cgroup架构及控制文件介绍
目录
- 一、基本概念
- 二、整体架构
- 三、控制文件介绍
-
- 1.各子系统的定义
- 2.常用控制文件含义简介
-
- cpu
- cpuacct
- cpuset
- memory
- pids
- files
- 四、cgroupv1和v2的差别
-
- 1.cgroup v1缺点
- 2.mount区别
- 3. 其它子系统差异
- 4. 如何启用cgroup_v2
- 5. 代码中判断cgroup版本
一、基本概念
- cgroup: Control Group,控制组,用于控制(限制)进程对系统各种资源的使用,比如 CPU 、 内存 、 网络 和 磁盘I/O 等资源的限制。
- 任务:指系统的一个进程
- 控制组:受相同资源限制的一组进程(任务)
- 层级:控制组以目录形式存在,目录之间可以组织成层级的形式,代表控制组之间的层级关系,子节点的资源也被统计到父节点中
- 子系统:subsystem,代表一个资源控制器,子系统副驾到一个层级上才能起作用,层级上的所有控制组受到与之绑定的子系统限制
服务中场景中由systemd完成启动时挂载,通常不会将不同子系统挂载到同一层级,典型组织方式如下:
# ll /sys/fs/cgroup/
dr-xr-xr-x. 10 root root 0 11月 3 13:17 blkio
lrwxrwxrwx. 1 root root 11 11月 3 13:17 cpu -> cpu,cpuacct
lrwxrwxrwx. 1 root root 11 11月 3 13:17 cpuacct -> cpu,cpuacct
dr-xr-xr-x. 10 root root 0 11月 3 13:17 cpu,cpuacct
dr-xr-xr-x. 2 root root 0 11月 3 13:17 cpuset
dr-xr-xr-x. 10 root root 0 11月 3 13:17 devices
dr-xr-xr-x. 2 root root 0 11月 3 13:17 files
...
dr-xr-xr-x. 10 root root 0 11月 3 13:17 pids
dr-xr-xr-x. 2 root root 0 11月 3 13:17 rdma
在各个子系统中,cgroup.procs中存放了受该层级控制的任务组:
[root@localhost ~]# head /sys/fs/cgroup/cpu/cgroup.procs
1
2
3
...
二、整体架构
cgroup v1版本想要实现灵活且精确的资源控制,任务组可以受单个子系统控制,也可以受多个控制组控制,为了表达多对多且精细化的关系,引入了众多的数据结构。
使用struct css_set来表示受相同子系统控制的一组进程(线程),二者关系如下:
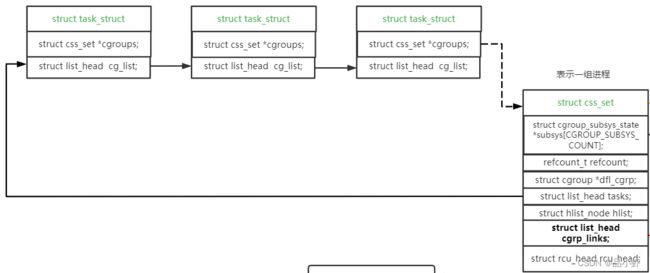
使用struct cgroup_subsys_state表示一个子系统,每个子系统会形成一个目录,用struct cgroup表示

使用了struct cgrp_cset_link结构来维护cgroup与任务组间多对多的关系,各数据结构之间关系如下图

- 找到进程所属的某个子系统,如pid cgroup:task_struct->cgroups->subsys[pids_cgrp_id]->cgroup
- 通过struct cgroup找到与之绑定的进程组:cgroup->cset_link->cset->tasks
- 找到进程组绑定的所有cgroup:css_set->cset_link->cgrp_link
三、控制文件介绍
1.各子系统的定义
cgroup对资源的限制主要是通过多个子系统下的控制文件来实现与用户交互的,如果用户需要限制某个资源,首先需要将进程添加到对应的子系统层级中,再对相应的控制文件写入限制值即可。如限制pid为1417的进程内存总限制为10k,只需要如下步骤
[root@localhost ~]# mkdir /sys/fs/cgroup/memory/test
[root@localhost ~]# echo 1417 >> /sys/fs/cgroup/memory/test/cgroup.procs
[root@localhost ~]# echo 10240 >> /sys/fs/cgroup/memory/test/memory.limit_in_bytes
memory.limit_in_bytes即为一个控制文件,而以cgroup开头的控制文件属于通用文件,所有子系统均包含;
在kernel/include/linux/cgroup.h中可看到所有子系统的定义
#define SUBSYS(_x) extern struct cgroup_subsys _x ## _cgrp_subsys;
#include 在cgroup_subsys.h中可以灵活的开启关闭各子系统
...
#if IS_ENABLED(CONFIG_CGROUP_CPUACCT)
SUBSYS(cpuacct)
#endif
#if IS_ENABLED(CONFIG_BLK_CGROUP)
SUBSYS(io)
#endif
#if IS_ENABLED(CONFIG_MEMCG)
SUBSYS(memory)
#endif
以memcg为例,SUBSYS(memory)相当于extern struct cgroup_subsys memory_cgrp_subsys,在mm/memory_control.c中定义
struct cgroup_subsys memory_cgrp_subsys = {
.css_alloc = mem_cgroup_css_alloc,
.css_online = mem_cgroup_css_online,
...
.dfl_cftypes = memory_files, // cgroup_v2控制文件
.legacy_cftypes = mem_cgroup_legacy_files, // cgroup_v1控制文件
.early_init = 0,
};
其cgroup v1的控制文件如下
static struct cftype memory_files[] = {
{
.name = "current",
.flags = CFTYPE_NOT_ON_ROOT,
.read_u64 = memory_current_read,
},
{
.name = "min",
.flags = CFTYPE_NOT_ON_ROOT,
.seq_show = memory_min_show,
.write = memory_min_write,
},
{
.name = "low",
.flags = CFTYPE_NOT_ON_ROOT,
.seq_show = memory_low_show,
.write = memory_low_write,
},
{
.name = "high",
.flags = CFTYPE_NOT_ON_ROOT,
.seq_show = memory_high_show,
.write = memory_high_write,
},
...
2.常用控制文件含义简介
前文介绍了各个子系统的定义为xx_cgrp_subsys,下面介绍每个子系统中常用的控制文件及功能(cgroup_v1 linux-5.10.61),首先是每个子系统均包含的基础控制文件。
kernel/cgroup/cgroup-v1.c, cgroup1_base_files,均以cgroup.开头
| 文件名 | 含义 |
|---|---|
| clone_children | 只对cpuset有影响,当内容为1时,新创建的cgroup将会继承父cgroup的配置 |
| procs | 当前cgroup中的所有进程ID |
| tasks | 当前cgroup中的所有线程ID |
| release_agent | 里面包含了cgroup退出时将会执行的命令,系统调用该命令时会将相应cgroup的相对路径当作参数传进去。 (这个文件只会存在于root cgroup下面,其他cgroup里面不会有这个文件 ) |
| notify_on_release | 该文件的内容为1时,当cgroup退出时(不再包含任何进程和子cgroup),将调用release_agent里面配置的命令。新cgroup被创建时将默认继承父cgroup的这项配置 |
cpu
| 文件名 | 含义 |
|---|---|
| shares | 限制cpu的使用,控制各个组之间的配额,默认1024,shares是一个绝对值,需要和其它cgroup的值进行比较才能得到自己的相对限额,而在一个部署很多容器的机器上,cgroup的数量是变化的,所以这个限额也是变化的,自己设置了一个高的值,但别人可能设置了一个更高的值,所以这个功能没法精确的控制CPU使用率 |
| cfs_period_us | 用于cfs调度组调度的带宽控制,控制调度时间分配周期,默认100ms |
| cfs_quota_us | 该group中所有cpu的使用率,默认-1表示不限制。如quato=250ms,period=250ms表示限制只能使用1个CPU |
| stat | 用于展示带宽控制的状态信息,nr_periods(表示过去了多少个cpu.cfs_period_us里面配置的时间周期),nr_throttled(在period_us这些周期中,有多少次是受到了限制,即用完了配额),throttled_time(进程组被限制使用CPU持续了多少纳秒) |
cpuacct
| 文件名 | 含义 |
|---|---|
| usage | 该cgroup中task所占用的CPU总时间(ns) |
| usage_user | 占用的时间中用户态的部分 |
| usage_sys | 占用的时间中内核态的部分 |
| usage_percpu | 占用每个核的CPU时间 |
| usage_percpu_user | 占用每个核的CPU时间属于用户态的部分 |
| usage_percpu_sys | 占用每个核的CPU时间属于内核态的部分 |
| usage_all | 在每个核上占用的内核态和用户态总时间 |
| stat | 该cgrp中任务所消耗的用户态(user)和内核态(sys)时间 |
cpuset
| 文件名 | 含义 |
|---|---|
| cpus | 该组任务可以使用的cpu核 |
| mems | 该组任务可以使用的NUMA节点 |
| effective_cpus | 生效的cpu核 |
| effective_mems | 生效的NUMA节点 |
| cpu_exclusive | 设置为1后,这个cgroup使用的cpu 节点将不会跟其他cgroup共享使用 |
| mem_exclusive | 设置为1后,这个cgroup使用的mem节点将不会跟其他cgroup共享使用 |
| mem_hardwall | 布尔值,默认0,内核为该group分配的进程是否应该仅仅在指定的内存节点上 |
| sched_load_balance | f1时表示可以使用的cpu核上进行负载均衡 |
| sched_relax_domain_level | kernel应尝试平衡负载的CPU宽度范围 |
| memory_pressure | 统计了该group内存压力的平均值,该值表示cpuset中任何进程导致的直接回收代码的条目的最近(半衰期为10秒)速率,单位是每秒尝试回收的次数*100 |
| memory_spread_page | 是否均衡使用该group的内存节点 |
| memory_spread_slab | 若设为1,那么内核将传播一些与文件系统相关的slab缓存,例如作为inode和目录条目的那些缓存,将均匀地覆盖在进程cpuset允许使用节点上,而不是放在进程正在运行的节点上。 |
| memory_pressure_enabled | 只在root cpuset下出现。设置为1时,会显示这个cpuset的内存pressure |
memory
| 文件名 | 含义 |
|---|---|
| usage_in_bytes | 当前已使用的内存字节数 |
| max_usage_in_bytes | 历史最大内存使用量 |
| limit_in_bytes | 强制内存上限,usage不能超过这个上限。如果试图超过,则会触发同步的内存回收过程,或者OOM |
| soft_limit_in_bytes | 非强制内存上限,usage超过这个上限后,组内进程使用的内存可能会被加快步伐进行回收 |
| failcnt | 内存使用量达到限制值的次数 |
| stat | 当前cgroup内存使用装填统计 |
| force_empty | 触发系统立即尽可能的回收当前cgroup中可以回收的内存 |
| use_hierarchy | 设置/显示是否将子cgroup的内存使用情况统计到当前cgroup里面 |
| swappiness | 设置和显示当前的swappiness |
| pressure_level | 设置内存压力的通知事件,配合cgroup.event_control一起使用 |
| oom_control | 一共三个状态值,oom_kill_disable(oom开关是否打开),under_oom(该cgroug正在产生oomtry_charge->mem_cgroup_oom->mem_cgroup_mark_under_oom), oom_kill(该cgroup中的进程是否由于oom被kill:oom_kill_process->__oom_kill_process->memcg_memory_event_mm(mm, MEMCG_OOM_KILL) |
| numa_stat | 打印numa相关的内存状态 |
| move_chage_at_immigrate | 设置当进程移动到其他cgroup中时,它所占用的内存是否也随着移动过去 |
| min/low/high | 与内存回收相关,递归回收子cgroup的内存,如果memcg的usage小于memory.min,则不会回收此memcg,当usage 小于memory.low时会选择回收,大于时会是理想的回收对象。其中memory.high默认与limit_in_bytes相同,当此cgroup的usage大于memory.high时,内存分配阻塞;如果swap空间可用,优先回收此cgroup的内存到swap中,直到当前内存为。 |
| memsw | 内存软上限相关,一共有三个控制文件,memsw.limit_in_bytes(memsw限制内存,limit_in_bytes限制的物理内存+swap部分的内存等于该值),memsw.max_usage_in_bytes(limit_in_bytes+swap内存峰值),memsw.usage_in_bytes(当前正在使用的内存) |
pids
| 文件名 | 含义 |
|---|---|
| current | 当前cgroup及其子孙cgroup中现有进程总数 |
| max | 当前cgroup及其所有子孙cgroup中所允许创建的总的最大进程数量 |
| events | 当前cgroup中进程数超出max而被限制的次数 |
files
| 文件名 | 含义 |
|---|---|
| limit | 当前cgroup及其子孙cgroup限制打开的文件总数 |
| usage | 当前cgroup及其子孙cgroup已打开的文件总数 |
freezer用于将cgroup内的进程进行冻结,perf_event用于对指定cgroup进行perf统计,其它的待补充。
四、cgroupv1和v2的差别
1.cgroup v1缺点
cgroup_v1设计中存在寻多的不足,如
- 多层级设计导致进程的管理混乱:为了提供高灵活性,导致了代码复杂及理解困难,同事也导致多个controller之间难以协同工作;
- 时间通知机制不完善:CGroups v1每次进行事件通知都是通过fork和exec一个用户层帮助程序(userland helper binary)完成的,开销相对较大。这种设计也导致在内核内部的事件传递过滤机制更加复杂;
- 基于线程的控制粒度:CGroups v1允许一个进程的各个线程属于不同的控制组,这种设计表明上增加了灵活性,但这和多层级的设计类似,除了增加操作、接口和代码实现的复杂度之外,实际上并没有什么用处。此外,如果一个进程的不同线程分属于同一层级的不同控制组,那么会引入资源竞争的问题,而且多数子系统对于这种行为是没有定义的,因此如果用户真的那么用了,那结果就不可知了。
为了对cgroupv1进行改进,在linux-4.5版本内核合入了全新开发的cgroupv2,其特点主要是使用了单层级,并且基于进程的粒度进行控制,使得整个代码架构及使用的复杂度大大降低;
2.mount区别
挂载的区别,cgroup_v1挂载root cgroup及层级,查看cgroup_v1挂载点,可以看出cgroup_v1挂载为tmpfs类型
[root@localhost ~]# findmnt
TARGET SOURCE FSTYPE OPTIONS
├─/sys sysfs sysfs rw,nosuid,nodev,noexec,relatime,seclabel
│ ├─/sys/fs/cgroup tmpfs tmpfs ro,nosuid,nodev,noexec,seclabel,size=4096k,nr_inodes=1024,mode=755
│ │ ├─/sys/fs/cgroup/systemd cgroup cgroup rw,nosuid,nodev,noexec,relatime,seclabel,xattr,release_agent=/usr/lib/systemd/systemd-cgroups-agent,nam
│ │ ├─/sys/fs/cgroup/memory cgroup cgroup rw,nosuid,nodev,noexec,relatime,seclabel,memory
│ │ ├─/sys/fs/cgroup/files cgroup cgroup rw,nosuid,nodev,noexec,relatime,seclabel,files
│ │ ├─/sys/fs/cgroup/blkio cgroup cgroup rw,nosuid,nodev,noexec,relatime,seclabel,blkio
│ │ ├─/sys/fs/cgroup/freezer cgroup cgroup rw,nosuid,nodev,noexec,relatime,seclabel,freezer
│ │ ├─/sys/fs/cgroup/devices cgroup cgroup rw,nosuid,nodev,noexec,relatime,seclabel,devices
│ │ ├─/sys/fs/cgroup/cpu,cpuacct cgroup cgroup rw,nosuid,nodev,noexec,relatime,seclabel,cpu,cpuacct
...
cgroup挂载后通过其controllers指定支持控制类型,且挂载的文件系统类型为cgroup2,echo “+cpuset +cpu +io +hugetlb +rdma +files” > cgroup.subtree_control添加、删除子group控制类型;
[root@localhost ~]# findmnt
TARGET SOURCE FSTYPE OPTIONS
├─/sys sysfs sysfs rw,nosuid,nodev,noexec,relatime,seclabel
│ ├─/sys/fs/cgroup cgroup2 cgroup2 rw,nosuid,nodev,noexec,relatime,seclabel,nsdelegate,memory_recursiveprot
[root@localhost ~]# cat /sys/fs/cgroup/cgroup.controllers
cpuset cpu io memory hugetlb pids rdma files
3. 其它子系统差异
- devices子系统,在cgroup中不再使用devices.deny等来控制cgroup对devices的访问控制,而更改为使用ebpf attach到cgroup的方式实现;
- perf_event:由于cgroup v2使用单一层级,因此对cgroup进行PMU统计时,可以直接使用其层级路径而不需要单独使用perf_event;
- files: 在linux-6.0.1版本之后废弃
4. 如何启用cgroup_v2
cgroup v1和v2版本默认同时编译进入内核,在服务器场景下,通过systemd实现挂载,在cmdline中添加systemd.unified_cgroup_hierarchy=1,启用cgroup_v2
5. 代码中判断cgroup版本
struct statfs buf;
#define CGROUP2_SUPER_MAGIC 0x63677270
statfs("/sys/fs/cgroup", &buf);
if (buf.f_type == CGROUP2_SUPER_MAGIC) {
// cgroup v2
}