【博学谷学习记录】超强总结,用心分享 | 架构师 MySql扩容学习总结
文章目录
-
- 1. 停机方案
- 2.停写方案
- 3.日志方案
- 4.双写方案(中小型数据)
- 5.平滑2N方案(大数据量)
1. 停机方案

- 发布公告
为了进行数据的重新拆分,在停止服务之前,我们需要提前通知用户,比如:我们的服务会在yyyy-MM-dd进行升级,给您带来的不便敬请谅解。
- 停止服务
关闭Service
- 离线数据迁移(拆分,重新分配数据)
将旧库中的数据按照Service层的算法,将数据拆分,重新分配数据
- 数据校验
开发定制一个程序对旧库和新库中的数据进行校验,比对
- 更改配置
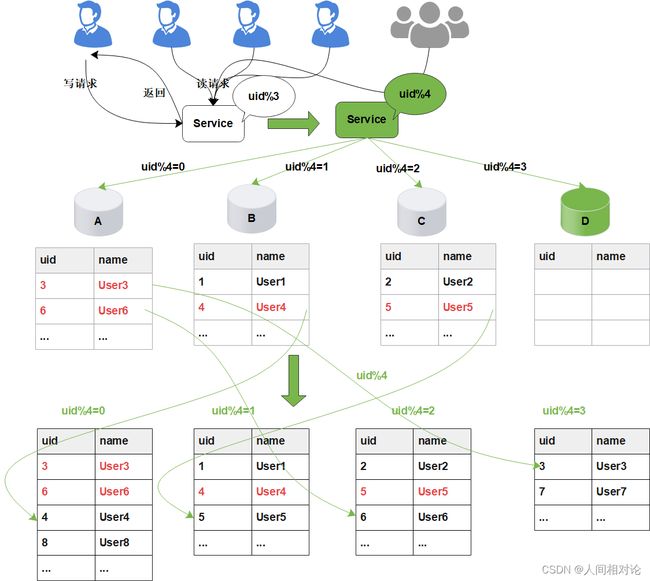
修改Service层的配置算法,也就是将原来的uid%3变为uid%4
- 恢复服务
重启Service服务
- 回滚预案
针对上述的每个步骤都要有数据回滚预案,一旦某个环节(如:数据迁移,恢复服务等)执行失败,立刻进行回滚,重新再来
停止服务之后, 能够保证迁移工作的正常进行, 但是服务停止,伤害用户体验, 并造成了时间压力, 必须在指定的时间内完成迁移。
2.停写方案
- 支持读写分离
数据库支持读写分离,在扩容之前,每个数据库都提供了读写功能,数据重新分配的过程中,将每个数据库设置为只读状态,关闭写的功能
- 升级公告
为了进行数据的重新拆分,在停写之前,我们需要提前通知用户,比如:我们的服务会在yyyy-MM-dd进行升级,给您带来的不便敬请谅解。
- 中断写操作,隔离写数据源(或拦截返回统一提示)
在Service层对所有的写请求进行拦截,统一返回提示信息,如:服务正在升级中,只对外提供读服务
- 数据同步处理
将旧库中的数据按照Service层的算法,将数据重新分配,迁移(复制数据)
- 数据校验
开发定制一个程序对旧库中的数据进行备份,使用备份的数据和重新分配后的数据进行校验,比对
- 更改配置
通过配置中心,修改Service层的配置算法,也就是将原来的uid%3变为uid%4,这个过程不需要重启服务
- 恢复写操作
设置数据库恢复读写功能,去除Service层的拦截提示
- 数据清理
使用delete语句对冗余数据进行删除
- 回滚预案
针对上述的每个步骤都要有数据回滚预案,一旦某个环节(如:数据迁移等)执行失败,立刻进行回滚,重新再来
缺点:在数据的复制过程需要消耗大量的时间,停写时间太长,数据需要先复制,再清理冗余数据
3.日志方案
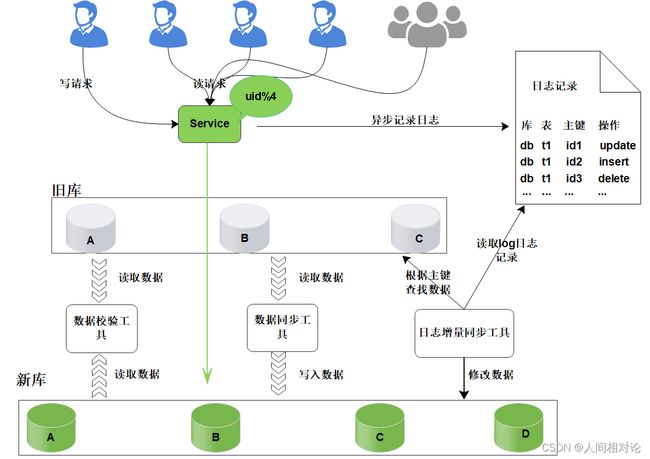
核心是通过日志进行数据库的同步迁移, 主要操作步骤如下:
- 数据迁移之前, 业务应用访问旧的数据库节点。

- 日志记录
在升级之前, 记录“对旧数据库上的数据修改”的日志(这里修改包括增、删、改),这个日志不需要记录详细的数据信息,主要记录:
(1)修改的库;
(2)修改的表;
(3)修改的唯一主键;
(4)修改操作类型。
日志记录不用关注新增了哪些信息,修改的数据格式,只需要记录以上数据信息,这样日志格式是固定的, 这样能保证方案的通用性。
服务升级日志记录功能风险较小:
写和修改接口是少数, 改动点少;
升级只是增加了一些日志,采用异步方式实现, 对业务功能没有太多影响
- 数据迁移:
研发定制数据迁移工具, 作用是把旧库中的数据迁移至新库中。
整个过程仍然采用旧库进行对外服务。
数据同步工具实现复杂度不高。
只对旧库进行读取操作, 如果同步出现问题, 都可以对新库进行回滚操作。
可以限速或分批迁移执行, 不会有时间压力。
数据迁移完成之后, 并不能切换至新库提供服务。
因为旧库依然对线上提供服务, 库中的数据随时会发生变化, 但这些变化的数据并没有同步到新库中, 旧库和新库数据不一致, 所以不能直接进行切换, 需要将数据同步完整。
- 日志增量迁移

研发一个日志迁移工具,把上面迁移数据过程中的差异数据追平,处理步骤:
读取log日志,获取具体是哪个库、表和主键发生了变化修改;
把旧库中的主键记录读取出来
根据主键ID,把新库中的记录替换掉
这样可以最大程度的保障数据的一致性。风险分析:
整个过程, 仍然是旧库对线上提供服务;
日志迁移工具实现的复杂度较低;
任何时间发现问题, 可以重新再来,有充分的容错空间;
可以限速重放处理日志, 处理过程不会因为对线上影响造成时间压力。
但是, 日志增量同步完成之后, 还不能切换到新的数据库。
因为日志增量同步过程中,旧库中可能有数据发生变化, 导致数据不一致,所以需要进一步读取日志, 追平数据记录; 日志增量同步过程随时可能会产生新的数据, 新库与旧库的数据追平也会是一个无限逼近的过程。
- 数据校验
准备好数据校验工具,将旧库和新库中的数据进行比对,直到数据完全一致。
- 切换新库
数据比对完成之后, 将流量转移切换至新库, 至此新库提供服务, 完成迁移。
但是在极限情况下, 即便通过上面的数据校验处理, 也有可能出现99.99%数据一致, 不能保障完全一致,这个时候可以在旧库做一个readonly只读功能, 或者将流量屏蔽降级,等待日志增量同步工具完全追平后, 再进行新库的切换。
至此,完成日志方案的迁移扩容处理, 整个过程能够持续对线上提供服务, 只会短暂的影响服务的可用性。
这种方案的弊端,是操作繁琐,需要适配多个同步处理工具,成本较高, 需要制定个性化业务的同步处理, 不具备普遍性,耗费的时间周期也较长。
4.双写方案(中小型数据)
双写方案可通过canal或mq做实现。
-
增加新库,按照现有节点, 增加对应的数量。
-
数据迁移:避免增量影响, 先断开主从,再导入(耗时较长), 同步完成并做校验
-
增量同步:开启Canal同步服务, 监听从节点数据库, 再开启主从同步,从节点收到数据后会通过Canal服务, 传递至新的DB节点。
-
切换新库:通过Nginx,切换访问流量至新的服务。
-
修复切换异常数据:在切换过程中, 如果出现,Canal未同步,但已切换至新库的请求(比如下单,修改了资金, 但还未同步 ), 可以通过定制程序, 读取检测异常日志,做自动修复或人工处理。
-
针对此种情况, 最好是在凌晨用户量小的时候, 或专门停止外网访问,进行切换,减少异常数据的产生。
-
数据校验:为保障数据的完全一致, 有必要对数据的数量完整性做校验。
5.平滑2N方案(大数据量)
- 线上数据库,为了保障其高可用,一般每台主库会配置一台从库,主库负责读写,从库负责读取。下图所示,A,B是主库,A0和B0是从库。

- 当需要扩容的时候,我们把A0和B0升级为新的主库节点,如此由2个分库变为4个分库。同时在上层的分片配置,做好映射,规则如下:
把uid%4=0和uid%4=2的数据分别分配到A和A0主库中
把uid%4=1和uid%4=3的数据分配到B和B0主库中
- 因为A和A0库的数据相同,B和B0数据相同,此时无需做数据迁移。只需调整变更一下分片配置即可,通过配置中心更新,不需要重启。
由于之前uid%2的数据是分配在2个库里面,扩容之后需要分布到4个库中,但由于旧数据仍存在(uid%4=0的节点,还有一半uid%4=2的数据),所以需要对冗余数据做一次清理。
这个清理,并不会影响线上数据的一致性,可以随时随地进行。
- 处理完成之后,为保证数据的高可用,以及将来下一步的扩容需求。
可以为现有的主库再次分配一个从库。
