牛客网刷题记录与机试面试记录
牛客网刷题记录与机试面试记录
- 牛客网
-
- 【2021】阿里巴巴编程题(2星)
-
- 第一题 完美对
- 第二题 选择物品
- 第三题 小强去春游
- 第四题 比例问题
- 第五题 小强修水渠
- 第六题 国际交流会
- 2021】阿里巴巴编程题(4星)
-
- 第一题 子集
- 第二题 小强爱数学
- 杂项
-
- 判断字符串
- 01翻转
- dfs优化思路
- 企业机试
-
- 2023-03-11 美团机试
-
- 第一题
- 第二题
- 第三题
- 第四题
- 第五题
- 2023-03-12 拼多多机试
-
- 第一题 多多的压缩编码II
- 第二题 多多的飞机大战游戏
- 第三题 多多的团建计划
- 第四题 多多的餐厅客流量
- 2023-3-15 阿里机试
-
- 第一题
- 第二题
- 第三题
- 2023-3-16 蚂蚁机试
-
- 第一题 整数抽取
- 第二题 组装电脑
- 第三题 带传送阵的矩阵游离
- 2023-03-19 米哈游机试
-
- 第一题
- 第二题
- 第三题
- 2023-03-23 腾讯音乐笔试
-
- 第一题
- 第二题
- 第三题
- 2023-03-26 腾讯笔试
-
- 第一题 链表操作
- 第二题 重组字符串
- 第三题 最小权值排列数组
- 2023-03-28 百度笔试
-
- 第一题
- 第二题
- 第三题
- 面试代码题
-
- 链表是否存在环
- 字符串数组去重
- 二分查找
- 流控算法
- 比较版本号
- 字符串最长单词
- LRU算法
- 重排链表
- 寻找后序遍历的后继节点
- 手写快排
牛客网
【2021】阿里巴巴编程题(2星)
【2021】阿里巴巴编程题(2星)
第一题 完美对

数组各数减去第一个数,归并相同特征的数组,使用map记录各数组的出现次数,对每一个map kv,查看map中是否存在相反数组,需对全0数组(相反数组为自身)进行特殊处理,为了避免重复计算,将相反数组出现次数置为-1
#include 第二题 选择物品

全排列变形问题,长度为m时输出结果,数字交换时强制要求序列递增,去重处理
#include 第三题 小强去春游

动态规划问题,假设已解决n-1与n-2规模时最短时间,可能的方法是:n-1 (最轻的人单独过河把最重的人接过来 fn-1+v0+vn) n-2(最轻的人过去 最重的和第二重的人过去 第二轻的人过来 第一第二轻的人过去 fn-2+v1+vn+v2+v2)
#include 第四题 比例问题
![]()
枚举即可,时刻注意溢出问题,机试多使用long long
#include 第五题 小强修水渠

最开始发现最小距离点一定在端点上(若有多个点,一定存在端点),故从前往后变量,计算端点的距离和,left为与左边点的长度和,right为与右边点的长度和
#include 后面发现最小距离和是中位数的性质,直接求中位数即可
#include 第六题 国际交流会
最近小强主办了一场国际交流会,大家在会上以一个圆桌围坐在一起。由于大会的目的就是让不同国家的人感受一下不同的异域气息,为了更好地达到这个目的,小强希望最大化邻座两人之间的差异程度和。为此,他找到了你,希望你能给他安排一下座位,达到邻座之间的差异之和最大。
输入总共两行。
第一行一个正整数,代表参加国际交流会的人数(即圆桌上所坐的总人数,不单独对牛牛进行区分)
第二行包含个正整数,第个正整数a_i代表第个人的特征值。
其中
注意:
邻座的定义为: 第人的邻座为,第人的邻座是,第人的邻座是。
邻座的差异值计算方法为。
每对邻座差异值只计算一次。
输出总共两行。
第一行输出最大的差异值。
第二行输出用空格隔开的个数,为重新排列过的特征值。
(注意:不输出编号)
如果最大差异值情况下有多组解,输出任意一组即可。
思路
依次选取较大值与较小值即可
#include #include 2021】阿里巴巴编程题(4星)
2021】阿里巴巴编程题(4星)
第一题 子集

经典的二维最长递增子序列问题,刚开始使用动态规划实现
#include 超时,过不了,只能使用二分查找解法了

#include 第二题 小强爱数学

记忆深刻的问题,之前写过一遍,当时也是写了很久没写出来,看了一下午愣是没看出为啥答案错了

题目的难点在于想出这个递推公式,然后就是mod运算的性质,不过我出错的点在于使用int存储A,B,并用A,B计算了一次dp[2],运算过程会溢出,即使dp[2]为long long,但表达式的组成元素类型全部为int,故仍然会发生溢出。
int A,B;
long long x = A * A - 2 * B;
#include 杂项
判断字符串
ali字符串,刚开始忽略了对开头字符是否为Aa的判断,只有3种状态
#include 01翻转
使用dfs遍历各个翻转可能,加上一点剪枝策略,骗分
正确思路


dfs优化思路
可以使用备忘录的方式减少各个点最大获得价值的重复计算
#include 企业机试
2023-03-11 美团机试
题目:美团2024届暑期实习第一轮后端笔试详解
通过了前三道,花了一堆时间在第四道上,一分没得,第五题都没时间看。题目的设置有点无语,一到四题安排在一起,第五题安排在一起,当时不知道提交后可以继续修改,进了一到四题的项就不敢提交,以为第五题单独放一起肯定很难,最后没时间了看了一下第五题,比较简单。搞不明白为啥要把第五题单独列一个项,要不然怎样都能写出四道来
第一题
小美有一个由数字字符组成的字符串。现在她想对这个字符串进行一些修改。 具体地,她可以将文个字符串中任意位置字符修改为任意的数字字符。她想知道,至少进行多少次修改,可以使得“修改后的字符串不包含两个连续相同的字符?
例如,对于字符串”111222333", 她可以进行3次修改将其变为” 121212313"。输入描述
一行,一个字符串s,保证s只包含数字字符。1<=|s|<= 100000输出描述
一行,一个整数,表示修改的最少次数。
思路
简单题,遇见相同的字符直接改成数字字符之外的‘a’即可
#include 第二题
小团在一个n*m的网格地图上探索。 网格地图上第i行第j列的格子用坐标(i,j)简记。初始时,小团的位置在地图的左上角,即坐标(1,1)。 地图上的每个格子 上都有一定的金币, 特别地,小团位于的初始位置(1,1)上的金币为0。小团在进行探索移动时,可以选择向右移动-格(即从(x,y)到达(x,y+1))或向下移动一格(即从(x,y)到达(x+1,y)) 。地图上的每个格子都有一个颜色,红,色或蓝色。如果小团次移动前后的两个格子颜色不同,那么他需要支付k个金币才能够完成这-次移动;如果移动前后的两个格子颜色相同,则不需要支付金币。小团可以在任意格子选择结束探索。现在给你网格地图上每个格子的颜色与金币数量,假设小团初始时的金币数量为0,请你帮助小团计算出最优规划,使他能获得最多的金币,输出能获得的最多 金币数量即可。注意:要求保证小团任意时刻金币数量不小于零。
输入描述
第一行是三个用空格隔开的整数n、m和k,表示网格地图的行数为n,列数为m,在不同颜色的两个格子间移动需要支付k个金币。
接下来n行,每行是一个长度为m的字符串, 字符串仅包含字符R’或’ B’。第i行字符串的第j个字符表示地图上第i行第j列的格子颜色,如果字符为’ R’ 则表示格子颜色为红色,为’B’ 表示格子颜色为蓝色。
接下来是个n行m列的非负整数矩阵,第i行第j列的数字表示地图上第行第j列的格子上的金币数量。保证所有数据中数字大小都是介于[0, 10]的整数。
1<=n,m<=200, 1<=k<=5。
思路
刚开始直接暴力回溯,运行超时
#include 后面用动态规划写了一个版本,通过
#include 第三题
小美是位天文爱好者, 她收集了接下来段时间中所有 会划过她所在的观测地上空的流星信息。具体地,她收集了n个流星在她所在观测地上空的出现时刻和消失时刻。对于一个流星,若’其的出现时刻为s,消失时刻为t,那么小美在时间段[s, t]都能够观测到它。对于一个时刻,观测地上空出现的流星数量越多,则小美认为该时刻越好。小美希望能够选择一个最佳的时刻进行观测和摄影,使她能观测到最多数量的流星。现在小美想知道 ,在这个最佳时刻,她最多能观测到多少个流星以及一共有多少个最佳时刻可供她选择。
输入描述
第一行是一个正整数n,表示流星的数量。
第二行是n个用空格隔开的正整数,第i个数si表示第i个流星的出现时间。
第三行是n个用空格隔开的正整数,第i个数ti表示第i个流星的消失时间。
1<=n<=100000, 1<=si<=ti<=10^9
输出描述
输出一行用空格隔开的两个数x和y,其中x表示小美能观测到的最多流星数,y表示可供她选择的最佳时刻数量。
思路
排序,从左往右计算可观测的流星数量,不过后面看别人说标准解法是差分数组
#include 第四题
小D和小W最近在玩坦克大战,双方操控自己的坦克在16*1 6的方格图上战斗,小D的坦克初始位置在地图的左上角,朝向为右,其坐标(0,0), 小W的坦克初始位置在地图右下角,朝向为左,坐标为(15,15)。坦克不能移动到地图外,坦克会占领自己所在的格子,己方的坦克不可以进入对方占领过的格子。每一个回合双方必须对自己的坦克下达以下5种指令中的一种:
.移动指令U:回合结束后,使己方坦克朝向为上,若上方的格子未被对方占领,则向当前朝向移动一个单位(横坐标-1),否则保持不动;
.移动指令D:回合结束后,使己方坦克朝向为下,若下方的格子未被对方占领,则向当前朝向移动一个单位(横坐标+1),否则保持不动,
.移动指令L:回合结束后,使己方坦克朝向为左,若左侧的格子未被对方占领,则向当前朝向移动一个单位(纵坐标-1) ,否则保持不动;
.移动指令R:回合结束后,使己方坦克朝向为右,若右侧的格子未被对方占领,则向当前朝向移动一个单位(纵坐标+1),否则保持不动;
. 开火指令F:己方坦克在当前回合立即向当前朝向开火;
己方坦克开火后,当前回合己方坦克的正前方若有对方的坦克,对方的坦克将被摧毁,游戏结束,己方获得胜利;若双方的坦克在同一-回合被摧毁,游戏结束,判定为平局;若双方的坦克在同一回合内进入到同一个未被占领的格子,则双方的坦克发生碰撞,游戏结束,判定为平局;当游戏进行到第256个回合后,游戏结束,若双方坦克均未被摧毁,则占领格子数多的一方获得胜利,若双方占领的格子数一样多,判定为平局。*注意, 若-方开火, 另-方移动,则认为是先开火,后移动。
现在小D和小W各自给出一串长度为256的指令字符串, 请你帮助他们计算出游戏将在多少个回合后结束,以及游戏的结果。
输入描述
输入共两行,每行为一串长度为256的指令宁符串,字符串中只包含“U”,“D",“L" “R”,“F"这五个字符。第一行表示小D的指令,第工行表示小W的指令。
输出描述
输出一共两行,第一行一个整数k,表示游戏将在k个回合后结束。第二行为游戏的结 果,若小D获胜则输出“D",若小W获胜则输出“W”若平局则输出“P”
思路
大模拟,40分钟一分没得,懒得贴代码了
第五题
给一棵有n个点的有根树,点的编号为1到n,根为1。每个点的颜色是红色或者蓝色。对于树上的一个点,如果其子树中(不包括该点本身)红色点和蓝色点的数量相同,那么我们称该点是平衡的。
请你计算给定的树中有多少个点是平衡点。
输入描述
第一行是一个正整数n,表示有n个点。
接下来行一个长度为n的字符串,仅包含字符R’和’B’, 第i个字符表示编号为的节点的颜色,字符为’R’ 表示红色,’ B’ 表示蓝色。
接下来一行n-1个用空格隔开的整数,第1个整数表示编号为i+ 1的点的父亲节点编号。1<=n<=10000
输出描述
一行一个整数,表示树上平衡点的个数。
思路
没写,无语的题目安排
2023-03-12 拼多多机试
题目链接: 2023暑期实习-笔试-拼多多-算法实习生
晚上的笔试,过了三道半
第一题 多多的压缩编码II
还原压缩后的字符串
输入 10a1b1c
输出 aaaaaaaaaabc
思路
简单题
#include 第二题 多多的飞机大战游戏
多多最近下载了一款飞机大战的游戏,多多可以通过游戏上的不同发射按键来控制飞机发射子弹:
按下A键,飞机会发射出2枚子弹,每个子弹会对命中的敌人造成1点固定伤害,但不能作用于同个敌人。
按下B键,飞机会发射出1枚子弹,子弹会对命中的敌人造成巨额伤害并瞬间将其秒杀。
多多是个游戏高手,总是能操控子弹命中想要命中的敌人。这个游戏—共有 T 个关卡,消灭当前关卡全部敌人后,发射出去多余的子弹会消失,游戏会自动进入下一个关卡。
假设每个关卡都会在屏幕中同时出现N个敌人,这N个敌人所能承受的伤害也已经知道。多多想知道,每个关卡自己最少按几次发射按键就可以将敌人全部消灭。
输入描述
第一行输入一个固定数字T(1<=T=1000)表示关卡的总数量,N(1<=N<=200)表示每个关卡出现的敌人数量。
接下来T行,每行有N个数字D1,D2,…,Dw(1<= Di <= 200)分别表示这N个敌人所能承受的伤害。
输出描述
结果共有N行,每行一个数字,分别表示对于这个关卡,最少按几次发射按键就可以将敌人全部消灭。
思路
承受伤害为1按A键,大于1则直接按B键
#include 第三题 多多的团建计划
多多君准备了三个活动(分别编号A、B和C),每个活动分别有人数上限以及每个人参加的费用。
参加团建的有N个人(分别编号1~N),每个人先投票选择若干个意向的活动,最终每个人只能参加其中一个。
多多君收集完投票结果后,发现如何安排成为了大难题:如何在满足所有人的意向的情况下,使得活动的总费用最少。
于是多多君找到了擅长编程的你,希望你能帮助找到个合理的团建计划。
输入描述
第一行,一个整数N(1<=N<=100),代表准备参加活动的人数。
接下来N行,每行一个由 “ABC” 组成的字符串,其中第i行表示第i个人投票了哪几个活动。输入保证字符串非空,且由大写的 “ABC” 字符组成。
最后三行,每行两个整数,分别表示三个活动的人数上限以及每个人参加的费用。
输出描述
输出共2行
如果能满足所有人的要求,第一行输出 “YES”,第二行输出最少的总费用。
如果不能满足所有人的要求,第一行输出 “NO”,第二行输出最多能满足多少人。
思路
本来想用贪心,但觉得贪心策略不一定对,就直接用dfs暴力枚举所有可能了,好像得了40-60分,太久了,忘了
但使用贪心虽然得不到满分,也有80-90分了,不能一昧地暴力回溯
#include 第四题 多多的餐厅客流量
多多君开了一家自助餐厅,为了更好地管理库存,多多君每天需要对之前的客流量数据进行分析,并根据客流量的平均数和中位数来制定合理的备货策略。
输入描述
第一行一个整数N,表示餐厅营业总天数(0
第二行共N个整数,分别表示第i天的客流量R:(0= R:1, 000, 000)。
输出描述
输出共两行:
第一行长度为N,其中第i个值表示前i天客流量的平均值;第二行长度为N,其中第i个值表示前i天客流量的中位数。
一共有N天,每天的客流量为 Ri,求第1天到第i天的平均数和中位数,结果四舍五入保留整数。
思路
没啥思路,就用插入排序过了,标准方法是295. 数据流的中位数
#include 2023-3-15 阿里机试
题目链接: 大厂真题|3月15日阿里春招笔试三道题
晚上的笔试,七道单选,八道多选,三道编程题,编程题过了2道半,不能使用本地IDE,故没当时的代码(临结束的时候应该把所有的代码拷贝到剪切板的)
第一题

思路
满二叉树,首先根据数组构建二叉树,而后寻找根节点,最后递归求解满二叉树,仅当两个子树皆为满二叉树且节点数目相同时该树为满二叉树
按记忆打的,不一定对
#include 第二题

三个数最大值减最小值=1,使用map记录数组与出现次数,对每个数字处理number与number+1的次数问题,注意结果可能超过int表示范围,需用long long存储
按记忆打的,不一定对
#include 第三题

思路
由于是第三题,所以我默认它很难,我就直接使用暴力回溯写了一遍
数组排序
dfs:
0: 达到终止条件,计算极差
1: 将数组首部数据乘2
2: dfs
3: 还原数组
4: 将数组尾部数据除2
5: dfs
6: 还原数组
细想一下可以知道,这根本不需要dfs,只需要for循环即可,不过我养成了思维定式,第三题一律暴力回溯
前面i个数据乘2,后面k-i个数据除2
for(int i=0;i<=k;i++){
for(int j=0;j<i;j++){
首部数据乘2
}
for(int j=0;j<k-i;j++){
尾部数据除2
}
}
另外我使用全排列写了一遍,不再使用以上的策略,直接所有情况枚举一遍
for(int i=start;i<vec.size();i++){
swap(vec[i],vec[start];
当前数字乘2
dfs
还原数字
当前数字除2
dfs
还原数字
swap(vec[i],vec[start];
}
最终我的解法都以超时结束,不知道用for循环实现可以得多少分
2023-3-16 蚂蚁机试
题目链接:「技术笔试」蚂蚁金服 2023-03-16
最终得分2.3分,第三题写了40分钟只得了30分,一直没找到bug
第一题 整数抽取
1e14 范围以内的一个正整数,将其每一数位上的奇数和偶数分别抽取出来组成两个新的数字,求这两差的绝对值。
思路
先将数字压入栈,然后计算奇数 偶数大小,上面的题解使用的是字符串存储数字,省去了压栈这一步
#include 第二题 组装电脑
n 组零件,每组零件有若干种,每一种有一个价格和性能。你需要从每组里面选出一种零件,使得总价格不超过 x,并且性能总和最大。
n <= 40, 所有零件的种类数不超过 40,其他数值 1e9。
思路
首先简单判断一下是否能完成组装,不能就直接返回,能的话就使用dfs穷举所有可能,找到最大性能
#include 第三题 带传送阵的矩阵游离
n 行 m 列的矩阵,每个位置上有一个元素。你可以上下左右行走,代价是前后两个位置元素值差的绝对值。另外,你最多可以使用一次传送阵(只能从一个数跳到另外一个相同的树),求从走上角走到右下角最少需要多少时间。
1 <= n, m <= 500, 1 <= aij <= 1e9。
思路
刚开始想了想,如果用dfs,应该能得30-60分,但当时时间也挺多的,就想完全通过。方法就是计算各点到起点的距离,计算各点到终点的距离,设使用传送阵的起始点为x,终点为y,最终的路径长度即为dist_form_start[x] + 0(传送阵代价) + dist_to_end[y],可惜代码有bug,只得了30分,我觉得我思路是没问题的
以下为有bug的版本,先计算两个最短距离,然后使用传送计算最终距离
额,好像优先队列没设置为小顶堆,有点尴尬,这样都能得30分,运气不错
设置方式为
// 自带的比较函数
priority_queue<TP, vector<TP>, greater<TP>> q;
// 自定义比较函数
auto cmp = [](const pair<int, int>& p1, const pair<int, int>& p2) -> bool { return p1.second > p2.second; };
priority_queue<pair<int, int>, vector<pair<int, int>>, decltype(cmp)> qu(cmp);
#include 相比之下,牛客网上的题解就简洁多了,多加一个维度k,对维度同样使用状态转移,更加通用的做法,并且在处理方向上,我还是用习惯的方法,对每个方向进行枚举,而题解中则使用dir数组进行统一处理,既方便又不容易出错,map赋值时我还对是否存在该值进行分类讨论,实际上是不需要的,如果不存在map会先设置默认值而后进行更新
for (int i = 0; i < 4; i++) {
int nx = x + dir[i][0], ny = y + dir[i][1];
if (nx < 0 || nx >= n || ny < 0 || ny >= m || v[nx][ny][z] == 1) continue;
if (d[nx][ny][z] > dist + abs(a[x][y] - a[nx][ny])) {
d[nx][ny][z] = dist + abs(a[x][y] - a[nx][ny]);
q.push({d[nx][ny][z], nx, ny, z});
}
}
2023-03-19 米哈游机试
题目链接:全网首发-真题分享|3月19日米哈游校招研发岗三道题
参考题解:
米哈游笔试题目思路(客户端卷)
米哈游后端笔试题解
第一题
米小游拿到了一个矩阵,矩阵上有一格有一个颜色,为红色( R )。绿色( G )和蓝色( B )这三种颜色的一种。然而米小游是蓝绿色盲,她无法分游蓝色和绿色,所以在米小游眼里看来,这个矩阵只有两种颜色,因为蓝色和绿色在她眼里是一种颜色。米小游会把相同颜色的部分看成是一个连通块。请注意,这里的连通划是上下左右四连通的。由于色盲的原因,米小游自己看到的连通块数量可能比真实的连通块数量少。你可以帮米小游计算连通块少了多少吗?
思路
看到连通分量,就自然而然想用并查集实现,实际上只需要连接两个方向的节点
#include dfs的解法如下,比并查集少一点代码,写起来快点
#include 第二题
米小游拿到了一个字符串 s 。她可以进行任意次以下两种操作:
1 删除 s 的一个 “mhy” 子序列。
2 添加一个 “mhy” 子序列在 s 上。
例如,给定 s 为 “mhbdy” ,米小游进行一次操作后可以使 s 变成 “bd” ,或者变成 “mhmbhdyy” 。
米小游想知道,经过若干次操作后 s 是否可以变成 t ?
注:子序列在原串中的顺序也是从左到右,但可以不连续。
思路
觉得写不出来,就直接进行骗分策略,看了别人的题解才发现解法很简单,最重要的是想到mhy三个字母的序列不重要

#include 第三题

思路:
我的思路与题解一样,只不过我少了倍数预处理的一步,直接两层for循环找到因数更新dp数组
#include 2023-03-23 腾讯音乐笔试
题目:3.23 腾讯音乐 暑期 实习 技术类 笔试
中途肚子痛,提前半小时交卷了,第一题写了一半,第二题dfs骗了几十分,第三题签到
笔试或面试前千万别吃坏肚子
第一题

这个问题可以分解成两个子问题:
1 通过层序遍历得到奇偶层节点个数
2 假设奇数层节点个数为k,解决是否能从[1,n]中选择k个数,总和为target问题
若1-n总和为偶数,则target为sum/2,若为奇数,则target为sum/2或sum/2+1
代码片段如下:(不一定对)
第一步:层序遍历
TreeNode* fun(TreeNode* root) {
queue<Info> qu;
int one = 0; // 奇数节点数
int two = 0; // 偶数节点数
stack<TreeNode*> one_stack; // 奇数节点栈
stack<TreeNode*> two_stack; // 偶数节点栈
qu.emplace(root, 1);
while (!qu.empty()) {
Info info = qu.front();
TreeNode* node = info.first;
int level = info.second;
qu.pop();
if (level % 2 == 1) {
one++;
one_stack.emplace(node);
} else {
two++;
two_stack.emplace(node);
}
if (node->left != nullptr) { // 将左子树节点压入队列
qu.emplace(node->left, level + 1);
}
if (node->right != nullptr) { // 将右子树节点压入队列
qu.emplace(node->right, level + 1);
}
}
}
第二步:选择k个数总和为target
双指针法求得可能结果
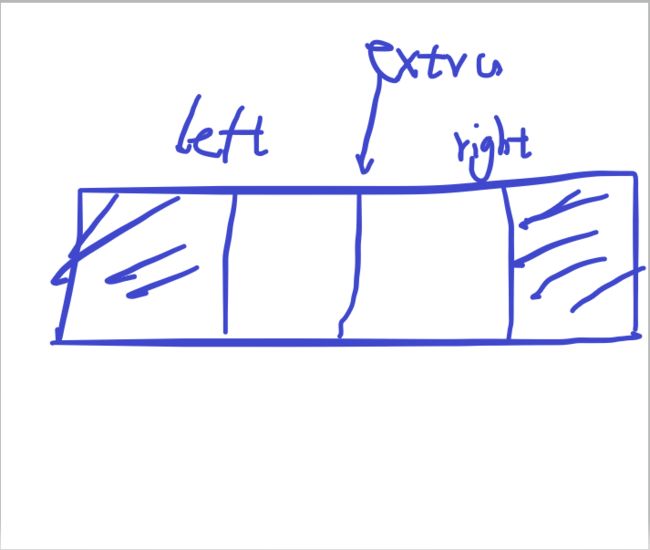
刚开始左区域最大,右区域为空,此时sum最小,而后一直将left right向左移动,增大sum,直至sum>target
#include 第二题

算法实现中为避免函数参数过多,可以将公有的数据结构放在类成员中,且没必要遵循命名规范(类成员名后加_),类成员的设置应该在具体实现前想好。
第二题看别人说是最大值最小化问题,使用二分+贪心的方法解决,但没看到啥具体实现
(二分答案,贪心验证答案是否符合,符合就再缩小一点答案,不符合就扩大一点 )
#include 第三题
签到题
#include 2023-03-26 腾讯笔试
题目:腾讯笔试记录0326(研发)
就写出了第一第二题,第三题题目有点问题,导致我写了40分钟没得啥分,一直没理解最后一个样例是怎么来的,第四第五题一看就是我不会的题目,随便写了写
第一题 链表操作
链表中相邻节点两两一组,然后相邻两组之间进行交换
类似的题目:25. K 个一组翻转链表
直接将链表节点指针存入数组,便于理解
class Solution {
public:
ListNode* reorderList(ListNode* head) {
ListNode virt_head(-1); // 虚拟头节点
virt_head.next = head;
vector<ListNode*> arr;
ListNode* cur = head;
while (cur != nullptr) {
arr.emplace_back(cur);
cur = cur->next;
}
int num = arr.size();
ListNode* prev = &virt_head; // 待处理组的前一个节点
for (int i = 0; i + 3 < num; i += 4) {
prev->next = arr[i + 2]; // 指向第二组的头节点
arr[i + 1]->next = arr[i + 3]->next; // 指向第二组后一个节点
prev = arr[i + 1]; // 更新prev节点
arr[i + 3]->next = arr[i]; // 更新第二组的next为第一组头节点
}
if (num % 4 == 3) { // 剩下3个节点,特殊处理
prev->next = arr[num - 1];
arr[num - 2]->next = arr[num - 1]->next;
arr[num - 1]->next = arr[num - 3];
}
return virt_head.next;
}
};
第二题 重组字符串
给定N个字符串,每个字符串全部由小写字母组成,且每个字符串的长度最多为8,请你断有多少重组字符串,重组字符串有以下规则:1.从每个字符串里面都抽取1个字母组成。2.新字符串不能有2个相同的字母。请问总共能组成多少个重组字符串。
字符串长度比较小,用dfs暴力枚举即可
#include 第三题 最小权值排列数组
给定2个整数数组A,B,数组长度都为N,数组B为权值数组,权值数据范国为[0,2],请你构造一个数组C,满足以下条件:
1,长应为N
2.数组元素范国为[1,N],且元素值不能更复,即为N的一个排列
3.如果数组下标i
4数组C与数组A每个元素之差的和的绝对值最小.
按理来说样例的答案应该是98,但样例是104,一直想不出来为什么

#include 2023-03-28 百度笔试
题目链接:3.28百度笔试复盘
图解SQL的inner join、left /right join、 outer join区别

编程题过了2.8道,第三题一直超时,只得了80分
第一题
题目:

签到题
#include 第二题
题目:
标准解法是单调栈,不过我当时没想到,就用数组存从当前位置往右看最大value的索引
#include 第三题
题目:

只得了80分,要么时间超时,要么内存使用过多,可以优化的点在于输入x y时将信息暂存到某一个地方,而后在树遍历的过程中一次性计算所有,而不是每次都遍历x的所有子节点,并与info相加,不过最后没时间了,就没实现
#include 面试代码题
可以刷一刷CodeTop
链表是否存在环
给你一个链表的头节点 head ,判断链表中是否有环。
#include C实现
字符串数组去重
将字符串数组中重复的字符串去掉。
#include C实现
二分查找
实现第一个大于等于,最后一个小于等于操作,见博客重载记录 二分查找
流控算法
实现一个简单的check函数,处理函数执行前调用check函数,若TPS超过MAX TPS则返回失败
bool check(){}
见博客重载记录 流控算法
比较版本号
165. 比较版本号
class Solution {
public:
// std::size_t std::__cxx11::string::find(char __c, std::size_t __pos) const noexcept
vector<int> getVersion(string& version) {
vector<int> ans;
version.push_back('.'); // 在末尾加上.,统一处理
int last_pos = 0;
int pos;
while ((pos = version.find('.', last_pos)) != string::npos) {
ans.emplace_back(stoi(version.substr(last_pos, pos - last_pos)));
last_pos = pos + 1;
pos = version.find('.', last_pos);
}
return ans;
}
int compareVersion(string version1, string version2) {
vector<int> v1 = getVersion(version1);
vector<int> v2 = getVersion(version2);
// 在尾部补齐0
if (v1.size() > v2.size()) {
int padding = v1.size() - v2.size();
for (int i = 0; i < padding; i++) {
v2.emplace_back(0);
}
} else {
int padding = v2.size() - v1.size();
for (int i = 0; i < padding; i++) {
v1.emplace_back(0);
}
}
// 比较版本号
for (int i = 0; i < v2.size(); i++) {
if (v1[i] > v2[i]) {
return 1;
} else if (v1[i] < v2[i]) {
return -1;
}
}
return 0;
}
};
写代码时卡壳了,主要的错误在于:
1:忘记了find的参数原型
std::size_t std::__cxx11::string::find(char __c, std::size_t __pos) const noexcept
__c和pos的位置写反了
2:v1 v2都传入了version1
vector<int> v1 = getVersion(version1);
vector<int> v2 = getVersion(version1);
3:没有补齐操作,若共用的部分相等则长度大的版本号更大,忽略了修订号有可能为0的情况,1.0.0与1.0
优化版本1:
#include 对于长度不一致的数组,采用或操作的方式进行循环遍历,减少代码量,思路有点像字符串相加中的代码
class Solution {
public:
string addStrings(string num1, string num2) {
int i = num1.length() - 1;
int j = num2.length() - 1;
int carry = 0;
string ans;
while ((i >= 0) || (j >= 0) || (carry > 0)) {
int x = (i >= 0) ? num1[i] - '0' : 0;
int y = (j >= 0) ? num2[j] - '0' : 0;
int sum = x + y + carry;
ans.push_back(sum % 10 + '0');
carry = sum / 10;
i--;
j--;
}
reverse(ans.begin(), ans.end());
return ans;
}
};
优化版本2:
class Solution {
public:
int compareVersion(string version1, string version2) {
// 末尾加.,统一处理
version1.push_back('.');
version2.push_back('.');
int i = 0;
int j = 0;
while (i < version1.length() || j < version2.length()) {
// 计算x y大小
long long x = 0;
while (i < version1.length()) {
if (version1[i] == '.') {
break;
}
x = x * 10 + version1[i] - '0';
i++;
}
long long y = 0;
while (j < version2.length()) {
if (version2[j] == '.') {
break;
}
y = y * 10 + version2[j] - '0';
j++;
}
// 比较x y大小
if (x > y) {
return 1;
}
if (x < y) {
return -1;
}
// 跳过.
i++;
j++;
}
return 0;
}
};
遍历时计算数字大小并比较
字符串最长单词
给定一个字符串数组,求其中有效单词(只能包含字母)的最大长度。示例:[abc abc0 abc–d ab] answer:3
版本1:传统的切割字符串然后计算最大长度
#include 版本2:遍历时计算单词长度并判断单词是否有效
#include LRU算法
146. LRU 缓存
使用STL list实现
#include 注意list删除后相应迭代器也失效了
简单示例:
#include 使用自定义双向链表,更新LRU时不需要修改map
#include 重排链表
143. 重排链表

遇到的问题:
1:面试时根本没想到解法,面试官给出了解法后实现上又出现了一些问题
2:链表反转函数实现受反转链表 II影响使用了虚拟头节点,却没有真正理解那道题中使用虚拟头节点的意义
3:前半部和后半部的连接没有断开,导致无限循环
美团的面试官都很nice,以后要多刷链表相关的算法题了
class Solution {
public:
ListNode* reverseList(ListNode* head) { // 链表反转 三指针法
ListNode* prev = nullptr;
ListNode* curr = head;
ListNode* next;
while (curr != nullptr) {
next = curr->next;
curr->next = prev;
prev = curr;
curr = next;
}
return prev;
}
ListNode* mergeList(ListNode* node1, ListNode* node2) { // 合并链表
ListNode virt_head(-1);
ListNode* node = &virt_head;
while (node1 != nullptr || node2 != nullptr) { // 先选择node1的节点,后选择node2的节点
if (node1 != nullptr) {
node->next = node1;
node = node1;
node1 = node1->next;
}
if (node2 != nullptr) {
node->next = node2;
node = node2;
node2 = node2->next;
}
}
return virt_head.next;
}
void reorderList(ListNode* head) {
if (head == nullptr || head->next == nullptr) {
return;
}
ListNode virt_head(-1, head);
ListNode* prev = &virt_head; // 慢指针的前继节点
ListNode* slow = head; // 慢指针
ListNode* fast = head; // 快指针
while (fast != nullptr && fast->next != nullptr) {
prev = slow;
slow = slow->next;
fast = fast->next->next;
}
prev->next = nullptr; // 断掉前后链表的连接
ListNode* latter_half = reverseList(slow); // 将后半部链表反转
head = mergeList(head, latter_half); // 再次合并前后链表
}
};
寻找后序遍历的后继节点
先进行分类讨论,处理简单的情况,再单独左子节点情况进行处理
当节点为左子节点且右子节点不为空时,需要想明白后继节点一定是叶子节点,后序遍历的顺序是左右根,那么先持续左再尝试向右,直至叶子节点
struct node {
struct node *left;
struct node *right;
struct node *parent;
};
struct node *next_postorder(const struct node *node) {
if (node->parent == NULL) { // 根节点
return NULL;
}
struct node *node_parent = node->parent;
if (node_parent->right == node) { // 为父节点的右子节点
return node_parent;
}
if (node_parent->right == NULL) { // 为父节点的左子节点,但右子节点为空
return node_parent;
}
struct node *next = node_parent->right; // 从右子节点开始
while (next->left != NULL || next->right != NULL) { // 不为叶子节点
while (next->left != NULL) { // 持续向左
next = next->left;
}
if (next->right != NULL) { // 向右拓宽路径
next = next->right;
}
}
return next;
}
手写快排
/*
写一个C/C++的函数供别人调用,实现以下功能
给定任意一个字符串,对其中的每个字符进行忽略字母大小写的排序
*/
#include