论文笔记——C2FNet:Context-aware Cross-level Fusion Network for Camouflaged Object Detection
Context-aware Cross-level Fusion Network for Camouflaged Object Detection
论文地址:https://arxiv.org/pdf/2105.12555.pdf?ref=https://githubhelp.com
代码地址:https://github.com/thograce/C2FNet
发表刊物:IJCAI 2021
由于对象与其周围环境之间的低边界对比度,伪装对象检测 (COD) 是一项具有挑战性的任务。 此外,伪装物体的外观变化很大,例如物体大小和形状,增加了准确 COD 的难度。 在本文中,我们提出了一种新颖的上下文感知跨级融合网络(C2F-Net)来解决具有挑战性的 COD 任务。 具体来说,我们提出了一种注意力诱导的跨级融合模块(ACFM),将多级特征与信息注意系数相结合。 然后将融合的特征馈送到提出的双分支全局上下文模块(DGCM),该模块产生多尺度特征表示,以利用丰富的全局上下文信息。 在 C2F-Net 中,这两个模块使用级联方式对高级特征进行处理。 在三个广泛使用的基准数据集上进行的大量实验表明,我们的 C2F-Net 是一种有效的 COD 模型,并且显着优于最先进的模型。 我们的代码在以下位置公开可用:https://github.com/thograce/C2FNet。
[Le et al., 2019] 提出了一个 anabranch 网络,它执行分类以预测图像是否包含伪装对象,然后将这些信息整合到伪装对象分割任务中。 基于捕食者通过先搜索后识别发现猎物的观察,[Fan et al., 2021] 设计了一个搜索模块和一个识别模块,分别用于定位粗糙区域和准确分割伪装物体。
现存问题:现有方法在从相对简单的场景中检测单个伪装对象方面显示出有希望的性能。 然而,对于许多具有挑战性的情况,例如多个对象、遮挡等,它们的性能会显着下降。
解决这些挑战的一个关键解决方案是一个显着的大感受野,它为准确的 COD 提供了丰富的上下文信息。 此外,跨层特征融合对COD的成功也起着至关重要的作用。 然而,现有的作品通常忽略了这两个关键因素的重要性。 因此,非常需要一个统一的 COD 框架,它同时考虑丰富的上下文信息和有效的跨级特征融合。
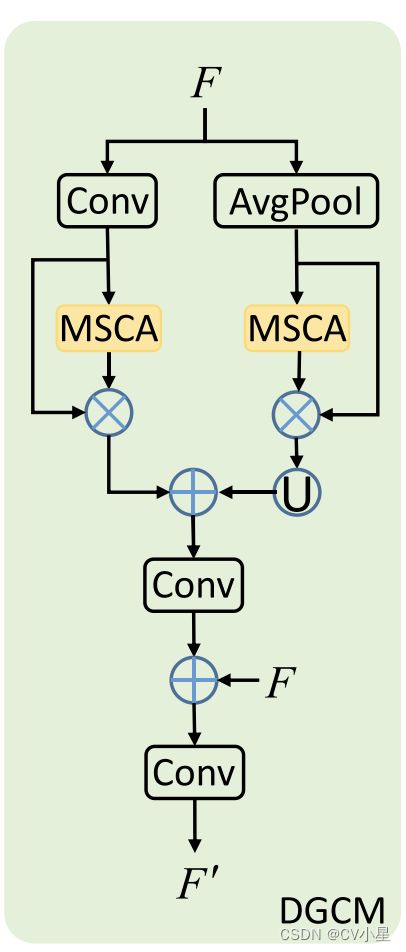
为此,我们提出了一种新颖的 COD 模型,称为 Context-aware Cross-level Fusion Network (C2F-Net)。 我们首先使用注意力诱导的跨层融合模块 (ACFM) 融合从主干中提取的跨层特征,该模块将特征与多尺度通道注意力 (MSCA) 组件的指导相结合。 ACFM 从多级特征中计算注意力系数,使用得到的注意力系数来细化特征,然后将得到的特征整合到融合的特征中。随后,我们提出了一个双分支全局上下文模块(DGCM)来利用融合特征中丰富的上下文信息。 DGCM 将输入特征转换为具有两个并行分支的多尺度特征,使用 MSCA 组件计算注意力系数,并通过考虑注意力系数来整合特征。 ACFM 和 DGCM 在两个阶段以级联方式组织,从高层到低层。 最终的 DGCM 从图像中预测伪装对象的分割图。 综上所述,本文的主要贡献如下:
-
我们提出了一种新颖的 COD 模型 C2F-Net,它将跨级别特征与丰富的全局上下文信息相结合。
-
我们提出了一个上下文感知模块 DGCM,它利用来自融合特征的全局上下文信息。 我们的 DGCM 能够捕获有价值的上下文信息,这是提高 COD 准确性的关键因素。
-
我们将跨级别特征与有效的融合模块 ACFM 集成,该模块将特征与 MSCA 提供的有价值的注意力线索集成在一起。
-
对三个基准数据集的广泛实验表明,我们的 C2F-Net 在四个评估指标方面优于 14 个最先进的模型。
此部分作者主要介绍伪装物体和上下文深度学习的相关文章,简单记录了我认为值得注意的方法,具体信息请参考原文.
GCFANet [Chen et al., 2020] 利用全局上下文流模块将包含全局语义的特征转移到不同阶段的特征映射,以提高突出对象检测的完整性。LCANet [Tan et al., 2020] 将局部区域上下文和全局场景上下文自适应地集成在从粗到细的结构中,以增强局部上下文特征。

采用Res2Net-50作为主干提取网络,记作 f i { i = 1 , 2 , . . . , 5 } f_i \{i=1,2,...,5\} fi{i=1,2,...,5}.然后,采用感受野块 (RFB) 来扩展感受野,以便在特定层中捕获更丰富的特征。在每个分支中,第一个卷积层的尺寸为 1×1,以将通道尺寸减小到 64。这是紧随其后的是两层,即。(2 k−1)×(2 k−1)卷积层和一个3×3卷积层与一个特定的膨胀率(2 k−1)当k > 2。前四个分支连接起来,然后使用 1 × 1 卷积操作将它们的通道大小减小到 64。然后,添加第五个分支并将整个模块馈送到 ReLU 激活函数以获得最终特征。之后,我们提出了一个注意力诱导的跨级融合模块(ACFM)来集成多尺度特征,以及一个双分支全局上下文模块(DGCM)来挖掘融合特征中的多尺度上下文信息。
Attention-induced Cross-level Fusion Module
对于带有伪装对象的捕获图像,伪装对象的比例经常变化。为了应对这些挑战,我们提出了一种 ACFM,通过引入多尺度通道注意 (MSCA) [Dai et al., 2020] 机制来有效融合跨层特征,该机制可以利用多尺度信息来缓解尺度变化。MSCA对不同尺度目标的适应性强,其结构如图2所示。MSCA基于双分支结构,其中一个分支使用全局平均池化获取全局上下文,强调全局分布的大对象, 其他分支保持原始特征大小以获得局部上下文以避免忽略小对象。与其他多尺度注意力机制不同,MSCA 在两个分支中使用点卷积(好像就是1x1卷积)沿通道维度压缩和恢复特征,从而聚合多尺度通道上下文信息。 不同层次的特征对任务的贡献不同,多层次的特征融合可以相互补充,得到全面的特征表达。
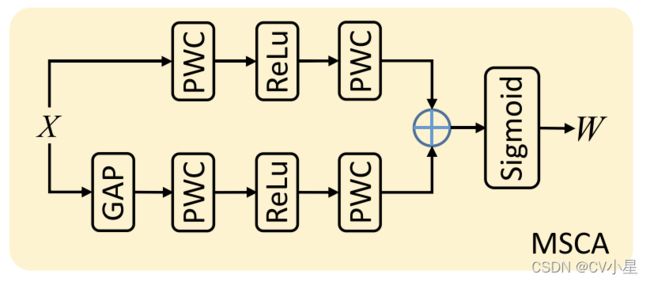
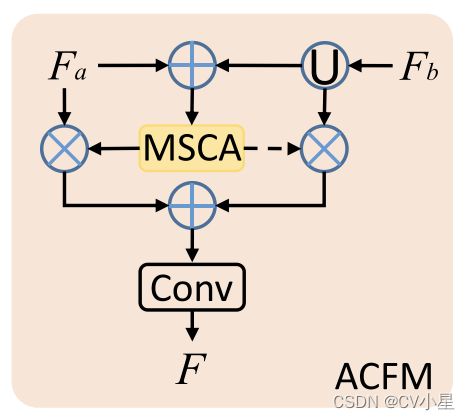
为了节省计算量,尽在有较高语义的特征图上进行操作 f i { i = 3 , 4 , 5 } f_i\{i=3,4,5\} fi{i=3,4,5},其中跨层融合过程可以描述如下:
![]()
Dual-branch Global Context Module
我们采用了所提出的 ACFM 来融合不同层次的多尺度特征,它引入了多尺度通道注意机制来获得基于注意力的信息融合特征。我们采用了所提出的 ACFM 来融合不同层次的多尺度特征,它引入了多尺度通道注意机制来获得基于注意力的信息融合特征。
Loss Function
使用IOU损失和BCE损失之和 L = L I o U ω + L B C E ω L=L^\omega_{IoU}+L^\omega_{BCE} L=LIoUω+LBCEω.
实验细节
- 设备: NVIDIA Tesla P40 GPU
- 主干网络: Res2Net (使用ImageNet的预训练权重)
- 数据增强: 多尺度训练策略 (0.75,1,1.25)
- 输入尺寸: 352x352
- epoch: 40
- batch size:32
- learning rate:1e-4 (30个epoch后衰减10倍)
数据集
CHAMELEON、CAMO、COD10K
训练集使用CAMO、COD10K,分别在CHAMELEON、CAMO、COD10K的测试集上测试.
实验结果
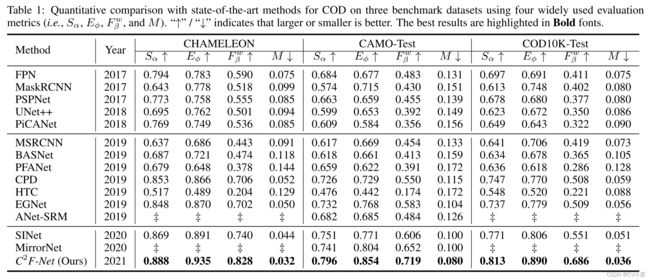
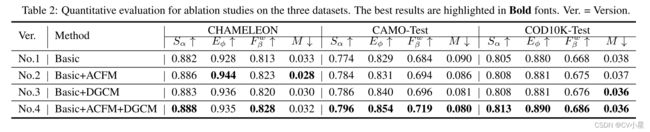
消融实验
根据下表验证了各个模块的有效性.

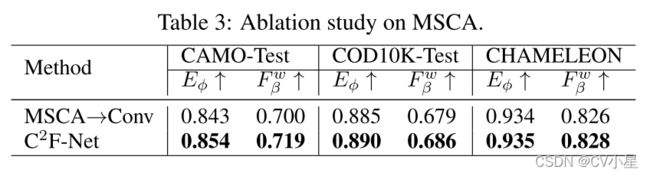
将MSCA模块换成普通卷积后效果下降,证明了MSCA模块的有效性.
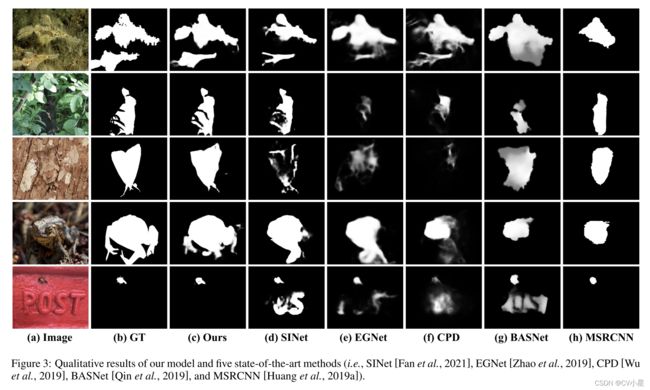
在本文中,我们提出了一种用于伪装物体检测的新型网络 C2F-Net,它结合了跨级别特征和丰富的全局上下文信息。 我们提出了一个上下文感知模块 DGCM,它利用来自融合特征的全局上下文信息。 我们将跨级别特征与有效的融合模块 ACFM 集成,该模块将这些特征与 MSCA 提供的有价值的注意力线索相结合。 三个基准数据集的广泛实验结果表明,所提出的模型优于其他最先进的方法。