python Clickhouse 分布式表介绍和创建、插入和查询数据,以及解决遇到的问题
目录
一、分布式表和本地表
原理解析:
二、Clickhouse创建分布式表结构
三、python代码实现(亲测有效)
四、解决遇到的问题
解决 DB::Exception: Missing columns: 'wefgrgrfew' while processing query: 'wefgrgrfew', required columns: 'wefgrgrfew' 'wefgrgrfew': While executing ValuesBlockInputFormat. Stack trace:
一、分布式表和本地表
clickhouse中的表可以分为分布式表和本地表。
分布表包括逻辑表和物理表,,逻辑表就是表机构用于查询,物理表是实际存储数据的。
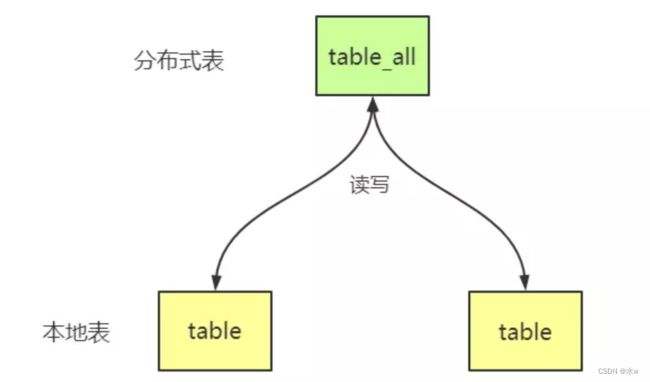
(1)分布式表:逻辑存在的表,自身不存储数据,可以理解为数据库中的视图, 一般建议使用分布式表做查询操作,分布式表引擎会将我们的查询请求路由本地表进行查询, 然后进行汇总最终返回给用户。
(2)本地表:真正存储数据的表。
原理解析:
分布式(Distributed)表引擎是分布式表的代名词,它⾃身不存储任何数据,⽽是作为数据分⽚的透明代理,能够⾃动的路由数据⾄集群中的各个节点,即分布式表需要和其他数据表⼀起协同⼯作。分布式表会将接收到的读写任务,分发到各个本地表,而实际上数据的存储也是保存在各个节点的本地表中。原理如下图:
二、Clickhouse创建分布式表结构
分布式表创建规则:
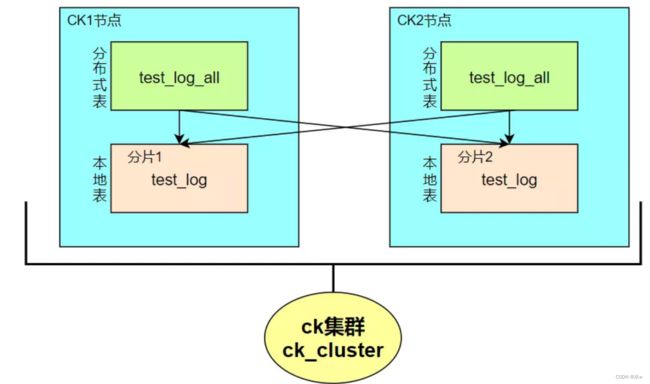
使用on cluster语句在集群的某台机器上执行以下代码,即可在每台机器上创建本地表和分布式表,其中⼀张本地表对应着⼀个数据分⽚,分布式表通常以本地表加“_all”命名。它与本地表形成⼀对多的映射关系,之后可以通过分布式表代理操作多张本地表。
这里有个要注意的点,就是分布式表的表结构尽量和本地表的结构一致。如果不一致,在建表时不会报错,但在查询或者插入时可能会抛出异常。
在集群中使用,我们要加上on cluster
(1)先在每一个分片上创建本地表:
-- auto-generated definition 物理表
CREATE TABLE IF NOT EXISTS test.test_log ON CLUSTER '{cluster}' (
ts_date Date,
ts_date_time DateTime,
user_id Int64,
event_type String,
site_id Int64,
groupon_id Int64,
category_id Int64,
merchandise_id Int64,
search_text String
-- A lot more columns...
)ENGINE = ReplicatedMergeTree('/clickhouse/tables/{shard}/test/events_local','{replica}')
PARTITION BY ts_date
ORDER BY (ts_date,toStartOfHour(ts_date_time),site_id,event_type)
SETTINGS index_granularity = 8192;ReplicatedMergeTree引擎族接收两个参数:
- ZK中该表相关数据的存储路径,ClickHouse官方建议规范化,如上面的格式
/clickhouse/tables/{shard}/[database_name]/[table_name]。 - 副本名称,一般用
{replica}即可。
观察一下上述ZK路径下的znode结构与内容。
[zk: localhost:2181(CONNECTED) 0] ls /clickhouse/tables/01/test/events_local
[metadata, temp, mutations, log, leader_election, columns, blocks, nonincrement_block_numbers, replicas, quorum, block_numbers]
[zk: localhost:2181(CONNECTED) 1] get /clickhouse/tables/04/test/events_local/columns
columns format version: 1
9 columns:
`ts_date` Date
`ts_date_time` DateTime
`user_id` Int64
`event_type` String
`site_id` Int64
`groupon_id` Int64
`category_id` Int64
`merchandise_id` Int64
`search_text` String
# ...................
[zk: localhost:2181(CONNECTED) 2] get /clickhouse/tables/07/test/events_local/metadata
metadata format version: 1
date column:
sampling expression:
index granularity: 8192
mode: 0
sign column:
primary key: ts_date, toStartOfHour(ts_date_time), site_id, event_type
data format version: 1
partition key: ts_date
granularity bytes: 10485760
# ...................ReplicatedMergeTree引擎族在ZK中存储大量数据,包括且不限于表结构信息、元数据、操作日志、副本状态、数据块校验值、数据part merge过程中的选主信息等等。可见,ZK在复制表机制下扮演了元数据存储、日志框架、分布式协调服务三重角色,任务很重,所以需要额外保证ZK集群的可用性以及资源(尤其是硬盘资源)。
(2)分布式表引擎的创建模板:
支持分布式表的引擎是Distributed,建表DDL语句示例如下,_all只是分布式表名比较通用的后缀而已。
-- auto-generated definition 逻辑表
CREATE TABLE IF NOT EXISTS test.test_log_all ON CLUSTER sht_ck_cluster_1
AS test.events_local
ENGINE = Distributed(sht_ck_cluster_1,test,events_local,rand());至此,ck_cluster集群的本地表test_log和分布式表test_log_all就创建完成了。
Distributed引擎需要以下几个参数,参数描述:
- cluster:集群名称,在对分布式表执⾏读写的过程中,它会使⽤集群的配置信息来找到相应的host节点。
- database,table:本地表所在的数据库和本地表名称,用于将分布式表映射到本地表上。
- 本地表名称,
- sharding_key(可选的): 分⽚键,分布式表会按照这个规则,将数据分发到各个本地表中。该键与config.xml中配置的分片权重(weight)一同决定写入分布式表时的路由,即数据最终落到哪个物理表上。它可以是表中一列的原始数据(如
site_id),也可以是函数调用的结果,如上面的SQL语句采用了随机值rand()。注意该键要尽量保证数据均匀分布,另外一个常用的操作是采用区分度较高的列的哈希值,如intHash64(user_id)。 - --创建分布式表test_log_all,数据在读写时会根据rand()随机函数的取值,决定数据写⼊哪个分⽚,也可以用hash取值。 create table test_log_all on cluster ck_cluster ( totalDate Date, unikey String ) engine = Distributed('ck_cluster', 'test', 'test_log', rand());
三、python代码实现(亲测有效)
from clickhouse_driver import Client
# 连接clickhouse数据库:host为ip地址,port为端口号,database为数据库名
client = Client(host='host', port='9000', database='database', user="user", password="xxxxxx")
# 创建本地表
sql = """
CREATE TABLE if not exists test_local on cluster 【集群名称】
(
id Int32,
user_name String,
age Int32
) ENGINE = MergeTree()
PARTITION BY id
ORDER BY id
SETTINGS index_granularity = 8192
"""
res = client.execute(sql)
print('#######res:',res)
# 创建分布式表
sql = """
CREATE TABLE if not exists test_all on cluster 【集群名称】
AS database.test_local
ENGINE = Distributed(【集群名称】, database, test_local, rand());
""" # cluster集群名,数据库名,本地表名,在读写时会根据rand()随机函数的取值来决定数据写⼊哪个分⽚
res = client.execute(sql)
print('#######res:',res)
# 打印表结构
sql1 = 'desc test_all'
sql2 = 'desc test_local'
ans = client.execute(sql1)
print('#######ans:',ans)
ans = client.execute(sql2)
print('#######ans:',ans)
# 写入数据
insert_sql = "insert into database.test_all(id,user_name,age) values ('%s','%s','%s')" % (6,"wefgrgw",23)
ans = client.execute(insert_sql)
# 查询数据
sql = """SELECT * FROM test_all where id=6"""
print('#######result:', client.execute(sql))
可以看到,插入成功了。
注意:如果恰好存到连接的这台服务器的话就可以在本地表中查询到,否则在本地表中查询不到该条信息。
四、解决遇到的问题
解决 DB::Exception: Missing columns: 'wefgrgrfew' while processing query: 'wefgrgrfew', required columns: 'wefgrgrfew' 'wefgrgrfew': While executing ValuesBlockInputFormat. Stack trace:
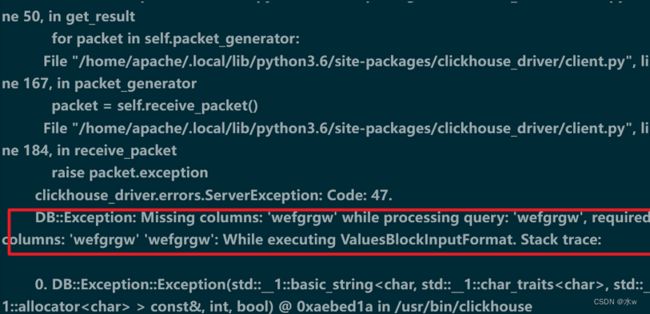
问题原因:insert语句写的不对,所以导致插入失败。
解决:
from clickhouse_driver import Client
# 连接clickhouse数据库:host为ip地址,port为端口号,database为数据库名
client = Client(host='host', port='9000', database='database', user="user", password="xxxxxx")
# 写入数据
insert_sql = "insert into database.test_all(id,user_name,age) values ('%s','%s','%s')" % (6,"wefgrgw",23)
ans = client.execute(insert_sql)
print('#######ans:',ans)![]()
可以看到,成功插入数据了。