ACDC:开箱即用的多租户数据集成平台
ACDC 是什么?
ACDC 的由来
新东方的一些核心业务存在单元写、中心入仓的场景,因此需要将数据从各单元的关系型数据库同步到中心,并异构存储到数据仓库之中。
技术团队最初使用 Apache Sqoop 以批的方式实现了这个能力。随着数据量的增长,这个方案很快暴露出了一些问题,如:
- 为了不影响业务,同步数据只能在夜间进行,制约了报表的时效性
- 数据的同步周期随着数据量增长而增长
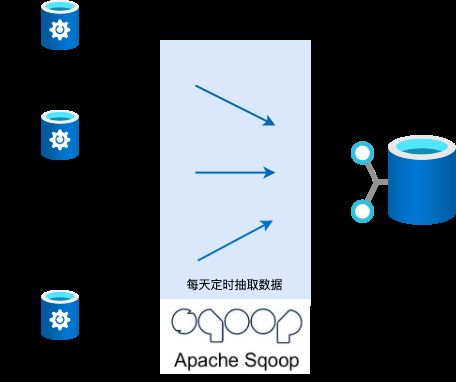
这时,大数据团队引入了 kafka connect 技术栈,并结合 Canal、SQLServer CT 等工具,实现了从批到流的转变,从而有效解决了以上问题。
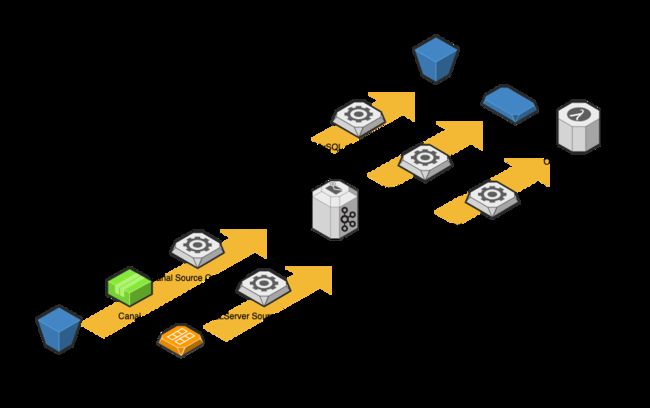
这时的数据同步仍是以工具的形态存在,随着同步链路的数量不断增长,又暴露出了一些新的问题,如:
- 核心服务不具备跨主机可用性
- 无 DevOps 手段,需要专属团队统一运维,边际成本较高且效率较低
- 血缘关系只能依靠文档记录,数据溯源的成本随着时间推移而提升
- 随着租户身份不断增多,需要精细的监控、告警手段
- 缺乏数据权限管理手段,仍需借助 OA 等外部系统
因此,新东方集团架构部决定以平台化方式解决上述问题,并将此产品逐渐演进为完整的数据中台解决方案,这个产品就是 ACDC。
ACDC 简介

ACDC:A Change Data Capture,是新东方集团架构部开源的数据平台产品,其目标是成为一个完整的数据集成、服务解决方案,为大数据团队和技术团队提供以下 DevOps 能力:
- 端到端全量、增量数据同步
- 数据聚合、转换
- 数据接口
- 可观测性
目前 ACDC 在新东方内部承载了 1000+ 的实时数据同步链路,仍在稳定增长中。
项目地址:https://github.com/xdfdotcn/acdc
使用方式
ACDC 的设计目标是以 DevOps 的方式为技术团队提供数据能力,因此所有操作都以多租户、白屏化进行。
角色
在介绍使用方式前,我们先了解下 ACDC 上定义的几种角色:
- 平台管理员:主要维护平台运行环境级别的元数据,如 kafka 集群等
- DBA:数据系统负责人,主要维护链路级别元数据,如项目信息、数据系统信息等
- 技术团队负责人:数据源负责人,主要进行链路审批操作
- 技术团队成员:ACDC 主要使用者,进行链路的生命周期管理,如链路创建、链路编辑等
创建实时增量数据同步链路
目前 ACDC 主要实现了部分数据源的实时同步能力,经过选取数据源、选取数据目标、字段匹配规则编辑等几个步骤后,即可完成链路的创建
选取数据源


选取数据目标
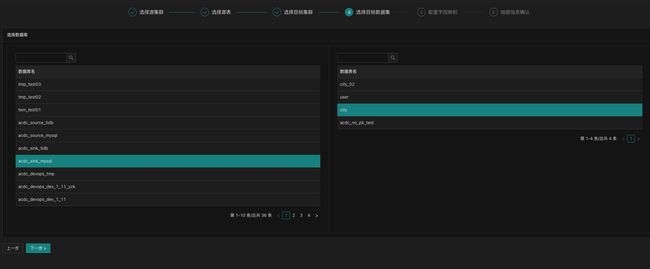
字段匹配规则配置

链路维护
使用场景
单元写,中心入仓
由于新东方的业务特点,全国地面学校的数据都存储在各自的单元中。在这样的场景中,数据汇总到中心就成为了各类数据报表的前提。
另外,汇总后的数据需要来源标识字段,这是单元数据中所不具备的,由 ACDC 在同步时填充。
轻聚合业务
一些系统存在轻度聚合的业务场景(如清结算,财务等),聚合所需的数据源往往来自多个三方系统。
这类数据因为量级较大、没有明确查询边界等原因,不适合使用常规 API 的方式实现,更适合通过 ACDC 的数据链路方式同步数据。
例如:在清结算业务中,需要根据教务系统、报名系统、行课中心等系统中的流水数据计算机构间的资金划接。这些数据种类繁杂,没有明确的查询边界。并且所需的数据可能会因为计算规则的调整而调整,因此若以传统 API 方式实现成本较高、周期较长。
基于数据的事件通知
很多业务系统之间使用了基于消息的异步处理方式实现解耦。在很多场景中,这里的消息可以理解为某种领域模型的变更事件。相比业务代码自行产生事件的方式,通过 ACDC 基于 binlog 捕获各类数据事件的方式更加灵活,成本也更低。
数据异构
在一些较为复杂的查询场景下,我们通常会使用如 ElasticSearch 等 OLAP 型数据系统提升查询性能。因此,我们需要将数据从其他数据源中同步过来。
技术团队通过自行部署 Canal 等服务可以实现数据的实时同步,但这显然增加了技术团队的日常运维成本:Canal 的服务可靠性和数据可靠性。为了解决这 2 个问题,很多技术团队甚至还额外开发了数据对比工具和修复工具,也是无奈之举。
数据孤岛间的数据拷贝
在企业发展过程中,因为早期的烟囱式团队组织和开发模式,数据往往不互通,但不同团队间又有使用其他团队数据的业务需求,这时候使用数据拷贝往往是较为节约成本的方式。
同一个数据集被同步到多个下游数据系统中
在实际生产中,难免会出现同一个源数据集被同步到多个目标数据集中的情况:例如用户中心的数据,会同步到大数据团队的数仓中,也会被同步到 ES 中用于加速搜索。
ACDC 通过 kafka 做数据缓冲,只需要抽取一次数据,便可以同步到多个目标数据集中。这样做可以节约上游数据系统的性能开销,不会随着目标数据集的数量增加而加大,从宏观看是一种降本增效的行为。
术语表
source
数据源,产生数据事件的数据系统
sink
数据目标,存储数据事件的数据系统
connect worker
kafka connect 实例,一个 jvm 进程
connect cluster
工作在 connect distributed 模式下的 connect worker 组成的集群,是 connector 的运行时环境。同一个集群中的 connector 以及因此产生的 task 会调度到不同 connect worker 中
connector
代表一个同步链路,运行在 connect woker、connect cluster 中。被创建后将会产生若干 task 执行实际的同步链路任务。
根据在链路中所处的位置不同,又分为 source connector 以及 sink connector
source connector
负责将数据事件从数据源写入到 kafka 中,以供后续的处理环节消费
sink connector
负责将 kafka 中的数据写入到目标数据系统中,kafka 中的数据通常是由 source connector 所生产
task
工作在 connect worker 进程中,执行实际同步任务的线程
在 connector 被创建后,connect worker 会根据其配置启动相应数量的 task 线程
架构设计
从宏观看,ACDC 目前分为控制面和数据面两部分。控制面主要表达用户意图,数据面主要实现数据同步。
在这种模式下,性能瓶颈往往发生在数据面。又由于项目的定位是平台型产品,需要考虑到较大规模的应用场景,因此我们对数据面设计的基本要求之一就是各组件可水平扩容。
另外,我们认为这种控制面、数据面分离的设计模式很适合采用声明式编程,因此我们使用这种范型实现了 DevOps 模块。
模块拓扑
ACDC 目前的主要模块包括:
- 控制面
- UI
- API
- Controller
- 数据面
- Kafka Connector
- Kafka Connect Cluster
- AVRO Schema Registry
- Kafka Cluster
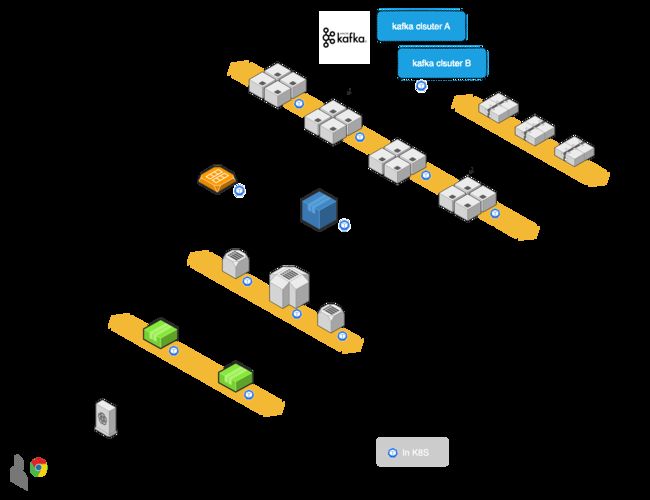
数据同步
ACDC 的增量数据同步基于 kafka connect 实现,对比 flinkCDC 等内存式数据同步流,具备以下优点:
- 对上游数据系统的性能影响更小:一次抽取,多次使用
- 更精准的运维手段:调整某个 sink connector 的消费点位,不会影响其他 sink connector

被 kafka cluster 解耦后,source connector 与 sink connector、sink connector 与 sink connector 之间不会互相影响。
随着链路数量的增长,以上拓扑中的 connect worker、kafka 容易成为性能瓶颈。短期内我们可以通过水平扩展增加这些集群的承载能力,但长期来看负载需求总量可能大于单集群的上限(我们在实际生产中发现:当单 connect cluster 中的 task 数量超过 1000 时,集群的故障恢复时间会明显加长)。所以我们在 ACDC 中增加了集群路由能力,使数据面的吞吐量水平扩展能力大大提升。
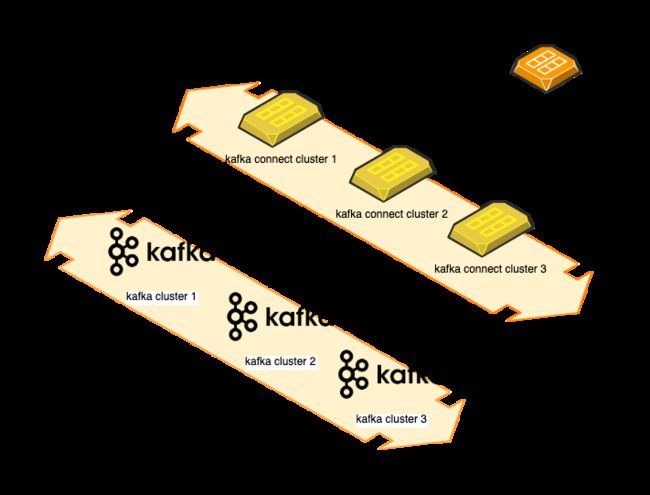
目前 ACDC 支持 MySQL、TiDB 作为数据源,Hive、MySQL、Oracle、Kafka、TiDB、SQLServer 作为数据目标。依托 kafka connect 强大的生态,未来我们将会支持更多的数据系统,包括开源、商业数据系统。
DevOps
DevOps 是 ACDC 的控制面,采用命令式编程范性实现,核心是 ACDC API 以及 ACDC controller。
这里我们借鉴了 k8s 的模块设计,上述两个模块分别与 apiserver、controller-manager 对等。熟悉 k8s 的同学一定知道,API 模块主要完成用户意图的表达,controller 模块则主要完成用户意图的实现:数据链路的生命周期管理。
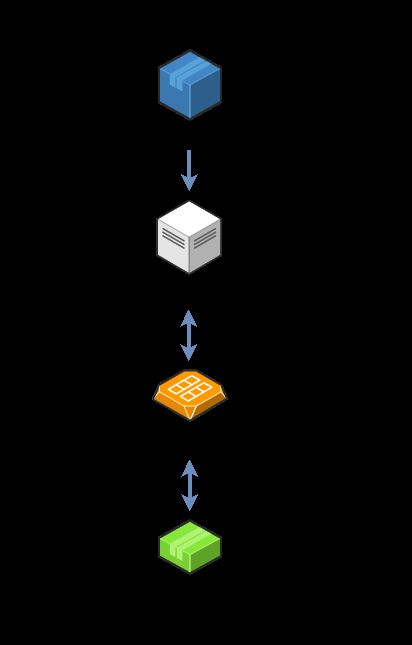
虽然带来了一些新的开发成本,但我们还是很明显的体会到了声明式编程带来的收益:更低的模块间耦合性,更高的扩展性。
可以简单的总结为:大多数用户操作周期与实际运算周期不同的业务,都适合采用这种开发范型。
服务可靠性
服务可靠性主要体现在数据面,依托 kafka connect distributed 模式、kafka 集群天然的跨进程故障恢复能力,ACDC 数据面具备整体的可靠性保障。
kafka 的可靠性原理相信大家已经很熟悉了,这里就不再过多介绍。
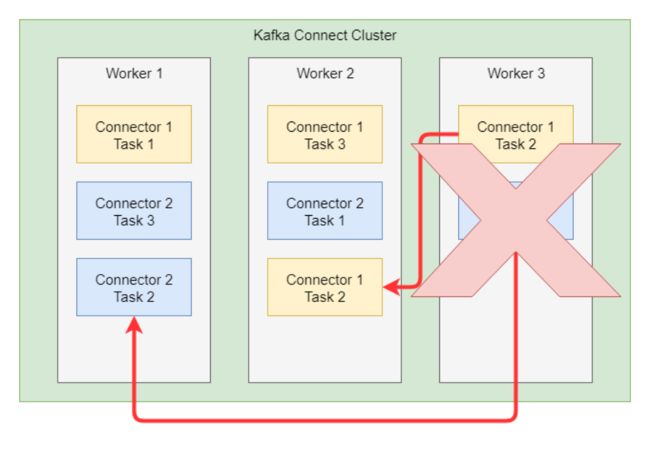
而 kafka connect distributed 模式主要基于 kafka 的 Coordinator 机制以及相应的 Group Management Protocol。在 kafka consumer 的场景中,被协调的资源是 partition 的消费机会。而在 connect 场景中,被协调的资源主要是执行同步链路的机会。
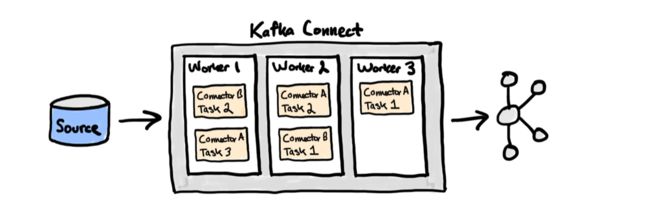
上图的 worker 代表集群中的每个 connect 进程,task 代表执行数据同步的线程。
当某个 worker 故障后,会触发 task 的重新分配,之前分配给故障节点的 task 会重新分配给其他健康节点,由此实现跨进程故障转移。kafka connect 与 kafka consumer 的故障转移都是 Coordinator 机制所提供的能力。
数据可靠性
数据可靠性是数据链路服务最重要的基础之一,是我们优先级最高的实现目标:每条数据链路都至少包含 4~5 个服务节点(数据源数据系统、source connector、kafka、sink connector、目标数据系统),任何一个节点都可能会丢失数据事件,并且故障定位成本很高。
流式处理常用“至少一次",”精准一次“来描述数据的准确等级,ACDC 满足”至少一次“的可靠性要求。我们认为在数据链路领域,”至少一次“可满足绝大多数应用的需求,并且这样可以降低一定实现成本。
source connector 的数据可靠性
source connector 的主要任务是将数据从源系统中提取出来,将付给 connect 框架,并最终写入到 kafka 集群中,供 sink connector 消费。

所以在 source connector 中,我们主要完成 2 个数据传递动作(数据内容处理,协议转换这里暂不展开):
- 通过上游数据系统的客户端提取数据事件(ACDC 主要基于 binlog 方式)
- 将数据事件交付给 kafka connect 框架
在这个场景中,保证“至少一次”也可以拆分为以下 3 个具体要求:
- 记录 source connector 对于上游数据系统的处理进度(例如 MySQL 的 binlog position)
- source connector task 重启后可以读取到最新进度,并从这个进度开始继续产生数据事件
- 进度在被记录前,要确保被发送到了下游 kafka 集群
依托于 kafka connect 框架,我们可以通过实现 source connector task 接口中的若干方法达到以上要求。
例如,下面的方法会在 kafka connect 通过 kafka producer 生产消息成功后被回调,实现这个方法即可满足上述第 3 点要求。
public abstract class SourceTask implements Task {
/**
*
* Commit an individual {@link SourceRecord} when the callback from the producer client is received. This method is
* also called when a record is filtered by a transformation, and thus will never be ACK'd by a broker. In this case
* {@code metadata} will be null.
*
*
* SourceTasks are not required to implement this functionality; Kafka Connect will record offsets
* automatically. This hook is provided for systems that also need to store offsets internally
* in their own system.
*
*
* The default implementation just calls {@link #commitRecord(SourceRecord)}, which is a nop by default. It is
* not necessary to implement both methods.
*
*
* @param record {@link SourceRecord} that was successfully sent via the producer or filtered by a transformation
* @param metadata {@link RecordMetadata} record metadata returned from the broker, or null if the record was filtered
* @throws InterruptedException
*/
public void commitRecord(SourceRecord record, RecordMetadata metadata)
throws InterruptedException {
// by default, just call other method for backwards compatibility
commitRecord(record);
}
}
sink connetor 的数据可靠性
sink connector 的工作方式和一个常规的 kafka client 类似:
- 从 broker 拉取消息
- 完成消息处理事务
- 提交已处理的消息的 offset 至 broker
所以要满足“至少一次”,只需要在提交了处理消息的事务后再提交偏移量即可,这与 kafka client 的日常使用类似,不再过多展开。
值得一提的是,若只是简单按上述方式实现 sink connector,可能会由于串行的处理方式影响性能。因此,ACDC 对上述流程进行了优化:在保证了可靠性的基础上,通过异步的方式提升了一定的性能。这部分内容将在后续的文章中继续展开讨论。
可扩展性
在 ACDC 领域,可扩展性分为两个部分:
- DevOps
- 数据链路
数据链路的可扩展性
由于 ACDC 基于 kafka connect 框架,因此天然就具备其所包含的良好的可插拔式的扩展方式。这些可扩展点包括:
- source、sink connector 支持的数据系统:对应 ETL 中的 E 和 L
- Converter 插件实现消息的序列化:这对于自行消费数据事件的用户很有帮助
- Transformer 插件实现消息内容转换:对应 ETL 中的 T
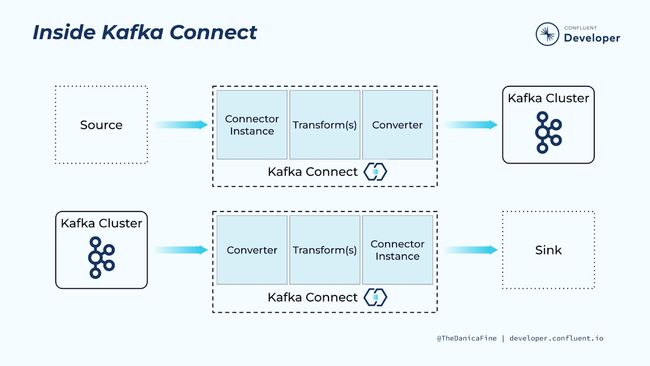
ACDC 也实现了一些自己的 Transformer、Converter,这些扩展既可以与 ACDC 一起工作,也可以单独与 kafka connect 工作。
DevOps 模块的可扩展性
前文提到 ACDC DevOps 模块采用声明式编程的开发范型,这种范型比较明显的一个受益就是:模块间的耦合度极低,低到几乎只有存储元数据的数据服务。这里讲的模块不单指项目中的 module,粒度可以细到单个领域模型。
举例来讲,ACDC 中链路相关的最重要的领域模型是 Connection,他负责描述用户创建的链路。在用户创建链路时,模块间的大致处理流程如下:
文字版
- ACDC 的 API 模块负责检验用户通过 UI 提交的数据,并保存至 ACDC 原数据存储服务中(目前是 MySQL)
- Connection 模型具备预期、实际两个状态,代表用户的预期状态和链路的实际状态。此时两个状态都是 stopped
- 用户启动链路,API 将 connection 的预期状态改为 running
- ACDC 的 Connection Controller 模块通过 Informer 机制 watch 到有新的 Connection 创建,并且预期状态域实际状态不一致后(running : stopped),根据 Connection 创建 Connector 模型的两个实例: source connector、sink connector,并将 Connection 的实际状态更改为 starting
- Connector Controller 模块 watch 到新的实例后,通过 kafka connect REST API 完成实际的创建动作,并将 Connector 的实际状态改为 starting
- Connector Controller 模块 watch 到 kafka connect 集群中存在了刚创建的 connector 实例,并且状态为 running 后,将 Connector 的实际状态更改为 running
- Connection Controller watch 到刚创建的 Connection 相关的两个 Connector 实际状态都是 running 后,将 Connection 的实际状态改为 running
时序图版

至此,用户可以在 UI 上看到刚刚创建的链路状态已经更改为 running。
在上述业务流程中,API、Connection Controller、Connector Controller 间的耦合只有存储 ACDC 元数据的 MySQL。这样除了降低系统复杂度外,也十分便于扩展。
一个例子
试想我们现在需要增加一个新功能:新表自动入仓。
要实现这个功能,我们需要扫描某个数据源 database 中的表,并在发现新表时建立对应的 Connection 即可。
在声明式开发范型下,我们只需要再增加一个类似 AutoConnection 的模型,以及相关 Controller。在用户创建了这个模型的实例后,Controller 就会 watch 目标 database 中的 table,并在发现 table 后创建对应的 Connection 实例,即可实现这个功能。
在实现过程中,不需要对原先的逻辑做任何改动,即没有耦合存在。
可观测性
ACDC 的可观测性基于 Prometheus 生态,这也是云原生的可观测性标准设施。
目前大部分模块都暴露了 metrics 接口,当前的指标主要体现了健康状态以及性能状态,未来我们会继续完善各类业务指标。
我们根据租户类型、数据系统的维度绘制了 5 类监控看板,可覆盖平台各类用户的可观测关注点。
平台管理人员
在宏观方面,运维人员重点关注全部链路的健康情况,性能情况,各组件、集群资源使用情况

在微观方面,运维人员重点关注某个 sink connector 的 task 调度、所在 connect worker 的 JVM、source connector 的性能情况等等
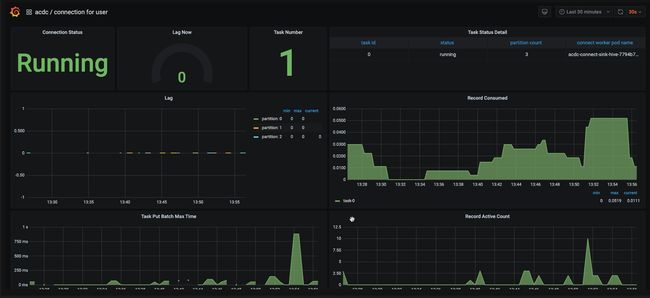
技术团队成员
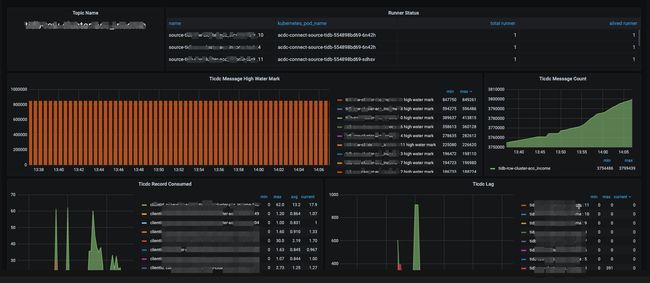
技术团队成员是数据链路的创建者,主要关注某链路的工作状态、延迟情况等
MySQL Source

TIDC Source
现状与 roadmap 规划
就像文章开篇介绍的,ACDC 的产品定位是 DevOps 形式的数据中台产品,他将具备:
- 端到端增量数据同步
- 端到端全量数据同步
- 数据聚合、转换能力
- 数据服务能力
目前我们还处于起步阶段:具备了一些数据系统间的增量数据同步能力。下一个阶段我们将会支持更多的数据系统种类,并且增加全量同步能力。
| 状态 | 数据源 | 数据目标 |
|---|---|---|
| 已实现 | MySQL TiDB(with TiCDC) |
JDBC 支持的数据系统(MySQL、TiDB、SQLServer、Oracle 等) Hive Kafka |
| 未实现 | TiDB (with TikvClient) Oracle Sqlserver PostgreSQL Kafka Hologres |
Elastic Search Redis MacCompute Hologres PostgreSQL StarRocks IceBerg Hudi |
数据处理方面,主要是针对数据提供一些加工、聚合能力,例如数据变换,数据过滤,数据维度打宽等。这在同步到 OLAP 型数据系统的场景中很常见。
数据服务方面,主要是将数据同步、处理的结果提供 REST 等访问方式。
彩蛋:努力成为像 AC/DC 一样伟大的旗帜

相信热爱摇滚乐的同学一定会像我一样,对 AC/DC 这四个字母有着深深的崇敬。
为产品赋予这样的名字,除了开篇提到的字面语意外,也是我们团队向这支伟大的摇滚乐队表达敬意的一种方式。
同时也在时刻提醒自己:要向着伟大不断前行,永远纯粹和热情。