kafka主要组件说明
目录
1、kafka当中的producer说明
2、kafka当中的topic说明
3、kafka当中的partition说明
4、kafka当中partition的副本数说明
5、kafka当中的segment说明
索引文件与数据文件的关系
6、kafka当中的partition的offset
7、kafka分区与消费组的关系
8、kafka当中的consumer
1、kafka当中的producer说明
producer主要是用于生产消息,是kafka当中的消息生产者,生产的消息通过topic进行归类,保存到kafka的broker里面去
2、kafka当中的topic说明
1、kafka将消息以topic为单位进行归类
2、topic特指kafka处理的消息源(feeds of messages)的不同分类。
3、topic是一种分类或者发布的一些列记录的名义上的名字。kafka主题始终是支持多用户订阅的;也就是说,一个主题可以有零个,一个或者多个消费者订阅写入的数据。
4、在kafka集群中,可以有无数的主题。
5生产者和消费者消费数据一般以主题为单位。更细粒度可以到分区级别。
3、kafka当中的partition说明
kafka当中,topic是消息的归类,一个topic可以有多个分区,每个分区保存部分topic的数据,所有的partition当中的数据全部合并起来,就是一个topic当中的所有的数据,
一个broker服务下,是否可以创建多个分区?
可以的,broker数与分区数没有关系; 在kafka中,每一个分区会有一个编号:编号从0开始
每一个分区的数据是有序的
说明-数据是有序 如何保证一个主题下的数据是有序的?(生产是什么样的顺序,那么消费的时候也是什么样的顺序)

topic的Partition数量在创建topic时配置。
Partition数量决定了每个Consumer group中并发消费者的最大数量。
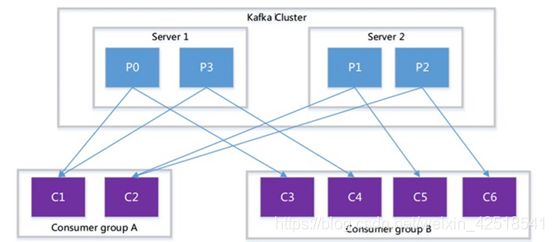
例如:Consumer group A 有两个消费者来读取4个partition中数据;Consumer group B有四个消费者来读取4个 partition中的数据
4、kafka当中partition的副本数说明
kafka分区副本数(kafka Partition Replicas)

副本数(replication-factor):控制消息保存在几个broker(服务器)上,一般情况下小于等于broker的个数
例如:一个broker服务下,是否可以创建多个副本因子?
不可以;创建主题时,副本因子应该小于等于可用的broker数。 副本因子过程图

副本因子操作以分区为单位的。每个分区都有各自的主副本和从副本;
主副本叫做leader,从副本叫做 follower(在有多个副本的情况下,kafka会为同一个分区下的所有分区,设定角色关系:一个leader和N个 follower),处于同步状态的副本叫做in-sync-replicas(ISR);
follower通过拉的方式从leader同步数据。
消费者和生产者都是从leader读写数据,不与follower交互。
副本因子的作用:让kafka读取数据和写入数据时的可靠性。
副本因子是包含本身,同一个副本因子不能放在同一个Broker中。
如果某一个分区有三个副本因子,就算其中一个挂掉,那么只会剩下的两个中,选择一个leader,但不会在其他的broker中,另启动一个副本(因为在另一台启动的话,存在数据传递,只要在机器之间有数据传递,就会长时间占用网络IO,kafka是一个高吞吐量的消息系统,这个情况不允许发生)所以不会在零个broker中启动。
如果所有的副本都挂了,生产者如果生产数据到指定分区的话,将写入不成功。
lsr表示:当前可用的副本
5、kafka当中的segment说明
一个partition当中有多个segment文件组成,每个segment文件,包含两部分,一个是.log文件,另外一个是.index文件,其中.log文件包含了我们发送的数据存储,.index文件,记录的是我们.log文件的数据索引值,以便于我们加快数据的查询速度
索引文件与数据文件的关系
既然它们是一一对应成对出现,必然有关系。索引文件中元数据指向对应数据文件中message的物理偏移地址
比如:索引文件中3,497代表:数据文件中的第三个message,它的偏移地址为497。再来看数据文件中,Message 368772表示:在全局partiton中是第368772个message。
注:segment index file采取稀疏索引存储方式,它减少索引文件大小,通过mmap可以直接内存操作,稀疏索引为数据文件的每个对应message设置一个元数据指针,它比稠密索引节省了更多的存储空间,但查找起来需要消耗更多的时间。

6、kafka当中的partition的offset
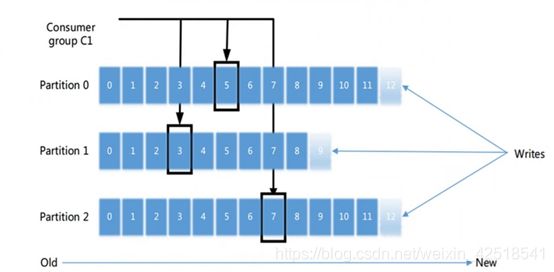
任何发布到此partition的消息都会被直接追加到log文件的尾部,每条消息在文件中的位置称为offset(偏移量),
offset是一个long类型数字,它唯一标识了一条消息,消费者通过(offset,partition,topic)跟踪记录。
7、kafka分区与消费组的关系
消费组: 由一个或者多个消费者组成,同一个组中的消费者对于同一条消息只消费一次。
某一个主题下的分区数,对于消费组来说,消费者应该小于等于该主题下的分区数。如下所示:
如:某一个主题有4个分区,那么消费组中的消费者应该小于4,而且最好与分区数成整数倍1 2 4同一个分区下的数据,在同一时刻,不能同一个消费组的不同消费者消费
总结:分区数越多,同一时间可以有越多的消费者来进行消费,消费数据的速度就会越快,提高消费的性能
8、kafka当中的consumer
consumer是kafka当中的消费者,主要用于消费kafka当中的数据,任何一个消费者都必定需要属于某一个消费组当中。
任意时刻,一个分区当中的数据,只能被kafka当中同一个消费组下面的一个线程消费