Leetcode刷题笔记:栈与队列篇
基础知识
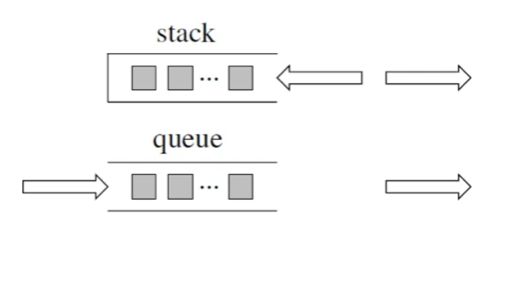
栈和队列的原理大家应该很熟悉了,队列是先进先出,栈是先进后出。
如图所示:
那么我这里再列出四个关于栈的问题,大家可以思考一下。以下是以C++为例,使用其他编程语言的同学也对应思考一下,自己使用的编程语言里栈和队列是什么样的。
- C++中stack 是容器么?
- 我们使用的stack是属于哪个版本的STL?
- 我们使用的STL中stack是如何实现的?
- stack 提供迭代器来遍历stack空间么?
这里我再给大家扫一遍基础知识,
首先大家要知道 栈和队列是STL(C++标准库)里面的两个数据结构。
C++标准库是有多个版本的,要知道我们使用的STL是哪个版本,才能知道对应的栈和队列的实现原理。
那么来介绍一下,三个最为普遍的STL版本:
-
HP STL 其他版本的C++ STL,一般是以HP STL为蓝本实现出来的,HP STL是C++ STL的第一个实现版本,而且开放源代码。
-
P.J.Plauger STL 由P.J.Plauger参照HP STL实现出来的,被Visual C++编译器所采用,不是开源的。
-
SGI STL 由Silicon Graphics Computer Systems公司参照HP STL实现,被Linux的C++编译器GCC所采用,SGI STL是开源软件,源码可读性甚高。
接下来介绍的栈和队列也是SGI STL里面的数据结构, 知道了使用版本,才知道对应的底层实现。
来说一说栈,栈先进后出,如图所示:
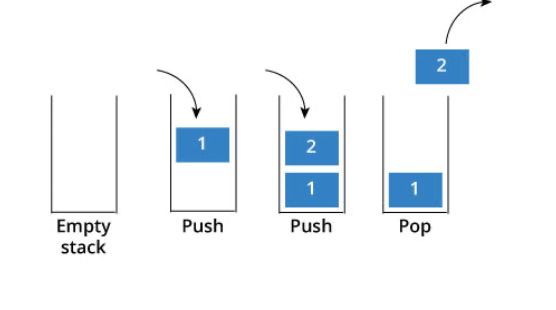
栈提供push 和 pop 等等接口,所有元素必须符合先进后出规则,所以栈不提供走访功能,也不提供迭代器(iterator)。 不像是set 或者map 提供迭代器iterator来遍历所有元素。
栈是以底层容器完成其所有的工作,对外提供统一的接口,底层容器是可插拔的(也就是说我们可以控制使用哪种容器来实现栈的功能)。
所以STL中栈往往不被归类为容器,而被归类为container adapter(容器适配器)。
那么问题来了,STL 中栈是用什么容器实现的?
从下图中可以看出,栈的内部结构,栈的底层实现可以是vector,deque,list 都是可以的, 主要就是数组和链表的底层实现。
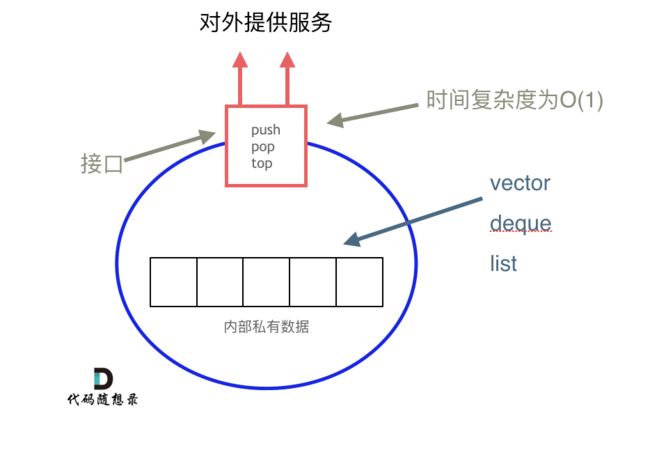
我们常用的SGI STL,如果没有指定底层实现的话,默认是以deque为缺省情况下栈的底层结构。
deque是一个双向队列,只要封住一段,只开通另一端就可以实现栈的逻辑了。
SGI STL中 队列底层实现缺省情况下一样使用deque实现的。
我们也可以指定vector为栈的底层实现,初始化语句如下:
std::stack > third; // 使用vector为底层容器的栈
刚刚讲过栈的特性,对应的队列的情况是一样的。
队列中先进先出的数据结构,同样不允许有遍历行为,不提供迭代器, SGI STL中队列一样是以deque为缺省情况下的底部结构。
也可以指定list 为起底层实现,初始化queue的语句如下:
std::queue> third; // 定义以list为底层容器的队列
所以STL 队列也不被归类为容器,而被归类为container adapter( 容器适配器)。
我这里讲的都是C++ 语言中的情况, 使用其他语言的同学也要思考栈与队列的底层实现问题, 不要对数据结构的使用浅尝辄止,而要深挖其内部原理,才能夯实基础。
1.Leetcode232 用栈实现队列(题解)
难度:⭐️⭐️
这道题是一道很好的模拟题,要求只用stack的基础function(push, pop , top, empty ,size)来实现队列的功能(push, pop peek, empty),最佳解法是双栈法,一个输入栈用于处理push,另一个输出栈用于处理pop/peek。,
在push数据的时候,只要数据放进输入栈就好,但在pop的时候,操作就复杂一些,输出栈如果为空,就把进栈数据全部导入进来(注意是全部导入),再从出栈弹出数据,如果输出栈不为空,则直接从出栈弹出数据就可以了。
// 注意这里有一个细节,只需要判断在输出栈为空的时候,将输入栈的全部元素压入输出栈即可(栈底变队首)
最后如何判断队列为空呢?如果进栈和出栈都为空的话,说明模拟的队列为空了。
具体实现代码。时间均摊复杂度O(1),空间复杂度O(n)。
再多说一些代码开发上的习惯问题,在工业级别代码开发中,最忌讳的就是 实现一个类似的函数,直接把代码粘过来改一改就完事了。
这样的项目代码会越来越乱,一定要懂得代码复用,功能相近的函数要抽象出来,不要大量的复制粘贴,很容易出问题!(踩过坑的人自然懂)
// 比如以后代码局部要修改,只需要修改原代码即可。如果只是复制粘贴,要每个代码都去改,相当麻烦。
工作中如果发现某一个功能自己要经常用,同事们可能也会用到,自己就花点时间把这个功能抽象成一个好用的函数或者工具类,不仅自己方便,也方便了同事们。
同事们就会逐渐认可你的工作态度和工作能力,自己的口碑都是这么一点一点积累起来的!在同事圈里口碑起来了之后,你就发现自己走上了一个正循环,以后的升职加薪才少不了你!哈哈哈
2.Leetcode 225用队列实现栈(题解)
难度:⭐️
和上道题类似, 但是由于栈是LIFO,所以两个栈可以模拟队列,但是由于队列是FIFO,所以不能用同样的思路来解答。但其实用两个队列来实现也是可以的,只不过一个队列就已经够用了。
先说一下双队列:题解给出了一个思路,每次将最后一个元素以外的所有元素压入另一个队列,然后弹出这个最后元素。再从刚才的队列中将这些元素压回来。
我优化了一下,由于每次pop后,总有一个队列为空,所以其实不需要挪回去,只用在每次pop前,加个判断哪个队列不为空的条件,然后对这个队列进行处理即可。具体实现代码。时间复杂度O(n),空间复杂度O(n)。
其实上述步骤完全可以只在单队列中进行,也就是每次从queue弹出时,同时将这个元素重新压入同一个队列的末尾即可。具体代码。时间复杂度O(n),空间复杂度O(n)。
这个解法中,push的复杂度为O(1),pop的复杂度为O(n),题解还提供了另一种写法,push的复杂度为O(n),pop的复杂度为O(1)。具体代码。
3.Leetcode20 有效的括号(题解)
难度:⭐️
括号匹配是经典的用栈解决的问题。由于栈结构的特殊性,非常适合做对称匹配类的题目。
首先要弄清楚,字符串里的括号不匹配有几种情况。
建议在写代码之前要分析好有哪几种不匹配的情况,如果不在动手之前分析好,写出的代码也会有很多问题。
先来分析一下 这里有三种不匹配的情况,
-
第一种情况,字符串里左方向的括号多余了 ,所以不匹配。

-
第二种情况,括号没有多余,但是 括号的类型没有匹配上。

-
第三种情况,字符串里右方向的括号多余了,所以不匹配。

我们的代码只要覆盖了这三种不匹配的情况,就不会出问题,可以看出 动手之前分析好题目的重要性。
动画如下:
还有一些技巧,在匹配左括号的时候,右括号先入栈,就只需要比较当前元素和栈顶相不相等就可以了,比左括号先入栈代码实现要简单的多了!
具体实现代码。时间复杂度O(n),空间复杂度O(n)。
当然,也可以将括号对存入哈希表中,便于查找,简化代码。具体实现代码。时间复杂度O(n),空间复杂度O(n+e),其中e为括号对的数量。
4.Leetcode1047 删除字符串中的所有相邻重复项(题解)
难度:⭐️
本题也是用栈来解决的经典题目。
那么栈里应该放的是什么元素呢?
我们在删除相邻重复项的时候,其实就是要知道当前遍历的这个元素,我们在前一位是不是遍历过一样数值的元素,那么如何记录前面遍历过的元素呢?
所以就是用栈来存放,那么栈的目的,就是存放遍历过的元素,当遍历当前的这个元素的时候,去栈里看一下我们是不是遍历过相同数值的相邻元素。
然后再去做对应的消除操作。 如动画所示:

从栈中弹出剩余元素,此时是字符串ac,因为从栈里弹出的元素是倒序的,所以再对字符串进行反转一下,就得到了最终的结果。
具体代码。时间复杂度O(n),空间复杂度O(n)。
值得一提的话,本题也可以直接用string而非栈来实现,因为string本身也提供了push_back, pop_back的接口,这样就可以简化代码。具体代码。时间复杂度O(n),空间复杂度O(1),注意返回值不计入空间复杂度。
补充:
这道题目就像是我们玩过的游戏对对碰,如果相同的元素挨在一起就要消除。
可能我们在玩游戏的时候感觉理所当然应该消除,但程序又怎么知道该如何消除呢,特别是消除之后又有新的元素可能挨在一起。
此时游戏的后端逻辑就可以用一个栈来实现(我没有实际考察对对碰或者爱消除游戏的代码实现,仅从原理上进行推断)。
游戏开发可能使用栈结构,编程语言的一些功能实现也会使用栈结构,实现函数递归调用就需要栈,但不是每种编程语言都支持递归,例如:
递归的实现就是:每一次递归调用都会把函数的局部变量、参数值和返回地址等压入调用栈中,然后递归返回的时候,从栈顶弹出上一次递归的各项参数,所以这就是递归为什么可以返回上一层位置的原因。
相信大家应该遇到过一种错误就是栈溢出,系统输出的异常是Segmentation fault(当然不是所有的Segmentation fault 都是栈溢出导致的) ,如果你使用了递归,就要想一想是不是无限递归了,那么系统调用栈就会溢出。
而且在企业项目开发中,尽量不要使用递归!在项目比较大的时候,由于参数多,全局变量等等,使用递归很容易判断不充分return的条件,非常容易无限递归(或者递归层级过深),造成栈溢出错误(这种问题还不好排查!)
5.Leetcode150逆波兰表达式求值(题解)
难度:⭐️⭐️
那么来看一下本题,其实逆波兰表达式相当于是二叉树中的后序遍历。 大家可以把运算符作为中间节点,按照后序遍历的规则画出一个二叉树。
但我们没有必要从二叉树的角度去解决这个问题,只要知道逆波兰表达式是用后序遍历的方式把二叉树序列化了,只需用栈去解决这个问题可以了。
具体实现代码,时间复杂度O(n),空间复杂度O(n)。
补充:
我们习惯看到的表达式都是中缀表达式,因为符合我们的习惯,但是中缀表达式对于计算机来说就不是很友好了。
例如:4 + 13 / 5,这就是中缀表达式,计算机从左到右去扫描的话,扫到13,还要判断13后面是什么运算符,还要比较一下优先级,然后13还和后面的5做运算,做完运算之后,还要向前回退到 4 的位置,继续做加法,你说麻不麻烦!
那么将中缀表达式,转化为后缀表达式之后:["4", "13", "5", "/", "+"] ,就不一样了,计算机可以利用栈来顺序处理,不需要考虑优先级了。也不用回退了, 所以后缀表达式对计算机来说是非常友好的。
可以说本题不仅仅是一道好题,也展现出计算机的思考方式。
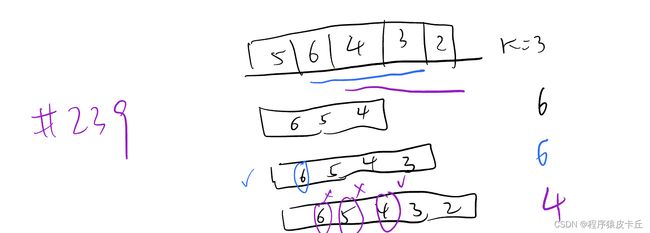
6. Leetcode 239滑动窗口最大值(题解)
难度:⭐️⭐️⭐️⭐️⭐️
这道题算是栈与队列章节让我觉得比较棘手的一道题目了,难点不光是具体的代码实现,更重要的是理解其背后的原理和思想。
一开始容易想到的是暴力解法,先遍历前k个元素完成窗口初始化,然后每次滑动窗口时,都遍历一次整个窗口中的元素,求取并保存最大值到结果数组。这种解法时间复杂度O(n-k+1)*O(k)=O((n-k)*k),空间复杂度O(1)。显而易见会出现超时。具体代码。
接下来想到的优化方案,是尽可能减少遍历时重复求取窗口最大值的次数。滑动窗口类似于单向队列queue的实现,每次窗口右移相当于进行了一次pop最左边的元素和push最右边的元素。那么我们可以用一个变量max来保存当前队列中的最大值,先遍历前k个元素完成窗口初始化,然后在遍历滑动窗口时,每次pop的元素如果不是最大值,或者新加入的元素nums[i]不小于最大值,那我们就只需要pop,push,然后让max=MAX(max, nums[i])即可。反之,如果pop的元素和最大值相等(这时虽然窗口中可能还存在其它也等于这个最大值的元素,但我们无从得知),且新入队元素比最大值小,那么我们需要重新遍历一遍整个窗口,算出新的最大值,更新max的值。(这里有个小细节,遍历的是滑动后的新窗口,即不包含刚弹出的最左边的值(旧最大值),但包含新插入的元素(新窗口最右边大元素),之所以要包含刚插入的元素,是因为它虽然比旧最大值小,但是有可能成为新的最大值的,另外如果k=1时,那每次新窗口的最大值就是它)
通过这种实现方式,每次遍历时,如果弹出的元素不是最大值,且新插入的元素小于最大值,那就直接pop push即可继续滑动,减少了重复计算最大值的次数。时间复杂度在最好的情况下,即nums中的元素全部升序(如:[1,2,3,4,5,6,7,8], k=3)那么只需要每滑动k次,重新计算一次最大值,一共计算最大值的次数为1+(n-k)/k=n/k,因此时间复杂度最好情况为O(k)+O(n-k)*O(1)+O(n)/O(k)*O(k)=O(n),最坏情况为nums中的元素全部降序(如:[8,7,6,5,4,3,2,1], k=3)那么每次滑动时都要重新计算一次最大值,一共计算最大值的次数为O(n-k),因此时间复杂度最坏情况为O(k)+O(n-k)*(1+O(k)=O((n-k)*k),空间复杂度为O(k)。具体代码(含注释)。
可以看出,这种实现方法的最大问题在于,每当弹出的值等于最大值时,都需要重新遍历一遍整个窗口元素计算新的最大值,花费了大量时间。如果我们在弹出旧最大值后,已经知道接下来新的最大值是多少,那么不就不用重新遍历计算了吗?也就是说,在队列中,我们不仅需要保存当前窗口中的最大值,还需要保存所有可能的局部最大值。局部最大值是指,在窗口滑动后,如果原先队首的最大值被弹出,那么这些"局部最大值"将会依次成为新的最大值。为了计算和保存局部最大值,我们采用双端队列deque的数据结构,来构建单调递减队列。单调递减队列是指,队首到队尾的所有元素,单调递减(每个元素小于等于前面的元素)。
具体实现为,每次push新元素前,如果这个元素比当前队列末端的元素大,那就用pop_back将其弹出(这也是用deque的原因),然后继续和新的末端元素做比较,直到小于等于末端元素时,才将新元素push_back到队列末尾,这样就保证了队列元素的单调递减。注意在push的过程中,我们弹出了一些元素,这些元素在后续窗口滑动时,不可能成为最大值,因此它们是否留在队列中并不重要,我们只需要保证队列中包含可能成为新窗口最大值的"局部最大值"元素即可。整个过程中,由于最多push_back和pop_back的元素个数为n,因此整体时间复杂度为O(n)。
说完了push的实现,pop就比较简单易懂了,因为现在我们队列中的队首元素,即为当前窗口的最大值,队列中队首以外的其它元素,即为所有可能成为最大值的"局部最大值"。每当遍历到新待插入元素nums[i]时,即将弹出的旧窗口最左边元素nums[i-k]如果小于队首元素,那么直接进行下次遍历即可(同之前单向队列的处理方式),无须pop,因为这个元素已经在之前push时,被后面进入的比它大的元素给pop_back掉了。而当nums[i-k]正好等于队首元素时(弹出的元素正好是最大值),那么只需要将队首元素弹出pop_front,然后push_back新元素nums[i]入队列并进行单调递减处理,那么此时队列中的新队首元素,即为新窗口的最大值。(相比之前单向队列的重新遍历整个窗口,只需要入队并单调递减处理,整体时间复杂度从O((n-k)*n)降低为O(n))
这种方法在每次遍历滑动窗口时,只需要进行一次pop、一次push、一次find_max操作即可,每次遍历时,pop的时间复杂度为O(1)。push的均摊时间复杂度为O(1)(总共push和pop_back的元素个数最多为n个,总时间复杂度O(n),平均每次复杂度O(1)),find_max的时间复杂度为O(1)。因此,总时间复杂度为O(k)+O(n-k)*O(1)=O(n),空间复杂度为O(k)。具体代码(含注释)。
单调队列方法的精髓在于,每次遍历滑动窗口并插入新元素时,我们只用了均摊时间复杂度O(1)的方法,便求解出了新窗口的最大值,而不需要采用单向队列那样重新遍历窗口所有元素的O(n)方法,大大较少了不必要的时间开销,提高代码运行效率。
以上便是基本思想,当然push的过程中,还有一些细节需要明确:
1.push_back新元素时,如果大于队尾元素时,就先将其pop_back,直到小于等于新队尾元素,再push_back。如果这个新元素比队首元素还大,那它将会pop_back掉队列中的全部元素,并成为新队首。
2.push_back新元素时,如果小于等于队尾元素时,那么直接push_back即可。
3.经过push_back环节后,如果新元素正好等于队首元素,那么它会位于队首元素的后面(不会将其pop掉),也就是说此时队列中存放了两个相同的最大值,即便之后滑动窗口时,将队首的最大值pop_front,此时队列中还保存有另一个最大值,确保了结果的合理性。
补充一下:
有的同学可能会想用一个大顶堆(优先级队列)来存放这个窗口里的k个数字,这样就可以知道最大的最大值是多少了, 但是问题是这个窗口是移动的,而大顶堆每次只能弹出最大值,我们无法移除其他数值,这样就造成大顶堆维护的不是滑动窗口里面的数值了。所以不能用大顶堆。
比如nums[1,3,2,4,5] k=3,第一个窗口最大值为3,如果我们依次把1,3,2压入堆中,不同于队列,它们会打乱顺序存储,而堆的接口priority_queue::pop()只能弹出最大值2,当我们滑动窗口时,需要弹出的元素是1。处理起来就会比较困难。
其实硬要用堆实现,也是可以的。具体思路是,堆中每个元素为(value, index)二元组,滑动窗口遍历到新元素nums[i]时,将其压入堆,判断当前堆顶元素(最大值)的索引是否位于滑动窗口区间[i-k, I-1]内,如果在,那么输出该值为最大值,如果不在,说明这个元素已经在滑动窗口的左侧(失效了),则弹出堆顶元素,直到新堆顶元素位于滑动窗口区间内。具体实现代码。
这个方法的一共会在堆中插入n个元素,最多弹出n-k个元素,时间复杂度最坏为O(nlogn),即nums[i]中元素升序排列,此时每次遍历堆中元素+1且一直没有弹出元素,最好为O(nlogk),即nums[i]中元素降序排列,此时每次遍历都会新增一个元素同时弹出元素,堆中元素数量始终为k。 空间复杂度最坏情况为O(n),最好为O(k)。
这道题目题解还给了一种分块 + 预处理的方法,通过建立前后缀来实现,也十分巧妙。大致思想如下:从nums[0]开始,每k个元素建立一个区间(如:[0,k-1] [k,2k-1], ... ,[ck, n],最后一个区间可能长度不足k),对于任意由k个元素组成的区间[i, i+k-1],如果i不为k的整数倍,那么[i, i+k-1]就会横跨之前建立的区间组。假设i落在[ck, (c+1)k-1]这个区间,令prefix[i]为[ck, i]区间内的最大值,suffix[i]为[i, (c+1)k-1]区间内的最大值。那么区间[i ,i+k-1]的最大值,即为max(suffix[i], prefix[i+k-1])的值。
通过这种方式,我们只需要先遍历一遍nums,求出每个索引i对应的prefix[i]和suffix[i],然后再遍历一遍nums, 求出每个索引i开始的长度为k的区间的最大值max,并保存到结果向量中。具体实现代码。时间复杂度O(n),空间复杂度O(n)。
这道题目真是一道有难度的好题,本来想着单调队列已经够精髓了,没想到还有这么多其它有趣的解法,值得品味。
7.Leetcode 347 前k个高频元素(题解)
难度:⭐️⭐️⭐️⭐️
这道题目主要涉及到如下三块内容:
- 要统计元素出现频率
- 对频率排序
- 找出前K个高频元素
首先统计元素出现的频率,这一类的问题可以使用map来进行统计。
然后是对频率进行排序,这里我们有两种方法。
一种是直接使用sort函数对整个map中的键值对pair
注意这里有个细节,自定义的cmp函数如果定义在类内(类成员函数),那实际上会包含三个参数(含隐藏参数this)而外部函数sort在调用cmp时,只会传入两个参数,会出现参数不匹配的错误。解决方法有四个:1.将cmp定义为静态成员函数2.将cmp定义在类外3.直接用lambda表达式作为sort的第三个参数4.定义函数类,然后将函数类的对象最为第三个参数传入sort。
具体实现代码。时间复杂度O(nlogn),空间复杂度O(n)。
另外一种方法,是使用堆(优先级队列)对键值对进行排序, 针对本体建立小顶堆,将map中的键值对依次传入堆中进行排序,堆内只需要存储k个元素即可,此后每当有新元素加入时,先将其push到堆中排序,然后将堆顶元素弹出,这样就能保证堆中的k个元素为当前已遍历键值对中最大的k个。
什么是优先级队列呢?
其实就是一个披着队列外衣的堆(容器适配器),因为优先级队列对外接口只是从队头取元素,从队尾添加元素,再无其他取元素的方式(无迭代器),看起来就是一个队列。
而且优先级队列内部元素是自动依照元素的权值排列。那么它是如何有序排列的呢?
缺省情况下priority_queue利用max-heap(大顶堆)完成对元素的排序,这个大顶堆是以vector为表现形式的complete binary tree(完全二叉树)。
什么是堆呢?
堆是一棵完全二叉树,树中每个结点的值都不小于(或不大于)其左右孩子的值。 如果父亲结点是大于等于左右孩子就是大顶堆,小于等于左右孩子就是小顶堆。
所以大家经常说的大顶堆(堆头是最大元素),小顶堆(堆头是最小元素),如果懒得自己实现的话,就直接用priority_queue(优先级队列)就可以了,底层实现都是一样的,从小到大排就是小顶堆,从大到小排就是大顶堆。
本题我们就要使用优先级队列来对部分频率进行排序。
为什么不用快排sort呢, 使用快排要将map转换为vector的结构,然后对整个数组进行排序, 而这种场景下,我们其实只需要维护k个有序的序列就可以了,所以使用优先级队列是最优的。
此时要思考一下,是使用小顶堆呢,还是大顶堆?
有的同学一想,题目要求前 K 个高频元素,那么果断用大顶堆啊。
那么问题来了,定义一个大小为k的大顶堆,在每次移动更新大顶堆的时候,每次弹出都把最大的元素弹出去了,那么怎么保留下来前K个高频元素呢。
而且使用大顶堆就要把所有元素都进行排序,那能不能只排序k个元素呢?
所以我们要用小顶堆,因为要统计最大前k个元素,只有小顶堆每次将最小的元素弹出,最后小顶堆里积累的才是前k个最大元素。
寻找前k个最大元素流程如图所示:(图中的频率只有三个,所以正好构成一个大小为3的小顶堆,如果频率更多一些,则用这个小顶堆进行扫描)
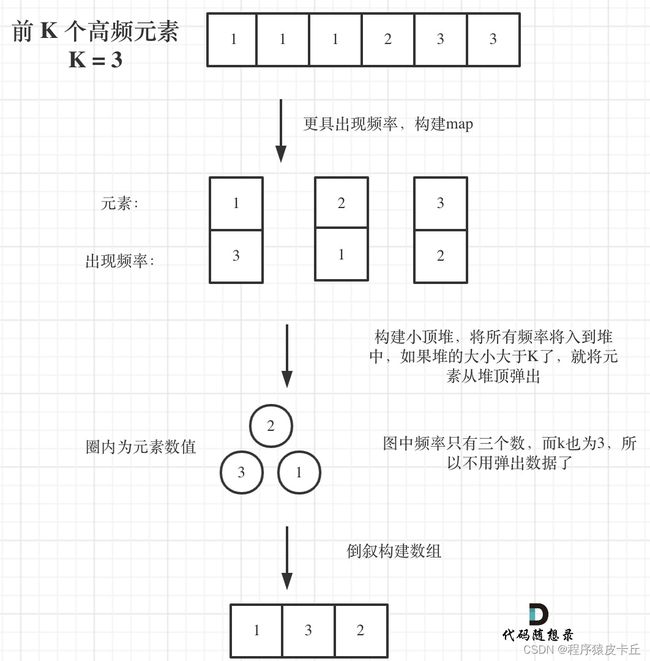
具体实现代码。时间复杂度O(nlogk),空间复杂度O(n)。
关于比较运算在建堆时是如何运用的,为什么左大于右就会建立小顶堆,反而建立大顶堆呢?
确实 例如我们在写快排的cmp函数的时候,return left>right 就是从大到小,return left
优先级队列的定义正好反过来了,可能和优先级队列的源码实现有关(我没有仔细研究),如果把队首弹出的元素放到队尾,大顶堆所有元素全弹出后,此时队列中的元素是按照从小到大排序的。
//有关这个问题的解释,可参考这篇文章。
8.Leetcode71 简化路径
难度:
总结:
在栈与队列系列中,我们强调栈与队列的基础,也是很多同学容易忽视的点。
使用抽象程度越高的语言,越容易忽视其底层实现,而C++相对来说是比较接近底层的语言。
我们用栈实现队列,用队列实现栈来掌握的栈与队列的基本操作。
接着,通过括号匹配问题、字符串去重问题、逆波兰表达式问题来系统讲解了栈在系统中的应用,以及使用技巧。
通过求滑动窗口最大值,以及前K个高频元素介绍了两种队列:单调队列和优先级队列,这是特殊场景解决问题的利器,是一定要掌握的。
本文部分内容来源:代码随想录