列作为输入。
这两种类型的层是交错的,以实现两个输入维度的交互。
Mix Feature:
现代深度视觉架构由混合特征(i)在给定空间位置,(ii)在不同空间位置之间,或同时混合两种特征的层组成。
-
在 CNN 中,(ii) 使用 N × N 卷积(对于 N > 1)和池化来实现。更深层的神经元具有更大的感受野 [1, 28]。1×1 卷积也执行 (i),更大的内核执行 (i) 和 (ii)。
-
在 Vision Transformers 和其他基于注意力的架构中,自注意力层执行 (i) 和 (ii) 以及 MLP 块执行 (i)。
-
Mixer 架构背后的想法是明确区分每个位置(通道混合)操作(i)和跨位置(标记混合)操作(ii)。
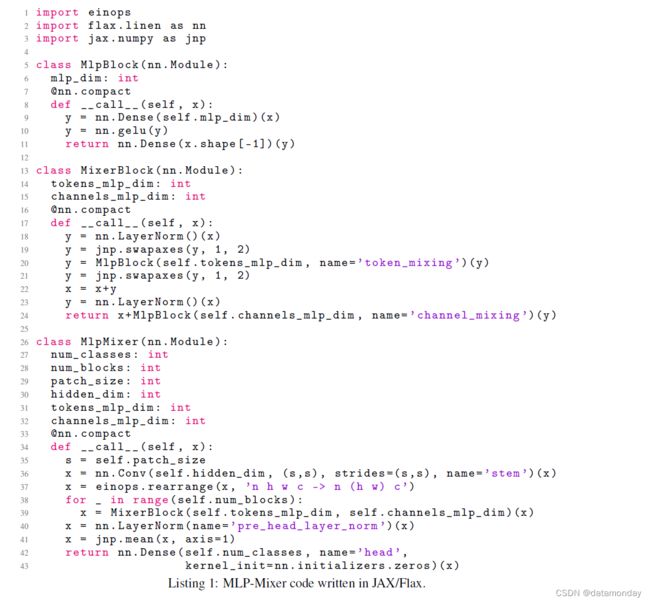
MLP-Mixer 实现代码
Abstract
Convolutional Neural Networks (CNNs) are the go-to model for computer vision. Recently, attention-based networks, such as the Vision Transformer, have also become popular. In this paper we show that while convolutions and attention are both sufficient for good performance, neither of them are necessary. We present MLP-Mixer, an architecture based exclusively on multi-layer perceptrons (MLPs). MLP-Mixer contains two types of layers: one with MLPs applied independently to image patches (i.e. “mixing” the per-location features), and one with MLPs applied across patches (i.e. “mixing” spatial information). When trained on large datasets, or with modern regularization schemes, MLP-Mixer attains competitive scores on image classification benchmarks, with pre-training and inference cost comparable to state-of-the-art models. We hope that these results spark further research beyond the realms of well established CNNs and Transformers.
卷积神经网络 (CNN) 是计算机视觉的首选模型。最近,基于注意力的网络,例如 Vision Transformer,也变得流行起来。在本文中,我们展示了虽然卷积和注意力都足以获得良好的性能,但它们都不是必需的。我们提出了 MLP-Mixer,一种完全基于多层感知器 (MLP) 的架构。 MLP-Mixer 包含两种类型的层:一种是 MLP 独立应用于图像块(即“混合”每个位置特征),另一种是 MLP 跨块应用(即“混合”空间信息)。当在大型数据集上或使用现代正则化方案进行训练时,MLP-Mixer 在图像分类基准上获得有竞争力的分数,其预训练和推理成本可与最先进的模型相媲美。我们希望这些结果能够引发超越成熟的 CNN 和 Transformer 领域的进一步研究。
1 Introduction
正如计算机视觉的历史所表明的那样,更大数据集的可用性以及计算能力的提高通常会导致范式(paradigm)转变。虽然卷积神经网络 (CNN) 已成为计算机视觉的事实标准,但最近Vision Transformers [14] (ViT),一种基于自注意力层的替代方案,获得了最先进的性能。 ViT 延续了从模型中去除手工制作的视觉特征和归纳偏差的长期趋势,并进一步依赖于从原始数据中学习。
我们提出了 MLP-Mixer 架构(或简称“Mixer”),这是一种具有竞争力但在概念上和技术上简单的替代方案,它不使用卷积或自注意力。相反,Mixer 的架构完全基于在空间位置或特征通道上重复应用的多层感知器 (MLP)。 Mixer 仅依赖于基本的矩阵乘法例程(matrix multiplication routines)、数据布局(data layout)的更改(重塑和转置)以及标量非线性(scalar nonlinearities)。
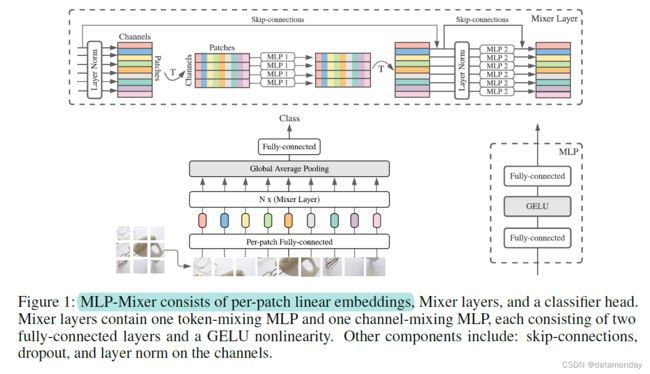
图 1 描述了 Mixer 的宏观结构。它接受一系列线性投影的图像块(也称为标记(tokens)),形状为**“块×通道”表(“patches × channels” table)作为输入,并保持该维度。 Mixer 使用两种类型的 MLP 层:通道混合 MLP 和标记混合 MLP**。
-
通道混合 MLP 允许不同通道之间的通信;它们独立地对每个标记进行操作,并将表的各个行作为输入。
-
标记混合 MLP 允许不同空间位置(标记)之间的通信;它们独立地在每个通道上运行,并将表的各个列作为输入。
这两种类型的层是交错的,以实现两个输入维度的交互。
在极端情况下,我们的架构可以看作是一个非常特殊的 CNN,它使用 1×1 卷积进行通道混合,并使用全感受野的单通道深度卷积和参数共享进行标记混合。反之则不然,因为典型的 CNN 并不是 Mixer 的特例。此外,卷积比 MLP 中的普通矩阵乘法更复杂,因为它需要对矩阵乘法和/或专门的实现进行额外的成本降低。
尽管简单,Mixer 还是获得了具有竞争力的结果。当在大型数据集(即~100M 图像)上进行预训练时,它在精度/成本权衡方面达到了接近于 CNN 和 Transformers 之前声称的最先进的性能。这包括 ILSVRC2012 “ImageNet”[13] 上 87.94% 的 top-1 验证准确率。当对更适度规模的数据(即~1-10M 图像)进行预训练时,再加上现代正则化技术 [49, 54],Mixer 也取得了强大的性能。然而,与 ViT 类似,它略微缺乏专门的 CNN 架构。
2 Mixer Architecture
现代深度视觉架构由混合特征(i)在给定空间位置,(ii)在不同空间位置之间,或同时混合两种特征的层组成。在 CNN 中,(ii) 使用 N × N 卷积(对于 N > 1)和池化来实现。更深层的神经元具有更大的感受野 [1, 28]。同时,1×1 卷积也执行 (i),更大的内核执行 (i) 和 (ii)。在 Vision Transformers 和其他基于注意力的架构中,自注意力层执行 (i) 和 (ii) 以及 MLP 块执行 (i)。 Mixer 架构背后的想法是明确区分每个位置(通道混合)操作(i)和跨位置(标记混合)操作(ii)。这两个操作都是用 MLP 实现的。图 1 总结了架构。
Mixer 将一系列 S S S 个不重叠的图像块作为输入,每个块都投影到所需的隐藏维度 C C C。这会产生一个二维实值输入表(real-valued input table), X ∈ R S × C X ∈ \R^{S×C} X∈RS×C。如果原始输入图像具有分辨率 ( H , W ) (H, W) (H,W),并且每个补丁(patch)具有 ( P , P ) (P,P) (P,P) 分辨率,则补丁数量为 S = H W / P 2 S = HW/P^2 S=HW/P2。所有补丁都使用相同的投影矩阵进行线性投影。 Mixer 由多个大小相同的层组成,每层由两个 MLP 块组成。
-
第一个是标记混合 MLP:它作用于 X X X 的列(即,它应用于转置的输入表 X T X^T XT),映射 R S → R S \R^S → \R^S RS→RS,并在所有列之间共享。
-
第二个是通道混合 MLP:它作用于 X X X 的行,映射 R C → R C \R^C → \R^C RC→RC,并在所有行之间共享。
每个 MLP 块包含两个全连接层和一个独立应用于其输入数据张量的每一行的非线性。混合器层可以写成如下(省略层索引):

这里 σ σ σ 是逐元素非线性(GELU [16])。 D S D_S DS 和 D C D_C DC 分别是标记混合和通道混合 MLP 中的可调隐藏宽度。请注意, D S D_S DS 的选择与输入补丁的数量无关。因此,网络的计算复杂度与输入块的数量成线性关系,不像 ViT 的复杂度是二次的。由于 D C D_C DC 与块大小无关,因此与典型的 CNN 一样,整体复杂度与图像中的像素数量呈线性关系。
如上所述,相同的通道混合 MLP(标记混合 MLP)应用于 X 的每一行(列)。绑定通道混合 MLP 的参数(在每一层内)是一种自然的选择——它提供了位置不变性,卷积的一个显著特征。但是,跨通道绑定参数的情况要少得多。例如,在某些 CNN 中使用的可分离卷积 [9, 40] 将卷积独立于其他通道应用于每个通道。然而,在可分离卷积中,不同的卷积核被应用于每个通道,这与 Mixer 中的标记混合 MLP 不同,后者为所有通道共享相同的内核(具有完整的感受野)。参数绑定(parameter tying)可防止架构在增加隐藏维度 C 或序列长度 S 时增长过快,并显著节省内存。令人惊讶的是,这种选择不会影响经验表现,见补充 A.1。
Mixer 中的每一层(除了最初的补丁投影层)都接受相同大小的输入。这种 “各向同性 (isotropic)” 设计与 Transformer 或其他领域的深度 RNN 最相似,它们也使用固定宽度。这与大多数具有金字塔结构的 CNN 不同:更深层的输入分辨率较低,但通道更多。请注意,虽然这些是典型设计,但也存在其他组合,例如各向同性 ResNets [38] 和金字塔形 ViTs [52]。
除了 MLP 层之外,Mixer 还使用其他标准架构组件:跳过连接 (skip-connections) [15] 和层规范化 (layer normalization) [2]。与 ViT 不同,Mixer 不使用位置嵌入,因为标记混合 MLP 对输入标记的顺序很敏感。最后,Mixer 使用标准分类头和全局平均池化层,然后是线性分类器。总的来说,该架构可以用 JAX/Flax 紧凑地编写,代码在补充 E 中给出。
3 Experiments
我们评估了 MLP-Mixer 模型在一系列中小型下游分类任务上的性能,这些模型使用中到大型数据集进行了预训练。我们对三个主要量感兴趣:
1)下游任务的准确性;
2)预训练的总计算成本,这对于在上游数据集上从头开始训练模型很重要;
3)测试时间吞吐量,这对从业者很重要。
我们的目标不是展示最先进的结果,而是展示一个简单的基于 MLP 的模型与当今最好的基于卷积和注意力的模型具有竞争力。
下游任务
我们使用流行的下游任务,例如 ILSVRC2012 “ImageNet”(1.3M 训练示例,1k 类),带有原始验证标签 [13] 和清理后的 RealL 标签 [5],CIFAR-10/100(50k 示例,10 /100 个类)[23]、Oxford-IIIT Pets(3.7k 个示例,36 个类)[32]和 Oxford Flowers-102(2k 个示例,102 个类)[31]。我们还使用了视觉任务适应基准(VTAB-1k),它由 19 个不同的数据集组成,每个数据集都有 1k 个训练示例 [58]。
预训练
我们遵循标准的迁移学习设置:预训练,然后对下游任务进行微调。我们在两个公共数据集上预训练我们的模型:ILSVRC2021 ImageNet 和 ImageNet-21k,它是 ILSVRC2012 的超集,包含 21k 类和 14M 图像 [13]。为了在更大范围内评估性能,我们还在 JFT-300M 上进行了训练,这是一个具有 300M 示例和 18k 类的专有数据集 [44]。正如 [14] 和 [22] 所做的那样,我们针对下游任务的测试集对所有预训练数据集进行去重 。我们使用 Adam 以 224 的分辨率对所有模型进行预训练,β1 = 0.9,β2 = 0.999,10k 步的线性学习率预热和线性衰减,批量大小 4096,权重衰减和全局范数 1 的梯度裁剪。对于 JFT- 300M,我们通过应用 [45] 的裁剪技术对图像进行预处理,除了随机水平翻转。对于 ImageNet 和 ImageNet-21k,我们采用了额外的数据增强和正则化技术。特别是,我们使用 RandAugment [12],mixup [60],dropout [43] 和 随机深度 [19]。这组技术的灵感来自 timm 库 [54] 和 [48]。补充 B 中提供了有关这些超参数的更多详细信息。
指标
我们评估模型的计算成本和质量之间的权衡。对于前者,我们计算两个指标:(1) TPU-v3 加速器的总预训练时间,它结合了三个相关因素:每个训练设置的理论 FLOP、相关训练硬件的计算效率和数据效率。 (2) TPU-v3 上图像/秒/核心的吞吐量。由于不同大小的模型可能会从不同的批量大小中受益,因此我们扫描批量大小并报告每个模型的最高吞吐量。对于模型质量,我们关注微调后的 top-1 下游精度。在两种情况下(图 3,右图和图 4),微调所有模型的成本太高,我们报告了通过解决冻结的学习图像表示之间的 '2-regularized 线性回归问题获得的少样本精度和标签。
模型
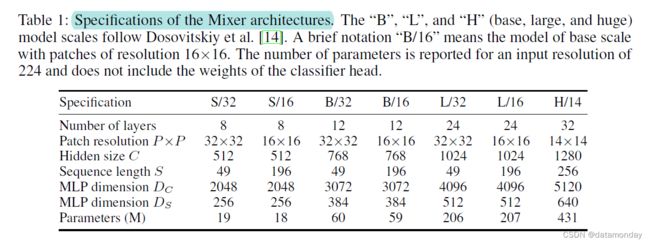
我们将表 1 中总结的 Mixer 的各种配置与最新的、最先进的 CNN 和基于注意力的模型进行比较。在所有图表中,基于 MLP 的 Mixer 模型用粉红色 ( ) 标记,基于卷积的模型用黄色 ( ) 标记,基于注意力的模型用蓝色 ( ) 标记。
-
Vision Transformers (ViTs) 具有类似于 Mixer 的模型比例和补丁分辨率。
-
HaloNets 是基于注意力的模型,它使用具有局部自注意力层而不是 3×3 卷积 [51] 的类似 ResNet 的结构。我们专注于特别高效的“HaloNet-H4 (base 128, Conv-12)”模型,它是更广泛的 HaloNet-H4 架构的混合变体,其中一些自注意力层被卷积取代。请注意,我们将 HaloNets 标记为注意力和卷积标记为蓝色 ( )。
-
Big Transfer (BiT) [22] 模型是针对迁移学习优化的 ResNet。
-
NFNets [7] 是无归一化器的 ResNets,对 ImageNet 分类进行了多项优化。我们考虑 NFNet-F4+ 模型变体。
-
我们将 MPL [34] 和 ALIGN [21] 用于 EfficientNet 架构。
-
MPL 在 JFT-300M 图像上进行了非常大规模的预训练,使用来自 ImageNet 的元伪标签而不是原始标签。我们与 EfficientNetB6-Wide 模型变体进行比较。
-
ALIGN 以对比的方式在嘈杂的网络图像文本对上预训练图像编码器和语言编码器。我们比较了他们最好的 EfficientNet-L2 图像编码器。
-
3.1 Main results
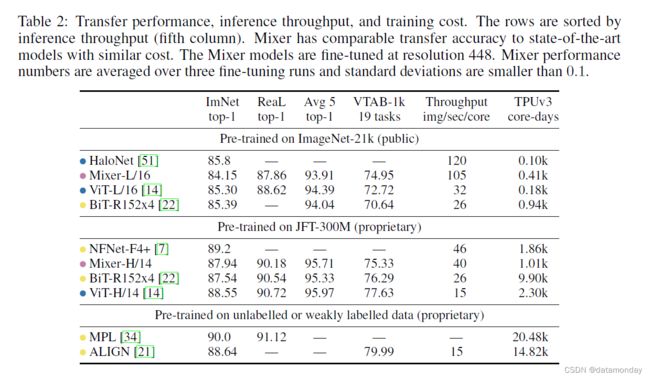
表 2 展示了最大的 Mixer 模型与文献中最先进模型的比较。 “ImNet”和“RealL”列指的是原始 ImageNet 验证 [13] 和清理后的 RealL [5] 标签。“平均5”代表所有五个下游任务(ImageNet、CIFAR-10、CIFAR-100、Pets、Flowers)的平均性能。图 2(左)可视化了准确度计算的边界。当在 ImageNet-21k 上通过额外的正则化进行预训练时,Mixer 实现了整体强大的性能(ImageNet 上 84.15% 的 top-1),尽管略逊于其他模型2。在这种情况下,正则化是必要的,没有它,Mixer 会过拟合,这与 ViT [14] 的类似观察结果一致。在 ImageNet 上从随机初始化训练 Mixer 时也得出同样的结论(参见第 3.2 节):Mixer-B/16 在分辨率为 224 时达到了 76.4% 的合理分数,但往往过拟合。这个分数类似于普通的 ResNet50,但落后于 ImageNet“从头开始”设置的最先进的 CNN/混合,例如 84.7% BotNet [42] 和 86.5% NFNet [7]。
当上游数据集的大小增加时,Mixer 的性能会显着提高。特别是,Mixer-H/14 在 ImageNet 上实现了 87.94% 的 top-1 准确率,比 BiTResNet152x4 好 0.5%,仅比 ViT-H/14 低 0.5%。值得注意的是,Mixer-H/14 的运行速度比 ViT-H/14 快 2.5 倍,几乎是 BiT 的两倍。总体而言,图 2(左)支持我们的主要主张,即在精度计算权衡方面,Mixer 与更传统的神经网络架构具有竞争力。该图还展示了总预训练成本与下游准确性之间的明显相关性,即使跨架构类也是如此。
表中的 BiT-ResNet152x4 是使用 SGD 进行预训练的,具有动量和较长的时间表。由于 Adam 趋向于更快地收敛,我们使用 Dosovitskiy 等人的 BiT-R200x3 模型完成了图 2(左)中的图片。 [14] 使用 Adam 在 JFT-300M 上进行了预训练。这个 ResNet 的准确率略低,但预训练计算量要低得多。最后,该图中还报告了较小的 ViT-L/16 和 Mixer-L/16 模型的结果。
3.2 The role of the model scale
上一节中概述的结果侧重于计算范围高端的(大型)模型。我们现在将注意力转向更小的 Mixer 模型。
我们可以通过两种独立的方式对模型进行缩放:
1)在预训练时增加模型大小(层数、隐藏维度、MLP 宽度)
2)微调时增加输入图像的分辨率。前者影响预训练计算和测试时的吞吐量,后者只影响吞吐量。除非另有说明,微调的分辨率默认设置为 224。
我们将 Mixer 的各种配置(见表 1)与类似规模的 ViT 模型和用 Adam 预训练的 BiT 模型进行比较。结果总结在表 3 和图 3 中。在 ImageNet 上从头开始训练时,Mixer-B/16 达到了 76.44% 的合理 top-1 准确率。这比 ViT-B/16 型号落后 3%。训练曲线(未报告)表明,两个模型都达到了非常相似的训练损失值。换句话说,Mixer-B/16 比 ViT-B/16 更过拟合。对于 Mixer-L/16 和 ViT-L/16 型号,这种差异更加明显。
表 3:Mixer 和文献中其他模型在各种模型和预训练数据集尺度上的性能。 “Avg. 5”表示五个下游任务的平均性能。 Mixer 和 ViT 模型在三个微调运行中取平均值,标准偏差小于 0.15。 (‡) 从在没有额外正则化的 JFT-300M 上预训练的相同模型报告的数字中推断。 (电话) 符号表示通过个人交流获得的 [14] 的作者提供的数字。行按吞吐量排序。

随着预训练数据集的增长,Mixer 的性能稳步提高。值得注意的是,在 JFT-300M 上预训练并以 224 分辨率微调的 Mixer-H/14 仅比 ImageNet 上的 ViT-H/14 低 0.3%,同时运行速度提高 2.2 倍。图 3 清楚地表明,尽管 Mixer 略低于模型尺度下端的前沿,但它自信地位于高端前沿。

3.3 The role of the pre-training dataset size
迄今为止的结果表明,对较大数据集的预训练显着提高了 Mixer 的性能。在这里,我们更详细地研究了这种影响。
为了研究 Mixer 使用越来越多的训练示例的能力,我们在包含 3%、10% 的 JFT-300M 随机子集上预训练 Mixer-B/32、Mixer-L/32 和 Mixer-L/16 模型、233、70、23 和 7 个 epoch 的所有训练示例的 30% 和 100%。因此,每个模型都针对相同的总步数进行了预训练。我们还在更大的 JFT-3B 数据集 [59] 上预训练 Mixer-L/16 模型,该数据集包含大约 3B 图像和 30k 类,总步数相同。
虽然没有严格的可比性,但这使我们能够进一步推断规模的影响。我们使用 ImageNet 上的线性 5-shot top-1 精度作为传输质量的代理。对于每次预训练运行,我们都会根据最佳上游验证性能执行提前停止。结果如图 2(右)所示,其中我们还包括 ViT-B/32、ViT-L/32、ViT-L/16 和 BiT-R152x2 模型。

图 2:左:表 2 中 SOTA 模型的 ImageNet 精度/训练成本 Pareto frontier(虚线)。模型在 ImageNet-21k 或 JFT(标记为 MPL 或为伪标记)或网络图像上进行了预训练文本对。 Mixer 与这些高性能的 ResNet、ViT 和混合模型一样好,并且与 HaloNet、ViT、NFNet 和 MPL 处于前沿。右图:随着数据大小的增长,Mixer(实线)捕获或超过 BiT(虚线)和 ViT(虚线)。曲线上的每个点都使用相同的预训练计算;它们分别对应于在 3%、10%、30% 和 100% 的 JFT-300M 上进行 233、70、23 和 7 个 epoch 的预训练。 ∼3B 的附加点对应于在更大的 JFT-3B 数据集上进行相同总步数的预训练。与 ResNet 甚至 ViT 相比,Mixer 对数据的改进更快。大型 Mixer 和 ViT 模型之间的差距缩小。
当在 JFT-300M 的最小子集上进行预训练时,所有 Mixer 模型都严重过拟合。 BiT 模型也过拟合,但程度较轻,可能是由于与卷积相关的强归纳偏差。随着数据集的增加,Mixer-L/32 和 Mixer-L/16 的性能增长都快于 BiT; Mixer-L/16 不断改进,而 BiT 模型趋于稳定。
同样的结论也适用于 ViT,与 [14] 一致。然而,更大的 Mixer 模型的相对改进更加明显。 Mixer-L/16 和 ViT-L/16 之间的性能差距随着数据规模的扩大而缩小。看起来,Mixer 从不断增长的数据集大小中受益甚至超过了 ViT。人们可以用归纳偏差的不同来推测和解释它:ViT 中的自注意力层导致学习函数的某些属性与真正的底层分布相比,与 Mixer 架构发现的那些属性不太兼容。
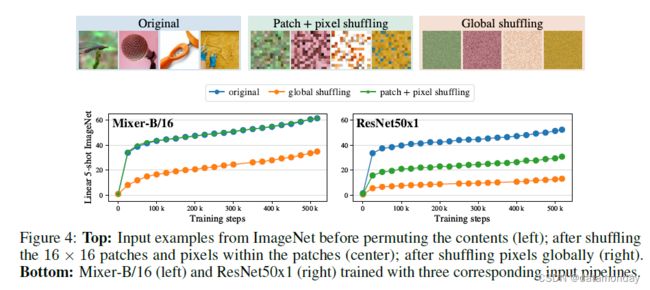
3.4 Invariance to input permutations
在本节中,我们研究了 Mixer 和 CNN 架构的归纳偏差之间的区别。具体来说,我们按照第 3 节中描述的预训练设置并使用两种不同的输入转换之一在 JFT-300M 上训练 Mixer-B/16 和 ResNet50x1 模型:
(1) 打乱 16×16 补丁的顺序并在其中置换像素每个补丁都有一个共享排列;
(2) 对整个图像中的像素进行全局置换。所有图像都使用相同的排列。
图 4(底部)中报告了 ImageNet 上训练模型的线性 5-shot top-1 精度。在图 4 顶部显示了一些原始图像及其两个转换版本。正如所料,Mixer 对补丁的顺序和补丁内的像素是不变的(蓝色和绿色曲线完美匹配)。另一方面,ResNet 的强归纳偏差依赖于图像中特定的像素顺序,当块被置换时其性能显着下降。值得注意的是,当对像素进行全局置换时,与 ResNet 相比,Mixer 的性能下降幅度要小得多(下降 ~ 45%)(下降 ~75%)。
3.5 Visualization

图 5:在 JFT-300M 上训练的 Mixer-B/16 模型的第一个(左)、第二个(中)和第三个(右)标记混合 MLP 中的隐藏单元。每个单元有 196 个权重,每个 14 × 14 个输入补丁一个。我们将这些单元配对,以突出相反相位的内核的出现。对按滤波器频率排序。与卷积滤波器的内核相比,每个权重对应于输入图像中的一个像素,左列的任何图中的一个权重对应于输入图像的特定 16 × 16 块。补充 D 中是完整图。
通常观察到,CNN 的第一层倾向于学习作用于图像局部区域像素的 Gabor 样检测器。相比之下,Mixer 允许在标记混合 MLP 中进行全局信息交换,这就引出了一个问题,它是否以类似的方式处理信息。图 5 显示了在 JFT-300M 上训练的 Mixer 的前三个标记混合 MLP 的隐藏单元。回想一下,标记混合 MLP 允许不同空间位置之间的全局通信。一些学习到的特征作用于整个图像,而另一些则作用于较小的区域。更深层似乎没有清晰可辨的结构。与 CNN 类似,我们观察到许多具有相反相位的特征检测器对 [39]。学习单元的结构取决于超参数。第一个嵌入层的图出现在补充 D 的图 7 中。

4 Related work
MLP-Mixer 是一种新的计算机视觉架构,它不同于以前成功的架构,因为它既没有使用卷积层,也没有使用自注意力层。然而,设计选择可以追溯到 CNN [24,25]和 Transformer [50]的文献。
自从 AlexNet 模型 [24] 超越了基于手工制作图像特征的流行方法 [35] 以来,CNN 一直是计算机视觉的事实标准。许多工作专注于改进 CNN 的设计。
Simonyan 和 Zisserman [41] 证明,可以仅使用具有 3×3 小内核的卷积来训练最先进的模型。
-
[15] 引入了跳跃连接和批量归一化 [20],它可以训练非常深的神经网络并进一步提高性能。
-
一个突出的研究方向已经研究了使用稀疏卷积的好处,例如分组 [57] 或深度 [9, 17] 变体。
-
[55] 本着与我们的标记混合 MLP 类似的精神,在自然语言处理的深度卷积中共享参数。
-
[18] 和 [53] 建议使用非局部操作来增强卷积网络,以部分缓解来自 CNN 的局部处理的约束。
Mixer 将使用带有小内核的卷积的想法发挥到了极致:
-
通过将内核大小减小到 1×1,它将卷积转换为独立应用于每个空间位置的标准密集矩阵乘法(通道混合 MLP)。
-
因为不允许空间信息的聚合,所以应用了密集矩阵乘法,这些乘法应用于所有空间位置的每个特征(标记混合 MLP)。在 Mixer 中,矩阵乘法是在“patches×features”输入表上按行或按列应用的,这也与稀疏卷积的工作密切相关。 Mixer 使用跳跃连接 [15] 和归一化层 [2, 20]。
在计算机视觉中,基于自注意力的 Transformer 架构最初应用于生成建模 [8, 33]。它们在图像识别方面的价值后来得到了证明,尽管结合了类似卷积的局部偏差 [37] 或低分辨率图像 [10]。[14] 介绍了 ViT,这是一种纯 Transformer 模型,具有较少的局部偏差,但可以很好地扩展到大数据。ViT 在流行的视觉基准上实现了最先进的性能,同时保持了 CNN [6] 的鲁棒性。[49] 使用广泛的正则化在较小的数据集上有效地训练了 ViT。 Mixer 借鉴了最近基于 Transformer 的架构的设计选择。 Mixer 的 MLP 块的设计起源于 [50]。将图像转换为一系列补丁并直接处理这些补丁的嵌入源自 [14]。
最近的许多作品都致力于为视觉设计更有效的架构。
-
[42] 用自注意力层替换 ResNets 中的 3×3 卷积。
-
[37],[47],[26] 和 [3] 设计了具有新的注意力机制的网络。
-
Mixer 可以看作是在正交方向上的一个步骤,而不依赖于局部偏差和注意力机制。
本文的工作与 [27] 密切相关。它在 CIFAR-10 上使用全连接网络、大量数据增强和自动编码器预训练获得了合理的性能。 Neyshabur [30] 设计了定制的正则化和优化算法,并训练了一个全连接的网络,在小规模任务上取得了令人印象深刻的性能。相反,我们依赖于标记和通道混合 MLP,使用标准正则化和优化技术,并有效地扩展到大数据。
传统上,在 ImageNet [13] 上评估的网络是使用 Inception 风格的预处理 [46] 从随机初始化中训练出来的。对于较小的数据集,ImageNet 模型的迁移很流行。然而,现代最先进的模型通常使用在较大数据集上预训练的权重,或者使用更新的数据增强和训练策略。例如,
- [14],[22],[29],[34],[56] 都使用大规模预训练推进了图像分类的最新技术。
由于增强或正则化更改而导致的改进示例包括 [11],他们通过学习数据增强获得了出色的分类性能,以及 [4],他们表明,如果使用最近的训练和增强策略,规范的 ResNets 仍然接近最先进的技术。
5 Conclusions
我们描述了一个非常简单的视觉架构。我们的实验表明,在训练和推理所需的准确性和计算资源之间的权衡方面,它与现有的最先进方法一样好。我们相信这些结果提出了许多问题。在实践方面,研究模型学习的特征并确定与 CNN 和 Transformer 学习的特征的主要区别(如果有的话)可能很有用。在理论方面,我们想了解隐藏在这些不同特征中的归纳偏差,并最终了解它们在泛化中的作用。最重要的是,我们希望我们的结果能够引发进一步的研究,超越基于卷积和自注意力的已建立模型的领域。看看这样的设计是否适用于 NLP 或其他领域将会特别有趣。
A Things that did not help
A.1 Modifying the token-mixing MLPs
A.2 Fine-tuning
B Pre-training: hyperparameters, data augmentation and regularization
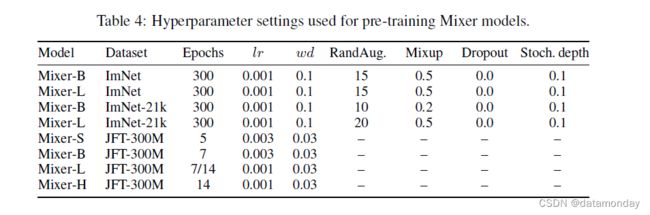
在表 4 中,我们描述了用于预训练 Mixer 模型的最佳超参数设置。对于 ImageNet 和 ImageNet-21k 的预训练,我们使用了额外的增强和正则化。对于 RandAugment [12],我们总是使用两个增强层并在集合 {0,10,15,20} 中扫描幅度 m 参数。对于 mixup [60],我们在集合 {0.0, 0.2, 0.5, 0.8} 中扫描混合强度 p。对于 dropout [43],我们尝试降低 0.0 和 0.1 的速率 d。对于随机深度,与原始论文 [19] 配置相同,将层从 0.0(对于第一个 MLP)下降到 s(对于最后一个 MLP)的概率线性增加,尝试 s ∈ {0.0, 0.1}。最后,分别从 {0.003, 0.001} 和 {0.1, 0.01} 扫描学习率 lr 和权重衰减 wd。
C Fine-tuning: hyperparameters and higher image resolution
D Weight visualizations
E MLP-Mixer code