uCOS-III 学习记录(6)——优先级表
参考内容:《[野火]uCOS-III内核实现与应用开发实战指南——基于STM32》第 11 章。
文章目录
-
- 1 优先级表的定义 OSPrioTbl(os_prio.c)
-
- 1.1 CPU_DATA——一个数组元素的数据长度为多少?(cpu.h)
- 1.2 OS_PRIO_TBL_SIZE——数组有多大?(os.h)
-
- 1.2.1 OS_CFG_PRIO_MAX——支持多少个优先级?(os_cfg.h)
- 1.2.2 DEF_INT_CPU_NBR_BITS——CPU 整型数据有多少位?(cpu_def.h)
- 1.3 优先级表的结构——定义好了以后?
- 2 初始化优先级表 OS_PrioInit()(os_prio.c)
- 3 置位优先级表中的相应位 OS_PrioInsert()(os_prio.c)
-
- 位运算求余——为什么求余操作可以这么写?
- 4 清除优先级表的相应位置 OS_PrioRemove()(os_prio.c)
- 5 查找最高优先级 OS_PrioGetHighest()(os_prio.c)
-
- 5.1 前导零和后导零
- 5.2 由 C 语言实现前导零 CPU_CntLeadZeros(cpu_core.c)
- 5.3 由汇编语言实现前导零 CPU_CntLeadZeros(cpu_a.asm)
- 5.4 完成剩余的工作
1 优先级表的定义 OSPrioTbl(os_prio.c)
在文件 os_prio.c 中定义优先级表,它是一个数组:
CPU_DATA OSPrioTbl[OS_PRIO_TBL_SIZE]; /* 定义优先级表 */
接下来着重理解 CPU_DATA 和 OS_PRIO_TBL_SIZE 的含义。
1.1 CPU_DATA——一个数组元素的数据长度为多少?(cpu.h)
在 cpu.h 中定义了 CPU_DATA 的类型为 unsigned int,也就是一个数组元素为 32 位:
typedef unsigned int CPU_INT32U;
typedef CPU_INT32U CPU_DATA;
如果 MCU 的(字长)类型是 16 位、8 位或者 64 位,只需要把优先级表的数据类型 CPU_DATA 改成相应的位数即可。
1.2 OS_PRIO_TBL_SIZE——数组有多大?(os.h)
这个问题将会关系到优先级表有多大。在 os.h 中宏定义了 OS_PRIO_TBL_SIZE:
#define OS_PRIO_TBL_SIZE ( ((OS_CFG_PRIO_MAX - 1u) / DEF_INT_CPU_NBR_BITS) + 1u )
接下来,我们来讲讲 OS_CFG_PRIO_MAX 和 DEF_INT_CPU_NBR_BITS 的来由。
1.2.1 OS_CFG_PRIO_MAX——支持多少个优先级?(os_cfg.h)
在 os_cfg.h 中宏定义了 OS_CFG_PRIO_MAX。我们设置为 32,即最大支持 32 个优先级:
/* 支持最大的优先级 */
#define OS_CFG_PRIO_MAX 32u
1.2.2 DEF_INT_CPU_NBR_BITS——CPU 整型数据有多少位?(cpu_def.h)
DEF_INT_CPU_NBR_BITS 表示一个整型数据有多少位,在 cpu_def.h 定义:
/* CPU整型数位定义 */
#define DEF_INT_CPU_NBR_BITS (DEF_OCTET_NBR_BITS * CPU_CFG_DATA_SIZE)
- DEF_OCTET_NBR_BITS 表示一个字节长度是多少位,这里默认设置为 8 位,在 cpu_def.h 中已定义:
/* 一个字节长度为8位 */
#define DEF_OCTET_NBR_BITS 8u
- CPU_CFG_DATA_SIZE 表示 CPU 数据的字长相当于多少个字节。类似地,CPU_CFG_ADDR_SIZE 表示 CPU 地址的字长相当于多少个字节。在 cpu.h 中已定义:
/*********************************CPU字长配置**********************************/
#define CPU_CFG_ADDR_SIZE CPU_WORD_SIZE_32
#define CPU_CFG_DATA_SIZE CPU_WORD_SIZE_32
#define CPU_CFG_DATA_SIZE_MAX CPU_WORD_SIZE_64
- 而 CPU_WORD_SIZE_32 又在 cpu_def.h 中已定义,表示 32 位长度在这种设置下被定义为 4 个字节:
#define CPU_WORD_SIZE_08 1u
#define CPU_WORD_SIZE_16 2u
#define CPU_WORD_SIZE_32 4u
#define CPU_WORD_SIZE_64 8u
因此,DEF_INT_CPU_NBR_BITS = DEF_OCTET_NBR_BITS * CPU_CFG_DATA_SIZE = 8(一个字节有 8 位) * 4(4 个字节) = 32,说明 CPU 整型数据有 32 位,即字长为 32。
【恶补概念!】
- 位(bit):位表示的是二进制位,一般称为比特,是计算机存储的最小单位。
- 字节(byte):字节是计算机中数据处理的基本单位。计算机中以字节为单位存储和解释信息,规定一个字节由八个二进制位构成,即 1 个字节等于 8 个比特(1Byte = 8bit)。
- 字(word):计算机进行数据处理时,一次存取、加工和传送的数据长度称为字(word)。一个字通常由一个或多个(一般是字节的整数位)字节构成。例如 286 微机的字由 2 个字节组成,它的字长为 16;486 微机的字由 4 个字节组成,它的字长为 32。计算机的字长决定了其 CPU 一次操作处理实际位数的多少,由此可见计算机的字长越大,其性能越优越。
- 字长:计算机的每个字所包含的位数称为字长。例如 286 微机的字由 2 个字节组成,它的字长为 16;486 微机的字由 4 个字节组成,它的字长为 32。
1.3 优先级表的结构——定义好了以后?
由以上讨论可知,我们定义的 CPU 字长为 32,支持最大优先级为 32,则DEF_INT_CPU_NBR_BITS = 32,OS_CFG_PRIO_MAX = 32,所以数组元素一共有:( (OS_CFG_PRIO_MAX - 1u) / DEF_INT_CPU_NBR_BITS ) + 1u = ( (32 - 1) / 32 ) + 1 = 0 + 1 = 1。优先级表里只有一个元素。
如果我们需要支持 64 个优先级,CPU 字长为 32,那么DEF_INT_CPU_NBR_BITS = 32,OS_CFG_PRIO_MAX = 64,所以数组元素一共有:( (OS_CFG_PRIO_MAX - 1u) / DEF_INT_CPU_NBR_BITS ) + 1u = ( (64 - 1) / 32 ) + 1 = 1 + 1 = 2。优先级表里两个元素。
如下图所示,这是 CPU 字长为 32 的优先级表结构:
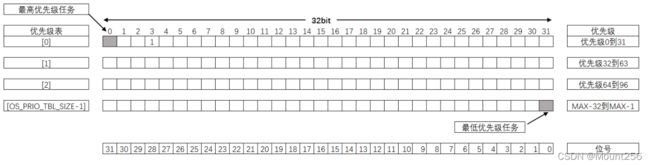
- 若最大支持 32 个优先级,那么说明优先级一共有 0-31 的编号,没有 32 的编号。
- 优先级表 OSPrioTbl[0] 记录了优先级 0-31 的情况,OSPrioTbl[1] 记录了优先级 32-63 的情况,以此类推。
- 数据的每一位表示该优先级的任务是否存在,置 1 表示该优先级存在任务,置 0 表示该优先级没有任务。
- 数据的高位对应的是更低的优先级,低位对应的是更高的优先级。比如,OSPrioTbl[0] 的位 31 对应的是优先级 0,而位 30 对应的是优先级 1。对于我们定义的字长和最大优先级,若要创建一个优先级为 prio 的任务,那么就在 OSPrioTbl[0] 的位 [31-prio] 置 1 即可。这与我们的认知正好相反。
- 总结:若要创建一个优先级为 prio 的任务,那么就在
OSPrioTbl[prio/字长]的位[字长-prio-1]置 1 即可。
2 初始化优先级表 OS_PrioInit()(os_prio.c)
该函数的功能是:
- 初始化优先级表 OSPrioTbl,将每个数组元素全部置 0。
/* 初始化优先级表 */
void OS_PrioInit (void)
{
CPU_DATA i;
/* 全部初始化为 0 */
for (i = 0u; i < OS_PRIO_TBL_SIZE; i++)
{
OSPrioTbl[i] = (CPU_DATA)0;
}
}
该函数需要被 OSInit() 调用。初始化后的优先级表如下所示:

3 置位优先级表中的相应位 OS_PrioInsert()(os_prio.c)
该函数的功能是:
- 在优先级表中,将相应的位置位。(形参是优先级)
/* 在优先级表的相应位置置位 */
void OS_PrioInsert (OS_PRIO prio)
{
CPU_DATA bit;
CPU_DATA bit_nbr;
OS_PRIO ix;
/* 求模,获取优先级表数组的下标 */
ix = prio / DEF_INT_CPU_NBR_BITS;
/* 求余,将优先级限制在 DEF_INT_CPU_NBR_BITS 内 */
bit_nbr = (CPU_DATA)prio & (DEF_INT_CPU_NBR_BITS - 1u); /* 等价于 prio % DEF_INT_CPU_NBR_BITS */
/* X % (2^N) = X & (2^N-1) */
bit = 1u;
/* 获取优先级在优先级表中对应的位的位置 */
bit <<= (DEF_INT_CPU_NBR_BITS - 1u) - bit_nbr;
/* 将优先级在优先级表中对应的位置 1 */
OSPrioTbl[ix] |= bit;
}
我们定义的 CPU 字长为 32,支持最大优先级为 32,则DEF_INT_CPU_NBR_BITS = 32,OS_CFG_PRIO_MAX = 32,则优先级表中只有一个元素。那么假设现在 prio = 3:
- 求模:ix = 3 / 32 = 0,说明优先级为 3 在第一个数组元素 OSPrioTbl[0] 中。
- 求余:bit_nbr = 3 & 31 = 3。
- 获取位置:bit <<= 31 - 3 = 28,在 OSPrioTbl[0] 的位 28 置 1 即可。
若 prio = 35:
- 求模:ix = 35 / 32 = 1,说明优先级为 35 在第二个数组元素 OSPrioTbl[1] 中。
- 求余:bit_nbr = 35 & 31 = 4。
- 获取位置:bit <<= 31 - 4 = 27,在 OSPrioTbl[1] 的位 27 置 1 即可。
由上面的例子可以看到,该函数没有防止优先级溢出的情况发生。目前我不太清楚 uCOS 有没有一种机制可以防止这种非法的情况发生。
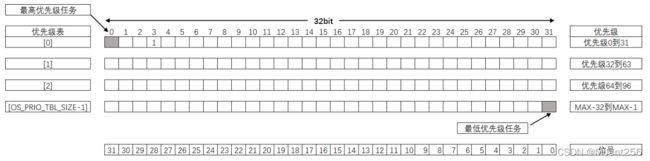
在优先级最大是 32,DEF_INT_CPU_NBR_BITS 等于 32 的情况下,如果分别创建了优先级 3、5、8 和 11 这四个任务,任务创建成功后,优先级表的设置情况可见下图。有一点要注意的是,在 uCOS 中,最高优先级和最低优先级是留给系统任务使用的,用户任务不能使用。

位运算求余——为什么求余操作可以这么写?
应该有同学注意到了,求余的那行代码居然不用 % ,用的是 & 运算符,这是什么原理呢?先提前声明:这个原理仅适用于 2 的幂次方。
我们知道,一个数除以一个形如 2^N 的数,可等价于这个数右移 N 位:
X / 2^N = X >> N
-
比如 11 / 2 = 5,11 的二进制为 1011,右移一位为 0101,也就是 5。现在请注意,被移走的消失不见的数是什么?是二进制下的 1,也就是十进制的 1,它就是余数;
-
再比如 11 / 8 = 1,11 的二进制为 1011,右移三位为 0001,也就是 1。被移走消失不见的数是二进制下的 011,也就是十进制的 3,它就是余数;
-
再比如 14 / 4 = 3,15 的二进制为 1110,右移两位为 0011,也就是 3。被移走消失不见的数是二进制下的 10,也就是十进制的 2,它就是余数。
你有发现什么吗?其实我们移走的数字就是余数。现在我们求余,想要保留的就是这个余数。那如何得到呢?还需要仔细观察上面这三个例子。
- 第一个例子:对 1011 右移一位,仅最后一位保留,保留的是 1;
- 第二个例子:对 1011 右移三位,最后三位保留,保留的是 011;
- 第三个例子:对 1110 右移两位,最后两位保留,保留的是 10。
联想到 & 运算的性质,可以将其等价为:
- 第一个例子:1011 & 0001,仅最后一位保留,保留的是 1;
- 第二个例子:1011 & 0111,最后三位保留,保留的是 011;
- 第三个例子:1110 & 0011,最后两位保留,保留的是 10。
也就是可以看做:
- 第一个例子: 1011 & (2-1),仅最后一位保留,保留的是 1;
- 第二个例子: 1011 & (8-1),最后三位保留,保留的是 011;
- 第三个例子: 1110 & (4-1),最后两位保留,保留的是 10。
你看懂了么?所以对 2 的幂次方求余,可以等价为:X & (2^N - 1)。这样做能加快运算速度。记住,该结论只对 2 的幂次方适用!!!
4 清除优先级表的相应位置 OS_PrioRemove()(os_prio.c)
与优先级表置位的函数类似,这个函数也需要找到相应的位置,寻找方法也是一样的。唯一不同的是最后一句代码,本函数需要将相应位清零。
该函数的功能是:
- 在优先级表中,将相应的位清零。(形参是优先级)
/* 清除优先级表的相应位置 */
void OS_PrioRemove (OS_PRIO prio)
{
CPU_DATA bit;
CPU_DATA bit_nbr;
OS_PRIO ix;
/* 求模,获取优先级表数组的下标 */
ix = prio / DEF_INT_CPU_NBR_BITS;
/* 求余,将优先级限制在 DEF_INT_CPU_NBR_BITS 内 */
bit_nbr = (CPU_DATA)prio & (DEF_INT_CPU_NBR_BITS - 1u); /* 等价于 prio % DEF_INT_CPU_NBR_BITS */
/* X % (2^N) = X & (2^N-1) */
bit = 1u;
/* 获取优先级在优先级表中对应的位的位置 */
bit <<= (DEF_INT_CPU_NBR_BITS - 1u) - bit_nbr;
/* 将优先级在优先级表中对应的位清 0 */
OSPrioTbl[ix] &= ~bit;
}
5 查找最高优先级 OS_PrioGetHighest()(os_prio.c)
什么是最高优先级?最高优先级即数组元素下标最大且位数最大的位置。比如如下图所示,只有一个数组元素,从高位看起,第一次出现 1 的位置是 28,那么对应的最高优先级为 3。

5.1 前导零和后导零
好了,最精彩的部分来了。现在我想请各位思考一个问题,如何才能最快、最高效的找到最高优先级?一个很朴素的想法是,从数组的最高位开始,一位一位的测试哪个位为 1,第一次出现 1 的地方一定就是最高优先级的位置。对,这个想法很朴素,也是接下来我们寻找最高优先级的核心思路。但是,思路正确,实现起来却有点棘手。
因为,一位位的测试,也太麻烦了。32 个优先级,就要循环 32 遍的位测试;128 个优先级,就要循环 128 遍的位测试。都说 uCOS 很小巧精致,这个称谓并非空穴来风。只需换个角度看待问题,立马算法效率就提高了。
还是以上面的图为例,从数据的高位到低位查找第一个不为 0 的位置,即优先级为 3,为最高优先级。你注意到了吗?既然是最高优先级,那么更高的位数肯定全都是 0,数数这些 0 的个数,正好是 3 个 0,正好也是最高优先级的值!
0001 0100 1001 0000 0000 0000 0000 0000
|
|
|
最高优先级(前面有 3 个 0,正好是最高优先级的值,也是前导零的个数)
从最高位起开始数 0 的个数,一直数到第一次出现 1 的地方。这些零,就是前导零,数出来的 0 的个数,就是这个数的前导零个数。 它也正好是最高优先级的值。
一个数的前导零个数是多少?这个问题是有前提条件的,即,你要告诉我该数的位数是多少,不同位数,得出的结果是不同的。例如:
- 在 4 位字长下,2 的前导零个数是多少?写成二进制:0010,前导零个数为 2。
- 在 8 位字长下,2 的前导零个数是多少?写成二进制:0000 0010,前导零个数为 6。
- 在 4 位字长下,7 的前导零个数是多少?写成二进制:0111,前导零个数为 1。
- 在 8 位字长下,7 的前导零个数是多少?写成二进制:0000 0111,前导零个数为 5。
- 在 32 位字长下,0001 0100 1001 0000 0000 0000 0000 0000 的前导零个数为 3。
类似的,从最低位起开始数 0 的个数,一直数到第一次出现 1 的地方。数出来的 0 的个数,就是这个数的后导零个数。
查找最高优先级的本质,就是求前导零的过程。我们有两种办法实现求前导零,一种是 C 语言,另一种是 ARM 汇编。
5.2 由 C 语言实现前导零 CPU_CntLeadZeros(cpu_core.c)
用 C 语言查找一个 32 位数的前导零个数,一个最容易想到的办法是一位位的查找,但对于这种实时性要求高的系统而言还是太慢了。最快的办法是“用空间换时间”,可以将 32 位数拆成四部分,每部分都是 8 位,我们 8 位 8 位的去检查,最多只需要检查 4 次。每次检查,直接从一个大数组表中找到对应的前导零个数,如下所示:
/*
*********************************************************************************************************
* 8位前导零查找表
*********************************************************************************************************
*/
#ifndef CPU_CFG_LEAD_ZEROS_ASM_PRESENT
static const CPU_INT08U CPU_CntLeadZerosTbl[256] = { /* Data vals : */
/* 0 1 2 3 4 5 6 7 8 9 A B C D E F */
8u, 7u, 6u, 6u, 5u, 5u, 5u, 5u, 4u, 4u, 4u, 4u, 4u, 4u, 4u, 4u, /* 0x00 to 0x0F */
3u, 3u, 3u, 3u, 3u, 3u, 3u, 3u, 3u, 3u, 3u, 3u, 3u, 3u, 3u, 3u, /* 0x10 to 0x1F */
2u, 2u, 2u, 2u, 2u, 2u, 2u, 2u, 2u, 2u, 2u, 2u, 2u, 2u, 2u, 2u, /* 0x20 to 0x2F */
2u, 2u, 2u, 2u, 2u, 2u, 2u, 2u, 2u, 2u, 2u, 2u, 2u, 2u, 2u, 2u, /* 0x30 to 0x3F */
1u, 1u, 1u, 1u, 1u, 1u, 1u, 1u, 1u, 1u, 1u, 1u, 1u, 1u, 1u, 1u, /* 0x40 to 0x4F */
1u, 1u, 1u, 1u, 1u, 1u, 1u, 1u, 1u, 1u, 1u, 1u, 1u, 1u, 1u, 1u, /* 0x50 to 0x5F */
1u, 1u, 1u, 1u, 1u, 1u, 1u, 1u, 1u, 1u, 1u, 1u, 1u, 1u, 1u, 1u, /* 0x60 to 0x6F */
1u, 1u, 1u, 1u, 1u, 1u, 1u, 1u, 1u, 1u, 1u, 1u, 1u, 1u, 1u, 1u, /* 0x70 to 0x7F */
0u, 0u, 0u, 0u, 0u, 0u, 0u, 0u, 0u, 0u, 0u, 0u, 0u, 0u, 0u, 0u, /* 0x80 to 0x8F */
0u, 0u, 0u, 0u, 0u, 0u, 0u, 0u, 0u, 0u, 0u, 0u, 0u, 0u, 0u, 0u, /* 0x90 to 0x9F */
0u, 0u, 0u, 0u, 0u, 0u, 0u, 0u, 0u, 0u, 0u, 0u, 0u, 0u, 0u, 0u, /* 0xA0 to 0xAF */
0u, 0u, 0u, 0u, 0u, 0u, 0u, 0u, 0u, 0u, 0u, 0u, 0u, 0u, 0u, 0u, /* 0xB0 to 0xBF */
0u, 0u, 0u, 0u, 0u, 0u, 0u, 0u, 0u, 0u, 0u, 0u, 0u, 0u, 0u, 0u, /* 0xC0 to 0xCF */
0u, 0u, 0u, 0u, 0u, 0u, 0u, 0u, 0u, 0u, 0u, 0u, 0u, 0u, 0u, 0u, /* 0xD0 to 0xDF */
0u, 0u, 0u, 0u, 0u, 0u, 0u, 0u, 0u, 0u, 0u, 0u, 0u, 0u, 0u, 0u, /* 0xE0 to 0xEF */
0u, 0u, 0u, 0u, 0u, 0u, 0u, 0u, 0u, 0u, 0u, 0u, 0u, 0u, 0u, 0u /* 0xF0 to 0xFF */
};
#endif
第一行存储的是 0x00-0x0F 的前导零个数,比如 0x00 的前导零有 8 个,0x01 的前导零有 7 个;以此类推,第二行存储的是 0x10-0x1F 的前导零个数,比如 0x10 的前导零有 3 个……一共有 256 个数,正好存储了从 0x00-0xFF 的前导零个数。现在的内存都已经非常充足,用这一点空间的损失换取算法上的提高是非常值得的。
每次检查 8 位时,只需要用 8 位数作为下标去访问数组表,得到对应的前导零个数。
用 C 语言求前导零,假设要求的数据是 32 位的:
- 检查位 31-24,是否全是 0,若不是,将其右移 24 位,变成 8 位数,然后将其作为下标访问查找表,得到前导零个数。
- 如果位 31-24 全是 0,检查位 23-16,是否全是 0,若不是,将其右移 16 位,变成 8 位数,然后将其作为下标访问查找表,得到前导零个数(还需要加上位 31-24 的前导零个数,即 8)。
- 如果位 23-16 全是 0,检查位 15-8,是否全是 0,若不是,将其右移 8 位,变成 8 位数,然后将其作为下标访问查找表,得到前导零个数(还需要加上位 31-16 的前导零个数,即 16)。
- 如果位 15-8 全是 0,检查位 7-0,是否全是 0,若不是,将其右移 0 位,变成 8 位数,然后将其作为下标访问查找表,得到前导零个数(还需要加上位 31-8 的前导零个数,即 24)。
/*
*********************************************************************************************************
* 前导零函数(只实现了 32 位)
*********************************************************************************************************
*/
#ifndef CPU_CFG_LEAD_ZEROS_ASM_PRESENT
CPU_DATA CPU_CntLeadZeros (CPU_DATA val)
{
CPU_DATA nbr_lead_zeros;
CPU_INT08U ix;
#if (CPU_CFG_DATA_SIZE == CPU_WORD_SIZE_32)
if (val > 0x0000FFFFu) /* 检查高 16 位,若不都是 0 */
{
if (val > 0x00FFFFFFu) /* 检查位 31-24,若不都是 0 */
{
ix = (CPU_INT08U)(val >> 24u); /* 右移 24 位 */
nbr_lead_zeros = (CPU_DATA)(CPU_LeadZerosTbl[ix] + 0u);
}
else /* 若位 31-24 都是 0,检查位 23-16 */
{
ix = (CPU_INT08U)(val >> 16u); /* 右移 16 位 */
nbr_lead_zeros = (CPU_DATA)(CPU_LeadZerosTbl[ix] + 8u);
}
}
else /* 检查低 16 位,若不都是 0 */
{
if (val > 0x000000FFu) /* 检查位 15-8,若不都是 0 */
{
ix = (CPU_INT08U)(val >> 8u); /* 右移 8 位 */
nbr_lead_zeros = (CPU_DATA)(CPU_LeadZerosTbl[ix] + 16u);
}
else /* 若位 15-8 都是 0,检查位 7-0 */
{
ix = (CPU_INT08U)(val >> 0u); /* 右移 0 位 */
nbr_lead_zeros = (CPU_DATA)(CPU_LeadZerosTbl[ix] + 24u);
}
}
#endif
return nbr_lead_zeros;
}
#endif
对于其他位数,比如 8 位、16 位、64 位等,也是一样的办法,这里不再赘述。
5.3 由汇编语言实现前导零 CPU_CntLeadZeros(cpu_a.asm)
事实上,某些汇编已经支持前导零和后导零的指令了。有些汇编没有前导零的指令,只能使用 C 语言的办法实现。而在 ARM 汇编中,可以用 CLZ 指令求前导零。而对于后导零,可以先将源操作数反转,然后再求前导零。
;********************************************************************************************************
; 前导零/后导零函数
;********************************************************************************************************
; CPU_DATA CPU_CntLeadZeros (CPU_DATA val); (前导零)
CPU_CntLeadZeros
CLZ R0, R0
BX LR
; CPU_DATA CPU_CntTrailZeros (CPU_DATA val); (后导零)
CPU_CntTrailZeros
RBIT R0, R0
CLZ R0, R0
BX LR
5.4 完成剩余的工作
现在将 OS_PrioGetHighest() 的代码全部展示出来:
/* 获取最高优先级 */
OS_PRIO OS_PrioGetHighest (void)
{
CPU_DATA *p_tbl;
OS_PRIO prio;
prio = (OS_PRIO)0;
p_tbl = &OSPrioTbl[0]; /* 优先级表首地址 */
while (*p_tbl == (CPU_DATA)0) /* 找到不为 0 的数组元素 */
{
prio += DEF_INT_CPU_NBR_BITS;
p_tbl++;
}
/* 找到优先级表中置位的最高的优先级 */
prio += (OS_PRIO)CPU_CntLeadZeros(*p_tbl);
return prio;
}
该函数完成的工作有:
- 先遍历优先级表,看看哪个数组元素是非 0 的。因为数组元素为 0,说明这个数组元素没有一个优先级是被置位的。
- 一旦发现某个数组元素非 0,意味着该数组元素至少有一位被置位了,最高优先级也一定在里面。
- 计算该数组元素的前导零个数,得到最高优先级。
现在,优先级表的代码,看起来也不那么难了吧!