Full-Face Appearance-Based Gaze Estimation论文翻译
It’s Written All Over Your Face:Full-Face Appearance-Based Gaze Estimation论文翻译
1.摘要
眼睛注视是人类情感分析的重要非语言线索。 最近的注视估计工作表明,来自全脸区域的信息可以提高性能。 进一步推动这一想法,我们提出了一种基于外观的方法,与计算机视觉领域的长期工作相比,该方法仅将全脸图像作为输入。 我们的方法使用卷积神经网络对面部图像进行编码,空间权重应用于特征图,以灵活地抑制或增强不同面部区域的信息。 通过广泛的评估,我们表明我们的全脸方法在 2D 和 3D 凝视估计方面显着优于最先进的方法,在 MPIIGaze 上实现了高达 14.3% 的改进,在与人无关的 3D 凝视估计上实现了 27.7% 的 EYEDIAP 改进。 我们进一步表明,这种改进在不同的照明条件和凝视方向上是一致的,对于最具挑战性的极端头部姿势尤其明显。
1、介绍
鉴于人机交互 [21]、情感计算 [4] 和社会信号处理 [30] 等不同应用的重要性,计算机视觉领域的大量作品研究了估计人眼凝视 [7] 的问题。 .虽然早期的方法通常需要可以控制照明条件或头部姿势的设置 [17、22、27、31],但使用卷积神经网络 (CNN) 的最新基于外观的方法为日常环境中的注视估计铺平了道路以大量的照明和外观变化为特征[36]。尽管有这些进步,以前基于外观的方法只使用从一只或两只眼睛编码的图像信息。
Krafka 等人的最新结果。表明将眼睛和面部图像作为输入的多区域 CNN 架构可以有益于凝视估计性能 [13]。虽然直观上,人类注视与眼球姿势密切相关,因此眼睛图像应该足以估计注视方向,但确实可以想象,特别是基于机器学习的方法可以利用来自其他面部区域的附加信息。例如,这些区域可以在比眼睛区域可用的图像区域更大的图像区域上对头部姿势或照明特定信息进行编码。然而,(更有效和优雅的)仅面部方法是否可行,哪些面部区域对于这种基于全脸外观的方法最重要,以及当前的深层架构是否可以将信息编码在这些地区。此外,[13] 中的视线估计任务仅限于简单的 2D 屏幕映射,因此全脸方法用于 3D 视线估计的潜力仍不清楚。
这项工作的目标是通过对基于 2D 和 3D 外观的注视估计的全脸方法的潜力进行详细分析来阐明这些问题(见图 1)。这项工作的具体贡献有两个方面。首先,我们提出了一种用于凝视估计的全脸 CNN 架构,与凝视估计的长期传统形成鲜明对比,它将全脸图像作为输入并直接回归到 2D 或 3D 凝视估计。我们将我们的全脸方法与现有的仅眼睛 [36] 和多区域 [13] 方法进行定量比较,并表明它可以在具有挑战性的 MPIIGaze 数据集上实现 4.8° 的独立于人的 3D 凝视估计精度,从而提高比现有技术高 14.3%。其次,我们提出了一种空间权重机制,以将有关全脸不同区域的信息有效地编码到标准的 CNN 架构中。该机制在卷积层的激活图上学习空间权重,反映不同面部区域中包含的信息 [[...]] 通过进一步的定量和定性评估,我们表明所提出的空间权重网络有助于学习估计器对当前数据集中可用的照明条件以及头部姿势和注视方向的显着变化具有鲁棒性。
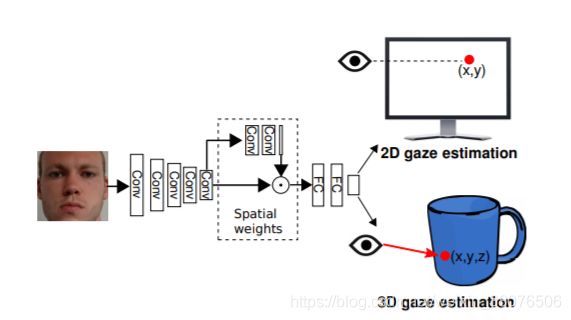
图 1:建议的基于全脸外观的凝视估计管道的概述。 我们的方法仅将人脸图像作为输入,并使用卷积神经网络对特征图应用空间权重来执行 2D 和 3D 凝视估计。
2、先关工作
我们的工作与之前针对 2D 和 3D 凝视估计任务的基于外观的凝视估计有关,特别是最近的多区域方法,以及在 CNN 中编码空间信息的方法。
Appearance-Based Gaze Estimation:注视估计方法通常分为基于模型或基于外观。虽然基于模型的方法使用眼睛和面部的几何模型来估计注视方向 [3, 29, 34],但基于外观的方法直接从眼睛图像回归到注视方向。早期的基于外观的方法假设每个用户都有固定的头部姿势和训练数据 [2, 27, 31]。后来的工作侧重于从单眼 RGB [16, 26] 或深度图像 [5] 进行的与姿势无关的注视估计,但仍需要针对个人的训练。实现姿势和个人独立的一个有希望的方向是基于学习的方法,但这些方法需要大量标记的训练数据 [13、20、25、36]。
因此,近年来在日常环境中收集的凝视估计数据集越来越多 [9, 19, 24],包括一些大规模 [13, 36],或由合成数据组成 [25, 32, 33]。在这项工作中,我们还使用留一人交叉验证方案专注于这一最具挑战性的姿势和个人独立凝视估计任务。
2D vs. 3D Gaze Estimation :基于外观的凝视估计方法可以根据回归目标是 2D 还是 3D 进一步分类。 早期的工作假设目标人的头部姿势是固定的 [2, 27, 29, 31],因此专注于 2D 凝视估计任务,其中训练估计器以输出屏幕上的凝视位置。 虽然最近的方法使用 3D 头部姿势 [18, 26] 或面部边界框 [13] 的大小和位置来允许头部自由移动,但它们仍将任务制定为直接映射到 2D 屏幕注视位置。 这些 2D 方法背后的基本假设是目标屏幕平面在相机坐标系中是固定的。 因此,它不允许在训练后自由移动相机,这可能是一个实际限制,尤其是对于基于学习的独立于人的估计器。
相比之下,在 3D 凝视估计中,估计器被训练为在相机坐标系中输出 3D 凝视方向 [5, 16, 18, 20, 33, 36]。 3D 公式与姿势和人无关的训练方法密切相关,最重要的技术挑战是如何在不需要太多训练数据的情况下有效地训练估计器。 为了促进模型训练,Sugano 等人。 提出了一种数据归一化技术,将外观变化限制在一个单一的、归一化的训练空间中 [25]。 虽然它需要额外的技术组件,例如 3D 头部姿势估计,但 3D 方法具有技术优势,因为它们可以估计任何目标对象和相机设置的注视位置。 由于这两种方法处理几何信息的方式不同,因此 2D 和 3D 方法之间全脸输入的作用也可能不同。
多区域注视估计: 尽管有这些进步,但以前的大多数工作都使用单眼图像作为回归器的输入,并且只有少数考虑过替代方法,例如使用两个图像、每只眼睛一个 [10] 或覆盖双眼的单个图像 [9]。 克拉夫卡等人。 最近提出了一种多区域 2D 凝视估计方法,该方法将单个眼睛图像、面部图像和面部网格作为输入 [13]。 他们的结果表明,添加人脸图像可能有益于基于外观的凝视估计。 我们的工作首先探索使用全脸信息进行 2D 和 3D 基于外观的凝视估计的潜力。 推进这一想法,我们进一步提出了第一种方法,该方法仅以真正端到端的方式从全脸图像中学习注视估计器。
CNN 中的空间编码: 卷积神经网络不仅在分类 [14] 上成功,而且在回归 [23] 中也很成功,包括注视估计 [36]。 之前的一些工作更有效地编码了空间信息,例如通过裁剪图像的子区域 [6, 11] 或同等对待图像上的不同区域 [8]。 汤普森等人。 在全连接层之前使用空间 dropout 以避免在训练过程中过度拟合,但 dropout 扩展到整个特征图而不是一个单元 [28]。 相反,我们提出了一种空间权重机制,该机制对全脸不同区域的权重进行编码,抑制噪声并增强低激活区域的贡献。
3.注视估计任务
在详细介绍基于全脸外观的凝视估计的模型架构之前,我们首先制定并讨论两种不同的凝视估计任务:2D 和 3D 凝视估计。 这项工作的一个关键贡献是研究这两项任务的基于全脸外观的凝视估计。 这不仅导致了通用模型架构,而且还提供了对从两种任务公式的全面信息中获得的差异和好处的宝贵见解。
尽管 3D 任务公式为正确处理复杂的 3D 几何体带来了额外的技术挑战,但它可以应用于不同的设备和设置,而无需假设固定的相机屏幕关系。 因此,这种表述是最通用的,也是最实用的。 如果应用场景能够承受固定的屏幕位置,那么 2D 公式在技术上的要求较低,因此有望显示出更好的精度。
3.1.二维注视估计
作为最直接的策略,二维注视估计任务被表述为从输入图像 I 到二维屏幕注视位置 p 的回归,如 p = f(I),其中 f 是回归函数。通常 p 在目标屏幕的坐标系中直接定义 [17, 26, 27, 29] 或更一般地,在相机坐标系 [13] 中定义的虚拟平面。由于眼睛外观和注视位置之间的关系取决于头部的位置,因此回归函数除了眼睛和面部图像之外,通常还需要 3D 头部姿势 [29] 或面部边界框位置 [10, 13]。
需要注意的是,除了固定目标平面之外,该公式中的另一个重要假设是输入图像 I 始终来自具有固定内在参数的同一相机。尽管之前的工作没有明确讨论这个问题,但如果不对投影模型的差异进行适当的处理,训练后的回归函数就不能直接应用于不同的相机。
3.2. 3D 凝视估计
相比之下,3D 凝视估计任务被表述为从输入图像 I 到 3D 凝视向量 g = f(I) 的回归。 与 2D 情况类似,回归函数 f 通常将 3D 头部姿势作为附加输入。 注视向量 g 通常定义为源自 3D 参考点 x 的单位向量,例如眼睛的中心 [5, 16, 18, 33, 36]。 通过假设一个校准过的相机和目标平面的 3D 姿态信息,可以通过将凝视位置 p 投影到相机坐标系来转换 3D 凝视向量 g。 可以通过将 3D 视线矢量 g 与目标平面相交来获得 2D 情况下的视线位置 p。
图像归一化:为了处理不同的相机参数并有效地解决跨人训练的任务,Sugano 等人。提出了一种用于基于 3D 外观的凝视估计的数据归一化程序 [25]。基本思想是对输入图像应用透视扭曲,以便可以在具有固定相机参数和参考点位置的归一化空间中执行估计。给定输入图像 I 和参考点 x 的位置,任务是计算转换矩阵 M = SR。
R 是旋转矩阵的逆矩阵,该矩阵旋转相机,使其观察参考点,并且相机和头部坐标系的 x 轴变得平行。缩放矩阵 S 被定义为使得参考点位于距归一化相机坐标系原点的距离为 ds 处。
缩放矩阵 S 被定义为使得参考点位于距归一化相机坐标系原点的距离为 ds 处。转换矩阵 M 将输入相机坐标系中的任何 3D 点旋转和缩放到归一化坐标系,并且可以使用图像转换矩阵 W = CsMC-1 r 通过透视扭曲将相同的转换应用于输入图像 I。 Cr 是对应于从相机校准获得的输入图像的投影矩阵,Cs 是另一个预定义参数,用于定义归一化空间中的相机投影矩阵。
在训练期间,所有具有真实注视向量 g 的训练图像 I 在训练空间中归一化或直接合成 [25, 33],由 ds 和 Cs 定义。 地面真实注视向量也被归一化为 gˆ = M g,而在实践中,它们被进一步转换为假设单位长度的角度表示(水平和垂直注视方向)。 在测试时,测试图像以相同的方式归一化,并通过归一化空间中训练的回归函数估计归一化空间中它们对应的注视向量。 然后通过 g = M−1gˆ 将估计的注视向量转换回输入相机坐标。
4. Full-Face Gaze Estimation with a Spatial Weights CNN
对于 2D 和 3D 凝视估计情况,核心挑战是学习回归函数 f。 虽然大量工作只考虑使用眼睛区域完成这项任务,但我们的目标是探索从全脸提取信息的潜力。
我们的假设是眼睛以外的面部其他区域包含用于注视估计的有价值的信息。

图 2:用于基于全脸外观的凝视估计的空间权重 CNN。 输入图像通过多个卷积层以生成特征张量 U。所提出的空间权重机制将 U 作为输入以生成权重映射 W,该权重映射 W 使用元素级乘法应用于 U。 输出特征张量 V 被馈送到以下全连接层,以根据任务输出最终的 2D 或 3D 凝视估计。
如图 2 所示,为此我们提出了一个具有空间权重(spatial weights CNN)的 CNN,用于基于全脸外观的 2D 和 3D 凝视估计。为了有效地使用来自全脸图像的信息,我们建议使用额外的层来学习空间权重以激活最后一个卷积层。这种空间加权背后的动机是双重的。首先,可能有一些图像区域对注视估计任务没有贡献,例如背景区域,必须抑制来自这些区域的激活以获得更好的性能。其次,更重要的是,与预期总是有助于凝视估计性能的眼睛区域相比,来自其他面部区域的激活预计是微妙的。面部外观的作用还取决于各种输入相关条件,例如头部姿势、注视方向和光照,因此必须根据输入图像外观进行适当增强。虽然从理论上讲,这种差异可以通过普通网络学习,但我们选择引入一种机制,强制网络更明确地学习和理解面部的不同区域对于估计给定测试样本的凝视具有不同的重要性。为了实现这种更强的监督,我们使用了 [28] 中的三个 1 × 1 卷积层加上整流线性单元层的概念作为基础,并将其调整到我们的全脸注视估计任务中。具体来说,我们没有生成多个热图(一个用于定位每个身体关节),我们只生成了一个热图,对整个面部图像的重要性进行了编码。然后,我们将该权重图与前一个卷积层的特征图进行元素级乘法。图 2 显示了一个示例权重图,从 MPIIGaze 数据集的所有样本中取平均值。
4.1. Spatial Weights Mechanism
提出的空间权重机制包括三个额外的卷积层,过滤器大小为 1×1,后跟一个整流线性单元层(见图 2)。 给定大小为 N ×H ×W 的激活张量 U 作为来自卷积层的输入,其中 N 是特征通道的数量,H 和 W 是输出的高度和宽度,空间权重机制生成一个 H × W 空间权重矩阵 W. 加权激活图是从 W 与原始激活 U 的逐元素乘法获得的

其中Uc是U的第c个通道,Vc对应同一个通道的加权激活图。 这些图被堆叠起来形成加权激活张量 V ,并被送入下一层。 与空间丢失 [28] 不同,空间权重机制不断对信息进行加权,并保留来自不同区域的信息。 相同的权重应用于所有特征通道,因此估计的权重直接对应于输入图像中的面部区域。
在训练过程中,前两个卷积层的滤波器权重从均值和 0.01 的高斯分布随机初始化,恒定偏差为 0.1。 最后一个卷积层的滤波器权重从高斯分布中随机初始化,均值为 0,方差为 0.001,偏差为 1。
关于 U 和 W 的梯度是

and
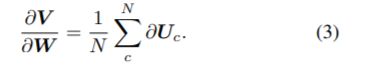
相对于 W 的梯度由特征图的总数 N 归一化,因为权重图 W 同等影响 U 中的所有特征图。
4.2. 实施细则
作为基线 CNN 架构,我们使用 AlexNet [14],它由五个卷积层和两个全连接层组成。 我们在最后一个全连接层之上训练了一个额外的线性回归层,以预测 2D 凝视估计的屏幕坐标中的 p 或 3D 凝视估计任务的归一化凝视向量 gˆ。 我们使用 LSVRC-2010 ImageNet 训练集 [14] 上的预训练结果来初始化五个卷积层,并在 MPIIGaze 数据集 [36] 上微调整个网络。 我们网络的输入图像大小为 448 × 448 像素,这导致在第 5 个卷积层的池化层之后大小为 256 × 13 × 13 的激活 U。
对于 2D 凝视估计,根据六个面部标志位置(四个眼角和两个嘴角)裁剪输入人脸图像。 虽然在实践中这被假定为使用面部对齐方法(例如 [1])来完成,但在以下实验中,我们使用了数据集提供的地标位置。 以6个地标的质心为人脸中心,宽度为地标间最大距离1.5倍的矩形作为人脸边界框。 损失函数是目标屏幕坐标系中预测和地面真实注视位置之间的ℓ1距离。
对于 3D 凝视估计,参考点 x 被定义为相同的六个面部标志的 3D 位置的中心。 我们将 MPIIGaze 提供的通用 3D 面部模型拟合到地标位置以估计 3D 头部姿势。 在图像归一化过程中,我们定义了 ds 和 Cs,使输入的人脸图像大小变为 448×448 像素。 在初步实验中,我们注意到 Zhang 等人提出的附加头部姿势特征。 [36] 没有提高全脸情况下的性能。 因此,在这项工作中,我们只使用了图像特征。 损失函数是归一化空间中预测和地面真实注视角度向量之间的ℓ1距离。
5. 评估
为了评估我们用于 2D 和 3D 凝视估计任务的架构,我们对两个当前的凝视数据集进行了实验:MPIIGaze [36] 和 EYEDIAP [19]。 对于 MPIIGaze 数据集,我们对所有 15 名参与者进行了留人交叉验证。 为了消除人脸对齐引起的错误,我们手动注释了六个人脸地标,用于数据归一化和图像裁剪。 在最初的评估中,每个参与者随机抽取了 1,500 个左眼和 1,500 个右眼样本。 为了直接比较,我们获得了对应于相同评估集的人脸图像,并在它们来自右眼时翻转了人脸图像。 我们基于面片的设置将面的中点(所有六个地标的中心)作为凝视方向的原点。
对于 EYEDIAP 数据集,我们使用屏幕目标会话进行评估,并从每个参与者的四个 VGA 视频中每 15 帧采样一张图像。 我们使用数据集提供的头部姿势和眼睛中心注释进行图像归一化,并将参考点设置为两个眼睛中心的中点。 眼睛图像的裁剪方式与 MPIIGaze 数据集相同。 我们将 14 名参与者随机分为 5 组并进行了 5 折交叉验证。
我们将我们的全脸注视估计方法与两个最先进的基线进行了比较:仅使用从一只眼睛编码的信息的单眼方法 [36] 以及拍摄眼睛图像的多区域方法 [13] 、人脸图像和人脸网格作为输入。
对于 EYEDIAP 数据集,我们使用屏幕目标会话进行评估,并从每个参与者的四个 VGA 视频中每 15 帧采样一张图像。 我们使用数据集提供的头部姿势和眼睛中心注释进行图像归一化,并将参考点设置为两个眼睛中心的中点。 眼睛图像的裁剪方式与 MPIIGaze 数据集相同。 我们将 14 名参与者随机分为 5 组并进行了 5 折交叉验证。
我们将我们的全脸注视估计方法与两个最先进的基线进行了比较:仅使用从一只眼睛编码的信息的单眼方法 [36] 以及拍摄眼睛图像的多区域方法 [13] 、人脸图像和人脸网格作为输入。
单眼: 基线方法之一是最先进的基于单眼外观的凝视估计方法 [36],它最初使用 LeNet [12, 15] 架构。 为了公平比较,我们改为使用 AlexNet 架构作为我们提出的模型(参见 4.2 小节)。 以眼角中心为中心裁剪眼部图像,宽度为角间距的1.5倍,并按照[36]中的建议调整为60×36像素。 在这种情况下,每只眼睛都成为模型的输入,参考点 x 被设置为内眼角和外眼角的中间。
iTracker:由于代码和模型都不可用,我们根据论文中提供的描述重新实现了 iTracker 架构 [13]。 面部图像以与我们提出的方法相同的方式裁剪,并调整为 224 × 224 像素。 以内眼角和外眼角的中点为图像中心,裁剪眼部图像,宽度为眼角间距的1.7倍,调整为224×224像素。 对于 2D 凝视估计任务,我们还使用了大小为 25 × 25 像素的人脸网格特征 [13]。 人脸网格对原始图像内的人脸大小和位置进行编码。 为了与我们提出的架构进行公平比较,我们还使用与 iTracker (AlexNet) 相同的 AlexNet CNN 架构评估了模型。 为了验证人脸输入的效果,我们还测试了 iTracker (AlexNet) 架构,仅将两只眼睛图像作为两只眼睛模型。
5.1.二维注视估计
图 3 总结了 2D 凝视估计任务的结果。每一行对应一种方法,如果没有另外说明,除了图像输入之外,还使用了人脸网格特征。左轴显示屏幕坐标系中估计和地面真实注视位置之间的欧几里得误差(以毫米为单位)。右轴显示了相应的角度误差,该误差是根据数据集提供的相机和监视器校准信息以及 3D 凝视估计任务的相同参考位置近似计算的。

图 3:以毫米(欧几里得误差)和度(角度误差)为单位的 MPIIGaze 数据集上的 2D 凝视估计误差。 面部网格用作附加输入。 误差棒表示标准偏差。
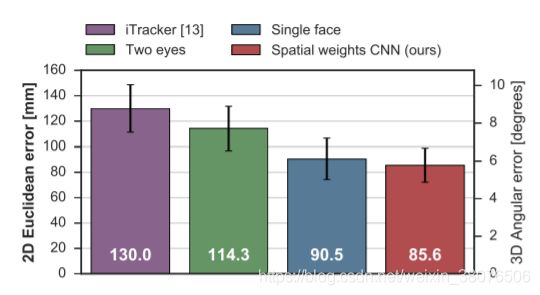
图 4:EYEDIAP 数据集上以毫米(欧几里得误差)和度数(角度误差)为单位的 2D 凝视估计误差。 误差棒表示标准偏差。
从图 3 中可以看出,所有以全脸信息作为输入的方法都明显优于单眼基线。单人脸图像模型取得了与 iTracker 和 iTracker (AlexNet) 模型竞争的结果。通过合并提出的空间权重网络,性能得到了进一步提高。与第二好的单人脸模型相比,所提出的空间权重网络实现了 7.2% 的统计显着性能提升(配对 t 检验:p < 0.01)。这些发现通常反映在图 4 所示的 EYEDIAP 数据集上,而整体性能最差的原因很可能是分辨率较低和训练图像数量有限。尽管 iTracker 架构的性能比两眼模型差,但我们提出的模型仍然表现最好。
5.2. 3D 凝视估计
图 5 总结了 3D 凝视估计任务的结果。 左轴显示了从估计的和真实的 3D 凝视向量直接计算的角度误差。 右轴显示了相应的欧几里得误差,通过将估计的 3D 视线矢量与屏幕平面相交来近似计算。 与2D凝视估计任务相比,iTracker与单人脸模型的性能差距更大(0.7度)。 由于基于AlexNet的iTracker模型可以达到与单人脸模型相似的性能,因此性能下降似乎部分是由于 到其网络架构。 我们提出的模型比 iTracker 实现了 14.3%(配对 t 检验:p > 0.01)的显着性能提升,并且性能与 2D 情况一致。

图 5:以度(角度误差)和毫米(欧几里得误差)为单位的 MPIIGaze 数据集上的 3D 凝视估计误差。 误差棒表示标准偏差。
如图 6 所示,所提出的模型在 EYEDIAP 数据集上的 3D 凝视估计任务中也取得了最佳性能。
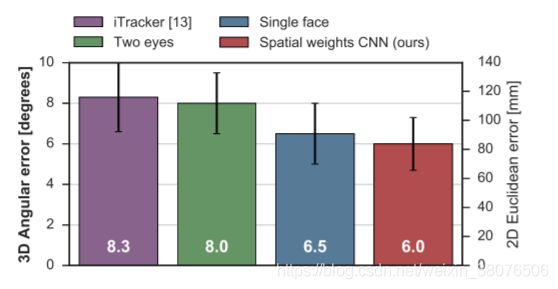
图 6:EYEDIAP 数据集上的 3D 凝视估计误差,以度(角度误差)和毫米(欧几里得误差)为单位。 误差棒表示标准偏差。
5.3.头部姿势和面部外观
关于为什么全脸输入可以帮助凝视估计任务的一个自然假设是它带来了头部姿势信息,这可以作为推断凝视方向的先验。在本节中,我们通过比较使用没有眼睛区域的人脸图像与简单的基于头部姿势的基线的性能来提供对这一假设的更多见解。更具体地说,使用 MPIIGaze 数据集,我们创建了面部图像,其中根据面部标志注释,两个眼睛区域都被灰色框遮挡。我们将使用眼睛遮挡面部图像的估计性能与:1) 直接将头部姿势视为凝视方向的朴素估计器,以及 2) 训练为从头部姿势输入输出凝视方向的线性回归函数。
这些方法用于 3D 估计任务的角度误差如图 7 所示。虽然使用眼部遮挡人脸图像的误差大于原始单人脸架构(5.5 度),但其性能优于基于头部姿势的基线估计器。这有点令人惊讶地表明,全脸输入的影响大于头部姿势信息,而面部外观本身有利于推断注视方向。
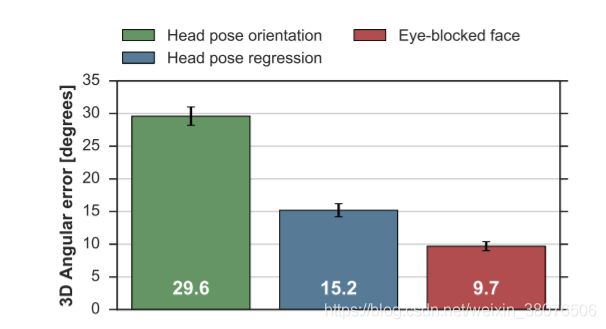
图 7:来自与头部姿势相关的不同模型的凝视估计误差。 这些数字是以度为单位的 3D 凝视估计的角度误差。 误差棒表示标准偏差。
5.4.不同面部区域的重要性
为了进一步分析不同面部区域对整体性能的贡献,我们针对 3D 凝视估计的不同因素生成了全脸模型的区域重要性图。如 [35] 中提出的,区域重要性图是通过在屏蔽部分输入图像后评估估计误差来生成的。具体来说,给定 448 × 448 的输入人脸图像,我们使用了一个大小为 64 × 64 像素的灰色蒙版,并以 32 像素步长的滑动窗口方式在整个图像上移动了这个蒙版。每个图像区域的重要性图是通过使用盒式滤波器平滑获得的 64 × 64 误差分布来获得的。凝视估计精度的下降幅度越大,面部该区域的重要性就越高。然后通过使用三个面部标志位置(眼角和嘴角的中心)扭曲整个图像来对齐各个人脸图像及其重要性图。最后,通过对所有图像求平均值来计算平均人脸块和平均区域重要性图。为了说明人脸图像输入的效果,我们将这些区域重要性图与两只眼睛(基线)和我们提出的全脸模型(我们的)之间的定量性能比较进行了比较。
光照条件: 最初的 MPIIGaze 论文根据不同的光照条件和注视范围对数据集进行了表征 [36]。 因此,我们首先探讨了是否以及哪些面部区域对这些照明条件的信息进行了编码。 与原始论文一样,我们使用脸部左右半部的平均强度值差异作为推断定向光的代理。 我们使用 k-means 聚类根据光照差异对所有 15 × 3, 000 图像进行聚类,并计算每个聚类的平均人脸图像和平均重要性图。 图 8 显示了相对于照明条件的结果样本区域重要性图。 从图中可以看出,在强烈的定向照明下(最左边和最右边的例子),脸部较亮的一侧需要眼睛周围更广泛的区域。 在所有光照条件下,所提出的方法始终比两眼模型表现得更好。
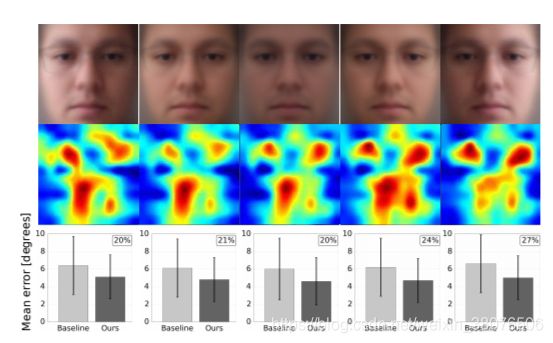
图 8:根据 MPIIGaze 数据集的光照条件,基于面部补丁聚类的区域重要性图和相应的平均面部补丁:从面部右侧的定向光(左)、正面光(中心)到定向 脸部左侧(右侧)的光。 条形图显示了两眼模型(基线)和建议的空间权重 CNN(我们的)的估计误差,以及右上角的性能增益百分比。 误差棒表示标准偏差。
注视方向:另一个可能影响不同面部区域重要性的因素是注视方向。 因此,我们以与以前相同的方式根据注视方向对图像进行聚类。 图 9 的顶部两行显示了取决于水平凝视方向的相应区域重要性图,而底部两行显示了取决于垂直凝视方向的地图。 如图所示,根据要推断的凝视方向,面部的不同部分变得重要。 如果注视方向是正前方,则眼睛区域最重要,而如果注视方向变得更极端,则模型对其他区域的重要性更高。
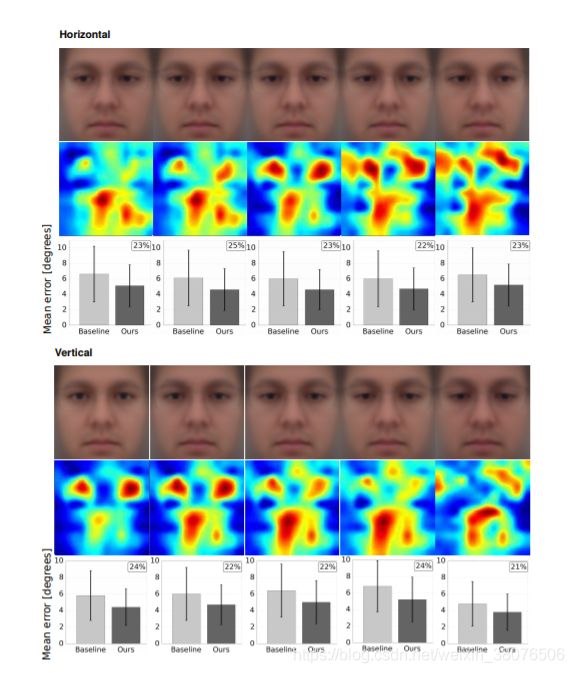
图 9:根据 MPIIGaze 数据集的真实水平(顶部)和垂直(底部)注视方向,基于图像聚类的区域重要性图和相应的平均面部补丁。 条形图以与图 8 中相同的方式显示估计误差。
头部姿势:虽然 MPIIGaze 中的头部姿势范围因录制设置而受到限制,但 EYEDIAP 数据集包含了广泛的头部姿势范围。
因此,我们最终以与以前相同的方式根据头部姿势在 EYEDIAP 中聚类图像。 图 10 的顶部两行显示了取决于水平头部姿势的相应区域重要性图,而底部两行显示了取决于垂直头部姿势的地图。 在这些情况下,可以清楚地看到,全脸输入特别有利于提高极端头部姿势的估计性能。 与 MPIIGaze 相比,非眼睛面部区域通常也具有更高的重要性,这表明对低分辨率图像使用全脸输入的好处。
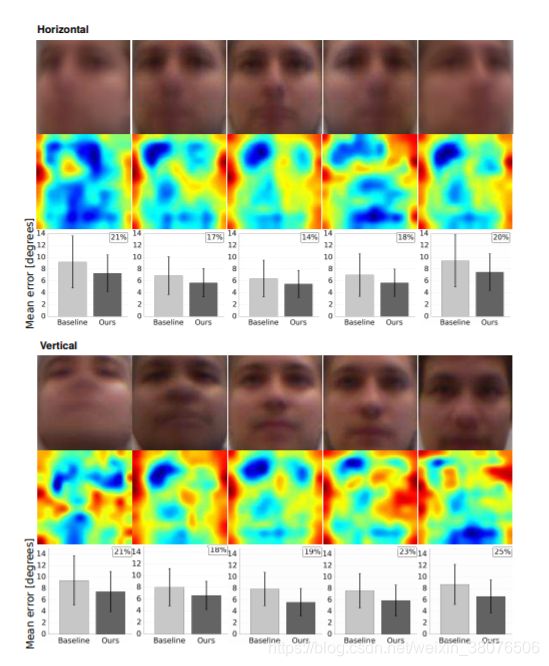
图 10:根据 EYEDIAP 数据集的真实水平(顶部)和垂直(底部)头部姿势,基于图像聚类的区域重要性图。 条形图以与图 8 中相同的方式显示估计误差。
我们的方法对由极端头部姿势和注视方向以及照明引起的面部外观变化更加鲁棒。 我们的方法分别在具有挑战性的野外 MPIIGaze 和 EYEDIAP 数据集上实现了 4.8 ◦ 和 6.0 ◦ 的精度,用于独立于人的 3D 凝视估计——比现有技术显着提高了 14.3% 和 27.7%。 我们认为基于全脸外观的凝视估计与相关的计算机视觉任务密切相关,例如面部和面部特征检测、面部表情分析或头部姿势估计。 因此,这项工作指向了未来基于学习的方法,可以共同解决多个这些任务。
7. 致谢
这项工作部分由德国萨尔大学的多模态计算和交互卓越集群 (MMCI) 和日本的 JST CREST 研究基金 (JPMJCR14E1) 资助。